前面介绍的主函数plot()主要用于绘制散点图和折线图,绘制其他常见的图形如柱状图、直方图、扇形图和箱形图等可以调用专门的函数。
1 柱状图
绘制基础柱状图的函数是barplot(),其语法结构如下:
barplot(height, width = 1, space = NULL,
names.arg = NULL, legend.text = NULL, beside = FALSE,
horiz = FALSE, density = NULL, angle = 45,
col = NULL, border = par("fg"),
main = NULL, sub = NULL, xlab = NULL, ylab = NULL,
xlim = NULL, ylim = NULL, xpd = TRUE, log = "",
axes = TRUE, axisnames = TRUE,
cex.axis = par("cex.axis"), cex.names = par("cex.axis"),
inside = TRUE, plot = TRUE, axis.lty = 0, offset = 0,
add = FALSE, ann = !add && par("ann"), args.legend = NULL, ...)
基本形态
height表示柱形高度,相当于y变量,数据结构为向量或者矩阵;
height为向量时,每个元素代表一组;
height为矩阵时,矩阵每列数据表示一个大组,每个元素表示一个亚组。
beside参数控制大组内亚组的摆放方式;默认值FALSE表示叠加摆放,TRUE表示并列摆放。
names.arg表示柱形的组名,相当于x变量,默认省略。
# 使用泊松分布函数生成随机数
set.seed(123)
num <- rpois(12, 6)
mat <- matrix(num, ncol = 3)
lab <- LETTERS[c(1:dim(mat)[2])]
labsub <- t(outer(lab, c(1:dim(mat)[1]), paste0))
par(fig = c(0,0.4,0,1))
barplot(mat, names.arg = lab)
par(new = T, fig = c(0.4,1,0,1))
barplot(mat, beside = T, names.arg = labsub)
细节调整
width调整柱形宽度;
width可根据柱形个数确定向量长度,当长度少于柱形个数时采用循环赋值;
单位宽度根据图形大小而定,因此该参数主要用于控制不同柱形宽度的比例,当长度为1时无意义。
space调整柱形间隔。
space默认是长度为2的向量,单位间隔为width;
第一个元素为组内间隔,第二个元素为组间间隔;也可以根据柱形个数依次赋值。
par(mfcol = c(1,2))
barplot(mat[,c(1,2)], beside = T, width = c(1,2))
barplot(mat[,c(1,2)], beside = T, width = c(1,2), space = c(0.2, 1.5))
