Elasticsearch之settings和mappings的意义
简单的说,就是
settings是修改分片和副本数的。
mappings是修改字段和类型的。
记住,可以用url方式来操作它们,也可以用java方式来操作它们。建议用url方式,因为简单很多。
1、ES中的settings
查询索引库的settings信息
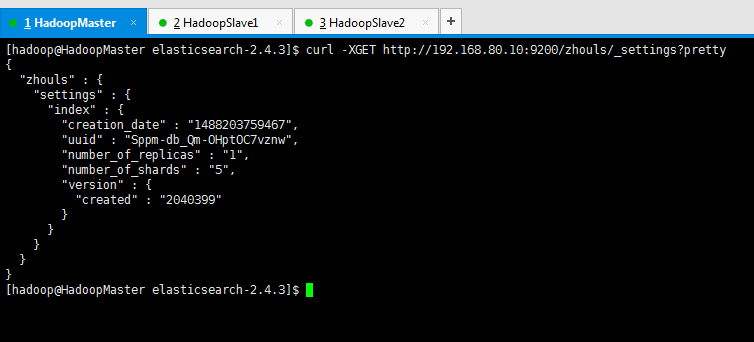
[hadoop@HadoopMaster elasticsearch-2.4.3]$ curl -XGET http://192.168.80.10:9200/zhouls/_settings?pretty
{
"zhouls" : {
"settings" : {
"index" : {
"creation_date" : "1488203759467",
"uuid" : "Sppm-db_Qm-OHptOC7vznw",
"number_of_replicas" : "1",
"number_of_shards" : "5",
"version" : {
"created" : "2040399"
}
}
}
}
}
[hadoop@HadoopMaster elasticsearch-2.4.3]$
settings修改索引库默认配置
例如:分片数量,副本数量
查看:curl -XGET http://192.168.80.10:9200/zhouls/_settings?pretty
操作不存在索引:curl -XPUT '192.168.80.10:9200/liuch/' -d'{"settings":{"number_of_shards":3,"number_of_replicas":0}}'
操作已存在索引:curl -XPUT '192.168.80.10:9200/zhouls/_settings' -d'{"index":{"number_of_replicas":1}}'
总结:就是,不存在索引时,可以指定副本和分片,如果已经存在,则只能修改副本。
在创建新的索引库时,可以指定索引分片的副本数。默认是1,这个很简单
2、ES中的mappings
ES的mapping如何用?什么时候需要手动,什么时候需要自动?
Mapping,就是对索引库中索引的字段名称及其数据类型进行定义,类似于mysql中的表结构信息。不过es的mapping比数据库灵活很多,它可以动态识别字段。一般不需要指定mapping都可以,因为es会自动根据数据格式识别它的类型,如果你需要对某些字段添加特殊属性(如:定义使用其它分词器、是否分词、是否存储等),就必须手动添加mapping。
我们在es中添加索引数据时不需要指定数据类型,es中有自动影射机制,字符串映射为string,数字映射为long。通过mappings可以指定数据类型是否存储等属性。
查询索引库的mapping信息
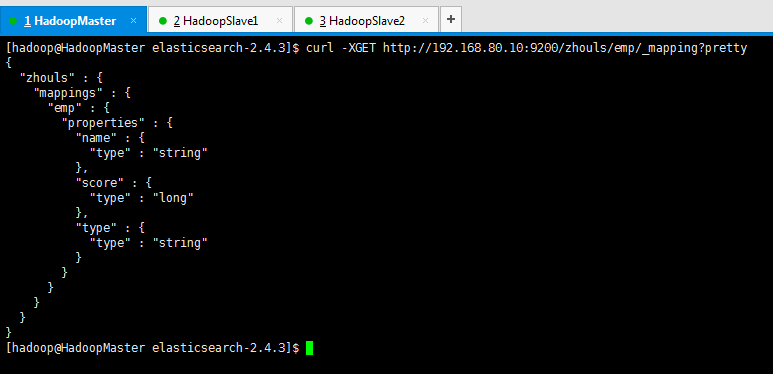
[hadoop@HadoopMaster elasticsearch-2.4.3]$ curl -XGET http://192.168.80.10:9200/zhouls/emp/_mapping?pretty
{
"zhouls" : {
"mappings" : {
"emp" : {
"properties" : {
"name" : {
"type" : "string"
},
"score" : {
"type" : "long"
},
"type" : {
"type" : "string"
}
}
}
}
}
}
[hadoop@HadoopMaster elasticsearch-2.4.3]$
mappings修改字段相关属性
例如:字段类型,使用哪种分词工具啊等,如下:
注意:下面可以使用indexAnalyzer定义分词器,也可以使用index_analyzer定义分词器
操作不存在的索引
curl -XPUT '192.168.80.10:9200/zhouls' -d'{"mappings":{"emp":{"properties":{"name":{"type":"string","analyzer": "ik_max_word"}}}}}'
