这篇文章是微软18年发的基于强化学习来做推荐系统的文章。
研究推荐系统一个月有余,总觉得自己的模型过分简单,单纯的无脑过FC把人都整的蠢蠢的,于是就搜寻了一下有没有别的方式来做推荐,就发现了这一篇文章,总体觉得还是很不错的,记录一下学习心得。
如果有理解错的地方,还望各路大佬不吝赐教。
摘要
目前主流推荐算法没有解决的问题:
(1)大多数模型只用点击率CTR来作为目标函数
(2)鲜少有人尝试利用用户反馈信息来提升推荐效果
(3)大多数方法都会重复的给用户推荐相似的内容(这一点我深有同感,目前APP中的推荐算法大多都是这种模式)
本文创新点:
(1)引入了用户返回模式(user return pattern)对CTR进行补充,以利用更多的用户反馈信息
(2)引入了一种高效的exploration策略来尽可能的给用户推荐具有新鲜感的新闻
Introduction及related work
新闻推荐中的三大挑战:
第一,推荐过程中的动态变化难以处理。这些动态变化主要有两部分构成:(1)新闻具有强的时效性,很快会过期。在本文所使用的数据集中,每条新闻从发布到最后一次点击的平均时长是4.1小时,因此推荐候选池变化是非常迅速的。(2)用户在看新闻的过程中,兴趣点是会发生改变的,所以需要定期更新模型,下图的说明非常直观清晰。而且当前的推荐内容是会影响到用户将来将会想看什么新闻的(原文讲了一个非常简单的story来make sense,比如推荐的两条新闻A和B你都想看,但是当你看了A之后,可能你会想看更多关于A的新闻,就没那么想看B了)
第二,模型很容易推荐相似的内容给用户。之前有两种办法来缓解这个问题:(1)ϵ \epsilonϵ-greedy策略,但它会推给用户完全不相关的内容(2)UCB,但是它的响应时间很长,需要重复点击一个item很多次才能给出一个准确的reward。
本文的解决方法是(1)引入DQN框架来更好的学习新闻动态特征和用户偏好,因为DQN能同时考虑current reward和future reward。MAB-based方法不能清晰地给出future reward,MDP-based方法不适用于大规模数据。(2)引入用户返回APP的情况转化为用户活跃度,作为用户反馈信息。可以在任意时刻计算用户活跃度。(3)exploration时采用Dueling Bandit Gradient Descent(DBGD)方法来挑选当前推荐环境下的候选items。
整体结构框架如下图,其中,用户点击情况就是实时reward,用户活跃度就是future reward,state表示的用户特征以及用户行为特征,action是新闻候选池的特征,这样就构成了强化学习的基本框架。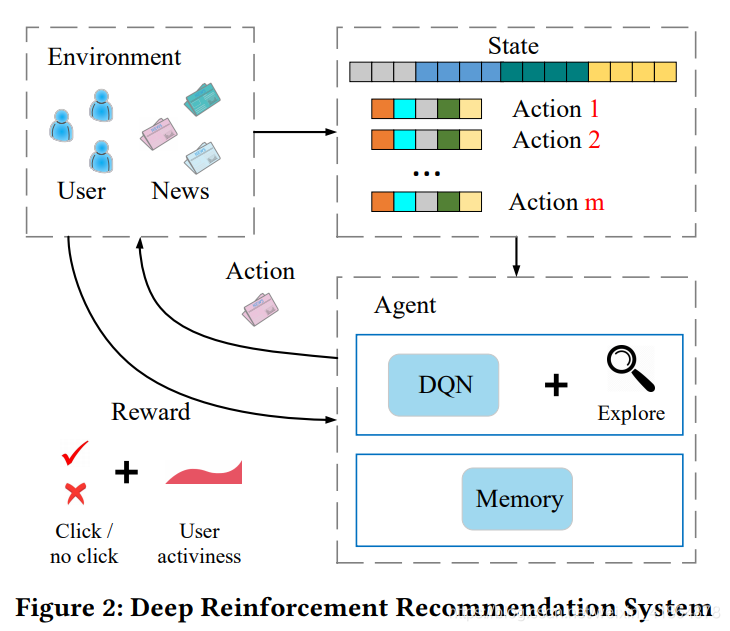
Method
模型框架

模型分为线上计算和线下计算。
线下计算部分,模型采用了用户记录日志的新闻级别和用户级别的4类特征作为输入,计算DQN的reward。
线上计算部分分为4步
