一元非参数回归
给定一组样本观测值( Y 1 , X 1 ) , ( Y 2 , X 2 ) , ⋯ , ( Y n , X n ) , (Y_1,X_1),(Y_2,X_2),\cdots,(Y_n,X_n),(Y1,X1),(Y2,X2),⋯,(Yn,Xn),X i X_iXi和Y i Y_iYi之间的任意函数模型表示为
Y i = m ( X i ) + ε i , i = 1 , 2 , ⋯ , n . Y_i=m(X_i)+\varepsilon_i,i=1,2,\cdots,n.Yi=m(Xi)+εi,i=1,2,⋯,n.
其中m ( ⋅ ) = E ( Y ∣ X ) , ε m(\cdot)=E(Y|X),\varepsilonm(⋅)=E(Y∣X),ε为随机误差项,一般假定E ( ε ∣ X = x ) = 0 E(\varepsilon|X=x)=0E(ε∣X=x)=0,v a r ( ε ∣ X = x ) = σ 2 \rm{var}(\varepsilon|X=x)=\sigma^2var(ε∣X=x)=σ2,不必是常数。
核回归光滑模型
参考上篇文章讲到的核密度估计法,相当于求x xx附件的平均点数,平均点数的求法是对可能影响到x xx的样本点,按照距离x xx的远近作距离加权平均.核回归光滑的基本思路之类似,在此不是求平均点数,而是估计点x xx处y yy的取值,仍然按照距离x xx的远近对样本观测值y i y_iyi加权,这一思想被称为N a d a r a y a − W a t s o n \rm{Nadaraya-Watson}Nadaraya−Watson核回归.
- 选择核函数K ( ⋅ ) K(\cdot)K(⋅)以及窗宽h n > 0 h_n>0hn>0,
inf K ( u ) d u = 1. \inf K(u)\rm{d}u=1.infK(u)du=1. - 定义加权平均核为
ω i ( x ) = K h n ( X i − x ) ∑ j = 1 n K h n ( X j − x ) , i = 1 , 2 , ⋯ , n , \omega_i(x)=\frac{K_{h_n}(X_i-x)}{\sum_{j=1}^n K_{h_n}(X_j-x)}, i=1,2,\cdots,n,ωi(x)=∑j=1nKhn(Xj−x)Khn(Xi−x),i=1,2,⋯,n,
其中K h n ( u ) = h n − 1 K ( u h n − 1 ) K_{h_n}(u)=h_n^{-1}K(uh_n^{-1})Khn(u)=hn−1K(uhn−1)是一个概率密度函数.则N-W估计的定义为:
m n ( x ) = ∑ i = 1 n ^ ω i ( x ) Y i . \hat{m_n(x)=\sum_{i=1}^n}\omega_i(x)Y_i.mn(x)=i=1∑n^ωi(x)Yi.
注意一点:
θ ^ = min θ ∑ i = 1 n ω i ( x ) ( Y i − θ ) 2 = ∑ i = 1 n ω i Y i ∑ i = 1 n ω i , \hat{\theta}=\min_\theta \sum_{i=1}^n \omega_i(x)(Y_i-\theta)^2=\sum_{i=1}^n \frac{\omega_iY_i}{\sum_{i=1}^n\omega_i},θ^=θmini=1∑nωi(x)(Yi−θ)2=i=1∑n∑i=1nωiωiYi,
因此,核估计等价于局部加权最小二乘估计.权重ω i = K ( X i − x ) \omega_i=K(X_i-x)ωi=K(Xi−x).常用核函数已经在上篇文章介绍.核密度回归还有另外一种写法:
E ( Y ∣ X = x ) = ∫ y f ( y ∣ x ) d y = ∫ y f ( x , y ) f X ( x ) d y = m ( x ) , E(Y|X=x)=\int yf(y|x)dy=\int y \frac{f(x,y)}{f_X(x)}dy=m(x),E(Y∣X=x)=∫yf(y∣x)dy=∫yfX(x)f(x,y)dy=m(x),
其中f ( y ∣ x ) f(y|x)f(y∣x)是给定X = x X=xX=x时Y YY的条件pdf,f X ( x ) f_X(x)fX(x)是X XX的边际pdf.上式对y yy积分所以可以进一步写为:
m ( x ) = E ( Y ∣ X = x ) = ∫ y f ( x , y ) d y f X ( x ) . m(x)=E(Y|X=x)=\frac{\int y f(x,y)dy}{f_X(x)}.m(x)=E(Y∣X=x)=fX(x)∫yf(x,y)dy.