操作已存在的索引
curl -XPOST http://192.168.80.10:9200/zhouls/emp/_mapping -d'{"properties":{"name":{"type":"string","analyzer": "ik_max_word"}}}'
也许我上面这样写,很多人不太懂,我下面,就举个例子。(大家必须要会)

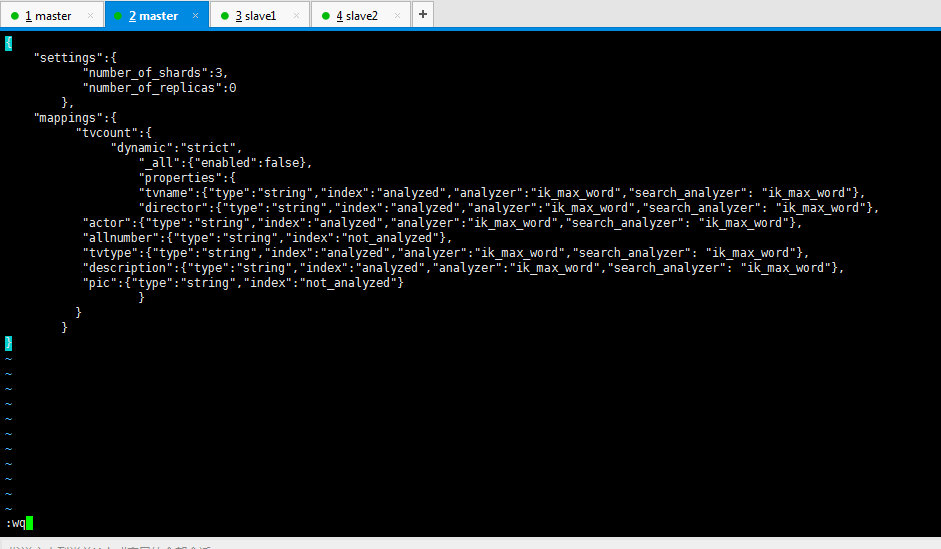
第一步:先编辑tvcount.json文件
内容如下(做了笔记):
{
"settings":{ #settings是修改分片和副本数的
"number_of_shards":3, #分片为3
"number_of_replicas":0 #副本数为0},
"mappings":{ #mappings是修改字段和类型的
"tvcount":{
"dynamic":"strict",
"_all":{"enabled":false},
"properties":{
"tvname":{"type":"string","index":"analyzed","analyzer":"ik_max_word","search_analyzer": "ik_max_word"},
如,string类型,analyzed索引,ik_max_word分词器
"director":{"type":"string","index":"analyzed","analyzer":"ik_max_word","search_analyzer": "ik_max_word"},
"actor":{"type":"string","index":"analyzed","analyzer":"ik_max_word","search_analyzer": "ik_max_word"},
"allnumber":{"type":"string","index":"not_analyzed"},
"tvtype":{"type":"string","index":"analyzed","analyzer":"ik_max_word","search_analyzer": "ik_max_word"},
"description":{"type":"string","index":"analyzed","analyzer":"ik_max_word","search_analyzer": "ik_max_word"},
"pic":{"type":"string","index":"not_analyzed"}
}
}
}
}
即,tvname(电视名称) director(导演) actor(主演) allnumber(总播放量)
tvtype(电视类别) description(描述)
‘’
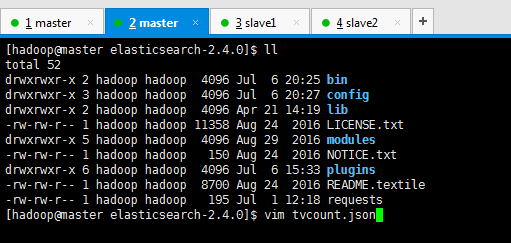
[hadoop@master elasticsearch-2.4.0]$ ll
total 52drwxrwxr-x 2 hadoop hadoop 4096 Jul 6 20:25bin
drwxrwxr-x 3 hadoop hadoop 4096 Jul 6 20:27config
drwxrwxr-x 2 hadoop hadoop 4096 Apr 21 14:19lib
-rw-rw-r-- 1 hadoop hadoop 11358 Aug 24 2016LICENSE.txt
drwxrwxr-x 5 hadoop hadoop 4096 Aug 29 2016modules
-rw-rw-r-- 1 hadoop hadoop 150 Aug 24 2016NOTICE.txt
drwxrwxr-x 6 hadoop hadoop 4096 Jul 6 15:33plugins
-rw-rw-r-- 1 hadoop hadoop 8700 Aug 24 2016README.textile
-rw-rw-r-- 1 hadoop hadoop 195 Jul 1 12:18requests
[hadoop@master elasticsearch-2.4.0]$ vim tvcount.json