density控制柱形内部阴影的密度;
angle控制阴影线条的倾斜角度,默认是45度;
col控制柱形内部填充颜色;
border控制柱形轮廓颜色。
par(mfcol = c(1,2))
barplot(mat, density = c(12,24,36,48), angle = c(-45, 0, 45, 90))
barplot(mat, beside = T, col = c("lightblue", "mistyrose", "lightcyan",
"lavender"), border = "red")
horiz为TRUE时,柱形水平摆放;
offset控制柱形高度与横坐标轴的偏移量,默认为0。
add为TRUE时,本句命令产生的新图形会直接添加在已存在的图形上,类似图层叠加;
当把
barplot()赋值给某变量时,返回的是每个柱形中心线的横坐标并在绘图区绘制出图形;但当plot参数为FALSE时不绘制图形,只返回中心线的横坐标;和
plot()函数一样,boxplot()也自动继承par()中的参数。
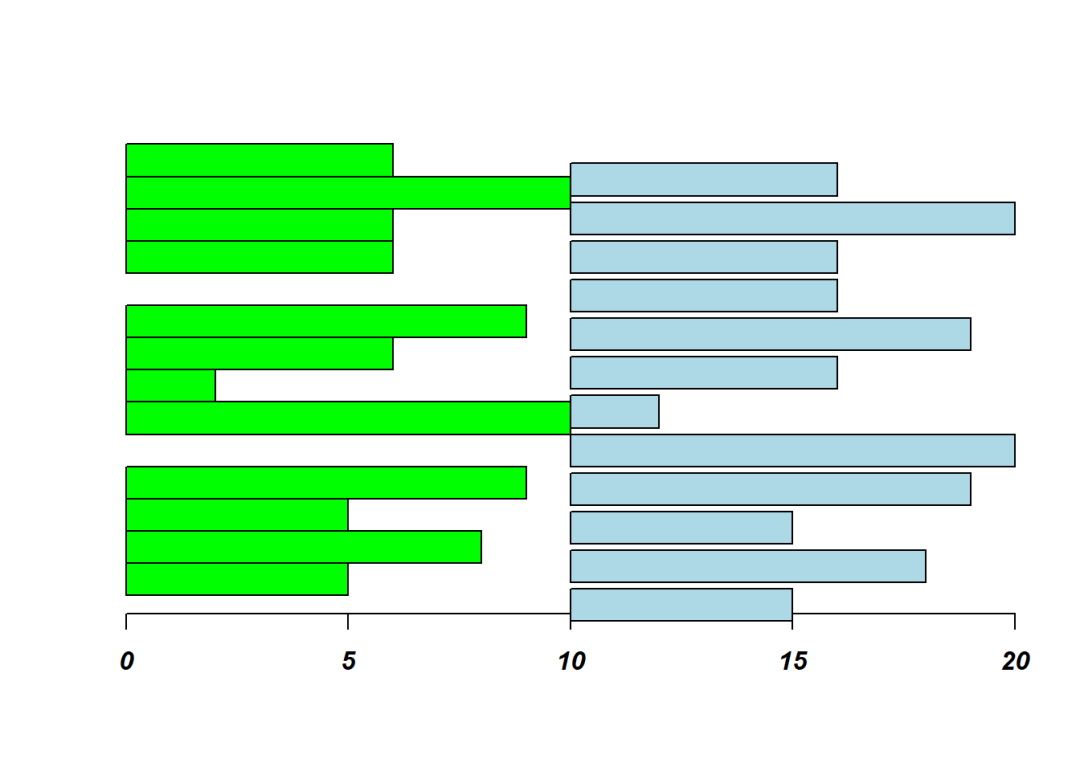
a <- barplot(mat, beside = T, horiz = T, xlim = c(0,20), col = "red", plot = F)
b <- barplot(mat, beside = T, horiz = T, xlim = c(0,20), col = "green", font = 4)
identical(a, b)
b
barplot(num, horiz = T, offset = 10, add = T, col = "lightblue", axes = F)
# 部分输出结果
identical(a, b)
## [1] TRUE
b
## [,1] [,2] [,3]
## [1,] 1.5 6.5 11.5
## [2,] 2.5 7.5 12.5
## [3,] 3.5 8.5 13.5
## [4,] 4.5 9.5 14.5
barplot()还可以用变量之间的函数形式来指明绘图变量和分组变量,其语法结构如下:
barplot(formula, data, subset, na.action,
horiz = FALSE, xlab = NULL, ylab = NULL, ...)
formula的基本形式为
y ~ x,其中y为绘图变量,x为分组变量,有以下三种形式:
y ~ x;
y ~ x1 + x2;
cbind(y1, y2) ~ x。
data为公式中变量所在的数据框或list;
当data中的分组变量控制的分组对应的绘图变量数值不唯一时,需使用subset取data的子集使之唯一;
前面的细节调整参数在该语法结构中仍然适用。
par(mfcol = c(1,2))
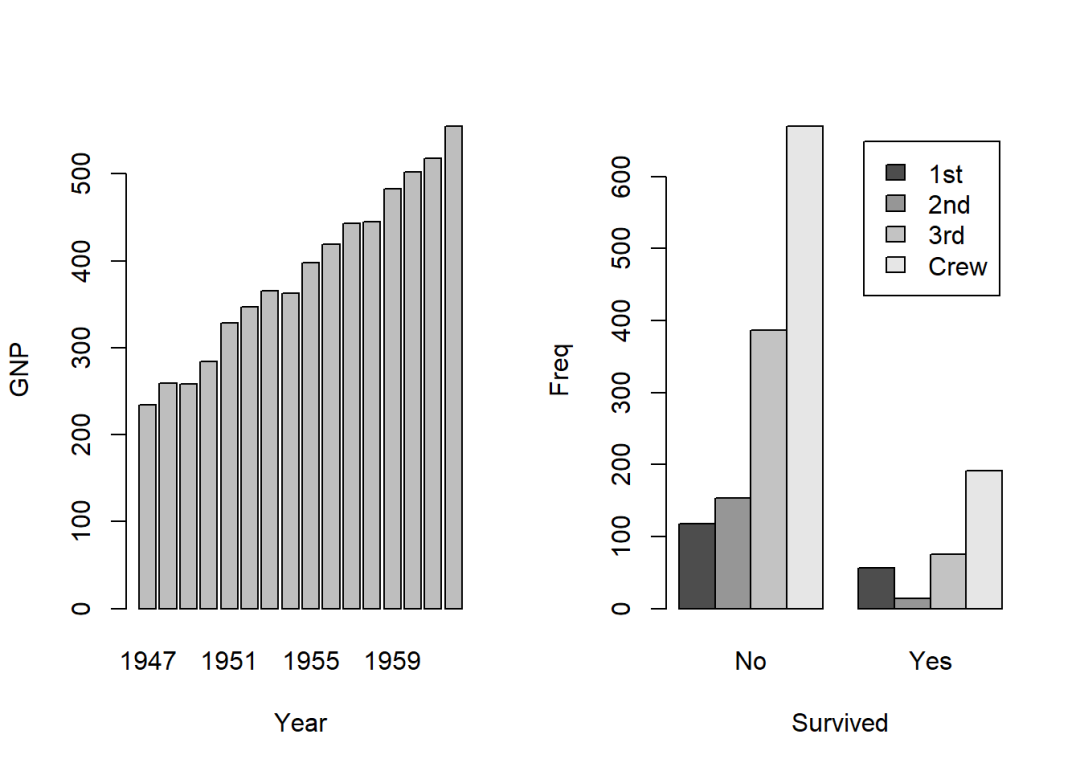
barplot(GNP ~ Year, data = longley)
