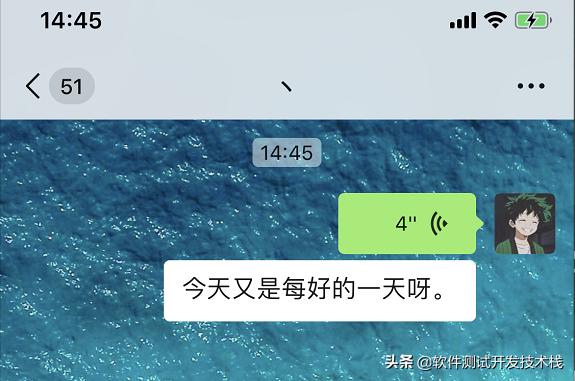
如上图,我们通过微信发送了一段语音,在对语音进行转文字时。语音识别引擎首先会将把这段语音进行分帧(切分成若干小段),然后利用声学模型将提取的每一帧的声学特征识别为一个个“状态”,多个状态会组合成一个音素(语音中的最小的单位),音素构成了诸多同音字,再利用 语言模型从诸多同音字中挑选出可以使 语义完整的字(例如 不会把“吃饭”识别成“痴泛”),最后将文本展示出来。
语音识别(ASR) 过程
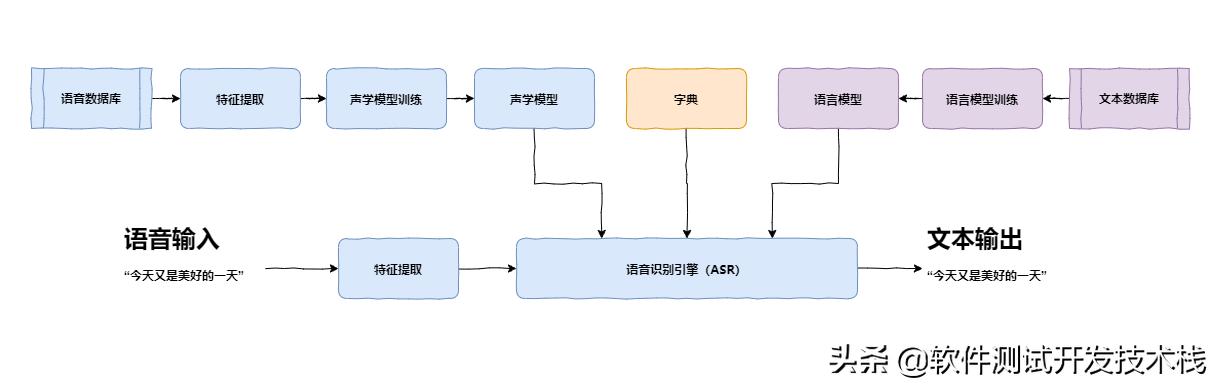
自动语音识别技术(Automatic Speech Recognition)是一种将人的语音转换为文本的技术。
所谓语音识别,就是将一段语音信号转换成相对应的文本信息,系统主要包含特征提取、声学模型,语言模型以及字典与解码四大部分。
此外为了更有效地提取特征往往还需要对所采集到的声音信号进行滤波、分帧等音频数据预处理工作,将需要分析的音频信号从原始信号中合适地提取出来。
特征提取工作将声音信号从时域转换到频域,为声学模型提供合适的特征向量。
声学模型中再根据声学特性计算每一个特征向量在声学特征上的得分,而语言模型则根据语言学相关的理论,计算该声音信号对应可能词组序列的概率。
最后根据已有的字典,对词组序列进行解码,得到最后可能的文本表示。
其中大致过程梳理如下(为方便理解忽略部分严谨性):
预处理:
- 首尾端的静音切除,降低干扰,静音切除的操作一般称为VAD。
- 声音分帧,也就是把声音切开成一小段一小段,每小段称为一帧,使用移动窗函数来实现,不是简单的切开,各帧之间一般是有交叠的。
特征提取:主要算法有线性预测倒谱系数(LPCC)和Mel 倒谱系数(MFCC),目的是把每一帧波形变成一个包含声音信息的多维向量。
声学模型(AM):通过对语音数据进行训练获得,输入是特征向量,输出为音素信息。
字典:字或者词与音素的对应, 简单来说, 中文就是拼音和汉字的对应,英文就是音标与单词的对应。
语言模型(LM):通过对大量文本信息进行训练,得到单个字或者词相互关联的概率。
解码:就是通过声学模型,字典,语言模型对提取特征后的音频数据进行文字输出。
语音识别流程的示例(为方便理解忽略部分严谨性):
语音信号
今天又是美好的一天呀特征提取
今天又是美好的一天呀 → [[123456],[],[]]声学模型
[[123456],[],[]] → j i n t i a n y o u s h i m e i h a o d e y i t i a n字典
今:j īn ; 进:j ìn ; 天:t i ān; 填:t i án ; 又:y òu; 佑:y òu;是:sh ì; 美:m ěi ; 妹:m èi; 好:h ǎo; 的:d e; 一:y ī; 甜:t i án;语言模型(概率)
今天:0.7456; 又:0.6524;是:0.9301;又是:0.6012;美好:0.7621,没好:0.5049,的:0.9871,;一:0.9123,天:0.6785,一天:0.9043;呀:0.7849,压:0.4356输出文字
今天又是美好的一天呀语音识别(ASR) 评估指标

句错误率(SER)
识别错误的句子个数 除以总的句子个数,即为SER。
计算公式
SER = 错误句数 / 总句数 * 100%
可以理解为以下几种情况会导致句子错误:
- 由于字多而导致句子不对。如:你好呀。被识别为:你丫 好呀。
- 由于字少而导致句子不对。如:你好呀。被识别为:你好。
- 由于字不对应而导致句子不对。如:你好呀。被识别为:你好丫。
句正确率(S.Corr)
识别正确的句子个数 除以总的句子个数,即为S.Corr。