{
"settings":{
"number_of_shards":3,
"number_of_replicas":0},
"mappings":{
"tvcount":{
"dynamic":"strict",
"_all":{"enabled":false},
"properties":{
"tvname":{"type":"string","index":"analyzed","analyzer":"ik_max_word","search_analyzer": "ik_max_word"},
"director":{"type":"string","index":"analyzed","analyzer":"ik_max_word","search_analyzer": "ik_max_word"},
"actor":{"type":"string","index":"analyzed","analyzer":"ik_max_word","search_analyzer": "ik_max_word"},
"allnumber":{"type":"string","index":"not_analyzed"},
"tvtype":{"type":"string","index":"analyzed","analyzer":"ik_max_word","search_analyzer": "ik_max_word"},
"description":{"type":"string","index":"analyzed","analyzer":"ik_max_word","search_analyzer": "ik_max_word"},
"pic":{"type":"string","index":"not_analyzed"}
}
}
}
}
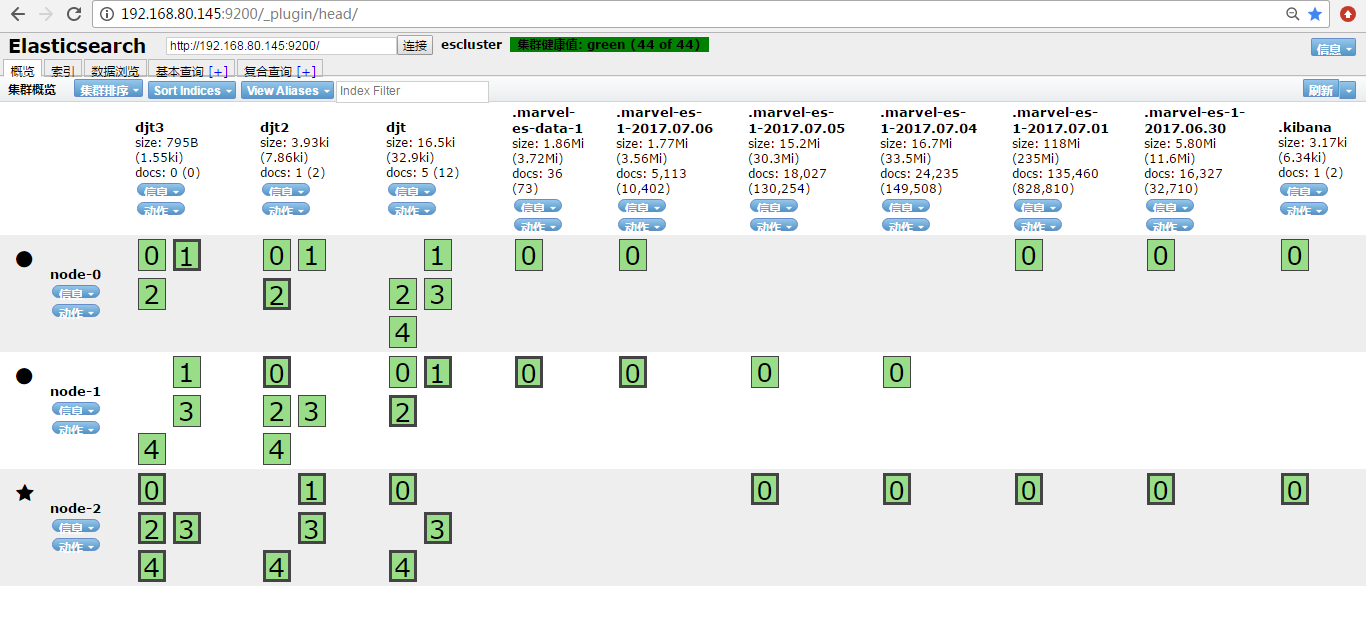
http://192.168.80.145:9200/_plugin/head/
第二步:创建mapping
这里,因为,之前,我们是在/home/hadoop/app/elasticsearch-2.4.0下,这个目录下有我们刚之前写的tvcount.json,所以可以直接
curl -XPOST 'http://master:9200/tv' -d @tvcount.json
不然的话,就需要用绝对路径
[hadoop@master elasticsearch-2.4.0]$ pwd
/home/hadoop/app/elasticsearch-2.4.0[hadoop@master elasticsearch-2.4.0]$ ll
total 56drwxrwxr-x 2 hadoop hadoop 4096 Jul 6 20:25bin
drwxrwxr-x 3 hadoop hadoop 4096 Jul 6 20:27config
drwxrwxr-x 2 hadoop hadoop 4096 Apr 21 14:19lib
-rw-rw-r-- 1 hadoop hadoop 11358 Aug 24 2016LICENSE.txt
drwxrwxr-x 5 hadoop hadoop 4096 Aug 29 2016modules
-rw-rw-r-- 1 hadoop hadoop 150 Aug 24 2016NOTICE.txt
drwxrwxr-x 6 hadoop hadoop 4096 Jul 6 15:33plugins
-rw-rw-r-- 1 hadoop hadoop 8700 Aug 24 2016README.textile
-rw-rw-r-- 1 hadoop hadoop 195 Jul 1 12:18requests
-rw-rw-r-- 1 hadoop hadoop 1022 Jul 6 22:27tvcount.json
[hadoop@master elasticsearch-2.4.0]$ curl -XPOST 'http://master:9200/tv' -d @tvcount.json
