1. 什么是索引?为什么要建立索引?
索引类似一本书的目录,用于快速找出在某个列中含有特定值的行,起到优化查询的作用。若是使用索引,MySQL必须从第一条记录开始读完整个表,知道找出相关的行,表越大,查询数据所花费的时间就越多。如果表中所查询的列建立了索引,那么MySQL就能够快速到达一个位置就搜索数据文件,而不必查看所有数据,这样就会极大的提高查询的速度,且表越大效果越明显。
2. 索引的分类
MySQL支持"FULLTEXT"、“NORMAL”、“SPATIAL”、“BTREE”、“HASH”、"UNIQUE"等索引类型。各个索引使用的场合和优缺点请参看此篇博客:传送门
此篇博客主要分析MySQL中默认使用的B树(BTREE)索引。
3. B树索引的优缺点


索引只是提高效率的一个因素,如果MySQL有大量数据的表,就需要花时间研究建立最优秀的索引,或优化查询语句。因此应该只为最经常查询和最经常排序的数据列建立索引。
4. B树索引的存储结构
索引是在存储引擎中实现的,也就是说不同的存储引擎,会使用不同的索引。如:
- MyISAM和InnoDB存储引擎只支持B树索引且不能更换
- MEMORY/HEAP存储引擎支持HASH和B树索引
这里只介绍MySQL数据库InnoDB和MyISAM存储引擎默认的索引存储类型:B树
B-树的查询过程和二叉排序树比较类似,从根节点依次比较每个节点,因为每个节点中的关键字和左右子树都是有序的(建立索引时,就已经将索引列的值按顺序排列好了),所以只要比较节点中的关键字,或沿着指针就能很快找到指定的关键字,如果查找失败,则会返回叶子节点,即空指针。
例如查询上图B-树中的数字13
1.从根节点15开始,13数值小于15,则进入左侧指针
2.左子树中,依次将13和4、8比较,因为13比8大,所以进入右侧指针
3.沿着右侧指针继续访问子树,并同样依次比较。发现第一个关键字13即为指定查找的值
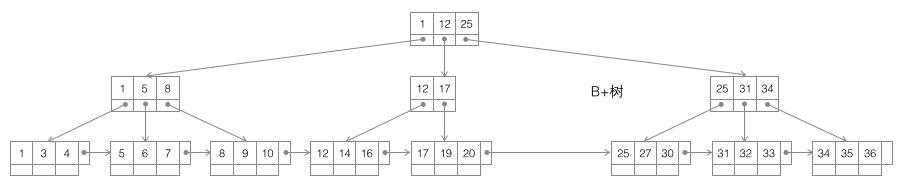
B+树的查找过程,与B树类似,只不过查找时,如果在非叶子节点上的关键字等于给定值,并不终止,而是继续沿着指针直到叶子节点位置。因此在B+树中,不管查找成功与否,每次查找都是走了一条从根到叶子节点的路径。
同时B+树相对B-树,在叶子节点间增加了横向指针,这样使得范围查找或者说顺序遍历变得更高效。
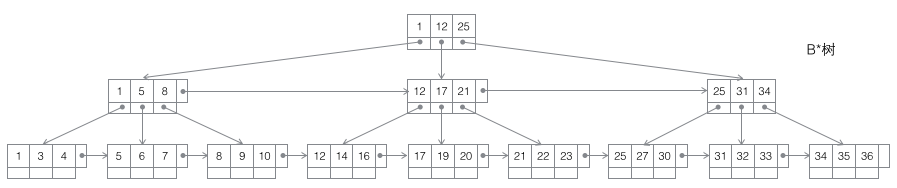
B*树的查找过程,与B+树类似,优化的地方就是在枝节点间也增加了横向指针,进一步优化了顺序遍历。
以上三张图是B树的演变,关于B树的具体原理请参考:传送门
tip:
·B-tree--->B+tree--->B*tree演变中的主要区别
B+tree相对B-tree,在叶子节点上增加了双向指针,对范围查询的情况做了进一步的优化;
B*tree相对B+tree,又在枝节点上增加了双向指针,对范围查询的情况又进一步优化
·对于innodb的B树索引来说,所有的行数据都放在叶子节点,非叶子节点不存储行数据,是为了存储更多的索引建,从而降低B树的高度,减少IO的次数,一般维持在3层及三层以内最佳。所以一般来说高度为3的树就可以存储百万级别的数据。
tip:MySQL对于百万级别的数据支持性比较好,因为数据一旦达到千万级别,B数的层数就会超过3层,此时MySQL数据库的性能就会急剧下降。所以当数据量较大的时候,对于MySQL数据库来说就需要使用分布式架构,进行数据的分库分表。(oracle对于千万级别的数据处理比较好)
·数据时如何查询的:
假设现在有一个高度为3的B+树,当我们查找数据时,会先发生第一次IO加载高度为1的磁盘块1到内存,然后在内存中二分查找得到下次需要加载的高度为2的磁盘块2的地址,然后再发生第二次IO加载磁盘块2到内存中再比较得到高度为3的磁盘块3的地址,再发生第三次IO加载磁盘3到内存比较就可以得到数据了。不过非叶节点通常会在初始阶段载入内存以加快访问速度。
·mysql加载索引是以磁盘块(页)为单位的,并不是一次性全部加载到内存中,每次只需要加载需要的那一块。然后一般高度为3的树就可以存储千万级别的数据,所以一般只需要3次IO就可以得到数据,速度就很快了
·数据行数较多引起的索引树高度较高时的解决办法:
分表:parttion 用的比较少了
分片:分布式架构.
