AOP 实现多数据源切换
1、数据源配置
# 数据源配置
spring:
datasource:
type: com.alibaba.druid.pool.DruidDataSource
driverClassName: com.mysql.cj.jdbc.Driver
druid:
# 主库数据源
master:
url: jdbc:mysql://localhost:3306/ruoyi?useUnicode=true&characterEncoding=utf8&zeroDateTimeBehavior=convertToNull&useSSL=true&serverTimezone=GMT%2B8
username: root
password: root
# 从库数据源
slave:
# 从数据源开关/默认关闭
enabled: true
url: jdbc:mysql://localhost:3307/ruoyi?useUnicode=true&characterEncoding=utf8&zeroDateTimeBehavior=convertToNull&useSSL=true&serverTimezone=GMT%2B8
username: root
password: root
# 初始连接数
initialSize: 5
# 最小连接池数量
minIdle: 10
# 最大连接池数量
maxActive: 20
其中,enabled 参数控制是否开启从库
2、数据库配置文件
/**
* druid 配置多数据源
*/
@Configuration
public class DruidConfig
{
@Bean
@ConfigurationProperties("spring.datasource.druid.master")
public DataSource masterDataSource(DruidProperties druidProperties)
{
DruidDataSource dataSource = DruidDataSourceBuilder.create().build();
return druidProperties.dataSource(dataSource);
}
@Bean
@ConfigurationProperties("spring.datasource.druid.slave")
@ConditionalOnProperty(prefix = "spring.datasource.druid.slave", name = "enabled", havingValue = "true")
public DataSource slaveDataSource(DruidProperties druidProperties)
{
DruidDataSource dataSource = DruidDataSourceBuilder.create().build();
return druidProperties.dataSource(dataSource);
}
@Bean(name = "dynamicDataSource")
@Primary
public DynamicDataSource dataSource(DataSource masterDataSource)
{
Map<Object, Object> targetDataSources = new HashMap<>();
targetDataSources.put(DataSourceType.MASTER.name(), masterDataSource);
setDataSource(targetDataSources, DataSourceType.SLAVE.name(), "slaveDataSource");
return new DynamicDataSource(masterDataSource, targetDataSources);