{"acknowledged":true}[hadoop@master elasticsearch-2.4.0]$
[hadoop@master elasticsearch-2.4.0]$
[hadoop@master elasticsearch-2.4.0]$
简单的说,就是
settings是修改分片和副本数的。
mappings是修改字段和类型的。
具体,见我的博客
然后,再来查询下
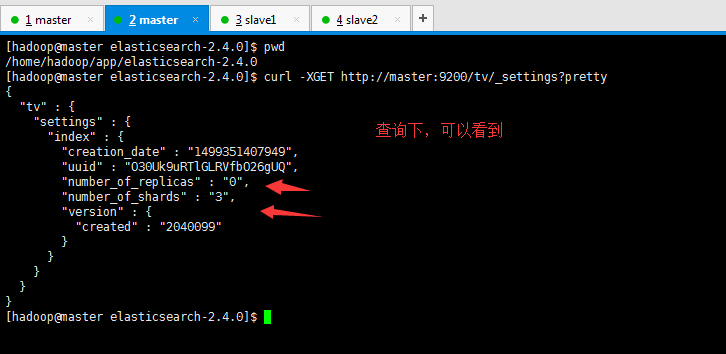
[hadoop@master elasticsearch-2.4.0]$ pwd
/home/hadoop/app/elasticsearch-2.4.0[hadoop@master elasticsearch-2.4.0]$ curl -XGET http://master:9200/tv/_settings?pretty
{
"tv": {
"settings": {
"index": {
"creation_date" : "1499351407949",
"uuid" : "O30Uk9uRTlGLRVfbO26gUQ",
"number_of_replicas" : "0",
"number_of_shards" : "3",
"version": {
"created" : "2040099"}
}
}
}
}
[hadoop@master elasticsearch-2.4.0]$
然后,再来查看mapping(mappings是修改字段和类型的)
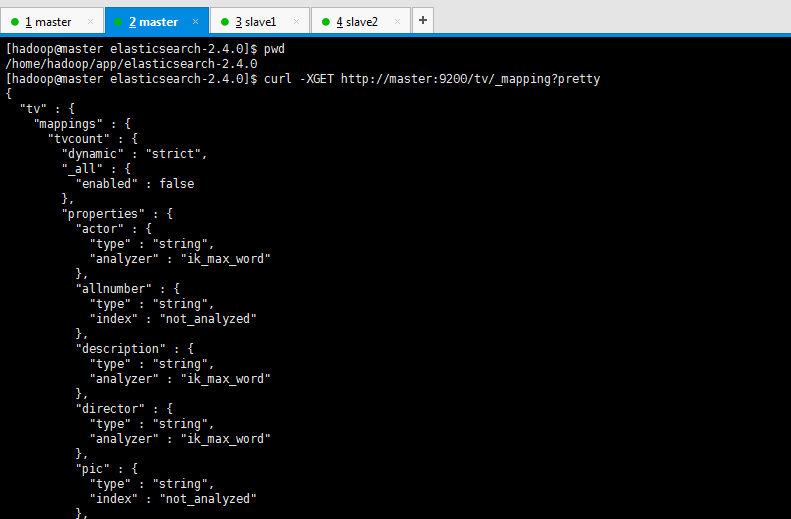
[hadoop@master elasticsearch-2.4.0]$ pwd
/home/hadoop/app/elasticsearch-2.4.0[hadoop@master elasticsearch-2.4.0]$ curl -XGET http://master:9200/tv/_mapping?pretty
{
"tv": {
"mappings": {
"tvcount": {
"dynamic" : "strict",
"_all": {
"enabled" : false},
"properties": {
"actor": {
"type" : "string",
"analyzer" : "ik_max_word"},
"allnumber": {
"type" : "string",
"index" : "not_analyzed"},
"description": {
"type" : "string",
"analyzer" : "ik_max_word"},
"director": {
"type" : "string",
"analyzer" : "ik_max_word"},
"pic": {
"type" : "string",
"index" : "not_analyzed"},
"tvname": {
"type" : "string",
"analyzer" : "ik_max_word"},
"tvtype": {
"type" : "string",
"analyzer" : "ik_max_word"}
}
}
}
}
}
[hadoop@master elasticsearch-2.4.0]$
说简单点就是,tvcount.json里已经初步设置好了settings和mappings。
然后启动hdfs、启动hbase
这里,很简单,不多说。
[hadoop@master elasticsearch-2.4.0]$ cd $HADOOP_HOME
[hadoop@master hadoop-2.6.0]$ jps6261Jps2451QuorumPeerMain4893Elasticsearch
[hadoop@master hadoop-2.6.0]$ sbin/start-all.sh
This scriptis Deprecated. Instead use start-dfs.sh and start-yarn.sh17/07/06 23:02:59 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes whereapplicable
