1.线上部署一般使用JAVA、C++、go或者TF-serving.
2.性能不够解决方案:加机器或者异步调用。每次用户请求的时候,假如计算500条推荐item,然后缓存下来。下次用户来的时候,不是重新计算,而是看这500条有没有消费完毕,如果没有消费完毕,则继续消费。如果消费完毕,在重新计算.

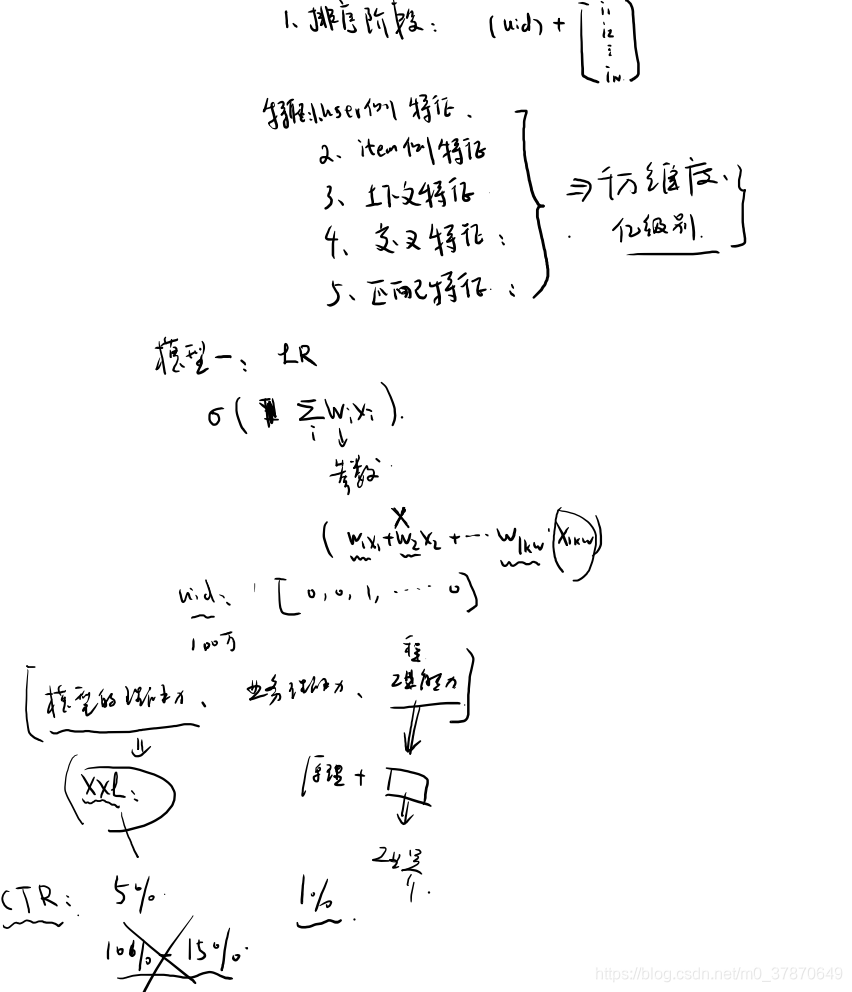
常用排序模型
LR: 合适高维稀疏特征。
WideDeep: 一般类别型特征和组合类特征放在Wide部分,因为如果放在deep部分,经过多层全连接后,特征的作用会减弱。业务特征和人工交叉特征一般也放在Wide部分,这些都属于强特征,我就是想记住它。
GBDT模型
决策树特别容易过拟合,所以一般不会使用单颗决策树进行训练模型,效果一般都不好。
C
版权声明:本文为m0_37870649原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。