给定样本观测值为{ X i , Y i } , i = 1 , … , n \{X_i,Y_i\},i=1,\dots,n{Xi,Yi},i=1,…,n.此时的未知量是f ( x , y ) f(x,y)f(x,y)和f X ( x ) f_X(x)fX(x),我们可以通过多元核密度估计来得到,此时有:
f ^ h , g ( x , y ) = 1 n ∑ i = 1 n K h ( x − X i h ) K g ( y − Y i g ) \hat{f}_{h,g}(x,y)=\frac{1}{n}\sum_{i=1}^n K_h \left( \frac{x-X_i}{h} \right)K_g \left( \frac{y-Y_i}{g} \right)f^h,g(x,y)=n1i=1∑nKh(hx−Xi)Kg(gy−Yi)
令( y − Y i ) g = s \frac{(y-Y_i)}{g}=sg(y−Yi)=s:
∫ y f ^ h , g ( x , y ) d y = 1 n ∑ i = 1 n 1 h K ( x − X i h ) ∫ y g K g ( y − Y i g ) d y = 1 n ∑ i = 1 n K h ( x − X i ) ∫ ( s g + Y i ) K ( s ) d s = 1 n K h ( x − X i ) { g ∫ s K ( s ) d s + Y i ∫ K ( s ) d