d.Titanic <- as.data.frame(Titanic)
d.Titanic
barplot(Freq ~ Class + Survived, data = d.Titanic, subset = Age == "Adult" & Sex == "Male", legend = T, beside = T)
# 部分输出结果
d.Titanic
## Class Sex Age Survived Freq
## 1 1st Male Child No 0
## 2 2nd Male Child No 0
## 3 3rd Male Child No 35
## 4 Crew Male Child No 0
## 5 1st Female Child No 0
## 6 2nd Female Child No 0
## 7 3rd Female Child No 17
## 8 Crew Female Child No 0
## 9 1st Male Adult No 118
## 10 2nd Male Adult No 154
## 11 3rd Male Adult No 387
## 12 Crew Male Adult No 670
## 13 1st Female Adult No 4
## 14 2nd Female Adult No 13
## 15 3rd Female Adult No 89
## 16 Crew Female Adult No 3
## 17 1st Male Child Yes 5
## 18 2nd Male Child Yes 11
## 19 3rd Male Child Yes 13
## 20 Crew Male Child Yes 0
## 21 1st Female Child Yes 1
## 22 2nd Female Child Yes 13
## 23 3rd Female Child Yes 14
## 24 Crew Female Child Yes 0
## 25 1st Male Adult Yes 57
## 26 2nd Male Adult Yes 14
## 27 3rd Male Adult Yes 75
## 28 Crew Male Adult Yes 192
## 29 1st Female Adult Yes 140
## 30 2nd Female Adult Yes 80
## 31 3rd Female Adult Yes 76
## 32 Crew Female Adult Yes 20
2 直方图
直方图是使用原始数据经过统计变换后得到分组的频率或频数绘制的柱状图,实质是离散的密度图。hist()函数会自动进行统计变换,语法结构如下:
hist(x, breaks = "Sturges",
freq = NULL, probability = !freq,
include.lowest = TRUE, right = TRUE,
density = NULL, angle = 45, col = NULL, border = NULL,