(1)PUSH:t1时刻用户u发出请求,agent利用u和新闻候选池作为输入,生成top k个推荐列表L
(2)FEEDBACK:当用户有点击行为时就生成了反馈信息B
(3)MINOR UPDATE(小调):t1时刻后,agent利用该用户u,生成的L和反馈信息B,比较exploitation网络Q和exploration网络Q’,选择更好的那个
(4)MAJOR UPDATE(大调):在经过某一个固定的时期Tr后,agent利用反馈信息B和memory存储的用户活跃度采样来更新Q(memory中存储近期的历史点击记录和用户活跃度分值)
特征构造
这一部分挺重要的,不过文章讲的不太细节
(1)新闻特征:417维的one hot,包括headline, provider, ranking, entity name, category, topic category, and click counts in last 1 hour, 6 hours, 24 hours, 1 week, and 1 year respectively。这里每个click count是1维,其余的特征总共412维,不知道分别是多少维的
(2)用户特征:413*5维: 1 hour, 6 hours, 24 hours, 1 week, and 1 year里用户点击过的新闻的headline, provider, ranking, entity name, category, and topic category + click count
(3)用户-新闻特征:25维,在该用户的所有浏览记录中category, topic category and provider的出现频率
(4)环境特征:32维,当一次点击发生时的环境,包括time, weekday, and the freshness of the news (the gap between
request time and news publish time).
reward计算
总的reward可写为

其中s是当前的state,r a , t + 1 r_{a,t+1}ra,t+1是action a发生后的immediate reward(因为reward总是存在延时,所以时间是t+1而不是t),W t W_{t}Wt和W T ′ W_{T}^{'}WT′是Q和Q’的参数。
在此公式中,在下一个状态s a , t + 1 s_{a,t+1}sa,t+1时,agent会产生一系列候选的action {a’},能带来对最大reward的a’所对应的参数W’就会替换掉当前的W。
下图显示了特征输入形式,值函数由静态的用户特征和环境特征构成,行为函数由静态动态的全部特征构成。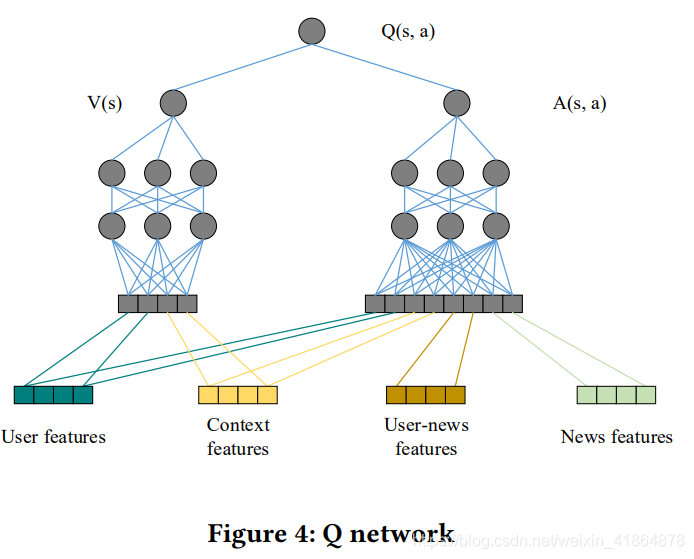
用户活跃度拟合
当产生用户请求时,就被标记为user return的时刻(这里有一点疑问,如果是用户在一段时间内连续多次刷新呢?)
