字符编码
个人理解
一个字符需要保存到计算机中,计算机只能识别0、1。这就需要一个规则来表述0、1数据与字符之间的关系。
ASCII码
表述 1个字节 0、1数据与字符之间的关系。
非ASCII码
英语用128个符号编码就够了,但是用来表示其他语言,128个符号是不够的。比如说中文,这就意味着需要更多的规则与更多的存储空间来存储字符。
产生的问题
获取到一个文件,需要知道文件的编码方式,如果这个编码方式比较小众,产生乱码可能概率就会很高。
unicode
有一种编码,将世界上所有的符号都纳入其中。每一个符号都给予一个独一无二的编码,那么乱码问题就会消失。这就是Unicode,就像它的名字表示的,这是一种所有符号的编码。
unicode的问题
Unicode是一个很大的集合,每个字符的编码都不一样,如果要全量表示字符,需要好几个字节,如果一个文件全部都是英文字符,不使用ASCII编码,而使用unicode的话,会浪费很多空间。
影响
unicode成为了一个符号集,规定了一个符号对应的数值,却没有规定这些数值如何存储到计算机中。我们可以把unicode看成一个properties,这里的key是字符,value是对应的数值
UTF-8
UTF-8编码是Unicode的实现方式之一。
说明了,计算机中如何存储字符对应的unicode码。
编码规则
- 对于单字节的符号,字节的第一位(字节的最高位)设为0,后面7位为这个符号的unicode码。因此对于英语字母,UTF-8编码和ASCII码是相同的。
- 对于n字节的符号(n>1),第一个字节的前n位都设为1,第n+1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的unicode码。
下表总结了编码规则,字母x表示可用编码的位。
| Unicode符号范围 | UTF-8编码方式 |
|---|---|
| 0000 0000-0000 007F | 0xxxxxxx |
| 0000 0080-0000 07FF | 110xxxxx 10xxxxxx |
| 0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx |
| 0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
举个栗子
"张"这个字符的unicode码为\u5f20,对应上表中的0000 0800-0000 FFFF,所以会占用3个字节,具体存储为:E5 BC A0
UTF-16
UTF-16编码是Unicode的实现方式之一。
说明了,计算机中如何存储字符对应的unicode码。
编码规则
| Unicode编码范围 | UTF-16编码方式 |
|---|---|
| U+000~U+FFFF | 2 字节存储,编码后等于Unicode值 |
| U+10000~U+10FFFF | 4 字节存储,编码后U2 = U-0x10000,把U2转换成二进制:yy yyyyyyyy xx xxxxxxxx,最终UTF-16编码为:110110yy yyyyyyyy 110111xx xxxxxxxx |
举个栗子
"张"这个字符的unicode码为\u5f20,对应上表中的U+000~U+FFFF范围,所以此时UTF-16的编码与unicode码一致5F 20
Little endian和Big endian
- little endian : 文件中先存字符对应编码的低字节
- big endian:文件中先存字符对应编码的高字节
举个栗子
\u5f20这个16进制数,保存到计算机中,是20保存在高字节即为"小头模式",反之是"大头模式"。这样计算机在解析文件的时候就知道,以一个什么样的顺序解析了。
如何查看文件是Little endian还是Big endian