main = paste("Histogram of" , xname),
xlim = range(breaks), ylim = NULL,
xlab = xname, ylab,
axes = TRUE, plot = TRUE, labels = FALSE,
nclass = NULL, warn.unused = TRUE, ...)
基本形态
x为原始数据序列;
freq为TRUE表示统计频数,probability为TRUE表示统计频率;默认情况下统计频数。
# 使用泊松分布生产随机数
set.seed(123)
num <- rpois(100, 10)
num
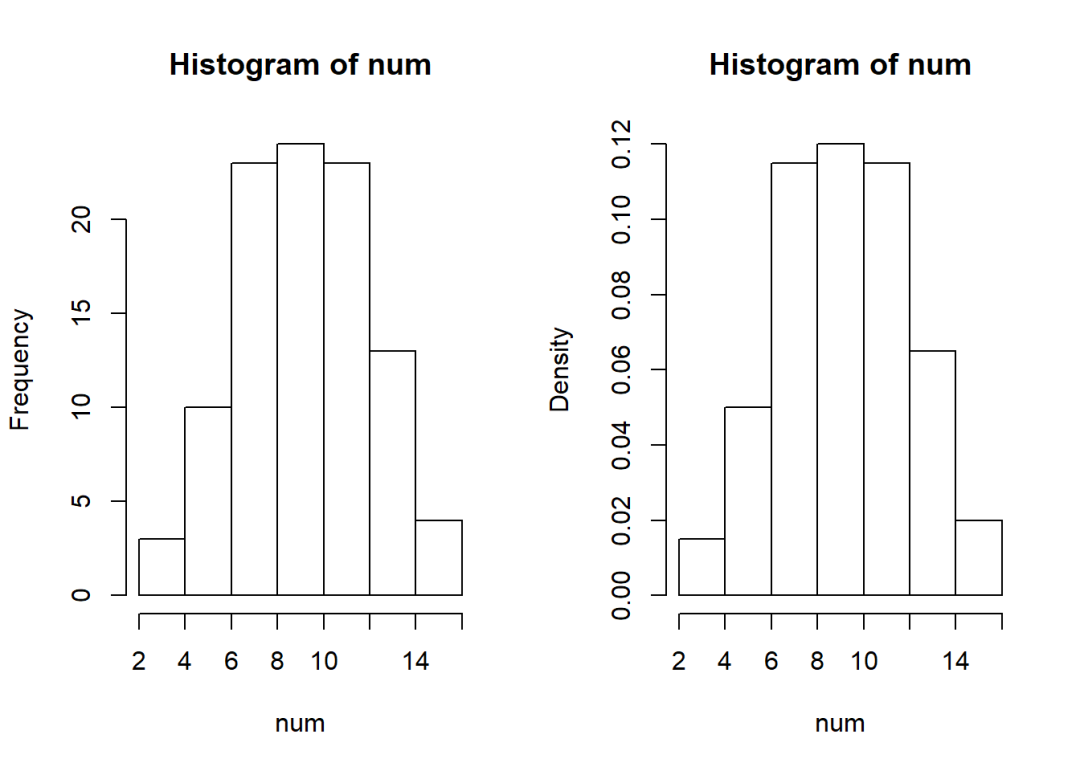
par(mfcol = c(1,2))
hist(num)
hist(num, probability = T)
# 部分输出结果
num
## [1] 8 9 14 10 10 15 11 5 4 13 11 11 10 8 15 11 3 7 6 8 6 8 4 6 6
## [26] 8 5 12 12 12 12 11 9 9 8 7 12 9 13 7 8 8 12 9 10 9 9 14 9 14
## [51] 5 6 10 11 8 8 6 11 13 12 11 12 9 9 7 7 11 9 7 10 9 10 11 8 12
## [76] 9 11 13 11 8 13 13 11 10 8 14 8 16 14 9 6 15 10 13 8 7 7 11 9 14
breaks表示分组区间的起始和终止点。有以下几种计算方式:
向量形式,必须保证所有数都包括在向量指定的范围内;
指定分组的数量;
指定算法,包括Sturges(默认)、Scott和FD,具体见
grDevices::nclass()函数。
right控制分组区间的闭合形式,默认值TRUE表示左开右闭,FALSE表示左闭右开;
include.lowest控制首尾两个区间的闭合形式,默认值TRUE表示首尾区间为完全闭合区间,为FASLE表示根据right参数决定左开右闭或左闭右开。
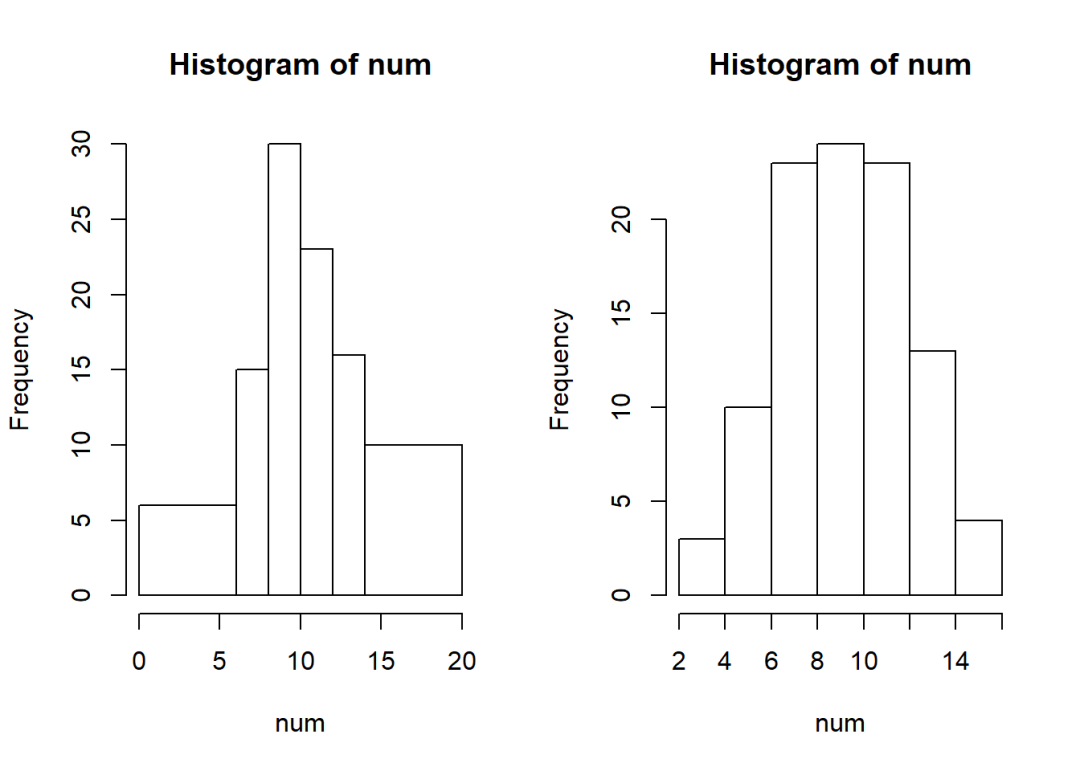
par(mfcol = c(1,2))
hist(num, right = F, breaks = c(0,6,8,10,12,14,20), freq = T)
hist(num, breaks = "Scott")
细节调整参数同barplot()函数
3 扇形图
扇形图(饼图)的绘制函数为pie()。扇形图的实质是极坐标下的频率直方图,但是pie()函数并不会自动进行统计变换。语法结构如下:
pie(x, labels = names(x), edges = 200, radius = 0.8,
clockwise = FALSE, init.angle = if(clockwise) 90 else 0,
density = NULL, angle = 45, col = NULL, border = NULL,
lty = NULL, main = NULL, ...)