采用生存模型进行拟合,一通数学的积分操作我直接截过来
然后一通定义变量,拟合,就变成这样:
函数的图象大概长这样,意义就比较明确了,最大值不超过1,初始化值是0.5,阶跃的点就代表发生了用户请求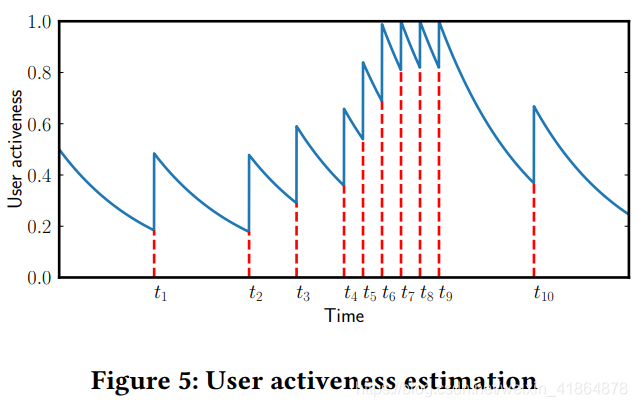
Explore
这一节主要阐述了DQN如何选取候选列表L的过程,如图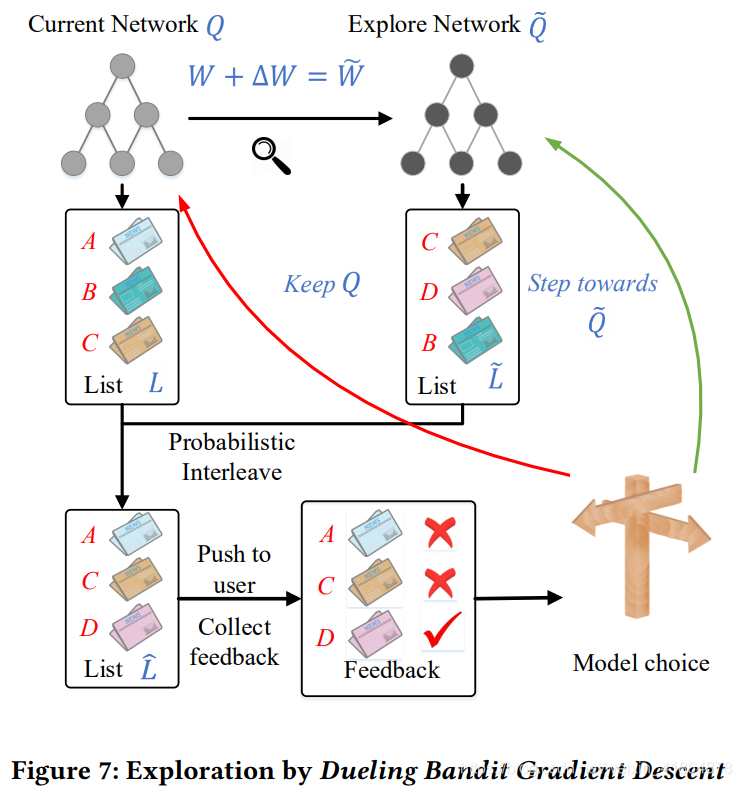
∆ W = α ⋅ r a n d ( − 1 , 1 ) ⋅ W ∆W = α · rand(−1, 1) · W∆W=α⋅rand(−1,1)⋅W,相当于给W一个很小的扰动,就会有一个新生成的Q’。Q’和Q都会给出top k的候选列表L’和L,最后推给用户的L LL是随机的在L和L’中选择,比如L