s } = 1 n K h ( x − X i ) Y i \begin{aligned} \int y\hat{f}_{h,g}(x,y)dy &=\frac{1}{n}\sum_{i=1}^n \frac{1}{h}K\left( \frac{x-X_i}{h} \right)\int\frac{y}{g}K_g\left( \frac{y-Y_i}{g} \right)dy\\ &=\frac{1}{n}\sum_{i=1}^nK_h(x-X_i)\int(sg+Y_i)K(s)ds\\ &= \frac{1}{n}K_h(x-X_i) \left\{g\int sK(s)ds+Y_i\int K(s)ds \right\} \\ &=\frac{1}{n}K_h(x-X_i)Y_i \end{aligned}∫yf^h,g(x,y)dy=n1i=1∑nh1K(hx−Xi)∫gyKg(gy−Yi)dy=n1i=1∑nKh(x−Xi)∫(sg+Yi)K(s)ds=n1Kh(x−Xi){g∫sK(s)ds+Yi∫K(s)ds}=n1Kh(x−Xi)Yi
其中由核函数的性质得到:∫ s K ( s ) d s = E ( s ) = 0 \int sK(s)ds=E(s)=0∫sK(s)ds=E(s)=0,∫ K ( s ) d s = 1 \int K(s)ds=1∫K(s)ds=1则Nadaraya-Watson估计量还可以写为:
