TensorFlow2实现Policy Gradient
一、原理
我找了很多资料,我发现李宏毅讲的是最清楚的: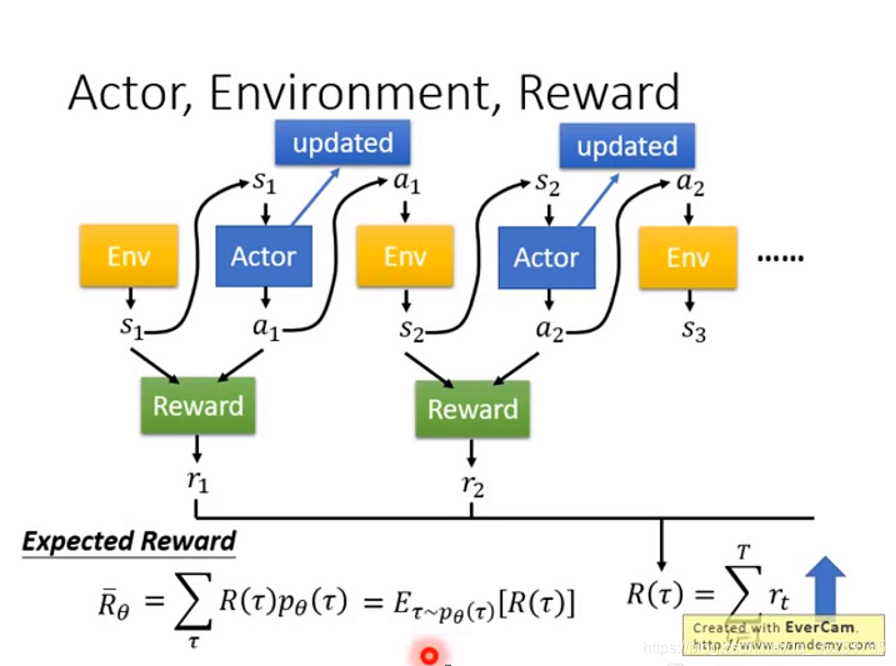
将这个图在具体一下,就是policy gradient的工作图了: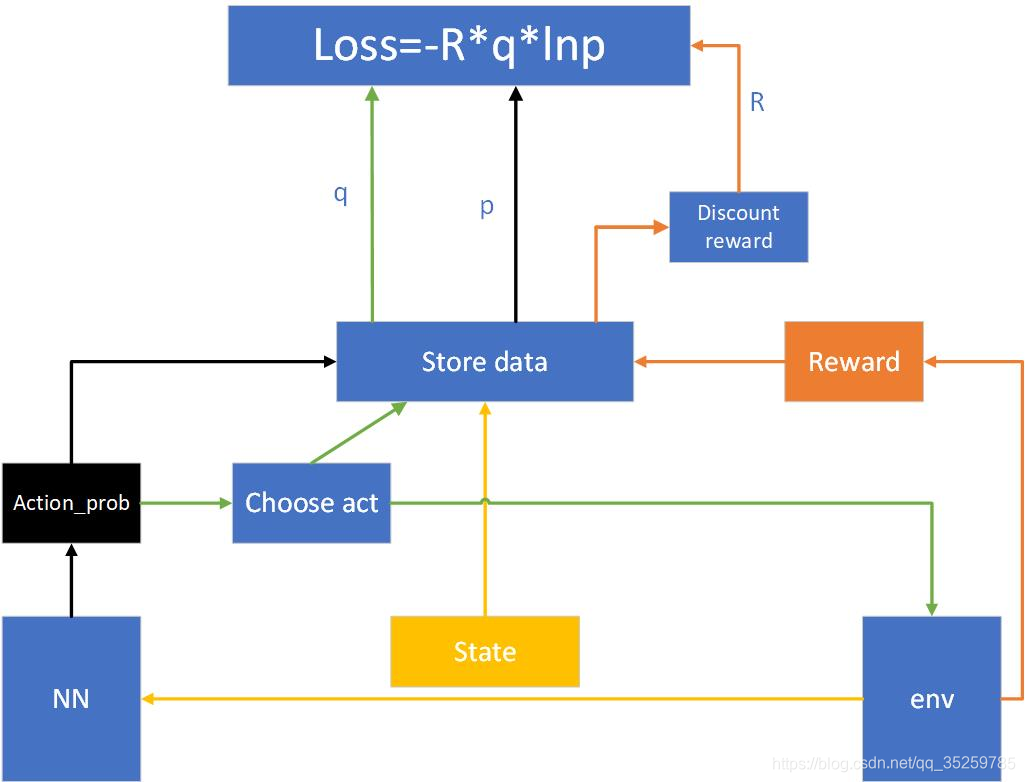
下面的代码就是按照这个流程图实现的。
二、网络搭建
PG_Brain.py
import tensorflow as tf
from tensorflow.keras import layers
import numpy as np
class PG:
def __init__(self, inputs, outs,
learning_rate=0.01,
gamma=0.9
):
self.n_features = inputs
self.actions = outs
self.evn_observation, self.evn_reward, self.evn_action = [], [], []
self.lr = learning_rate
self.gamma = gamma # reward衰减量
self.model = self._built_net()
def _built_net(self):
model = tf.keras.Sequential([
layers.Dense(16, input_dim=self.n_features, activation="relu"),
layers.Dense(self.actions, activation='softmax')
])
model.compile(loss="sparse_categorical_crossentropy", optimizer=tf.optimizers.Adam(lr=self.lr))
return model
# store data
def get_S_R_A(self, Observation, reward, action):
self.evn_observation.append(Observation)
self.evn_reward.append(reward)
self.evn_action.append(action)
def choose_action(self, observation):
state = np.array([observation])
action_prob = self.model.predict(state) # 获取概率
# 获取选择左还是右的总概率
action_prob = np.sum(action_prob, axis=0)
action_prob /= np.sum(action_prob)
return np.random.choice([0, 1], p=action_prob)
def discount_reward_and_norm(self):
discount_reward = np.zeros_like(self.evn_reward)
prior = 0
for i in reversed(range(len(self.evn_reward))):
prior = prior * self.gamma + self.evn_reward[i]
discount_reward[i] = prior
discount_reward -= np.mean(discount_reward)
discount_reward /= np.std(discount_reward)
return discount_reward
def learn(self,cp_callback):
discount_reward = self.discount_reward_and_norm()
history = self.model.fit(np.vstack(self.evn_observation), np.vstack(self.evn_action),
sample_weight=discount_reward,callbacks=[cp_callback])
self.evn_action, self.evn_observation, self.evn_reward = [], [], []
return history
三、学习过程
cartpole.py
