1、下载文件包:https://github.com/qqwweee/keras-yolo3
2、为此模型建立anaconda虚拟环境。
conda creat -n yolo python=3.6安装相应的环境,conda install 安装即可
版本号对应:
- python 3.6.9
- cuda 9.2
- cudnn 7.3.1
- tensorflow-gpu 1.12.0
- keras 2.2.4
3、安装依赖
pip install Pillow
pip install matplotlib
conda install ffmpeg
pip install opencv-contrib-python4、下载权重文件
https://pjreddie.com/media/files/yolov3.weights
也可以用命令行下载:
wget https://pjreddie.com/media/files/yolov3.weights如果特别慢可以百度网盘下载:链接:https://pan.baidu.com/s/1vFlOhClLDcyvUfu0JatVtA
提取码:k7lo
5、转化权重为keras模型
将权重文件转换成.h5文件(代码包中有convert.py文件负责,生成的.h5文件在model_data中)
命令行输入:
python convert.py yolov3.cfg yolov3.weights model_data/yolo.h5然后可以测试一下环境或者权重是否成功匹配好:
命令号输入:
python yolo_video.py --image然后输入图片名字(单张)
6、准备数据集
①建立一下名字和对应关系的文件夹
#在keras-yolo3下创建
VOCdevkit
└── VOC2012
├── Annotations (存标注好的xml文件,标注可用labelImg)
├── ImageSets
│ ├── Layout
│ ├── Main (存放4个txt文件,装着图片名字,train.txt test.txt trainval.txt val.txt预先建好)
│ └── Segmentation
├── JPEGImages (放图片)
└── labels没有备注的没用上。
②按比例分配测试图片和训练图片
写一个test.py用来分配1:9数据(Main中),执行完此程序Main中的四个txt文件中会有图片名字。
import os
import random
trainval_percent = 0.1
train_percent = 0.9
xmlfilepath = '/home/sys507/sun/VOCdevkit/VOC2012/Annotations'
txtsavepath = '/home/sys507/sun/VOCdevkit/VOC2012/ImageSets/Main'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open('/home/sys507/sun/VOCdevkit/VOC2012/ImageSets/Main/trainval.txt', 'w')
ftest = open('/home/sys507/sun/VOCdevkit/VOC2012/ImageSets/Main/test.txt', 'w')
ftrain = open('/home/sys507/sun/VOCdevkit/VOC2012/ImageSets/Main/train.txt', 'w')
fval = open('/home/sys507/sun/VOCdevkit/VOC2012/ImageSets/Main/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftest.write(name)
else:
fval.write(name)
else:
ftrain.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()③修该voc_annotation中的类别并执行此文件
修改成自己的类和对应的生成文件名字
修改完执行,可用pycharm直接执行,也可命令行
python voc_annotation.py执行后会在主目录生成3个txt文件
④生成适合自己数据的anchor
执行k-means.py文件,会在主目录生成yolo_anchor.txt文件。
⑤修改model_data中voc_classes.txt和coco_classes.txt中个的类别,换成自己的类别。
7、开始训练
先在主目录建立一个名字为logs的文件夹,然后在里面再建立一个名为000的文件夹,用于存储最后的权重。
修改train,py中对应路径、初始训练权重、batch尺寸、迭代次数 ,讯改完执行train.py文件,开始训练。最后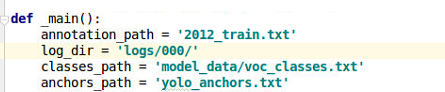

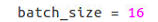

备注:也可以用以下代码替换带原有的train.py代码,这个就是全部层数都训练,源文件是先训练后三层(冻结前面249层),然后再训练全部层。但是这个代码有个缺点就是不能保存中间权重,只有最终权重。
"""
Retrain the YOLO model for your own dataset.