}
/**
* 设置数据源
*
* @param targetDataSources 备选数据源集合
* @param sourceName 数据源名称
* @param beanName bean名称
*/
public void setDataSource(Map<Object, Object> targetDataSources, String sourceName, String beanName)
{
try
{
DataSource dataSource = SpringUtils.getBean(beanName);
targetDataSources.put(sourceName, dataSource);
}
catch (Exception e)
{
}
}
}
1、获取配置文件中 spring.datasource.druid.master 的数据并封装到 DruidProperties 中,并借此创建 master数据源。
2、@ConditionalOnProperty 条件注解判断 配置文件中 spring.datasource.druid.slave 的 enabled 参数为 true 的时候才创建 slave 数据源。
3、创建 Map<Object, Object> 来收集数据源,key 为数据源的名称,value 就是上面创建的数据源。
public enum DataSourceType
{
/**
* 主库
*/
MASTER,
/**
* 从库
*/
SLAVE
}
补充知识点:@Primary 注解
当一个接口有2个不同实现时,使用@Autowired注解时会报NoUniqueBeanDefinitionException异常信息
方案1:使用@Qualifier注解,选择一个对象的名称,通常比较常用
方案2:@Primary 注解,默认优先选择,同时不可以同时设置多个,内部实质是设置BeanDefinition的primary属性
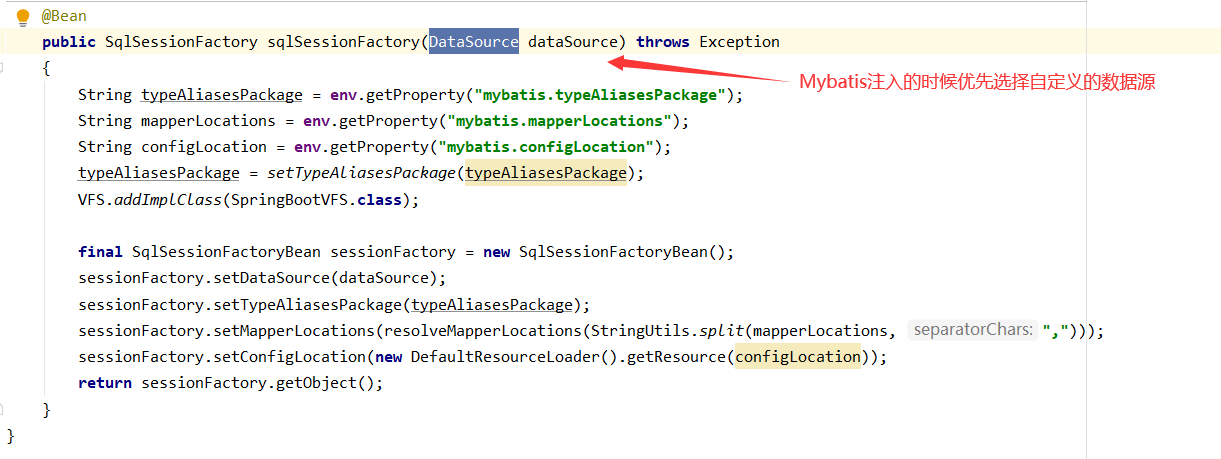
4、创建自定义数据源DynamicDataSource,参数为master数据源 和 Map 数据源集合
/**
* 动态数据源
*/
public class DynamicDataSource extends AbstractRoutingDataSource
{
public DynamicDataSource(DataSource defaultTargetDataSource, Map<Object, Object> targetDataSources)
{
// 设置默认数据源
super.setDefaultTargetDataSource(defaultTargetDataSource);
// 设置数据源集合
super.setTargetDataSources(targetDataSources);
super.afterPropertiesSet();
}
@Override
protected Object determineCurrentLookupKey()
{
return DynamicDataSourceContextHolder.getDataSourceType();
}
}
自定义数据源继承自 可路由的数据源AbstractRoutingDataSource
源码分析:
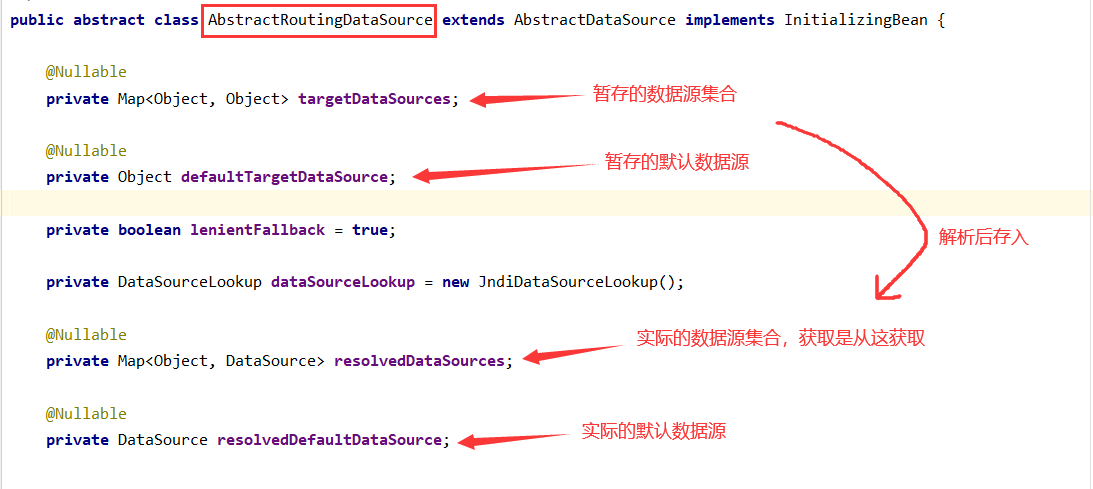
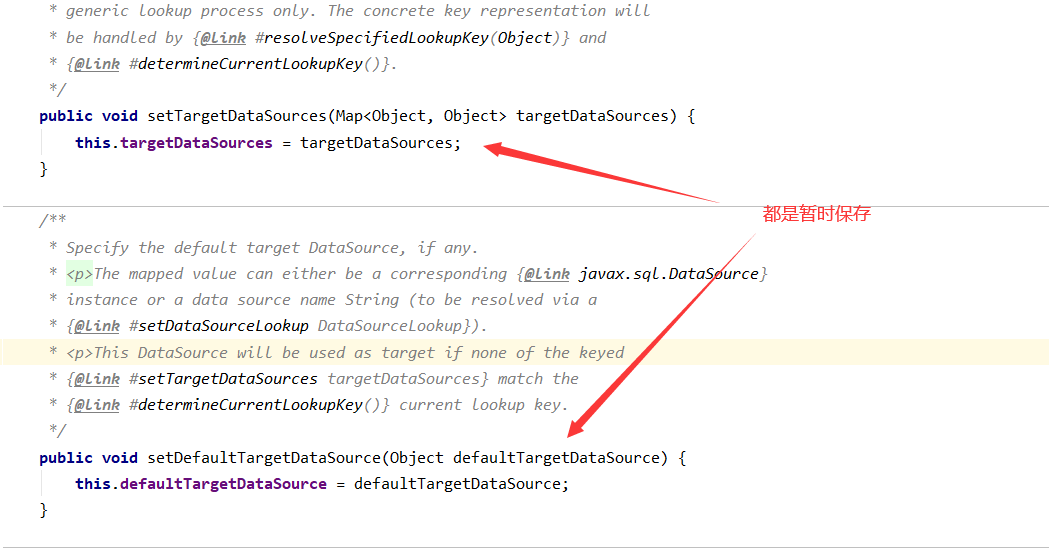
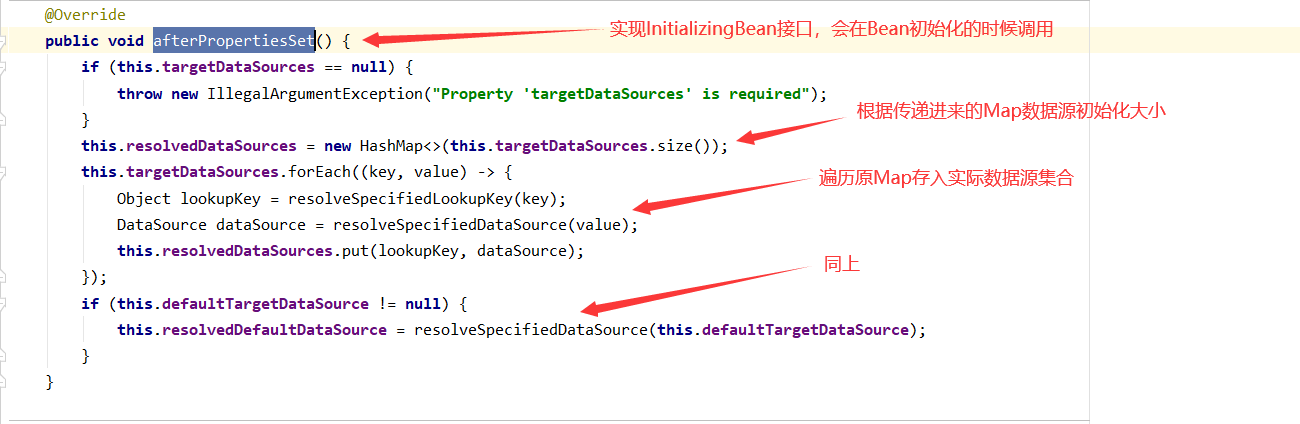
数据源保存完毕!之后如果要获取连接会来这个数据源,不要忘了!
3、自定义注解实现数据源动态切换
1、自定义多数据源切换注解
/**
* 自定义多数据源切换注解
*
* 优先级:先方法,后类,如果方法覆盖了类上的数据源类型,以方法的为准,否则以类上的为准