基本形态
x为统计变换后的频率数据序列,会根据数值大小同比例地转换为百分比。
细节调整
饼图的外轮廓实际上是多边形,边数由edges指定,默认为200;
clockwise表示绘制的方向,默认值FALSE表示逆时针;
init.angle表示绘制的起始角度,逆时针时默认为0度(3点钟位置),顺时针时默认为90度(12点钟位置);
labels用于给扇形图各区域命名。
# 使用泊松分布生产随机数
par(mfcol = c(1,2))
set.seed(123)
num <- rpois(10, 3)
num
pie(num)
n <- tapply(num, num, length) # 统计个数
pie(n)
pie(n, edges = 10, init.angle = 90, labels = LETTERS[c(1:length(n))])
pie(n, edges = 100, clockwise = T, labels = LETTERS[c(1:length(n))])
# 部分输出结果
num
## [1] 2 4 2 5 6 0 3 5 3 3


其他细节调整参数同barplot()函数
4 箱形图
箱形图主要用于展示数据分布情况,绘制函数为boxplot(),语法结构如下:
boxplot(x, ..., range = 1.5, width = NULL, varwidth = FALSE,
notch = FALSE, outline = TRUE, names, plot = TRUE,
border = par("fg"), col = NULL, log = "",
pars = list(boxwex = 0.8, staplewex = 0.5, outwex = 0.5),
ann = !add, horizontal = FALSE, add = FALSE, at = NULL)
基本形态
箱形图的构成:
箱形中间的横线表示数据序列的中位数,上下边表示上四分位(Q3)和下四分位(Q1);箱形高度为内距(IQR = Q3 - Q1);
箱形外的两个横线表示数据的正常分布范围,与箱形的距离用内距的倍数表示,一般取1.5倍,即上侧横线的位置为Q3 + 1.5*IQR,下侧横线的位置为Q1 - 1.5*IQR;
横线范围外为异常值,使用散点表示。
相应控制参数:
x和
...代表原始数据序列;range控制箱形外横线的位置,默认值1.5表示距离箱形1.5个内距;
outline控制异常值是否显示,默认值TRUE表示显示。
set.seed(123)
num <- rpois(100, 12)
num2 <- rpois(200, 8)
par(mfcol = c(1,2))
boxplot(num, range = 1.1)
boxplot(num, num2, range = 1.1, outline = F)
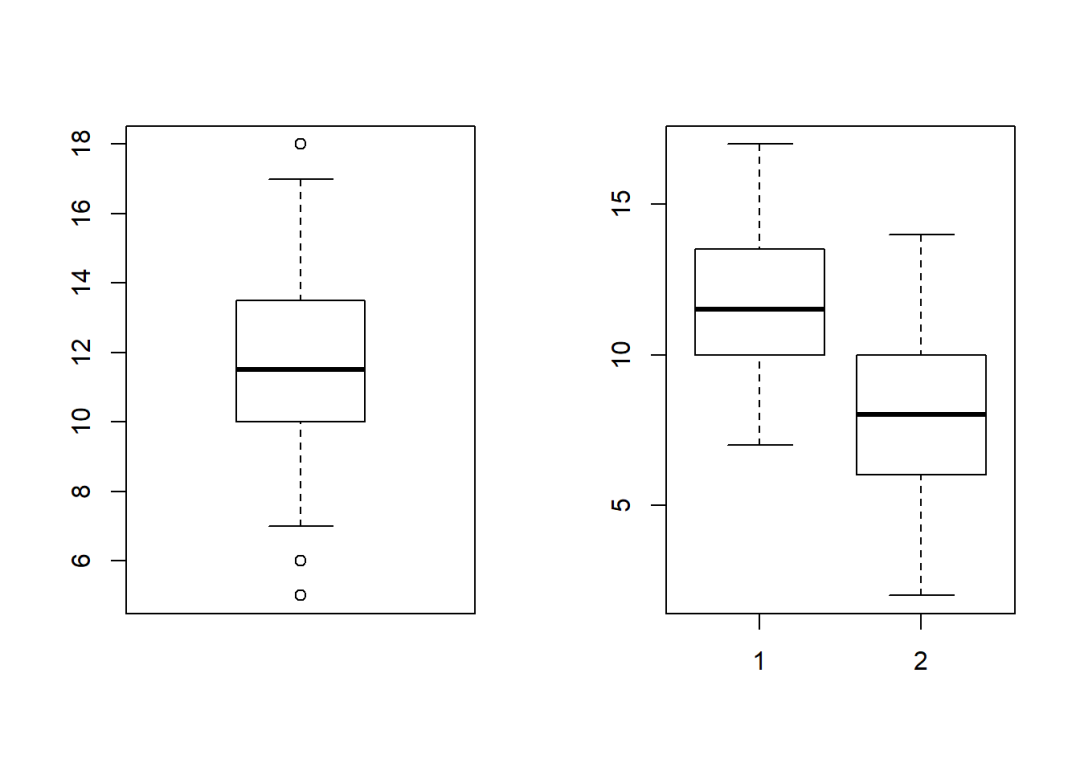
细节调整
notch调整箱形形状;
width控制多个箱形宽度的比例;
varwidth默认值为FASLE,为TRUE时表示箱形宽度与数据量成正比。
par(mfcol = c(1,2))
boxplot(num, num2, notch = T, width = c(2,1))
