集群基本配置
1、slaves配置
假设集群其他配置都配好了,这里提一个slaves配置。
cd /opt/module/hadoop-2.7.2/etc/hadoop
切换目录,找到slaves配置文件,打开
vim slaves
把机器配上
192.168.136.102
192.168.136.103
192.168.136.104
2、启动集群
这里提一点:
如果集群是第一次启动,需要格式化NameNode
切换到hadoop相应的目录下,敲以下命令
bin/hdfs namenode -format
datanode未启动的原因
启动集群,namenode正常启动而datanode却没有启动,jps命令查看没有datanode的进程。
原因是:当我们使用hdfs namenode -format格式化namenode时,会在namenode数据文件夹中保存一个current/VERSION文件,记录clusterID,而datanode中保存的current/VERSION文件中的clustreID的值是第一次格式化保存的clusterID,刚好有进行了一次格式化,在namenode的current/VERSION文件保存新的clusterID这样datanode和namenode之间的ID不一致。
简单总结:就是namenode的集群ID和datanode的集群ID不一致,导致只启动了namenode而未启动datanode
解决办法
1、切换到存放namenode和datanode数据文件的目录
cd data/tmp/dfs/
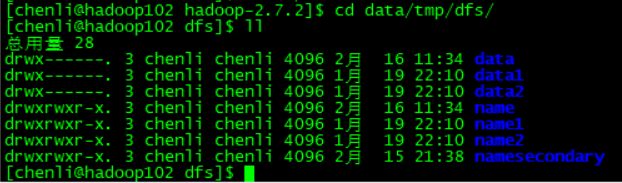
2、编辑文件
2.1 查看NameNode的集群ID
vim name/current/VERSION

这个是namenode的集群ID,把它复制下来,等会替换datanode的集群ID
2.2 打开DataNode的集群ID,用NameNode的集群ID去替换它
vim data/current/VERSION
注意
其他从节点机器也这样操作,全部替换成一样的。
版权声明:本文为weixin_42870497原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。