Starting namenodes on [master]
master: starting namenode, logging to/home/hadoop/app/hadoop-2.6.0/logs/hadoop-hadoop-namenode-master.outslave2: starting datanode, logging to/home/hadoop/app/hadoop-2.6.0/logs/hadoop-hadoop-datanode-slave2.outslave1: starting datanode, logging to/home/hadoop/app/hadoop-2.6.0/logs/hadoop-hadoop-datanode-slave1.outStarting secondary namenodes [0.0.0.0]0.0.0.0: starting secondarynamenode, logging to /home/hadoop/app/hadoop-2.6.0/logs/hadoop-hadoop-secondarynamenode-master.out
17/07/06 23:06:46 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes whereapplicable
starting yarn daemons
starting resourcemanager, logging to/home/hadoop/app/hadoop-2.6.0/logs/yarn-hadoop-resourcemanager-master.outslave2: starting nodemanager, logging to/home/hadoop/app/hadoop-2.6.0/logs/yarn-hadoop-nodemanager-slave2.outslave1: starting nodemanager, logging to/home/hadoop/app/hadoop-2.6.0/logs/yarn-hadoop-nodemanager-slave1.out[hadoop@master hadoop-2.6.0]$ jps6721ResourceManager6987Jps6390NameNode2451QuorumPeerMain6579SecondaryNameNode4893Elasticsearch
[hadoop@master hadoop-2.6.0]$
[hadoop@slave1 elasticsearch-2.4.0]$ jps5725Elasticsearch2296QuorumPeerMain6615NodeManager6529DataNode6683Jps
[hadoop@slave1 elasticsearch-2.4.0]$
[hadoop@slave2 elasticsearch-2.4.0]$ jps6826NodeManager5407Elasticsearch7015Jps6748DataNode2229QuorumPeerMain
[hadoop@slave2 elasticsearch-2.4.0]$
[hadoop@master hadoop-2.6.0]$ cd $HBASE_HOME
[hadoop@master hbase]$ bin/start-hbase.sh
starting master, logging to/home/hadoop/app/hbase/logs/hbase-hadoop-master-master.outslave2: regionserver runningas process 7175. Stop it first.
slave1: starting regionserver, logging to/home/hadoop/app/hbase/bin/../logs/hbase-hadoop-regionserver-slave1.out[hadoop@master hbase]$ jps6721ResourceManager7214HMaster6390NameNode2451QuorumPeerMain6579SecondaryNameNode4893Elasticsearch7327Jps