boxplot(num, num2, notch = T, varwidth = T)
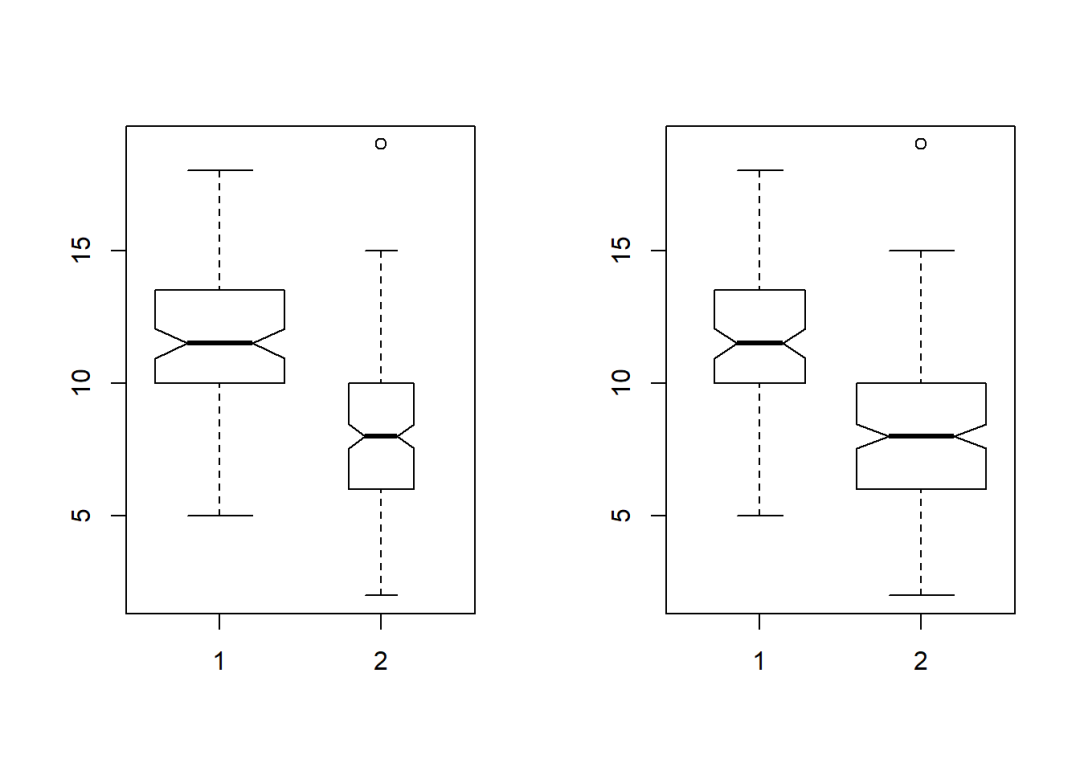
boxwex控制箱形和箱形外横线的绝对宽度;
staplewex只控制箱形外横线的绝对宽度。
par(mfcol = c(1,2))
boxplot(num, num2, boxwex = c(0.8, 1))
boxplot(num, num2, staplewex = c(0.5, 0.8))
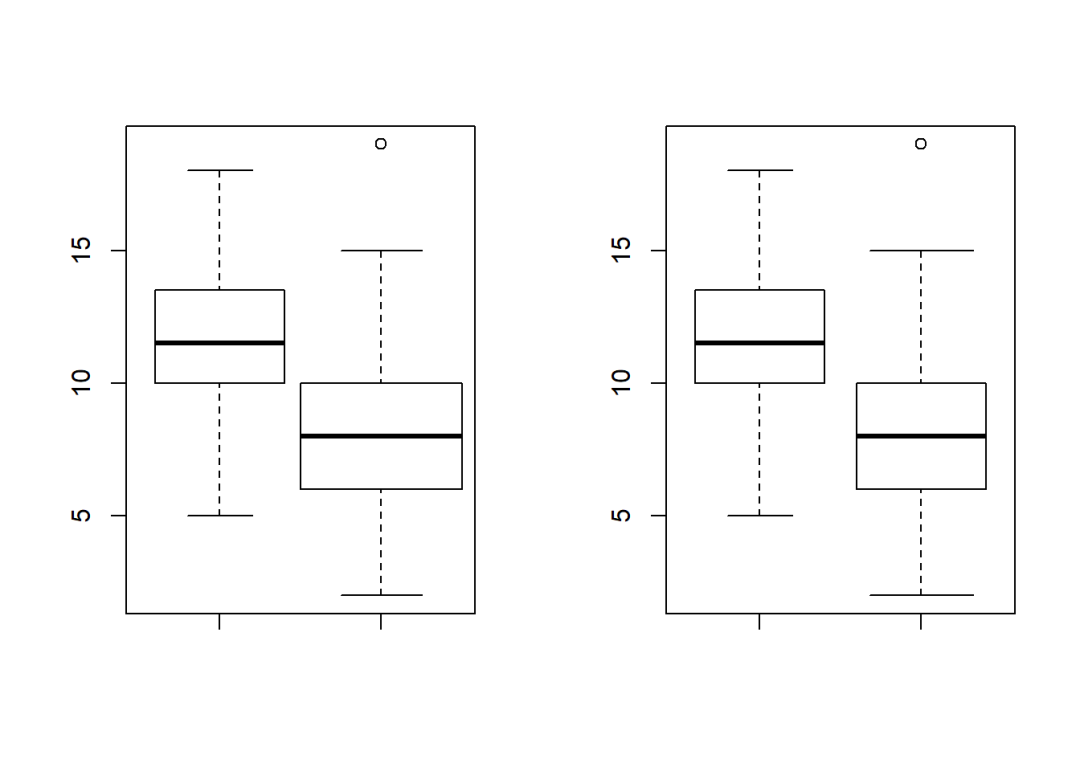
at控制箱形的横坐标,可配合add参数使用;
horizontal相当于
boxplot()的horiz参数;其他细节调整参数同
barplot()函数。
par(mfcol = c(1,2))
boxplot(num, xlim = c(0, 3), ylim = c(2, 20), col = "lightblue")
boxplot(num2, add = T, at = 2, col = "red")
boxplot(num, xlim = c(0, 3), ylim = c(2, 20), col = "lightblue", horizontal = T)
boxplot(num2, add = T, at = 2, col = "red", horizontal = T)
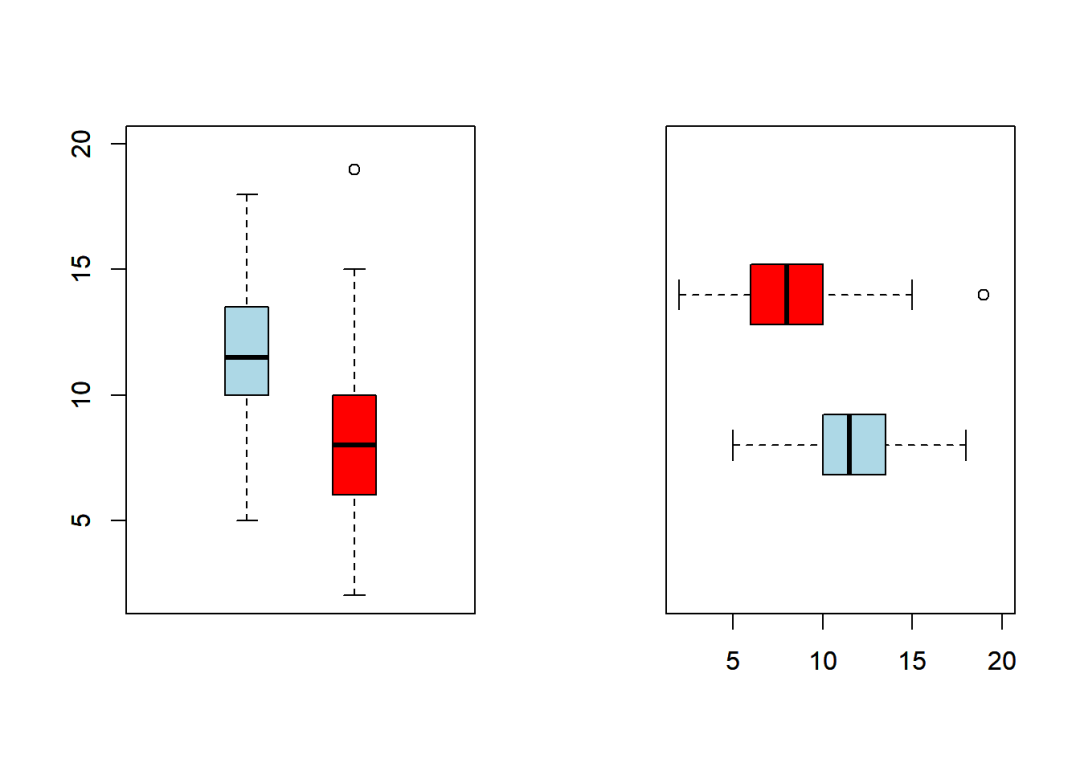
与barplot()一样,boxplot()也可以使用函数关系制定统计变量和分组变量,语法结构如下:
