现象描述:当我们搭建好集群之后,初次执行hadoop作业时成功的,但是过了一段时间之后会一直卡着不能继续执行,想要重启集群,但是考虑到可能会造成数据丢失,这种情况下该怎么办呢。
现象如下:
20/08/04 11:02:53 INFO input.FileInputFormat: Total input paths to process : 1
20/08/04 11:02:53 INFO mapreduce.JobSubmitter: number of splits:1
20/08/04 11:02:53 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1596505147038_0005
20/08/04 11:02:54 INFO impl.YarnClientImpl: Submitted application application_1596505147038_0005
20/08/04 11:02:54 INFO mapreduce.Job: The url to track the job: http://yunslave1:8088/proxy/application_1596505147038_0005/
20/08/04 11:02:54 INFO mapreduce.Job: Running job: job_1596505147038_0005
问题分析:
首先:我们的服务器或者笔记本的磁盘和内存都是足够用的; 查看磁盘的存储是否够,由查看的磁盘使用状况知磁盘是够的
[root@yunmaster1 ~]# df -h
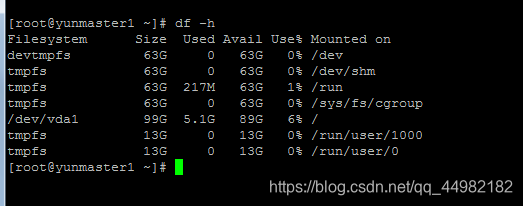
其次:由于之前运行没有出错,执行job作业成功了,所以排除配置是没有问题的; 因此可以确定是集群本身的磁盘和内存资源分配问题,由于获取的相应资源不够用,所以执行的job的时候出现了资源分配不够,导致了job不能继续执行。
解决方法:
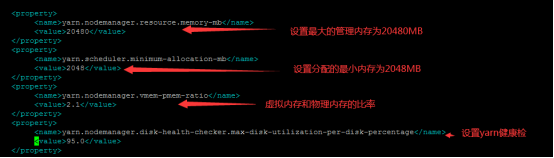
第一步:编辑yarn的内存大小
以下设置的yarn可以管理分配的最大内存是 20480 MB,yarn计算分配的最小内存是2048 MB,虚拟内存和真实物理内存的比率ratio为 2.1
vi yarn-site.xml
#添加如下:
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>20480</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.1</value>
</property>
<property>
<name>yarn.nodemanager.disk-health-checker.max-disk-utilization-per-disk-percentage</name>
<value>95.0</value>
</property>
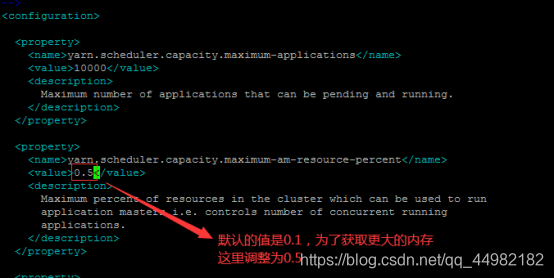
第二步:修改Capacity Scheduler(容量调度器)
在hadoop配置目录下修改:capacity-scheduler.xml
yarn.scheduler.capacity.maximum-am-resource-percent=0.1
这个值调为0.6 或者根据适当情况调大调小。
这个属性的意思是你的application master 申请的container资源最大不能超过集群总资源的百分之多少,默认是百分之10.
#vi capacity-scheduler.xml
第三步:完成以上的添加配置之后需要重启yarn。
版权声明:本文为qq_44982182原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。