*/
@Target({ ElementType.METHOD, ElementType.TYPE })
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Inherited
public @interface DataSource
{
/**
* 切换数据源名称,默认选择Master数据源
*/
public DataSourceType value() default DataSourceType.MASTER;
}
2、在增删改查的时候能指定选择数据源
@RequiresPermissions("system:dept:list")
@PostMapping("/list")
@ResponseBody
@DataSource(value = DataSourceType.SLAVE)
public List<SysDept> list(SysDept dept)
{
List<SysDept> deptList = deptService.selectDeptList(dept);
return deptList;
}
3、当方法或者类上标注 @DataSource 注解的时候会被 AOP 捕获并进行增强
/**
* 多数据源处理
*/
@Aspect
@Order(1)
@Component
public class DataSourceAspect
{
protected Logger logger = LoggerFactory.getLogger(getClass());
@Pointcut("@annotation(com.ruoyi.common.annotation.DataSource)"
+ "|| @within(com.ruoyi.common.annotation.DataSource)")
public void dsPointCut()
{
}
@Around("dsPointCut()")
public Object around(ProceedingJoinPoint point) throws Throwable
{
DataSource dataSource = getDataSource(point);
if (StringUtils.isNotNull(dataSource))
{
DynamicDataSourceContextHolder.setDataSourceType(dataSource.value().name());
}
try
{
return point.proceed();
}
finally
{
// 销毁数据源 在执行方法之后
DynamicDataSourceContextHolder.clearDataSourceType();
}
}
/**
* 获取需要切换的数据源
*/
public DataSource getDataSource(ProceedingJoinPoint point)
{
MethodSignature signature = (MethodSignature) point.getSignature();
// 现在方法上查询注解,查询到直接返回
DataSource dataSource = AnnotationUtils.findAnnotation(signature.getMethod(), DataSource.class);
if (Objects.nonNull(dataSource))
{
return dataSource;
}
// 如果方法不存在,则查询类上的注解,因为是从 PointCut 切点进来的,所以肯定存在 @DataSource
return AnnotationUtils.findAnnotation(signature.getDeclaringType(), DataSource.class);
}
}
其中有两个知识点,为不打乱节奏补充在文章末尾!