"""
import numpy as np
import keras.backend as K
from keras.layers import Input, Lambda
from keras.models import Model
from keras.callbacks import TensorBoard, ModelCheckpoint, EarlyStopping
from yolo3.model import preprocess_true_boxes, yolo_body, tiny_yolo_body, yolo_loss
from yolo3.utils import get_random_data
def _main():
annotation_path = '2012_train.txt'
log_dir = 'logs/000/'
classes_path = 'model_data/voc_classes.txt'
anchors_path = 'yolo_anchors.txt'
class_names = get_classes(classes_path)
anchors = get_anchors(anchors_path)
input_shape = (416, 416) # multiple of 32, hw
model = create_model(input_shape, anchors, len(class_names))
train(model, annotation_path, input_shape, anchors, len(class_names), log_dir=log_dir)
def train(model, annotation_path, input_shape, anchors, num_classes, log_dir='logs/'):
model.compile(optimizer='adam', loss={
'yolo_loss': lambda y_true, y_pred: y_pred})
logging = TensorBoard(log_dir=log_dir)
checkpoint = ModelCheckpoint(log_dir + "ep{epoch:03d}-loss{loss:.3f}-val_loss{val_loss:.3f}.h5",
monitor='val_loss', save_weights_only=True, save_best_only=True, period=1)
batch_size = 10
val_split = 0.05
with open(annotation_path) as f:
lines = f.readlines()
np.random.shuffle(lines)
num_val = int(len(lines) * val_split)
num_train = len(lines) - num_val
print('Train on {} samples, val on {} samples, with batch size {}.'.format(num_train, num_val, batch_size))
model.fit_generator(data_generator_wrap(lines[:num_train], batch_size, input_shape, anchors, num_classes),
steps_per_epoch=max(1, num_train // batch_size),
validation_data=data_generator_wrap(lines[num_train:], batch_size, input_shape, anchors,
num_classes),
validation_steps=max(1, num_val // batch_size),
epochs=200,
initial_epoch=0)
model.save_weights(log_dir + 'trained_weights.h5')
def get_classes(classes_path):
with open(classes_path) as f:
class_names = f.readlines()
class_names = [c.strip() for c in class_names]
return class_names
def get_anchors(anchors_path):
with open(anchors_path) as f:
anchors = f.readline()
anchors = [float(x) for x in anchors.split(',')]
return np.array(anchors).reshape(-1, 2)
def create_model(input_shape, anchors, num_classes, load_pretrained=False, freeze_body=False,
weights_path='trained_weights.h5'):
K.clear_session() # get a new session
image_input = Input(shape=(None, None, 3))
h, w = input_shape
num_anchors = len(anchors)
y_true = [Input(shape=(h // {0: 32, 1: 16, 2: 8}[l], w // {0: 32, 1: 16, 2: 8}[l], \
num_anchors // 3, num_classes + 5)) for l in range(3)]
model_body = yolo_body(image_input, num_anchors // 3, num_classes)
print('Create YOLOv3 model with {} anchors and {} classes.'.format(num_anchors, num_classes))
if load_pretrained:
model_body.load_weights(weights_path, by_name=True, skip_mismatch=True)
print('Load weights {}.'.format(weights_path))
if freeze_body:
# Do not freeze 3 output layers.
num = len(model_body.layers) - 7
for i in range(num): model_body.layers[i].trainable = False
print('Freeze the first {} layers of total {} layers.'.format(num, len(model_body.layers)))
model_loss = Lambda(yolo_loss, output_shape=(1,), name='yolo_loss',
arguments={'anchors': anchors, 'num_classes': num_classes, 'ignore_thresh': 0.5})(
[*model_body.output, *y_true])
model = Model([model_body.input, *y_true], model_loss)
return model
def data_generator(annotation_lines, batch_size, input_shape, anchors, num_classes):
n = len(annotation_lines)
np.random.shuffle(annotation_lines)
i = 0
while True:
image_data = []
box_data = []
for b in range(batch_size):
i %= n
image, box = get_random_data(annotation_lines[i], input_shape, random=True)
image_data.append(image)
box_data.append(box)
i += 1
image_data = np.array(image_data)
box_data = np.array(box_data)
y_true = preprocess_true_boxes(box_data, input_shape, anchors, num_classes)
yield [image_data, *y_true], np.zeros(batch_size)
def data_generator_wrap(annotation_lines, batch_size, input_shape, anchors, num_classes):