import gym
from PG_Brain import PG
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
import os
env = gym.make('CartPole-v0')
checkpoint_save_path = "./checkpoint/fashion.ckpt"
RL = PG(env.observation_space.shape[0], env.action_space.n)
if os.path.exists(checkpoint_save_path + '.index'):
print('-------------load the model-----------------')
RL.model.load_weights(checkpoint_save_path)
cp_callback = tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_save_path,
save_weights_only=True,
save_best_only=False)
for i_episode in range(100):
observation = env.reset()
while True:
action = RL.choose_action(observation)
observation_, reward, done, info = env.step(action)
RL.get_S_R_A(observation, reward, action, )
# print(reward)
if done:
vl = RL.learn(cp_callback)
break
observation = observation_
env.close()
四、利用训练好的模型进行控制
import tensorflow as tf
from tensorflow.keras import layers
import numpy as np
import os
import gym
env = gym.make('CartPole-v0')
env.seed(1)
env = env.unwrapped
model = tf.keras.Sequential([
layers.Dense(16, input_dim=env.observation_space.shape[0], activation="relu"),
layers.Dense(env.action_space.n, activation='softmax')
])
model.compile(loss="sparse_categorical_crossentropy", optimizer=tf.optimizers.Adam(0.01))
checkpoint_save_path = "./checkpoint/fashion.ckpt"
model.load_weights(checkpoint_save_path)
def choose_action(observation):
state = np.array([observation])
action_prob = model.predict(state) # 获取概率
# 获取选择左还是右的总概率
action_prob = np.sum(action_prob, axis=0)
action_prob /= np.sum(action_prob)
return np.random.choice([0, 1], p=action_prob)
for i_episode in range(1000):
step = 0
while True:
env.render()
action = choose_action(observation)
observation_, reward, done, info = env.step(action)
step +=1
# print(reward)
if done:
print(step)
break
observation = observation_
env.close()
六、测试结果
100episode
版权声明:本文为qq_35259785原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。