4、增强:修改数据源
具体实现:
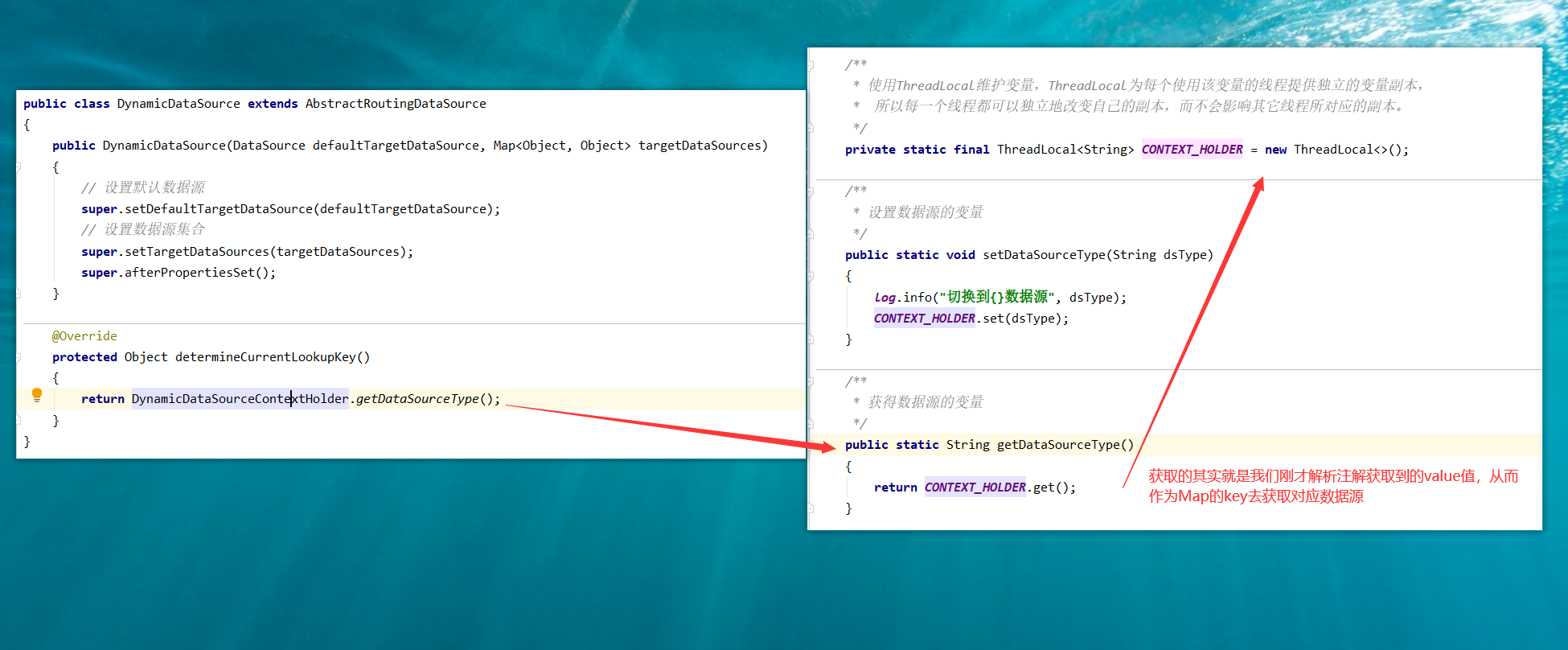
1、解析DataSource注解获取value值
2、将获取到的value,也就是数据源的key存入到一个 ThreadLocal 变量中
/**
* 数据源切换处理
*/
public class DynamicDataSourceContextHolder
{
public static final Logger log = LoggerFactory.getLogger(DynamicDataSourceContextHolder.class);
/**
* 使用ThreadLocal维护变量,ThreadLocal为每个使用该变量的线程提供独立的变量副本,
* 所以每一个线程都可以独立地改变自己的副本,而不会影响其它线程所对应的副本。