n = len(annotation_lines)
if n == 0 or batch_size <= 0: return None
return data_generator(annotation_lines, batch_size, input_shape, anchors, num_classes)
if __name__ == '__main__':
_main()如果报错:
Hint: If you want to see a list of allocated tensors when OOM happens, add report_tensor_allocations_upon_oom to RunOptions for current allocation info.就是显存不足,改小batch,如果改到1还是不行,那就是环境有问题了。
8、测试图片并计算mAP
①下载测试文件包:https://github.com/Cartucho/mAP
如果慢可以百度网盘下载:链接:https://pan.baidu.com/s/1dyG_0UpziwNfjBO4xbOEyA
提取码:yzqw
复制这段内容后打开百度网盘手机App,操作更方便哦
②准备测试数据
--mAP
--input
--images-optional 放测试图片
--ground-truth 放图片对应的xml文件
--detection-results 放测试结果(程序生成)执行:
cd mAP/scripts/extra
python convert_gt_xml.py用于提取xml中的数据变成txt。代码运行完后,测试数据的GT坐标会保存在对应的txt文件内,XML文件会另存在目录中的backup文件夹内;
③建立检测文件yolo_detect.py并修改参数
建立yolo_detect.py文件,放在主目录下,与yolo.py同级。
代码如下:
# -*- coding: utf-8 -*-
"""
Class definition of YOLO_v3 style detection model on image and video
"""
import colorsys
import os
import sys
from timeit import default_timer as timer
import numpy as np
from keras import backend as K
from keras.models import load_model
from keras.layers import Input
from PIL import Image, ImageFont, ImageDraw
from yolo3.model import yolo_eval, yolo_body, tiny_yolo_body
from yolo3.utils import letterbox_image
import os
from keras.utils import multi_gpu_model
class YOLO(object):
_defaults = {
"model_path": 'trained_weights.h5', ##训练好的模型的路径
"anchors_path": 'yolo_anchors.txt',
"classes_path": 'model_data/voc_classes.txt',
"score" : 0.3,
"iou" : 0.45,
"model_image_size" : (416, 416),
"gpu_num" : 1
}
@classmethod
def get_defaults(cls, n):
if n in cls._defaults:
return cls._defaults[n]
else:
return "Unrecognized attribute name '" + n + "'"
def __init__(self, **kwargs):
self.__dict__.update(self._defaults) # set up default values
self.__dict__.update(kwargs) # and update with user overrides
self.class_names = self._get_class()
self.anchors = self._get_anchors()
self.sess = K.get_session()
self.boxes, self.scores, self.classes = self.generate()
def _get_class(self):
classes_path = os.path.expanduser(self.classes_path)
with open(classes_path) as f:
class_names = f.readlines()
class_names = [c.strip() for c in class_names]
print('classes:{}'.format(class_names))
return class_names
def _get_anchors(self):
anchors_path = os.path.expanduser(self.anchors_path)
with open(anchors_path) as f:
anchors = f.readline()
anchors = [float(x) for x in anchors.split(',')]
return np.array(anchors).reshape(-1, 2)
def generate(self):
model_path = os.path.expanduser(self.model_path)
assert model_path.endswith('.h5'), 'Keras model or weights must be a .h5 file.'
# Load model, or construct model and load weights.
num_anchors = len(self.anchors)
num_classes = len(self.class_names)
is_tiny_version = num_anchors==6 # default setting
try:
self.yolo_model = load_model(model_path, compile=False)
except:
self.yolo_model = tiny_yolo_body(Input(shape=(None,None,3)), num_anchors//2, num_classes) \
if is_tiny_version else yolo_body(Input(shape=(None,None,3)), num_anchors//3, num_classes)
self.yolo_model.load_weights(self.model_path) # make sure model, anchors and classes match
else:
assert self.yolo_model.layers[-1].output_shape[-1] == \
num_anchors/len(self.yolo_model.output) * (num_classes + 5), \
'Mismatch between model and given anchor and class sizes'
print('{} model, anchors, and classes loaded.'.format(model_path))
# Generate colors for drawing bounding boxes.
hsv_tuples = [(x / len(self.class_names), 1., 1.)
for x in range(len(self.class_names))]
self.colors = list(map(lambda x: colorsys.hsv_to_rgb(*x), hsv_tuples))
self.colors = list(
map(lambda x: (int(x[0] * 255), int(x[1] * 255), int(x[2] * 255)),
self.colors))
np.random.seed(10101) # Fixed seed for consistent colors across runs.
np.random.shuffle(self.colors) # Shuffle colors to decorrelate adjacent classes.
np.random.seed(None) # Reset seed to default.