LL的第一个内容选择在L中产生,那么就会随机的从L中抽取一个item,这个随机不是完全随机,和L中各item的概率有关,概率高的被抽到的概率也大(和tensorflow自带的log_uniform_candidate_sampler采样方式的原理相似)。
之后将L LL推给用户,用户就会产生点击行为和反馈信息B,如果由Q’产生的推荐item效果好于Q,就替换,这就是模型选择的逻辑
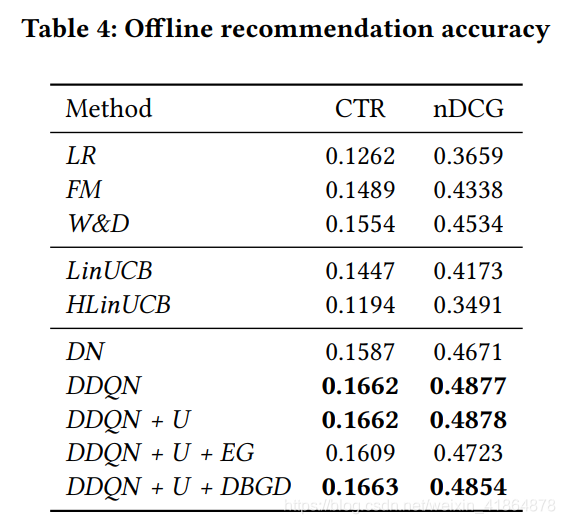
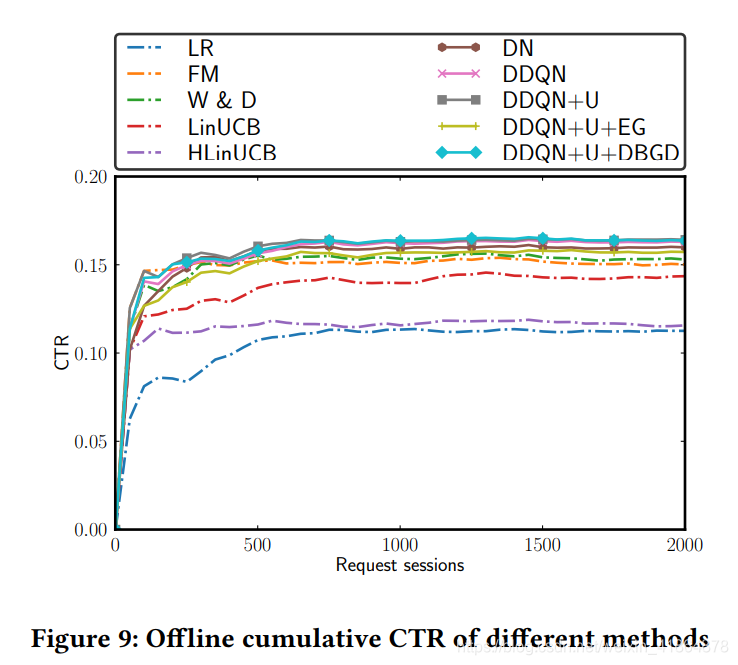
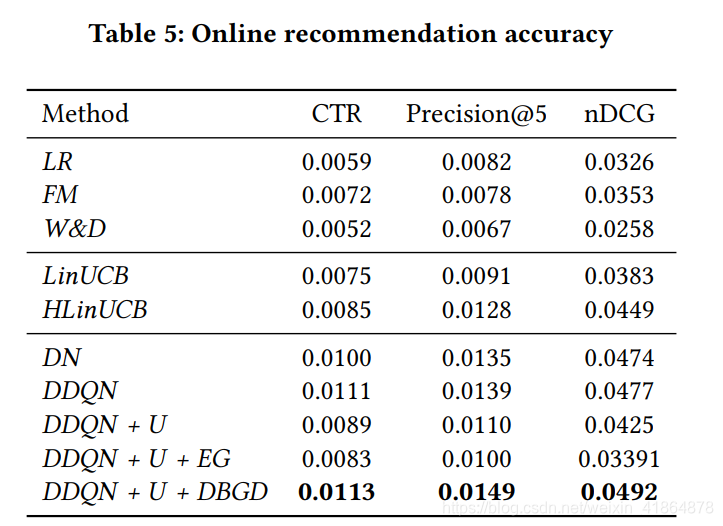
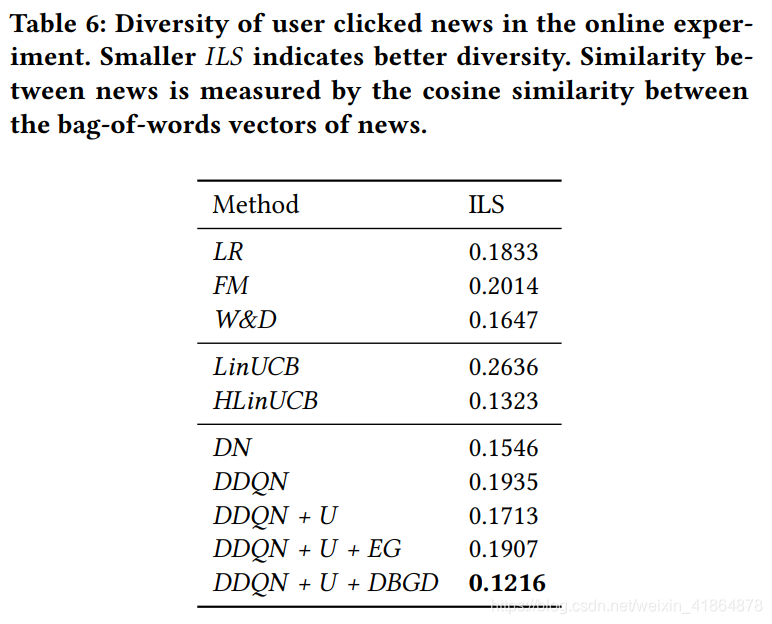
实验结果
metrics:用了precision@5和nDCG@5