0、前言
做过微博爬虫的应该都知道微博存在一个Sina Visitor System,即无需登录就能访问的页面,也需要获得一个访客cookie才能访问。如果我们直接对微博页面爬取,那么返回的页面全都是Sina Visitor System的页面。
因此,我们在这里分析一下Sina Visitor System生成访客Cookie的原理,同时实现自动化获取有效访客Cookie,以此绕过微博Sina Visitor System系统。
1、Sina Visitor System原理
1.1、基本流程
首先,我们看一下加载微博界面的整个流程。这里我们随便选取了一个用户的页面作为展示:

可以看到,中间红框部分就是新浪访客系统分配访客Cookie的过程。我们只要分析一下整个过程工作的原理,就可以自动化获取到足够多的访客Cookie,以此支持我们的爬虫可以不间断的爬取。
首先看一下红框中的第一个请求,这里就是Sina Visitor System。我们进去查看一下,在首部引入了一个js文件,可以发现这就是上述红框请求中第二个请求;然后就是下面部分中incarnate()是生成访客Cookie的。
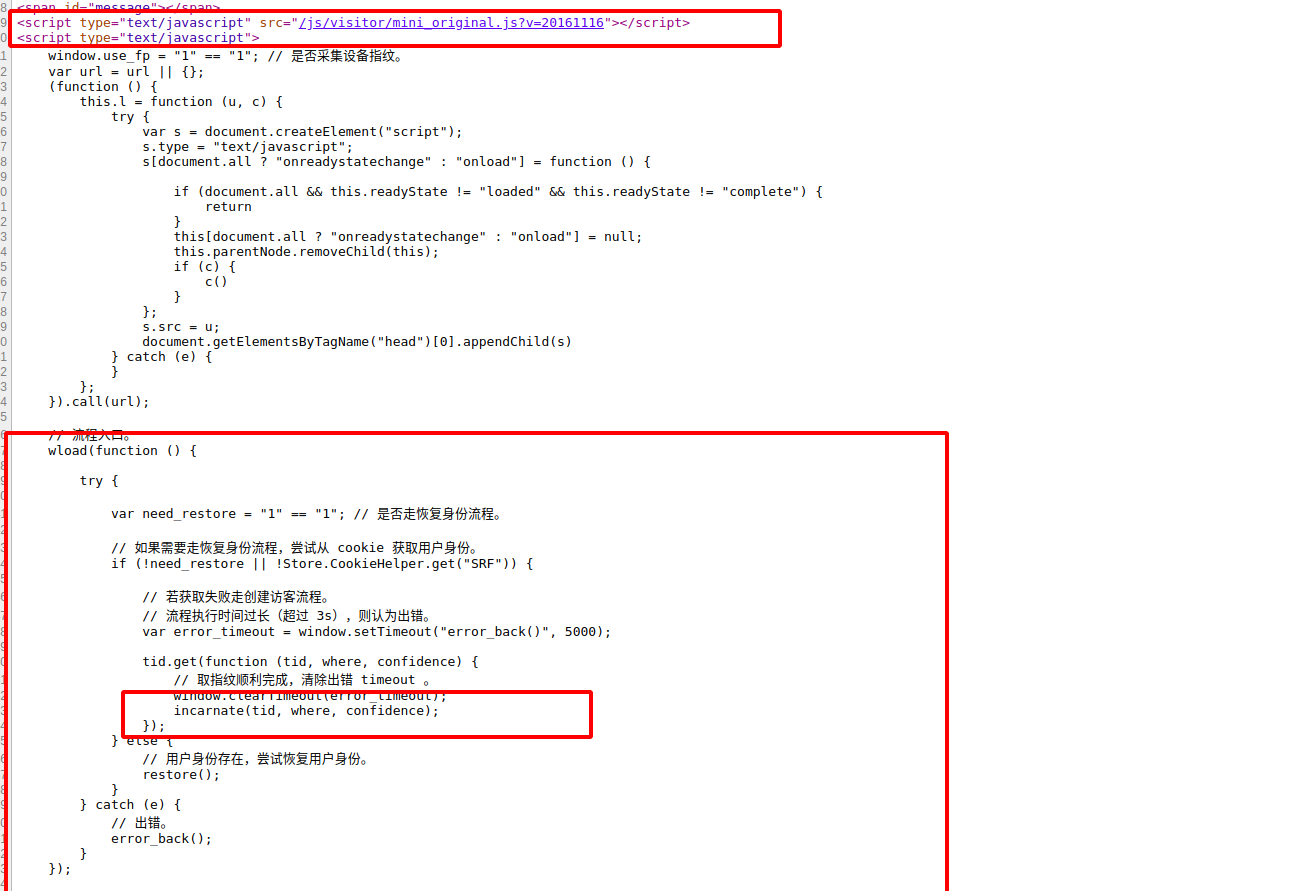
看一下incarnate()的内容,这里就是发送了一个GET请求,然后我们可以发现就是上述红框中第四个请求