计算公式
S.Corr = 1 - SER = 正确句数 / 总句数 * 100%
字错误率(WER/CER)
为了使识别出来的词序列(实际识别结果)和标准的词序列(期望识别结果)之间保持一致,需要进行替换、删除或者插入某些词,这些插入、替换或删除的词的总个数,除以标准的词序列中词的总个数的百分比,即为WER。
WER是语音识别领域的关键性评估指标,WER越低表示效果越好。
- WER(Word Error Rate),词错误率,但一般称为字错误率。
- CER(Character Error Rate),字符错误率,中文一般用CER来表示 字错误率。
为什么存在这两种表示方式,原因如下:
英文: Today # 1个单词中文: 你好 # 2个字符通俗点的解释就是:
- 英文,最小单元是单词,语音识别应该用"字错误率"(WER)。
- 中文,最小单元是字符,语音识别应该用“字符错误率”(CER)。
计算公式
WER = (S + D + I ) / N = (S + D + I ) / (S + D + C) * 100%
公式注解
S: 替换的字数,如 你好呀。被识别为:你好丫。D: 删除的字数,如 你好呀。被识别为:你好。 I: 插入的字数,如 你好呀。被识别为:你丫 好呀。 C: 正确的字数.N: 为(S替换 + D删除 + C正确)的字数,需要注意的是这并不等于原句总字数或者识别结果字数。同时,在计算公式中因为有插入字数的计算,所以理论上WER/CER存在大于100%的可能。但实际场景,特别是大样本量的时候,基本太不可能出现。,否则就太差了,不可能被商用。
字准确率(W.Acc)
字准确率(Word Accuracy),就是1-字错误率的结果。
计算公式
W.Acc = 1 - WER(或CER) = (N - D - S - I) / N = (C - I) / (S + D + C) * 100%
公式注解
S: 替换的字数,如 你好呀。被识别为:你好丫。D: 删除的字数,如 你好呀。被识别为:你好。 I: 插入的字数,如 你好呀。被识别为:你丫 好呀。 C: 正确的字数.N: 为(S替换 + D删除 + C正确)的字数,需要注意的是这并不等于原句总字数或者识别结果字数。字正确率(W.Corr)
字正确率(Word Correct),通常说的某某ASR识别率(识别正确率) 达到97%,就是指的字正确率,计算中忽略了插入的字数。
计算公式
W.Corr = ( N - D - S ) / N = C/ (S + D + C) * 100%
公式注解
S: 替换的字数,如 你好呀。被识别为:你好丫。D: 删除的字数,如 你好呀。被识别为:你好。 I: 插入的字数,如 你好呀。被识别为:你丫 好呀。 C: 正确的字数.N: 为(S替换 + D删除 + C正确)的字数,需要注意的是这并不等于原句总字数或者识别结果字数。语音识别(ASR)评估指标计算示例

识别结果仅存在删除(D)情况
示例:语音输入: 今 天 又 是 美 好 的 一 天 呀文本输出: 今 天 又 是 美 好 ASR 各指标计算结果,如下:
SER(句错误率) = 1 / 1 * 100%= 100 %S.Corr(句正确率) = 1 - 1 * 100% = 0 %WER/CER(字错误率) = (S + D + I ) / (S + D + C) = (0 + 4 + 0) / (0 + 4 + 6) = 40 %W.Acc(字准确率) = (C - I) / (S + D + C) = (6 - 0) / (0 + 4 + 6) = 60 %W.Corr(字正确率) = C/ (S + D + C) = 6 / (0 + 4 + 6) = 60 % 识别结果仅存在删除(S)、替换(D)的情况
