首先需要说明的是,本文在写时仅仅依靠着对论文的解读,具体代码的实现还没有看。最终可能也不一定会看源码,会找一个合适的进行详细的学习。通过阅读以下两篇论文及翻译,总结出一些网络的特点记录在这里,方便之后的查找。
Faster R-CNN https://arxiv.org/abs/1506.01497
翻译:https://blog.csdn.net/quincuntial/article/details/79132243
SSD https://arxiv.org/abs/1512.02325
翻译:https://blog.csdn.net/quincuntial/article/details/78854930
这两篇文章是2016年具有开拓性的两篇目标检测类的文章。
Faster R-CNN
Conv layers。作为一种CNN网络目标检测方法,Faster RCNN首先使用一组基础的conv+relu+pooling层提取image的feature maps。该feature maps被共享用于后续RPN层和全连接层。
Region Proposal Networks。RPN网络用于生成region proposals。该层通过softmax判断anchors属于foreground或者background,再利用bounding box regression修正anchors获得精确的proposals。
Roi Pooling。该层收集输入的feature maps和proposals,综合这些信息后提取proposal feature maps,送入后续全连接层判定目标类别。
Classification。利用proposal feature maps计算proposal的类别,同时再次bounding box regression获得检测框最终的精确位置。
1.区域提出网络(PRN)和检测网络共享全图像的卷积特征。全卷积网络,同时在每个位置预测目标边界和目标分数,旨在预测具有广泛尺度和长宽比的区域建议。
2.目标提议方法:基于超像素分组:基于滑动窗口的方法
R-CNN主要作为分类器,并不能预测目标边界,其准确度取决于区域提出模块的性能。
3.全连接和卷积层
卷积层:卷积层的主要作用是提取特征,通过可训练的滤波器得到权值。卷积核在图像上进行滑动,所以不必考虑图像的尺度,基于统计学原理:图像的一部分统计特性与其他部分是一样的,所以可以使用同样的学习特征。因此采用了参数共享。参数共享减少过拟合:无论图像大小,参数数量是固定的:(卷积核乘积+偏置)*卷积核个数。激活函数赋予了位移不变性,池化层由于求取了局部的平均或者最大值,使得对输入样本具有较高的畸变容忍能力。卷积层中存在多个卷积核时,每个卷积核都会将图像生成为另外一个图像,在多个通道上的卷积操作,在卷积核w的某位置(i,j)处的值,是由多个通道上的(i,j)处的卷积结果相加再取激活函数值得到的。由4个通道生成3个通道的过程中,参数的数目为4×3×2×2.(2×2为卷积核大小)。
三维卷积是使用了一个三通道的滤波器。如果原始输入图像是RGB三维,假设6×6×3,则卷积核假设为3×3×3,最终得到4×4×1而不是4×4×3的图像,三通道的滤波核可以设为不同的权值,这样就考虑了颜色所带来的不同的特征。所以三维卷积具有什么样的特征:对颜色敏感或者不敏感等等。是由于三通道具体的含义所带来的。