# Generate output tensor targets for filtered bounding boxes.
self.input_image_shape = K.placeholder(shape=(2, ))
if self.gpu_num>=2:
self.yolo_model = multi_gpu_model(self.yolo_model, gpus=self.gpu_num)
boxes, scores, classes = yolo_eval(self.yolo_model.output, self.anchors,
len(self.class_names), self.input_image_shape,
score_threshold=self.score, iou_threshold=self.iou)
return boxes, scores, classes
def detect_image(self, image):
start = timer()
if self.model_image_size != (None, None):
assert self.model_image_size[0]%32 == 0, 'Multiples of 32 required'
assert self.model_image_size[1]%32 == 0, 'Multiples of 32 required'
boxed_image = letterbox_image(image, tuple(reversed(self.model_image_size)))
else:
new_image_size = (image.width - (image.width % 32),
image.height - (image.height % 32))
boxed_image = letterbox_image(image, new_image_size)
image_data = np.array(boxed_image, dtype='float32')
print(image_data.shape)
image_data /= 255.
image_data = np.expand_dims(image_data, 0) # Add batch dimension.
out_boxes, out_scores, out_classes = self.sess.run(
[self.boxes, self.scores, self.classes],
feed_dict={
self.yolo_model.input: image_data,
self.input_image_shape: [image.size[1], image.size[0]],
K.learning_phase(): 0
})
print('Found {} boxes for {}'.format(len(out_boxes), 'img'))
font = ImageFont.truetype(font='font/FiraMono-Medium.otf',
size=np.floor(3e-2 * image.size[1] + 0.5).astype('int32'))
thickness = (image.size[0] + image.size[1]) // 300
for i, c in reversed(list(enumerate(out_classes))):
predicted_class = self.class_names[c]
box = out_boxes[i]
score = out_scores[i]
label = '{} {:.2f}'.format(predicted_class, score)
draw = ImageDraw.Draw(image)
label_size = draw.textsize(label, font)
top, left, bottom, right = box
top = max(0, np.floor(top + 0.5).astype('int32'))
left = max(0, np.floor(left + 0.5).astype('int32'))
bottom = min(image.size[1], np.floor(bottom + 0.5).astype('int32'))
right = min(image.size[0], np.floor(right + 0.5).astype('int32'))
print(label, (left, top), (right, bottom))
#new_f=open("/home/shan/xws/pro/keras-yolo3/detection-results/"+tmp_file.replace(".jpg", ".txt"), "a")
new_f.write("%s %s %s %s %s\n" % (label, left, top, right, bottom))
if top - label_size[1] >= 0:
text_origin = np.array([left, top - label_size[1]])
else:
text_origin = np.array([left, top + 1])
# My kingdom for a good redistributable image drawing library.
for i in range(thickness):
draw.rectangle(
[left + i, top + i, right - i, bottom - i],
outline=self.colors[c])
draw.rectangle(
[tuple(text_origin), tuple(text_origin + label_size)],
fill=self.colors[c])
draw.text(text_origin, label, fill=(0, 0, 0), font=font)
del draw
end = timer()
print(end - start)
return image
def close_session(self):
self.sess.close()
if __name__ == '__main__':