有bom头的文件,在文件的最前面会添加一个表示存储顺序的字符,这个字符的名字叫做 “零宽度非换行空格”(ZERO WIDTH NO-BREAK SPACE),用FEFF表示。
如果一个文本文件的头两个字节是FE FF,就表示该文件采用大头方式;如果头两个字节是FF FE,就表示该文件采用小头方式。
举个栗子
utf16 编码的文件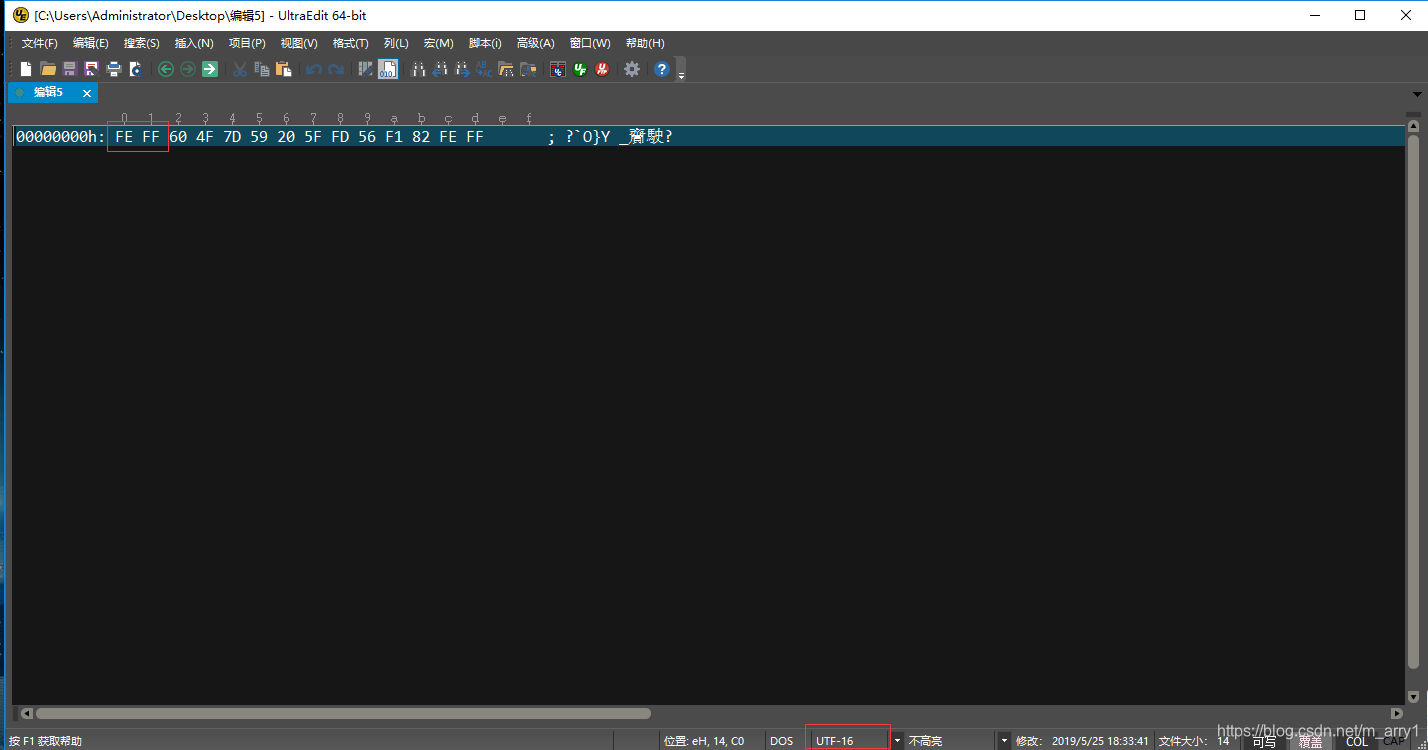
注意点
uft8编码的文件是没有 “零宽度非换行空格”(ZERO WIDTH NO-BREAK SPACE),因为是可以通过每个字节的前缀识别出字节存储顺序的。
utf16编码的文件是可以通过
通信中的大小端问题
通信中规定都使用大端模式
延伸
javascript
每个字符在 JavaScript 内部都是以16位(即2个字节)的 UTF-16 格式储存。也就是说,JavaScript 的单位字符长度固定为16位长度,即2个字节。
但是,UTF-16 有两种长度:对于码点在U+0000到U+FFFF之间的字符,长度为16位(即2个字节);对于码点在U+10000到U+10FFFF之间的字符,长度为32位(即4个字节),而且前两个字节在0xD800到0xDBFF之间,后两个字节在0xDC00到0xDFFF之间。举例来说,码点U+1D306对应的字符为?,它写成 UTF-16 就是0xD834 0xDF06。
JavaScript 对 UTF-16 的支持是不完整的,由于历史原因,只支持两字节的字符,不支持四字节的字符。这是因为 JavaScript 第一版发布的时候,Unicode 的码点只编到U+FFFF,因此两字节足够表示了。后来,Unicode 纳入的字符越来越多,出现了四字节的编码。但是,JavaScript 的标准此时已经定型了,统一将字符长度限制在两字节,导致无法识别四字节的字符。上一节的那个四字节字符?,浏览器会正确识别这是一个字符,但是 JavaScript 无法识别,会认为这是两个字符。
栗子
- 浏览器中显示?
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
</head>
<body>
<a>?</a>
</body>
</html>
- 一个字符识别为2个字符
"?".length; //2
java
JVM内部是以UTF-16形式存储字符(char)。
栗子
@Test
public void testEncoding(){
String testUtf16 = "张";//UTF-16存储字符
byte[] strByte = testUtf16.getBytes();//UTF-8 字节流
byte[] bytes = {(byte) 0xE5, (byte) 0xBC, (byte) 0xA0};
String byte2str = new String (bytes);
System.out.println(byte2str);//"张"
}
debug
说明:
通过观察testUtf16这个字符串可以看出char类型是使用utf-16编码的,通过testUtf16.getBytes()得到字节数组,可以看到这个数组的长度为3,明显不符合utf16编码规范,通过观察,可以知道是使用utf8编码的。
后面3行代码,用于验证猜测。
参考
https://www.cnblogs.com/daxiong2014/p/4768681.html
https://www.cnblogs.com/cyq1162/p/9183424.html
https://github.com/wangdoc/javascript-tutorial/blob/master/docs/types/string.md
https://blog.csdn.net/u200814499/article/details/53420263