*/
private static final ThreadLocal<String> CONTEXT_HOLDER = new ThreadLocal<>();
/**
* 设置数据源的变量
*/
public static void setDataSourceType(String dsType)
{
log.info("切换到{}数据源", dsType);
CONTEXT_HOLDER.set(dsType);
}
/**
* 获得数据源的变量
*/
public static String getDataSourceType()
{
return CONTEXT_HOLDER.get();
}
/**
* 清空数据源变量
*/
public static void clearDataSourceType()
{
CONTEXT_HOLDER.remove();
}
}
3、当Mybatis执行数据操作,会从刚才我们自定义的数据源DynamicDataSource中获取Connection,DynamicDataSource没有实现这个方法,会调用其父类AbstractRoutingDataSource的方法,让我们在回到源码:
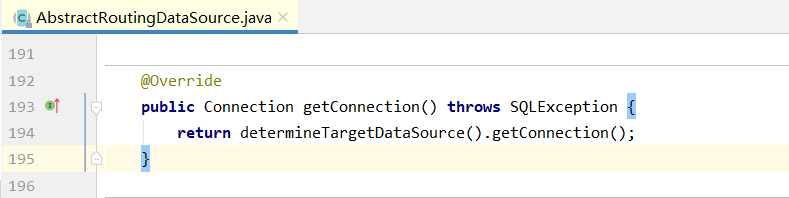
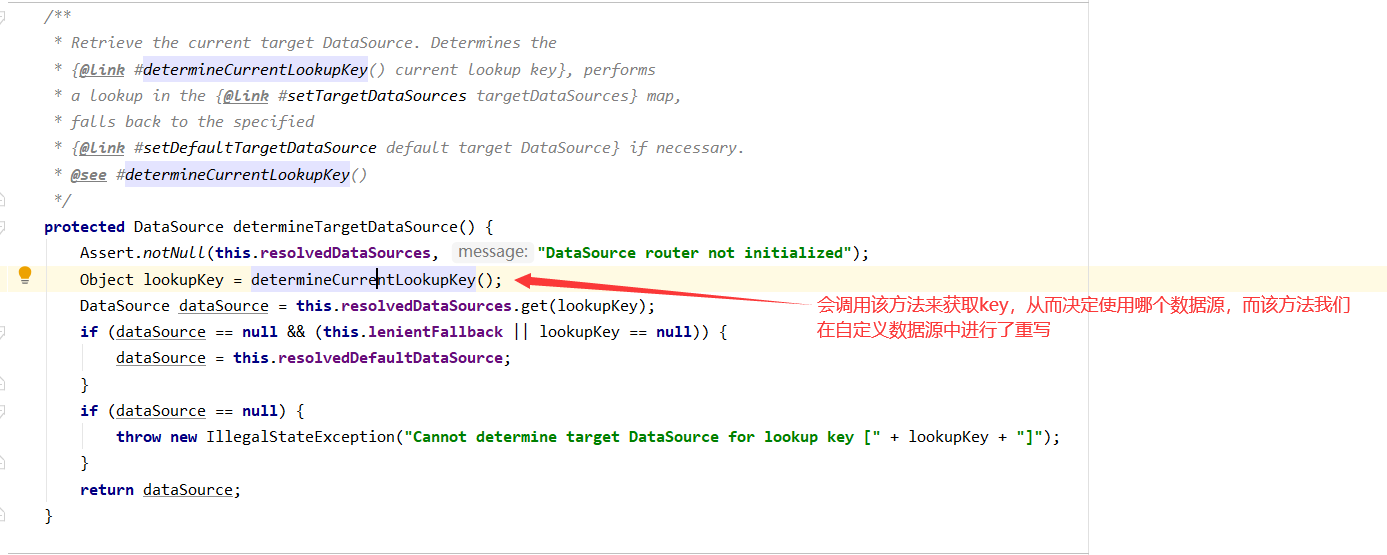
调用重载的方法获取数据源的key,从而实现动态切换数据源
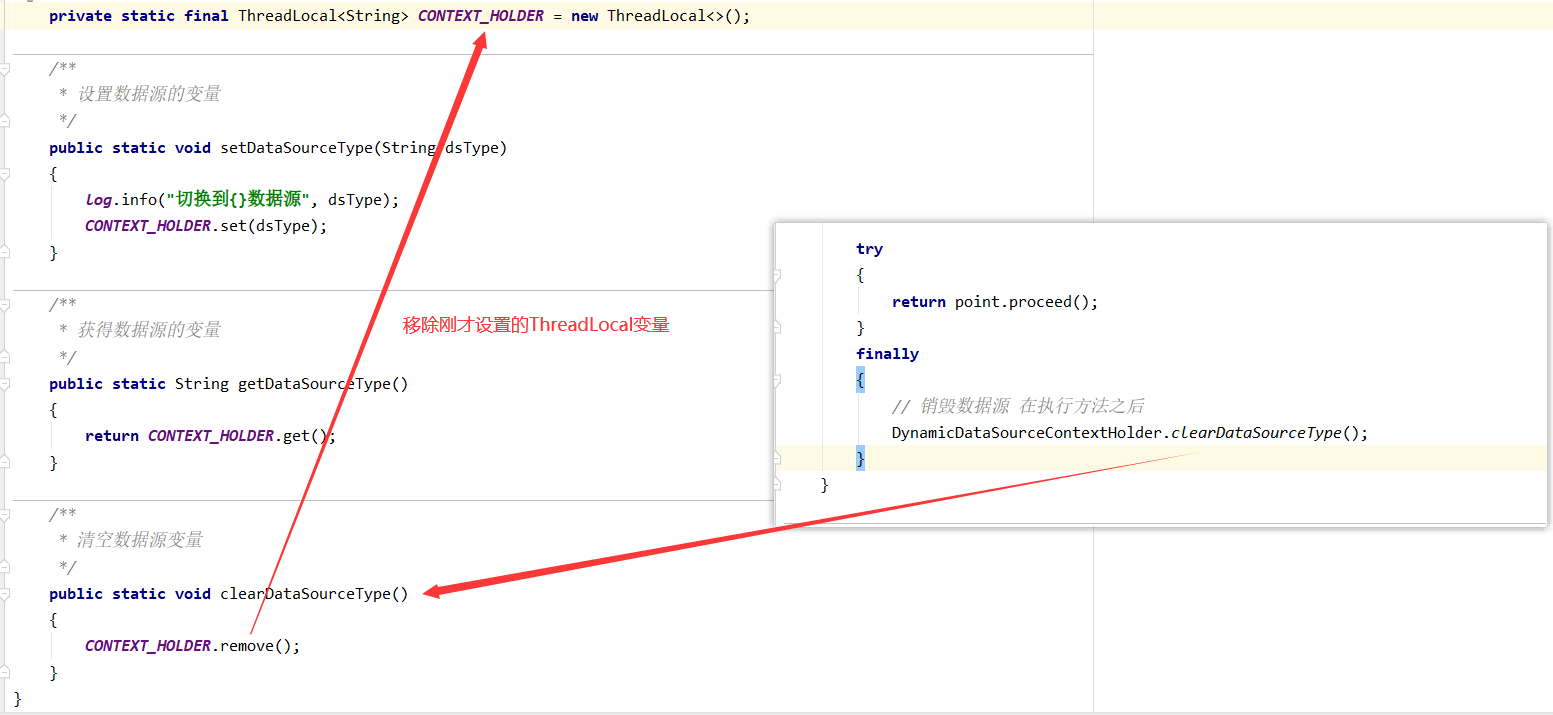
4、当数据库操作执行完毕后清空数据源变量,也就是将刚才的 ThreadLocal值 删除掉。
到此,AOP实现多数据源切换完毕!