5. B树索引的方式
- 聚集索引
目前,只有solidDB和InnoDB支持聚集索引,MyISAM不支持聚集索引。
tip:聚集索引和非聚集索引的区别
InnoDB使用的是聚集索引,将主键组织到一棵B+树中,而行数据就储存在叶子节点上,若使用"where id = 14"这样的条件查找主键,则按照B+树的检
索算法即可查找到对应的叶节点,之后获得行数据。若对Name列进行条件搜索,则需要两个步骤:第一步在辅助索引B+树中检索Name,到达其叶子节点获取对
应的主键。第二步使用主键在主索引B+树种再执行一次B+树检索操作,最终到达叶子节点即可获取整行数据。
MyISM使用的是非聚集索引,非聚集索引的两棵B+树看上去没什么不同,节点的结构完全一致只是存储的内容不同而已,主键索引B+树的节点存储了主键,
辅助键索引B+树存储了辅助键。表数据存储在独立的地方,这两颗B+树的叶子节点都使用一个地址指向真正的表数据,对于表数据来说,这两个键没有任何差
别。由于索引树是独立的,通过辅助索引检索无需访问主键的索引树。见下图。
我们重点关注聚集索引,看上去聚集索引的效率明显要低于非聚集索引,因为每次使用辅助索引检索都要经过两次B+树查找,这不是多此一举吗?聚集索引的优势在哪?
1 由于行数据和叶子节点存储在一起,这样主键和行数据是一起被载入内存的,找到叶子节点就可以立刻将行数据返回了,如果按照主键Id来组织数
据,获得数据更快。
2 辅助索引使用主键作为"指针" 而不是使用地址值作为指针的好处是,减少了当出现行移动或者数据页分裂时辅助索引的维护工作,使用主键值当
作指针会让辅助索引占用更多的空间,换来的好处是InnoDB在移动行时无须更新辅助索引中的这个"指针"。也就是说行的位置(实现中通过16K的Page来定
位,后面会涉及)会随着数据库里数据的修改而发生变化(前面的B+树节点分裂以及Page的分裂),使用聚簇索引就可以保证不管这个主键B+树的节点如何变
化,辅助索引树都不受影响。


- 辅助索引(二级索引)

主键索引是InnoDB存储引擎默认给我们创建的一套索引结构,我们表里的数据也是直接放在主键索引里,作为叶子节点。但我们在开发的过程中,往往会根据业务的需求在不同的字段上建立索引,这些索引就是二级索引。
比如,你给表中的name字段加了一个索引,你插入数据的时候,就会重新搞一棵B+树,B+树的叶子节点也是数据页,但是这个数据页里仅仅存放了主键字段和name字段。叶子节点的数据页的name值,跟主键索引一样的,都是按照大小排序的。同一个数据页里的name字段值都是大于上一个数据页里的name字段值。name字段的B+树也会构建多层索引页,这个索引页里放的是下一层的页号和最小name字段的值。
建立辅助索引,查找整行数据时,存储引擎需要进行两次B树查找:
- 找到辅助索引的叶子节点获取对应的主键值;
- 根据这个主键值去聚集索引中查找到对应的整行数据。若使用辅助索引查找建立辅助索引所在列的值,就不再需要在聚集索引中查找了。
4.1查看索引的方式
首先创建一张表,或者从自己的数据库中找到一张表,我这里就使用我自己数据库中的"users"表给大家演示。
users表:
tip:因为我在创建users表时就指定了"u_id"列为主键列,所以MySQL自动使用"u_id"列创建了一个聚集索引
步骤一:
DESC users; 查询表中有哪些索引
PRI ==> 主键索引
MUL ==> 辅助索引
UNI ==> 唯一索引
步骤二:
SHOW INDEX FROM users; 查看表中索引的具体名称
4.2辅助索引细分
- 单列辅助索引
单列辅助索引的创建:
ALTER TABLE users ADD INDEX idx_name(username);
tip:
1.idx_name是索引名称,()括号里表示要使用哪一列建立辅助索引
2.创建索引是在线DDL操作,会产生锁表的动作,所以尽量不要在数据库使用的高峰期去创建索引
结果:
- 多列的联合索引
多列联合索引的创建:
ALTER TABLE users ADD INDEX idx_n_a(username,age);
- 唯一索引(若是选取的列中的值不是唯一值,那么创建唯一索引就会报错)
唯一索引的创建:
ALTER TABLE users ADD UNIQUE INDEX idx_c(country);
若是一张在创建时没有指定哪一列是唯一值列,可通过下面的语句测试:
SELECT COUNT(xxx) from 表名; 计算某一列值的个数
SELECT COUNT(DISTINCT xxx) from 表名; 将此列去重后,计算此列值的个数
若是两个结果一直,则说明此列是唯一值列。
- 前缀索引(前缀索引只能使用在字符串列,数字列无法创建前缀索引)
前缀索引的创建:
ALTER TABLE users ADD INDEX idx_use(username(3)); 取username列值字符串的前3个字符作为索引值
tip:创建前缀索引的方式和创建单列辅助索引的方式一样,那为什么还要有前缀索引呢?