boxplot(formula, data = NULL, ..., subset, na.action = NULL,
xlab = mklab(y_var = horizontal),
ylab = mklab(y_var =!horizontal),
add = FALSE, ann = !add, horizontal = FALSE,
drop = FALSE, sep = ".", lex.order = FALSE)
par(mfcol = c(1,2))
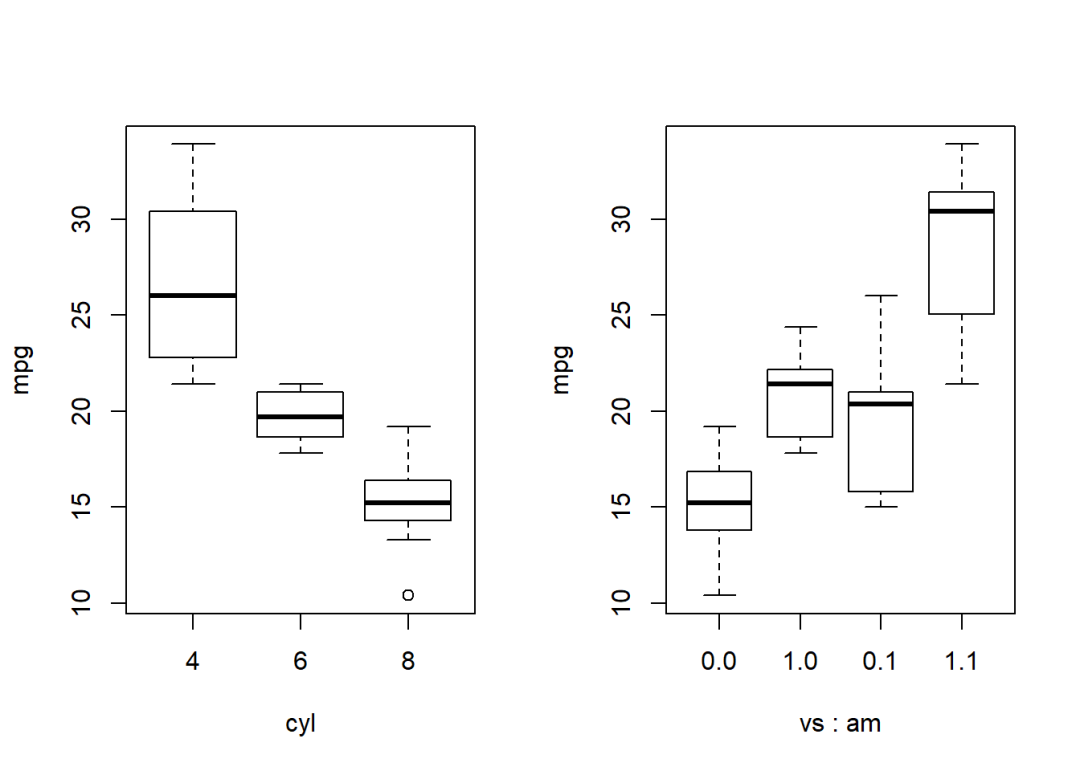
boxplot(mpg ~ cyl, data = mtcars)
boxplot(mpg ~ vs + am, data = mtcars)
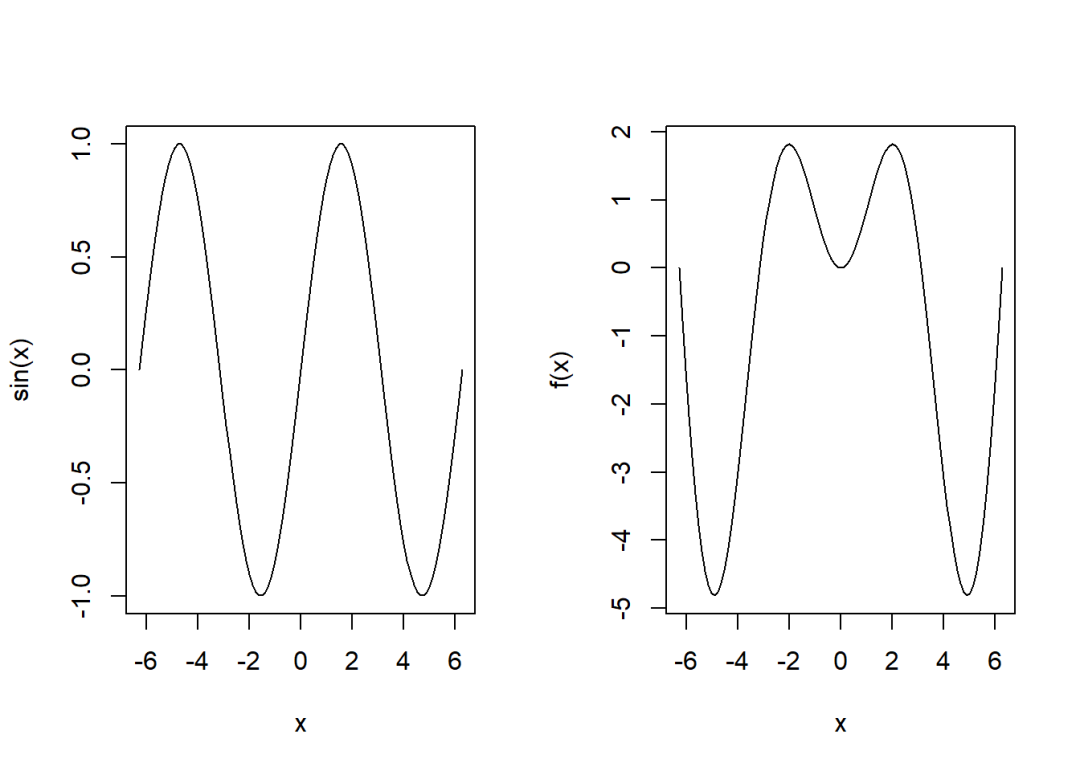
5 函数图象
curve()根据根据函数表达式绘制出某区间段的函数图象,语法结构如下:
curve(expr, from = NULL, to = NULL, n = 101, add = FALSE,
type = "l", xname = "x", xlab = xname, ylab = NULL,
log = NULL, xlim = NULL, ...)
expr为数学函数表达式,可以为系统中的函数,也可以为自定义函数;
from和to为区间的起始和终止位置;
n为绘制图像所用的描点个数,默认值为101个。
par(mfcol = c(1,2))
curve(sin, -2*pi, 2*pi)
f <- function(x) x*sin(x)
curve(f, -2*pi, 2*pi)