m ^ h ( x ) = n − 1 ∑ i = 1 n K h ( x − X i ) Y i n − 1 ∑ j = 1 n K h ( x − X j ) \hat{m}_h(x)=\frac{n^{-1}\sum_{i=1}^nK_h(x-X_i)Y_i}{n^{-1}\sum_{j=1}^{n}K_h(x-X_j)}m^h(x)=n−1∑j=1nKh(x−Xj)n−1∑i=1nKh(x−Xi)Yi
举个例子: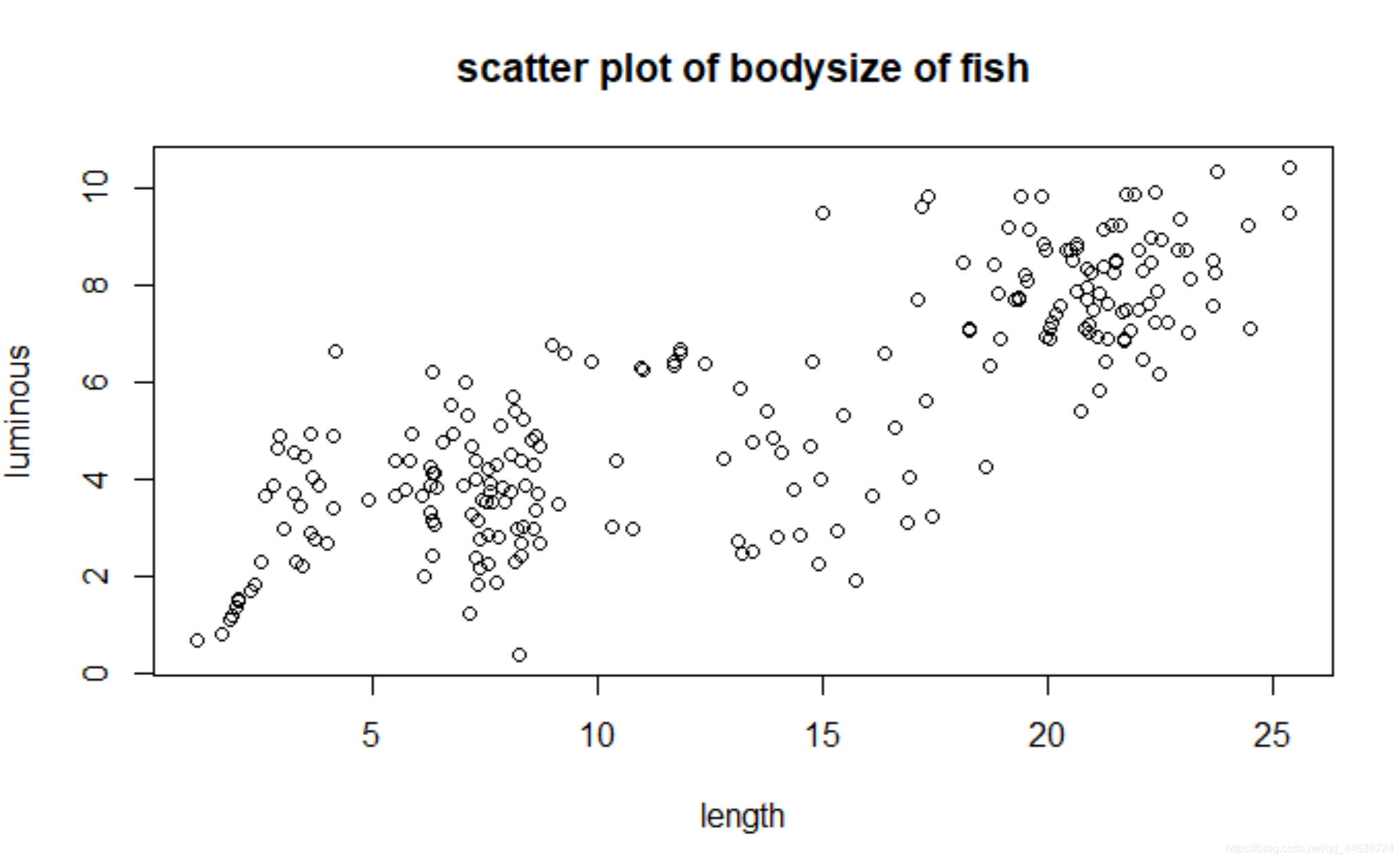
我们通过一元核回归模型来拟合这个数据集,采用N a d a r a y a − W a t s o n Nadaraya-WatsonNadaraya−Watson核回归,同时比较不同窗宽h hh对回归曲线的影响,首先复习一下上节的二元核密度估计: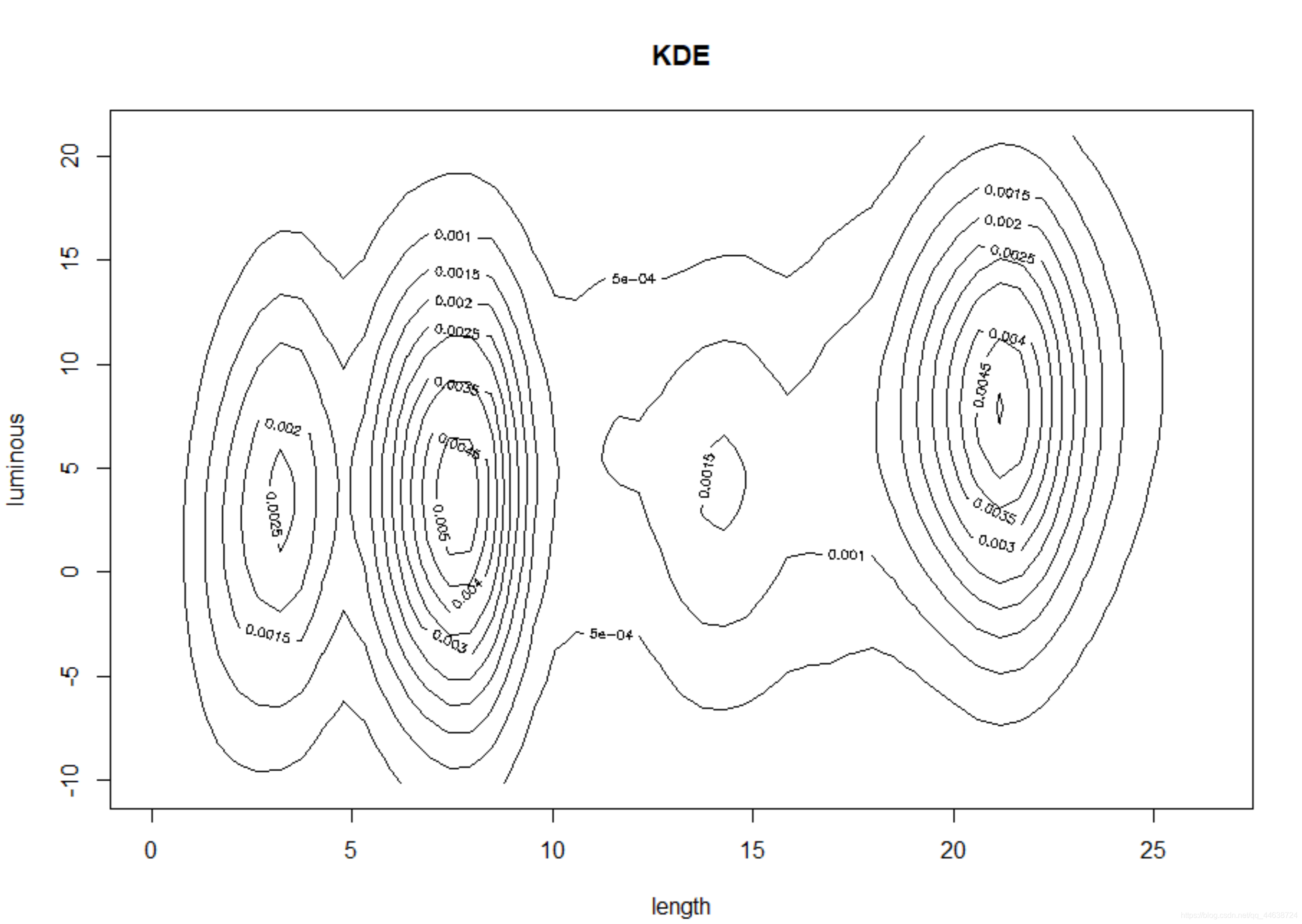
再看看另一个角度:
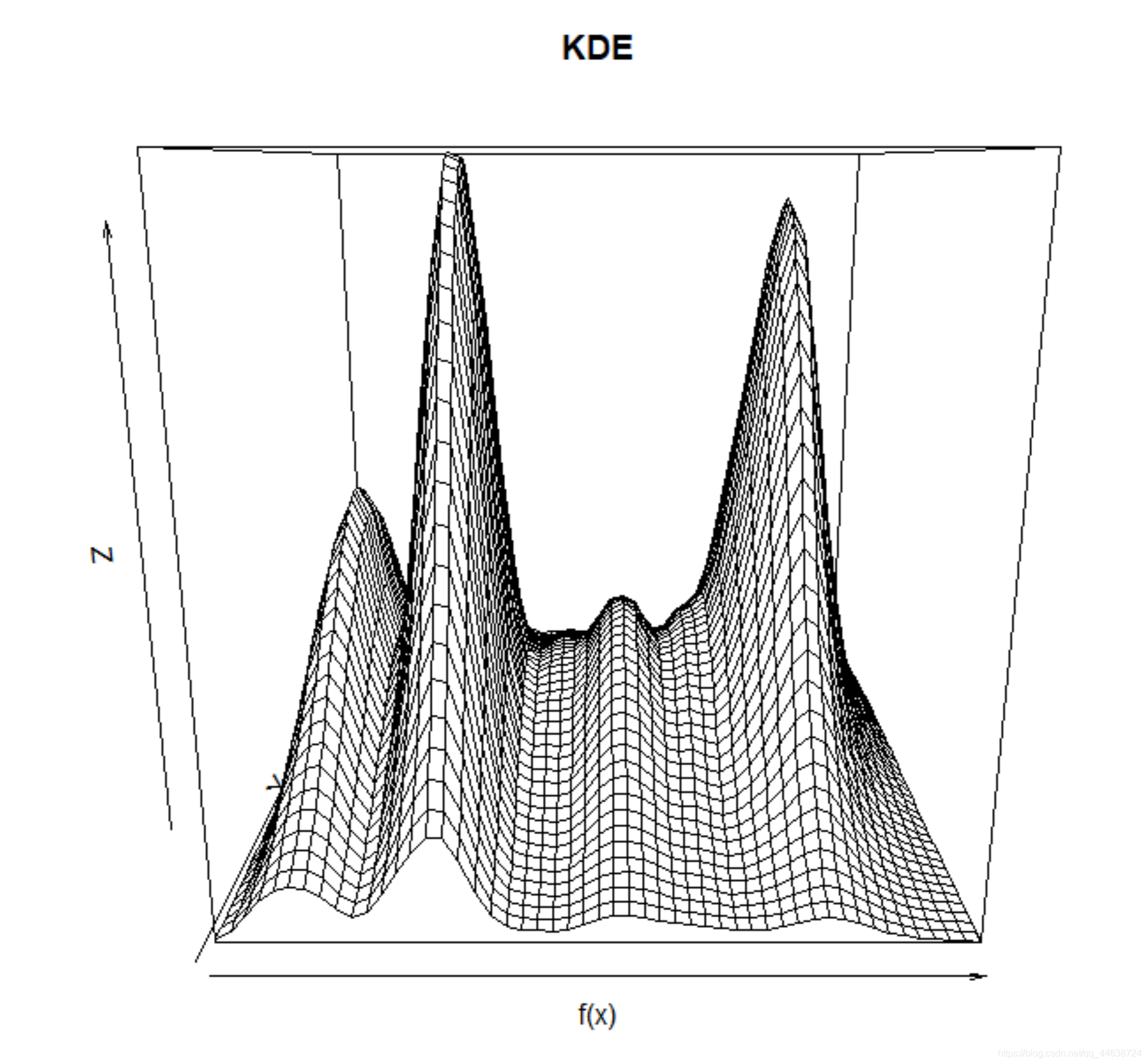
代码如下
file = "D:\REF\fish.txt"
data<-read.table(file="D:\\REF\\fish.txt",header = T)
x <- cbind(data$length,data$luminous)
est <- bkde2D(x=x)