示例:语音输入: 今 天 又 是 美 好 的 一 天 呀文本输出: 今 天 有 是 美 好 ASR 各指标计算结果,如下:
SER(句错误率) = (1 / 1) * 100%= 100 %S.Corr(句正确率) = (1 - 1) * 100% = 0 %WER/CER(字错误率) = (S + D + I ) / (S + D + C) * 100% = (1 + 4 + 0) / (1 + 4 + 5) * 100% = 50 %W.Acc(字准确率) = (C - I) / (S + D + C) * 100% = (5 - 0) / (1 + 4 + 5) * 100% = 50 %W.Corr(字正确率) = C/ (S + D + C) * 100% = 5 / (1 + 4 + 5) * 100% = 50 % 识别结果存在删除(S)、替换(D)、插入(I)的情况
示例:语音输入: 今 天 又 是 美 好 的 一 天 呀文本输出: 今 天 有 是 更 美 好 ASR 各指标计算结果,如下:
SER(句错误率) = (1 / 1) * 100%= 100 %S.Corr(句正确率) = (1 - 1) * 100% = 0 %WER/CER(字错误率) = (S + D + I ) / (S + D + C) * 100% = (1 + 4 + 1) / (1 + 4 + 5) * 100% = 60 %W.Acc(字准确率) = (C - I) / (S + D + C) * 100% = (5 - 1) / (1 + 4 + 5) * 100% = 40 %W.Corr(字正确率) = C / (S + D + C) * 100% = 5 / (1 + 4 + 5) * 100% = 50 % 识别结果字数小于语料字数,且全错的情况
示例:语音输入: 今 天 又 是 美 好 的 一 天 呀文本输出: 上 山 打 老 虎 ASR 各指标计算结果,如下:
SER(句错误率) = (1 / 1) * 100%= 100 %S.Corr(句正确率) = (1 - 1) * 100% = 0 %WER/CER(字错误率) = (S + D + I ) / (S + D + C) * 100% = (5 + 5 + 0) / (5 + 5 + 0) * 100% = 100 %W.Acc(字准确率) = (C - I) / (S + D + C) * 100% = (0 - 0) / (5 + 5 + 0) * 100% = 0 %W.Corr(字正确率) = C / (S + D + C) * 100% = 0 / (5 + 5 + 0) * 100% = 0 % 识别结果字数大于语料字数,且全错的情况
示例:语音输入: 今 天 又 是 美 好 的 一 天 呀文本输出: 景 甜 有 时 妹 号 得 亿 田 丫 上 山 打 老 虎 ASR 各指标计算结果,如下:
SER(句错误率) = (1 / 1) * 100%= 100 %S.Corr(句正确率) = (1 - 1) * 100% = 0 %WER/CER(字错误率) = (S + D + I ) / (S + D + C) * 100% = (10 + 0 + 5) / (10 + 0 + 0) * 100% = 150 %W.Acc(字准确率) = (C - I) / (S + D + C) * 100% = (0 - 5) / (10 + 0 + 0) * 100% = -50 %W.Corr(字正确率) = C / (S + D + C) * 100% = 0 / (10 + 0 + 0) * 100% = 0 %