# yolo=YOLO()
# path = '1.jpg'
# try:
# image = Image.open(path)
# except:
# print('Open Error! Try again!')
# else:
# r_image = yolo.detect_image(image)
# r_image.show()
# yolo.close_session()
#strat1=timer()
dirname="/home/sys507/sun/mAP-master/input/images-optional/" ##该目录为测试照片的存储路径,每次测试照片的数量可以自己设定
path=os.path.join(dirname)
pic_list=os.listdir(path)
count=0
yolo=YOLO()
for filename in pic_list:
tmp_file=pic_list[count]
new_f=open("/home/sys507/sun/mAP-master/input/detection-results/"+tmp_file.replace(".jpg", ".txt"), "a") #预测坐标生成txt文件保存的路径
abs_path=path+pic_list[count]
image = Image.open(abs_path)
r_image = yolo.detect_image(image)
count=count+1
#end1=timer()
print(count)
yolo.close_session()
修改路径等参数。
④执行yolo_detect.py
python yolo_detect.py测试完后将测试结果(.txt)保存在mAP项目的input/detection-results文件夹下。
⑤计算mAP保存检测图片(带框)
执行main.py文件即可:
python main.py测试结果会自动保存在result目录下(各种数据图什么的)
另:
①如果想直接测试图片,可以使用一下代码:
# -*- coding: utf-8 -*-
"""
功能:keras-yolov3 进行批量测试 并 保存结果
项目来源:https://github.com/qqwweee/keras-yolo3
"""
import colorsys
import os
from timeit import default_timer as timer
import time
import numpy as np
from keras import backend as K
from keras.models import load_model
from keras.layers import Input
from PIL import Image, ImageFont, ImageDraw
from yolo3.model import yolo_eval, yolo_body, tiny_yolo_body
from yolo3.utils import letterbox_image
from keras.utils import multi_gpu_model
#path = '2012_test.txt'
path = 'model_data/test/' # 待检测图片的位置
# 创建创建一个存储检测结果的dir
result_path = 'model_data/result'
if not os.path.exists(result_path):
os.makedirs(result_path)
# result如果之前存放的有文件,全部清除
for i in os.listdir(result_path):
path_file = os.path.join(result_path, i)
if os.path.isfile(path_file):
os.remove(path_file)
# 创建一个记录检测结果的文件
txt_path = result_path + '/result.txt'
file = open(txt_path, 'w')
class YOLO(object):
_defaults = {
"model_path": 'model_data/trained_weights_final.h5',
"anchors_path": 'model_data/yolo_anchors.txt',
"classes_path": 'model_data/voc_classes.txt',
"score": 0.3,
"iou": 0.45,
"model_image_size": (416, 416),
"gpu_num": 1,
}
@classmethod
def get_defaults(cls, n):
if n in cls._defaults:
return cls._defaults[n]
else:
return "Unrecognized attribute name '" + n + "'"
def __init__(self, **kwargs):
self.__dict__.update(self._defaults) # set up default values
self.__dict__.update(kwargs) # and update with user overrides
self.class_names = self._get_class()
self.anchors = self._get_anchors()
self.sess = K.get_session()
self.boxes, self.scores, self.classes = self.generate()
def _get_class(self):
classes_path = os.path.expanduser(self.classes_path)
with open(classes_path) as f:
class_names = f.readlines()
class_names = [c.strip() for c in class_names]
return class_names
def _get_anchors(self):
anchors_path = os.path.expanduser(self.anchors_path)
with open(anchors_path) as f:
anchors = f.readline()
anchors = [float(x) for x in anchors.split(',')]
return np.array(anchors).reshape(-1, 2)
def generate(self):
model_path = os.path.expanduser(self.model_path)
assert model_path.endswith('.h5'), 'Keras model or weights must be a .h5 file.'
# Load model, or construct model and load weights.
num_anchors = len(self.anchors)
num_classes = len(self.class_names)
is_tiny_version = num_anchors == 6 # default setting
try:
self.yolo_model = load_model(model_path, compile=False)
except:
self.yolo_model = tiny_yolo_body(Input(shape=(None, None, 3)), num_anchors // 2, num_classes) \
if is_tiny_version else yolo_body(Input(shape=(None, None, 3)), num_anchors // 3, num_classes)
self.yolo_model.load_weights(self.model_path) # make sure model, anchors and classes match
else:
assert self.yolo_model.layers[-1].output_shape[-1] == \
num_anchors / len(self.yolo_model.output) * (num_classes + 5), \
'Mismatch between model and given anchor and class sizes'
print('{} model, anchors, and classes loaded.'.format(model_path))
# Generate colors for drawing bounding boxes.
hsv_tuples = [(x / len(self.class_names), 1., 1.)
for x in range(len(self.class_names))]
self.colors = list(map(lambda x: colorsys.hsv_to_rgb(*x), hsv_tuples))
self.colors = list(
map(lambda x: (int(x[0] * 255), int(x[1] * 255), int(x[2] * 255)),
self.colors))
np.random.seed(10101) # Fixed seed for consistent colors across runs.
np.random.shuffle(self.colors) # Shuffle colors to decorrelate adjacent classes.
np.random.seed(None) # Reset seed to default.