[hadoop@master hbase]$
[hadoop@slave1 hbase]$ jps7210Jps7145HRegionServer5725Elasticsearch2296QuorumPeerMain6615NodeManager6529DataNode6969HMaster
[hadoop@slave1 hbase]$
[hadoop@slave2 hbase]$ jps6826NodeManager5407Elasticsearch7470Jps7337HMaster6748DataNode7175HRegionServer2229QuorumPeerMain
[hadoop@slave2 hbase]$
打开进入hbase shell

[hadoop@master hbase]$ bin/hbase shell2017-07-06 23:41:03,412 INFO [main] Configuration.deprecation: hadoop.native.lib isdeprecated. Instead, use io.native.lib.available
HBase Shell; enter'help' forlist of supported commands.
Type"exit"to leave the HBase Shell
Version0.98.19-hadoop2, r1e527e73bc539a04ba0fa4ed3c0a82c7e9dd7d15, Fri Apr 22 19:07:24 PDT 2016hbase(main):001:0>
查询一下有哪些库

hbase(main):001:0>list
TABLE2017-07-06 23:51:21,204 WARN [main] util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes whereapplicable
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found bindingin [jar:file:/home/hadoop/app/hbase-0.98.19/lib/slf4j-log4j12-1.6.4.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found bindingin [jar:file:/home/hadoop/app/hadoop-2.6.0/share/hadoop/common/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
0 row(s) in 266.1210seconds=> []
如果tvcount数据库已经存在的话可以删除掉
hbase(main):002:0> disable 'tvcount'ERROR: Table tvcount does not exist.
Hereis some help for thiscommand:
Start disable of named table:
hbase> disable 't1'hbase> disable 'ns1:t1'hbase(main):003:0> drop 'tvcount'ERROR: Table tvcount does not exist.
Hereis some help for thiscommand:
Drop the named table. Table must first be disabled:
hbase> drop 't1'hbase> drop 'ns1:t1'hbase(main):004:0>list
TABLE0 row(s) in 1.3770seconds=>[]
hbase(main):005:0>
然后,启动mysql数据库,创建数据库创建表

进一步,可以见
http://www.cnblogs.com/zlslch/p/6746922.html