ILSVRC 2017 图像分类比赛冠军

Abstract
卷积神经网络建立在卷积运算的基础上,它通过在局部感受野内将空间和通道方面的信息融合在一起,来提取信息特征。为了提高网络的表达能力,最近的一些方法已经显示出空间编码的优越性。
在这项工作中,作者专注于通道关系,并提出了一个新的架构单元,称之为 “SE block”,通过模拟通道之间的相互依赖关系,自适应地重新校准通道方面的特征响应。通过将这些SE模块堆叠在一起,可以构建SENet架构,本结构在具有挑战性的数据集上有较好的泛化能力。
以SENets为基础的模型在 ILSVRC 2017获得了第一名,并将top5误差降低到2.251%,比2016年的最佳模型实现了25%的相对提升。
Introduction
本文重点研究了通道关系,通过引入一个新的架构单元SE block,来对卷积特征的通道之间的相互依赖关系进行建模,以提高网络的表示能力。为了实现这一目标,我们提出了一种机制,允许网络执行特征重新校准(feature recalibration),通过这种机制,网络可以学习使用全局信息来有选择地强调信息量大的特征,并抑制不太有用的特征。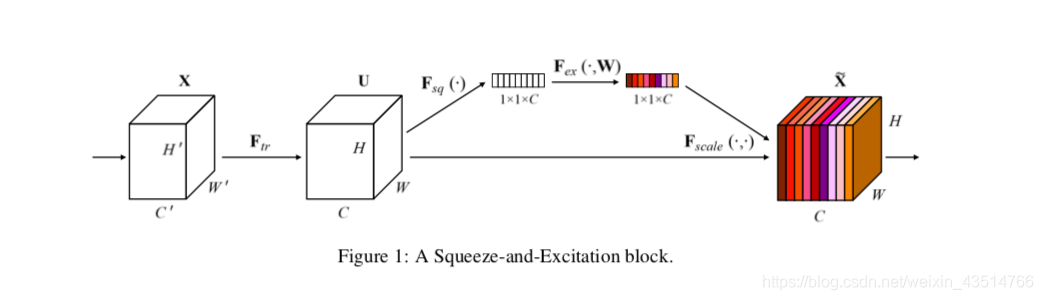
上图,X到U:一个或多个卷积操作;然后特征U会经历一个squeeze操作,将特征图在空间维度H×W上进行聚合,产生通道描述符,每个通道有一个描述符;【这个描述符嵌入了通道特征的全局分布,使得网络的全局接受场的信息能够被其下层所利用。】This descriptor embeds the global distribution of channel-wise feature responses, enabling information from the global receptive field of the network to be leveraged by its lower layers. 在这之后进行excitation操作,得到每个通道的激励(权重);通过乘法操作,U的各个通道就被重新分配了权值,再输入到后续的网络层中。
Squeeze-and-Excitation Blocks