# Generate output tensor targets for filtered bounding boxes.
self.input_image_shape = K.placeholder(shape=(2,))
if self.gpu_num >= 2:
self.yolo_model = multi_gpu_model(self.yolo_model, gpus=self.gpu_num)
boxes, scores, classes = yolo_eval(self.yolo_model.output, self.anchors,
len(self.class_names), self.input_image_shape,
score_threshold=self.score, iou_threshold=self.iou)
return boxes, scores, classes
def detect_image(self, image):
start = timer() # 开始计时
if self.model_image_size != (None, None):
assert self.model_image_size[0] % 32 == 0, 'Multiples of 32 required'
assert self.model_image_size[1] % 32 == 0, 'Multiples of 32 required'
boxed_image = letterbox_image(image, tuple(reversed(self.model_image_size)))
else:
new_image_size = (image.width - (image.width % 32),
image.height - (image.height % 32))
boxed_image = letterbox_image(image, new_image_size)
image_data = np.array(boxed_image, dtype='float32')
print(image_data.shape) # 打印图片的尺寸
image_data /= 255.
image_data = np.expand_dims(image_data, 0) # Add batch dimension.
out_boxes, out_scores, out_classes = self.sess.run(
[self.boxes, self.scores, self.classes],
feed_dict={
self.yolo_model.input: image_data,
self.input_image_shape: [image.size[1], image.size[0]],
K.learning_phase(): 0
})
print('Found {} boxes for {}'.format(len(out_boxes), 'img')) # 提示用于找到几个bbox
font = ImageFont.truetype(font='font/FiraMono-Medium.otf',
size=np.floor(2e-2 * image.size[1] + 0.2).astype('int32'))
thickness = (image.size[0] + image.size[1]) // 500
# 保存框检测出的框的个数
file.write('find ' + str(len(out_boxes)) + ' target(s) \n')
for i, c in reversed(list(enumerate(out_classes))):
predicted_class = self.class_names[c]
box = out_boxes[i]
score = out_scores[i]
label = '{} {:.2f}'.format(predicted_class, score)
draw = ImageDraw.Draw(image)
label_size = draw.textsize(label, font)
top, left, bottom, right = box
top = max(0, np.floor(top + 0.5).astype('int32'))
left = max(0, np.floor(left + 0.5).astype('int32'))
bottom = min(image.size[1], np.floor(bottom + 0.5).astype('int32'))
right = min(image.size[0], np.floor(right + 0.5).astype('int32'))
# 写入检测位置
file.write(
predicted_class + ' score: ' + str(score) + ' \nlocation: top: ' + str(top) + '、 bottom: ' + str(
bottom) + '、 left: ' + str(left) + '、 right: ' + str(right) + '\n')
print(label, (left, top), (right, bottom))
if top - label_size[1] >= 0:
text_origin = np.array([left, top - label_size[1]])
else:
text_origin = np.array([left, top + 1])