contour(est$x1, est$x2, est$fhat,xlab = 'length',ylab='luminous',main='KDE')
persp(est$fhat,xlab = 'f(x)',main = 'KDE')
再进行核回归,这里分别取h = 0.1 , 0.5 , 1.5 , 3.0 h=0.1,0.5,1.5,3.0h=0.1,0.5,1.5,3.0.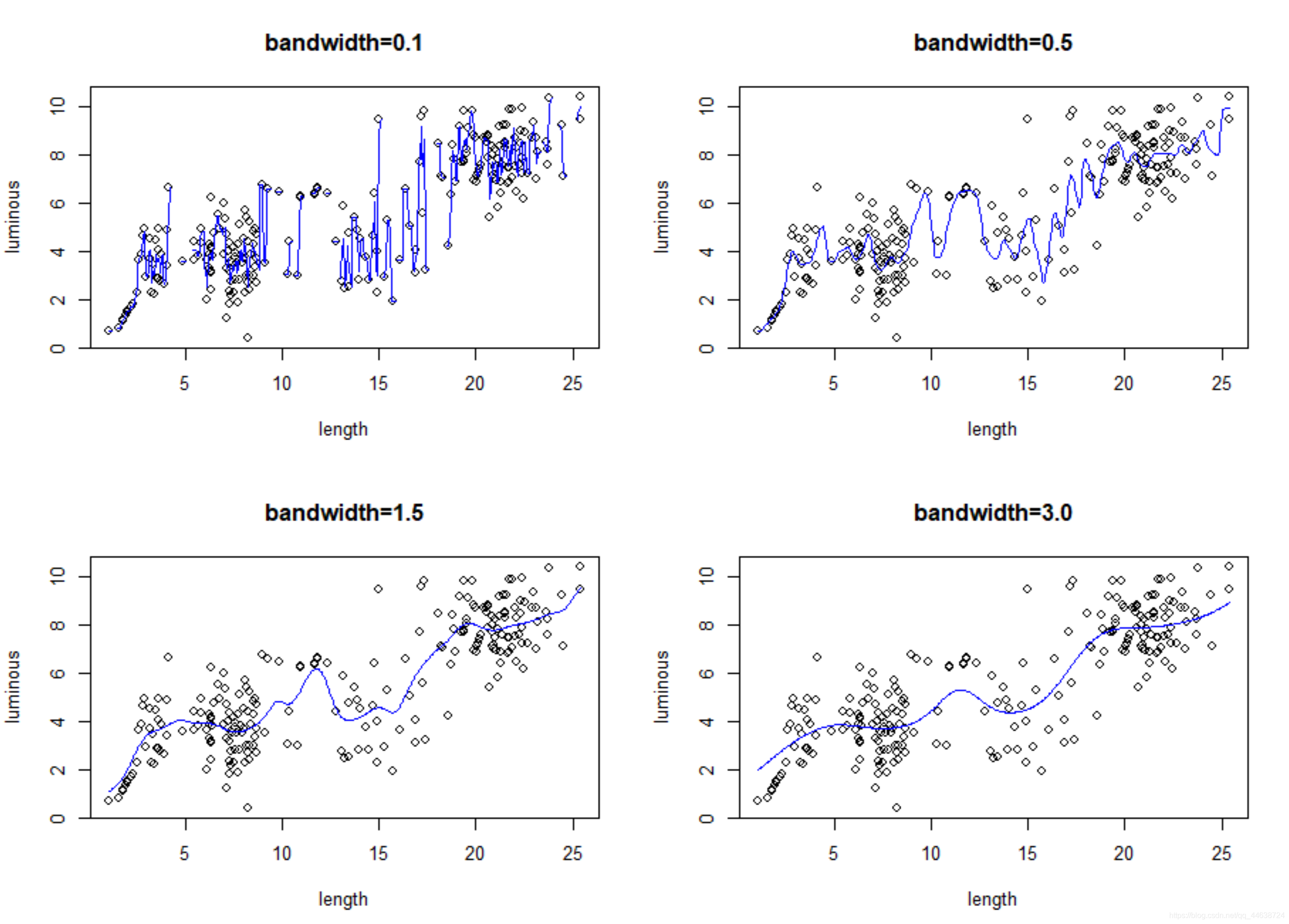
R语言代码如下
file = "D:\REF\fish.txt"
data<-read.table(file="D:\\REF\\fish.txt",header = T)
x <- cbind(data$length,data$luminous)
par(mfrow=c(2,2))
fit1 <- ksmooth(x=data$length,y=data$luminous,kernel='normal',bandwidth = 0.1,range.x = range(data$length),n.points = length(x))
fit2 <- ksmooth(x=data$length,y=data$luminous,kernel='normal',bandwidth = 0.5,range.x = range(data$length),n.points = length(x))
fit3 <- ksmooth(x=data$length,y=data$luminous,kernel='normal',bandwidth = 1.5,range.x = range(data$length),n.points = length(x))
fit4 <- ksmooth(x=data$length,y=data$luminous,kernel='normal',bandwidth = 3.0,range.x = range(data$length),n.points = length(x))
plot(x1,x2,xlab = 'length' ,ylab = 'luminous' ,main='bandwidth=0.1')
lines(fit1,lwd=1.0,col='blue')
plot(x1,x2,xlab = 'length' ,ylab = 'luminous' ,main='bandwidth=0.5')
lines(fit2,lwd=1.0,col='blue')
plot(x1,x2,xlab = 'length' ,ylab = 'luminous' ,main='bandwidth=1.5')
lines(fit3,lwd=1.0,col='blue')
plot(x1,x2,xlab = 'length' ,ylab = 'luminous' ,main='bandwidth=3.0')
lines(fit4,lwd=1.0,col='blue')