全连接层:全连接层通常出现在最后几层,用于整合前面所提取的特征,同时还具有分类器的作用。全连接层由于忽略了空间特性所以不适用于分割任务,但同时减少了特征位置的不同对于分类器的影响。由于全连接层卷积核和上层特征图中所有的元素均连接,所以参数数量庞大。假如上一层的输出是7×7×5,接一个全连接层4096,则相当于7×7×5×4096的卷积层去卷积上层激活函数的输出。但如果是卷积层,则可以选择更小的卷积核。所以说,卷积是全连接的弱化版本,弱化为局部连接,并强制各局部的参数一致。
所以实际上,全连接层和卷积层之间是相互转化的,二者在计算上等价,但FCN更加灵活。全连接层需要将矩阵变为1维向量,所以输入图片的大小必须一样,否则feature map不一样,全连接层的参数数量就不能确定。但是卷积不需要固定的大小,因为卷积核是独立的参数不需要有联系。全连接层还可以被GAP所替代。
4.RPN和Faster R-CNN目标检测网络共享一组共同的卷积层。
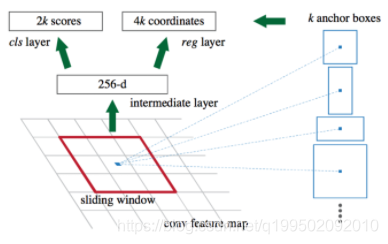
5.锚点
使用了3个缩放尺度和3个长宽比,在每个滑动位置产生9个锚点。所以对于一个w×h大小的卷积特征图总共会产生whk个锚点。每个锚点对应的边界框有(x,y,w,h)4个值来定位边界框,所以reg层有4k个输出,cls层2k个分数输出。具有平移不变的特性。
多尺度锚点解决多尺度问题优于基于图像或特征金字塔多尺度和在特征映射上使用多尺度滑动窗口的方法。该方法是共享特征的关键,无需额外的成本来处理尺度。
6.损失函数


7.训练具有共享特征的网络



8.训练细节
算法允许预测比基础感受野更大的目标。训练时,跨越图像边界的锚点需要忽略。ROI pooling层用于使每个建议窗口生成固定尺寸的feature map
9.非极大值抑制(nms)
NMS不会损害检测map并能减少误报。
SSD
1.边界框的输出空间离散化为一组默认框,该默认框在每个特征图位置有不同的宽高比和尺寸。网络组合来自不同分辨率的多个特征图的预测,以适应处理各种尺寸的对象。比yolo更快,基本和faster rcnn一样准确。速度的根本改进来自于消除边界框proposal和随后的像素或特征重采样阶段。
核心:使用小卷积滤波器来预测特征图上固定的一组默认边界框的类别分数和位置偏移。为了提高检测精度,从不同尺度的特征图产生不同尺度的预测,并且通过宽高比来明确的分离预测
2.SSD的基础网络为高质量的图像分类网络(VGG,GoogLeNet)。在基础网络的末尾添加几个特征层,这些特征层的尺寸逐渐减小,得到多个尺度检测的预测值,得到预测值所用的卷积模型对于每个特征层是不同的。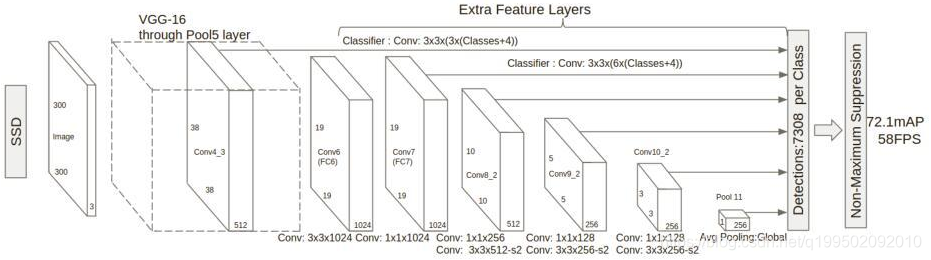
3.在每个特征映射单元中,我们预测相对于单元格中的默认框形状的偏移,以及每个框中实例的每类分数。在特征图中的每个位置共需(c+4)k个滤波器,对于m×n特征图产生(c+4)kmn个输出。特殊的,在ssd中,目标有c分类别,需要预测c+1个置信度值,还包括背景的类别。
4.先验框匹配
在进行训练时,首先确定训练图片中的ground truth 与哪个先验框相匹配,与之相匹配的先验框所对应的边界框负责预测他。
5.损失函数
定义为位置误差和置信度误差的加权和。
6.预测过程
7.ssd和faster rcnn中RPN十分的相似,但是不是使用锚点框来池化特征并评估另一个分类器,而是为每个目标类别在每个边界框中同时生成一个分数。对比于yolo,增加了多尺度特征映射。