有时候想要在一列上建立索引,但是此列的列值都是很长的字符串,要是使用单列辅助索引,这样创建出来的索引,索引文件就会很大,而且也会让查询变得很慢。
所以可以使用前缀索引对此列进行建立索引,前缀索引就是只使用字符串的部分字符创建索引,这样就可以大大的缩小索引文件的大小,节约硬盘空间,也提高了查询效率。
但是使用前缀索引也有可能会降低索引的选择性。索引的选择性是指不重复的索引值和数据表记录总数的比值,
索引选择性越高则查询效率越高,因为不重复值多的索引可以让MySQL在查询时直接过滤掉更多的行。
只使用字符串的部分字符建立索引,就有可能提高索引值的重复性。所以在使用前缀索引时,尽量选择不重复的字符串列。
4.3删除索引
ALTER TABLE users DROP INDEX idx_name; 删除users表名称为idx_name的辅助索引
6. 压力测试
下面通过压力测试,来展示建立索引对于查询效率的优化程度。
db01 [(none)] >use test
db01 [test]> source /tmp/t100w.sql 大家可以从网站上搜索"t100w.sql"这张表用来测试
db01 [test]>select count(*) from t100w;
+----------+
| count(*) |
+----------+
| 1030345 |
+----------+
db01 [test]>desc t100w;
+-------+-----------+------+-----+-------------------+-----------------------------+
| Field | Type | Null | Key | Default | Extra |
+-------+-----------+------+-----+-------------------+-----------------------------+
| id | int(11) | YES | | NULL | |
| num | int(11) | YES | | NULL | |
| k1 | char(2) | YES | | NULL | |
| k2 | char(4) | YES | | NULL | |
| dt | timestamp | NO | | CURRENT_TIMESTAMP | on update CURRENT_TIMESTAMP |
+-------+-----------+------+-----+-------------------+-----------------------------+
- 未作索引优化之前测试
模拟100个用户连接数据库,并作2000此查询
[root@db01 ~] mysqlslap --defaults-file=/etc/my.cnf \
--concurrency=100 --iterations=1 --create-schema='test' \
--query="select * from test.t100w where k2='MN89' engine=innodb \
--number-of-queries=2000 -uroot -p123 -verbose
结果:
mysqlslap: [Warning] Using a password on the command line interface can be insecure.
Benchmark
Running for engine rbose
Average number of seconds to run all queries: 755.861 seconds 平均的总访问时长
Minimum number of seconds to run all queries: 755.861 seconds
Maximum number of seconds to run all queries: 755.861 seconds
Number of clients running queries: 100
Average number of queries per client: 20
可在另一个窗口,打开数据库使用show processlist;查看模拟的情况
ps:部分数据
- 对查询的"k2"列建立索引
ALTER TABLE t100w add index idx_k2(k2);
- 索引优化后测试
[root@db01 ~] mysqlslap --defaults-file=/etc/my.cnf \
--concurrency=100 --iterations=1 --create-schema='test' \
--query="select * from test.t100w where k2='MN89' engine=innodb \
--number-of-queries=2000 -uroot -p123 -verbose
结果:
mysqlslap: [Warning] Using a password on the command line interface can be insecure.
Benchmark
Running for engine rbose
Average number of seconds to run all queries: 1.678 seconds 平均总的时长
Minimum number of seconds to run all queries: 1.678 seconds
Maximum number of seconds to run all queries: 1.678 seconds
Number of clients running queries: 100
Average number of queries per client: 20
可以看出,经过索引优化后,查询的效率大大的提高了。
7. 索引的应用规范
- 建表必须要有主键,一般是无关列,自增长
- 经常作为where的条件列、order by、group by、join on、distinct的条件列,将这些列建立索引
- 最好使用唯一值多的列作为联合索引前导列,其它的按照联合索引优化细节来做
- 列值长度较长的索引列,建议使用前缀索引
- 降低索引条目,一方面不要创建没用的索引,一方面要常清理不使用的索引;可以使用percona toolkit(xxxxx)工具来清理不常用的索引,或者使用sqlyog中“information”提示的多余索引的信息。
- 索引维护要避开业务繁忙期
- 小表不建索引
TIP:使用enum时,即使枚举的是字符串,但数据库中只会存储1、2、3…这种位置数据,这样就会占用很少的空间,所以以enum列的辅助索引就会很高效