因此,我们只要能成功的提交红框中第四个请求,就可以获取到一个访客Cookie。
1.2、tid的获取
看一下第四个请求的内容:
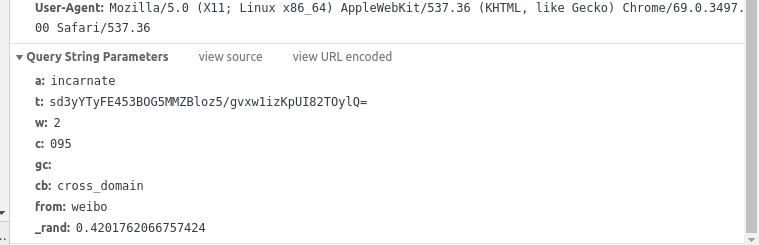
这里我们可以发现有很多个参数,在多次从测试对比中我们可以发现其中a、cb、from、c、w是固定的,_rand是一个随机数,gc一致是为空。因此我们只需要获取到tid的值就ok了。在上述源码页面中并不存在这几个值相关的代码,因此我们需要看其引入的js文件中是否存在,也就是红框中第二个请求。


可以发现,这里发送的请求就是上述红中的第三个请求,POST了两个参数,一个是cp,定值为:gen_callback;另一个是fp,他是通过getFp()方法生成,其大致是获取浏览器类型,窗口大小,字体之类的常量。因此这两个值我们都可以认为是个定值,在测试时只需要直接复制就OK了。
然后我们模拟提交一下这个请求,发现可以返回tid:
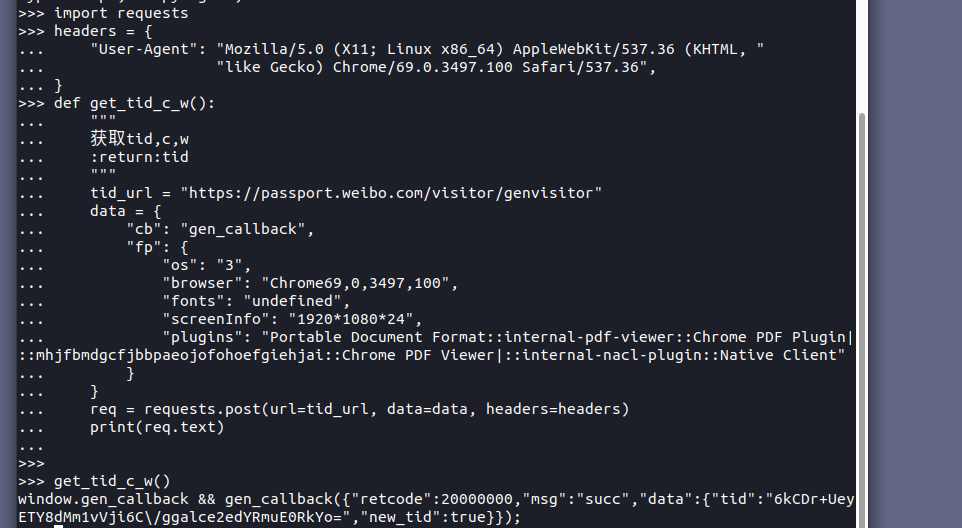
至此我们已经成功获取到了第一个关键的参数——tid。
1.3、Cookie的获取
然后就是发出我们最终的请求了,也就是红框中的第四个请求。注意:发送该请求时,我们需要加入一个Cookie: tid: tid__095
代码如图:
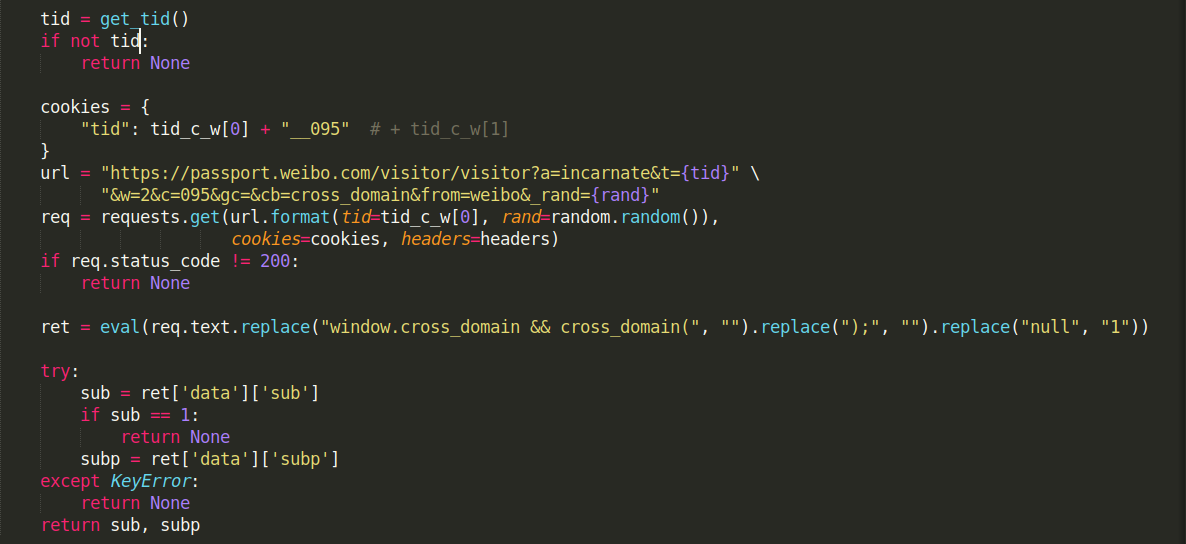
运行结果:

成功获取到了两个Cookie值:SUB和SUBP。
注意,这里有个缺陷,即我们并不能保证每次都可以获取到SUB和SUBP两个值。有时是获取不到的,获取失败时只需要重新获取就可以。
2、测试
我们在Cookie中加入这两个值进行测试,发现可以绕过Sina Visitor System,直接访问页面。
正常访问时的页面加载流程:

加入Cookie时页面加载流程:
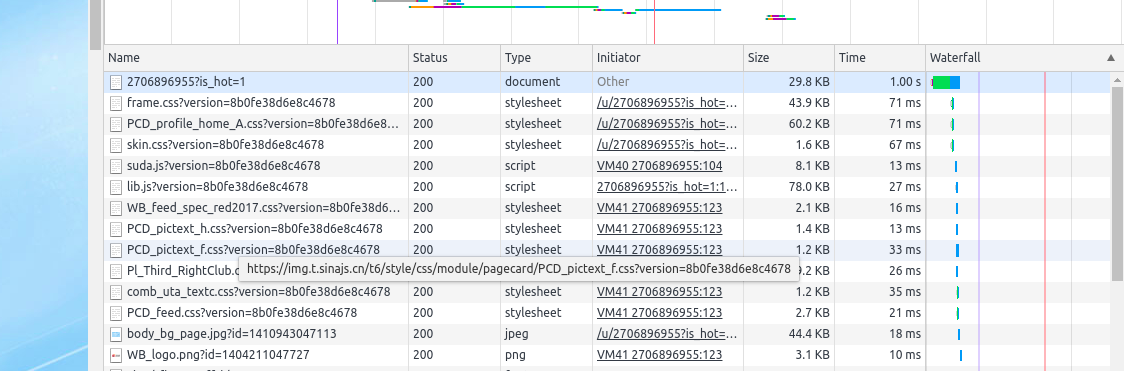
可以看到,第一次需要经过Sina Visitor System加载,第二次页面直接加载,成功绕过Sina Visitor System。
3、简易代码
下面是一个简单的实现代码# -*- coding:utf-8 -*-
# Author: Suummmmer
# Date: 2019-05-17
import requests
import random
headers = {
"User-Agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, "
"like Gecko) Chrome/69.0.3497.100 Safari/537.36",
}
def get_tid():
"""
获取tid,c,w
:return:tid
"""
tid_url = "https://passport.weibo.com/visitor/genvisitor"
data = {
"cb": "gen_callback",
"fp": {
"os": "3",
"browser": "Chrome69,0,3497,100",
"fonts": "undefined",
"screenInfo": "1920*1080*24",
"plugins": "Portable Document Format::internal-pdf-viewer::Chrome PDF Plugin|::mhjfbmdgcfjbbpaeojofohoefgiehjai::Chrome PDF Viewer|::internal-nacl-plugin::Native Client"
}
}
req = requests.post(url=tid_url, data=data, headers=headers)
if req.status_code == 200:
ret = eval(req.text.replace("window.gen_callback && gen_callback(", "").replace(");", "").replace("true", "1"))
return ret.get('data').get('tid')
return None
def get_cookie():
"""
获取完整的cookie
:return: cookie
"""
tid = get_tid()
if not tid:
return None
cookies = {
"tid": tid + "__095" # + tid_c_w[1]
}
url = "https://passport.weibo.com/visitor/visitor?a=incarnate&t={tid}"
"&w=2&c=095&gc=&cb=cross_domain&from=weibo&_rand={rand}"
req = requests.get(url.format(tid=tid, rand=random.random()),
cookies=cookies, headers=headers)
if req.status_code != 200:
return None
ret = eval(req.text.replace("window.cross_domain && cross_domain(", "").replace(");", "").replace("null", "1"))
try:
sub = ret['data']['sub']
if sub == 1:
return None
subp = ret['data']['subp']
except KeyError:
return None
return sub, subp
4、参考链接