# My kingdom for a good redistributable image drawing library.
for i in range(thickness):
draw.rectangle(
[left + i, top + i, right - i, bottom - i],
outline=self.colors[c])
draw.rectangle(
[tuple(text_origin), tuple(text_origin + label_size)],
fill=self.colors[c])
draw.text(text_origin, label, fill=(0, 0, 0), font=font)
del draw
end = timer()
print('time consume:%.3f s ' % (end - start))
return image
def close_session(self):
self.sess.close()
# 图片检测
if __name__ == '__main__':
t1 = time.time()
yolo = YOLO()
for filename in os.listdir(path):
image_path = path + '/' + filename
portion = os.path.split(image_path)
file.write(portion[1] + ' detect_result:\n')
image = Image.open(image_path)
r_image = yolo.detect_image(image)
file.write('\n')
#r_image.show() #显示检测结果
image_save_path = 'model_data/result/result_' + portion[1]
print('detect result save to....:' + image_save_path)
r_image.save(image_save_path)
time_sum = time.time() - t1
file.write('time sum: ' + str(time_sum) + 's')
print('time sum:', time_sum)
file.close()
yolo.close_session()②可能遇到的错误:
1)权重转化的时候报错:
Traceback (most recent call last):
File "convert.py", line 262, in <module>
_main(parser.parse_args())
File "convert.py", line 83, in _main
unique_config_file = unique_config_sections(config_path)
File "convert.py", line 53, in unique_config_sections
output_stream.write(line)
TypeError: unicode argument expected, got 'str'修改办法:
头添加:outputstream=io.StringIO
output_stream = io.StringIO()
改成
output_stream = io.BytesIO()2)也是权重转化时报错:
File "convert.py", line 22
SyntaxError: Non-ASCII character '\xe6' in file convert.py on line 22, but no encoding declared; see http://python.org/dev/peps/pep-0263/ for details修改办法:
在头文件前加入:(中文问题)
# -*- coding: utf-8 -*3)试验运行yolo.py时报错:
Traceback (most recent call last):
File "yolo.py", line 19, in <module>
from keras.utils import multi_gpu_model
ImportError: cannot import name multi_gpu_model解决办法:
备注上:#from keras.utils import multi_gpu_model
或者:pip install git+git://github.com/fchollet/keras.git --upgrade
升级keras版本。4)执行python voc_annotation时报错:
Traceback (most recent call last):
File "voc_annotation.py", line 31, in <module>
convert_annotation(year, image_id, list_file)
File "voc_annotation.py", line 15, in convert_annotation
difficult = obj.find('difficult').text
AttributeError: 'NoneType' object has no attribute 'text'解决办法:
difficult中的D大写,原xml中是大写的。
然后在运行,主目录会多三个txt文档。或者把带difficult的都备注掉。
5)执行python voc_annotation时报错:
ValueError: invalid literal for int() with base 10: '45.70000076293945'解决办法:
原因是数字字符串不能直接转int类型,需要转为float类型后才能转int类型:
b = (int(float(xmlbox.find('xmin').text)), int(float(xmlbox.find('ymin').text)),
int(float(xmlbox.find('xmax').text)), int(float(xmlbox.find('ymax').text)))6)测试时报错:
v2.error: OpenCV(3.4.2) /tmp/build/80754af9/opencv-suite_1535558553474/work/modules/highgui/src/window.cpp:632: error: (-2:Unspecified error) The function is not implemented. Rebuild the library with Windows, GTK+ 2.x or Carbon support. If you are on Ubuntu or Debian, install libgtk2.0-dev and pkg-config, then re-run cmake or configure script in function 'cvShowImage'解决办法:
sudo apt-get install build-essential cmake libgtk2.0-dev libtiff4-dev libjasper-dev libavformat-dev libswscale-dev libavcodec-dev libjpeg62-dev pkg-config ffmpeg又报错:
正在读取软件包列表... 完成
正在分析软件包的依赖关系树
正在读取状态信息... 完成
没有可用的软件包 libtiff4-dev,但是它被其它的软件包引用了。
这可能意味着这个缺失的软件包可能已被废弃,
或者只能在其他发布源中找到
然而下列软件包会取代它:
libtiff5-dev:i386 libtiff5-dev
E: 软件包 libtiff4-dev 没有可安装候选解决办法:
重新安装opencv
删除XML文件中某些类别的对应信息代码:
import xml.etree.cElementTree as ET
import os
path_root = ['/home/sys507/sun/VOCdevkit/VOC2012/Annotations']
CLASSES = [ "traindoor"]
for anno_path in path_root:
xml_list = os.listdir(anno_path)
for axml in xml_list:
path_xml = os.path.join(anno_path, axml)
tree = ET.parse(path_xml)
root = tree.getroot()
for child in root.findall('object'):
name = child.find('name').text
if not name in CLASSES:
root.remove(child)
tree.write(os.path.join('/home/sys507/sun/VOCdevkit/VOC2012/A', axml))mAP参考:https://blog.csdn.net/plSong_CSDN/article/details/89502117