V代表学习到的filter kernel,下标c表示第c个通道;Uc:第c个通道的卷积结果。
由于输出是通过所有通道求和产生的,通道之间的依赖性隐含在vc中,但这些依赖性与滤波器捕获的空间相关性纠缠(?)在一起。
我们的目标是确保网络能够提高其对信息特征的敏感性,以便它们能够被后续的变换所利用,并抑制不太有用的特征。
Squeeze: Global Information Embedding
为了解决 利用通道依赖性 的问题,我们首先在输出特征中考虑到每个通道的信号。 每个filter都在局部感受野上进行操作,因此,转换输出U的每个单元都无法利用该区域之外的上下文信息。 这个问题在接收场大小较小的网络较低层变得更加严重。【没读懂】
为了解决这个问题,作者使用了global pooling全局池化,把全局空间信息压缩成一个“通道描述符”。 下面公式,Uc的描述符Zc计算方法。
Excitation: Adaptive Recalibration
为了利用squeeze操作中聚合的信息,进行了第二步操作,旨在完全捕获通道相关性。
为了实现这一目标,函数必须满足两个条件:
首先,它必须具有灵活性(in particular,它必须能够学习通道之间的非线性相互作用);
其次,它必须学习一个非互斥的关系,因为我们允许强调多个通道,而不是单一地强调某一个通道(并非one-hot activation)。
例如,确保相对于一键激活,允许强调多个通道。
为了满足这些条件,我们选择采sigmoid激活函数作为门控机制:
简单来说就是两个全连接层,两个激活函数(relu和sigmoid)。
该模块的最终输出是通过使用得到的值来rescale U获得的:
Fscale(Uc,Sc):通道间乘法。Sc是上一步通过sigmoid得到的激活值。
Exemplars: SE-Inception and SE-ResNet
将SE block嵌入InceptionNet中: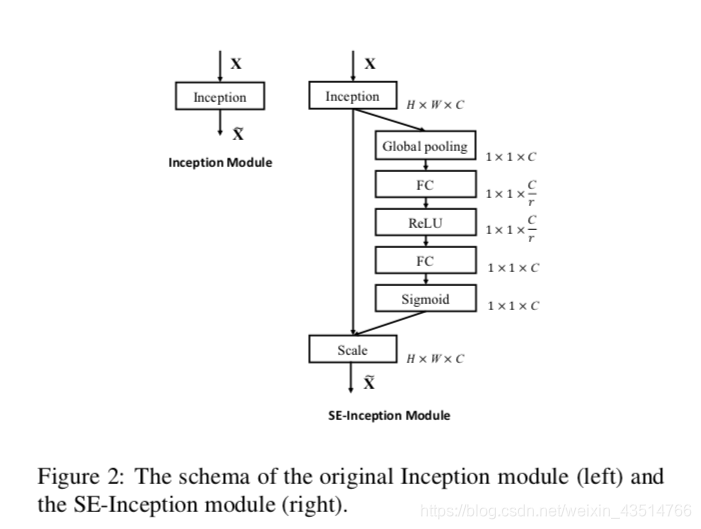
将SE block嵌入ResNet中: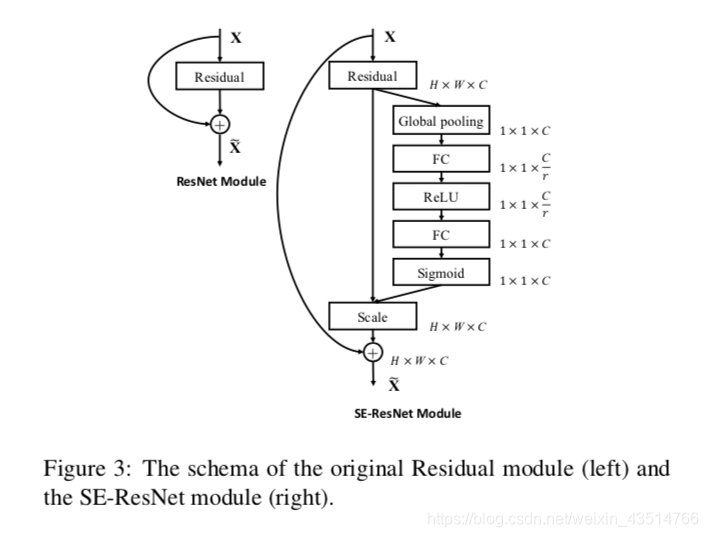
下表:ResNet-50,SE-ResNet-50,SE-ResNeXt-50 with a 32×4d template的结构。
fc指SE block中两个全连接层各自的输出通道数。
Implementation
每个原始网络及其对应的加入SE模块的网络都使用相同的优化方案进行训练。
在ImageNet上的训练期间,我们遵循标准做法,随机裁剪224×224像素,并执行数据增强和随机的水平翻转。
Experiments
ImageNet Classification
ImageNet 2012数据集由128万个训练图像和来自1000个类别的50000验证图像组成。 我们在训练集上训练网络,计算top-1和top-5错误率。
Network depth
首先将SE-ResNet与具有不同深度的ResNet架构进行比较。 表2中的结果表明,SE块在不同深度上都提高了模型的整体性能,而计算复杂度只有极小的增加。
还可以用于Scene Classification、Object Detection 等等,都可以使用SE block。不具体看了,主要想了解SE block的实现过程,看了一些博客,简单总结一下自己的理解。
再次回到这张最核心的图: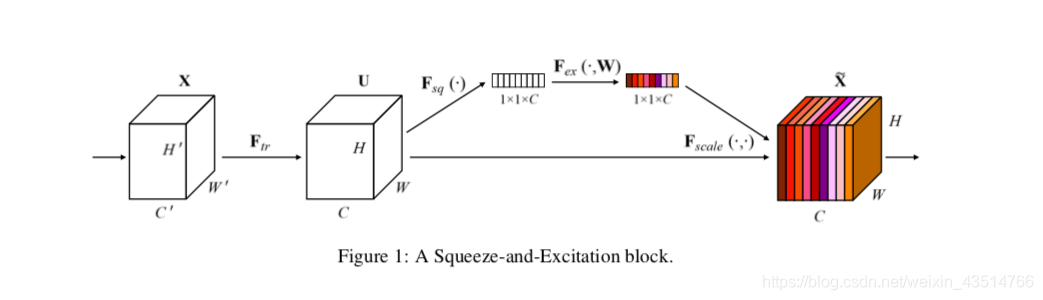
最左边X,是一系列特征图(H’W’C’),经过Ftr(卷积或者其它操作),得到U(HWC),U可以理解为更深层的特征信息。U有C个通道,此时,在神经网络看来,这C个通道各自提取到了不同的特征,每个通道提取到的特征是平等的,也就是说这些特征对于我们最终任务(例如:图像分类)的贡献是相同的。但是我们知道,由于各个通道的参数各异,提取到的特征肯定大不相同(有的层专注于某种纹理,有的层专注于某种颜色,etc.),一句话总结:每个层的重要程度是不同的。
如何得到每个层的重要程度,并将这个重要程度体现在任务中,就是SE block考虑的核心问题。
关于“特征的重要性”,这篇博客给出了很直观的解释,对我理解注意力机制的帮助很大,分享给大家。一张手绘图带你搞懂空间注意力、通道注意力、local注意力及生成过程(附代码注释)
附上博客里的一张图:
通道注意力 VS 空间注意力
个人理解(如果有错误,欢迎指出):
通道注意力是给每个通道赋予不同的权重:如果有C个通道,对这C个通道乘上一个(Cx1x1)大小的向量。
简化来看,如果有三个通道,在加入SE block之前,这三个通道的权重,也就是重要性,是相同的。

以上是我自己的一些理解,欢迎交流。