知识点补充
知识点1:@Order(1) 注解
1、Spring 4.2利用@Order控制配置类的加载顺序;
2、Spring在加载Bean的时候,有用到Order注解;
3、通过@Order指定执行顺序,值越小,越先执行;
4、@Order注解常用于定义的AOP先于事物执行;
5、Order如果不标注数字,默认最低优先级,因为其默认值是int最大值。
那为什么需要这个注解来控制加载顺序呢?我们设想一种场景:
当我们想做基于 AOP 的多数据源切换 和 基于 AOP 的日志自动记录 这两个功能时遇到了这个问题,就是当两个或多个aop同时作用于同一个方法时的执行顺序是什么。答案是,根据这个切面的设定顺序,这个设定的顺序越小则越先执行,目前设定顺序主要有三种方式:
1、实现org.springframework.core.Ordered接口,重写getOrder方法。
2、使用Order注解指定顺序。
3、通过配置文件配置设定顺序。
<aop:config expose-proxy="true">
<aop:aspect ref="aopBean" order="0">
</aop:aspect>
</aop:config>
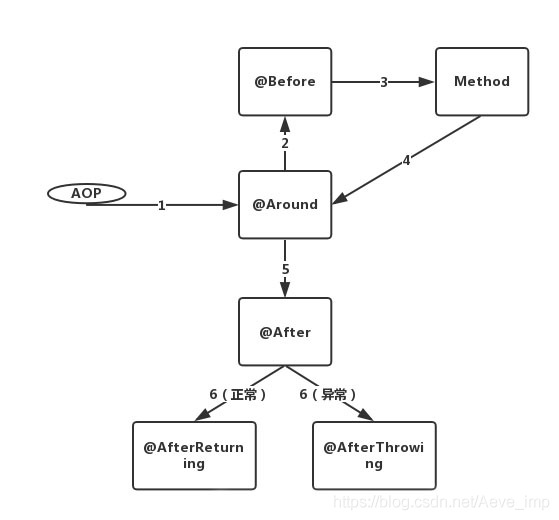
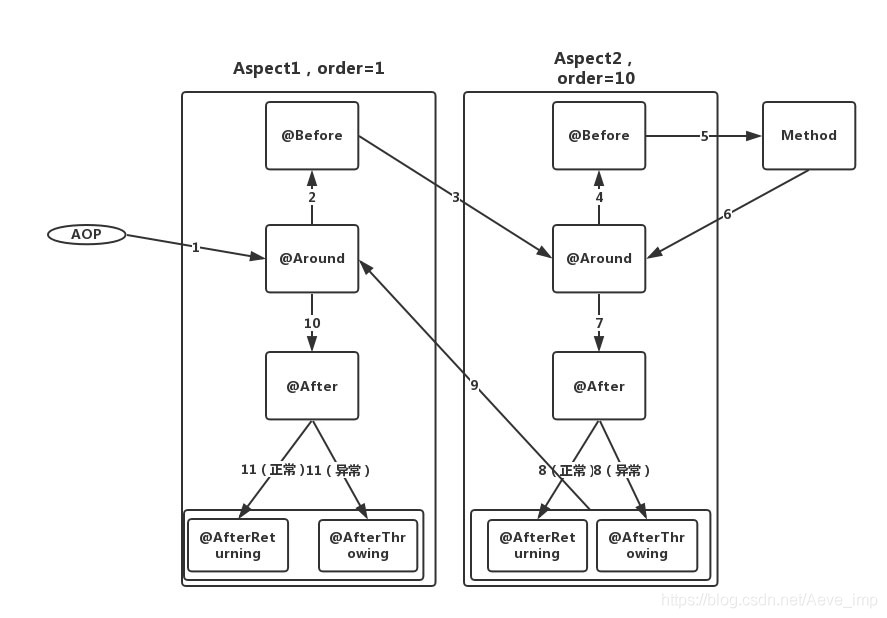
经实验确定,确实是order越小越是最先执行,但更重要的是最先执行的最后结束。
单个AOP的执行顺序:
多个AOP,不同Order数值的执行顺序:
编写代码实验结果:

这也解释了为什么 AOP实现多数据源的切换需要将 @Order的数值设定为1,因为其他AOP操作可能会执行数据库操作。
知识点2:@within 注解
@within和@annotation的区别:
@within 对象级别
@annotation 方法级别
@Around("@annotation(自定义注解)") //自定义注解标注在方法上的方法执行aop方法
如:@Around("@annotation(org.springframework.transaction.annotation.Transactional)")
@Around("@within(自定义注解)") //自定义注解标注在的类上;该类的所有方法(不包含子类方法)执行aop方法
如:@Around("@within(org.springframework.transaction.annotation.Transactional)")