单词
discoveryClient-发现客户端、loadBalance-负载均衡、Rule-规则、current-当前的、fallback-回退(降级)、break-中断(熔断)、flowlimit-限流、circuit-电路、dashboard-仪表盘、refresh-刷新、actuator-执行器
SpringCloud是一系列框架的有序集合,是一揽子框架的解决方案
(约定 > 配置 > 编码)
微服务架构
微服务架构是一种架构模式,它提倡将单一应用程序划分成一组小的服务,服务之间互相协调、互相配合,为用户提供最终价值。每个服务运行在其独立的进程中,服务与服务间采用轻量级的通信机制互相协作(通常是基于HTTP协议的RESTful API)。每个服务都围绕着具体业务进行构建,并且能够被独立的部署到生产环境、类生产环境等。另外,应当尽量避免统一的、集中式的服务管理机制,对具体的一个服务而言,应根据业务上下文,选择合适的语言、工具对其进行构建
分布式架构
或者说是对分布式架构的理解
- 服务注册与发现
- 服务调用
- 服务熔断
- 负载均衡
- 服务降级
- 服务消息队列
- 配置中心管理
- 服务网关
- 服务监控
- 全链路追踪
- 自动化构建部署
- 服务定时任务调度操作
- …
一些架构需要学习掌握的技术
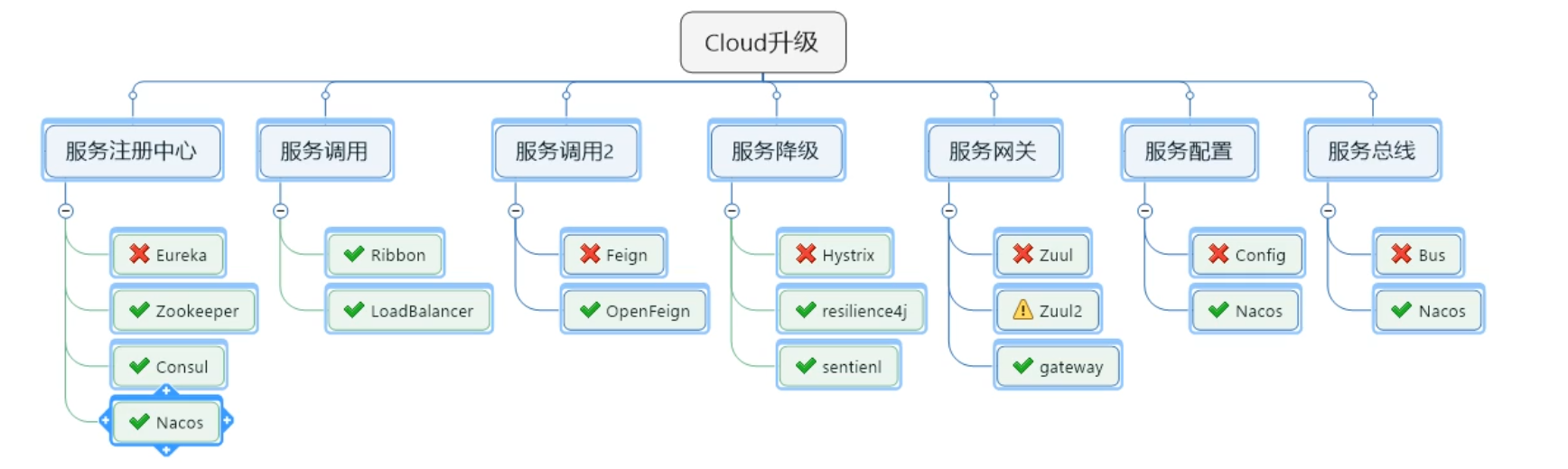
开始搭建项目
- dependencyManagement里只是声明依赖,并不实现引入,因此子项目需要显示的声明需要用的依赖。
<!--dependencyManagement: 子模块继承之后,提供作用:锁定版本+子module不用写groupId和version -->
<dependencyManagement>
<dependencies>
<!--spring boot 2.2.2-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-dependencies</artifactId>
<version>2.2.2.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
......
这样做的好处就是:如果有多个子项目都引用同一样依赖,则可以避免在每个使用的子项目里都声明一个版本号,这样当想升级或切换到另一个版本时,只需要在顶层父容器里更新,而不需要一个一个子项目的修改﹔另外如果某个子项目需要另外的一个版本,只需要声明version就可。
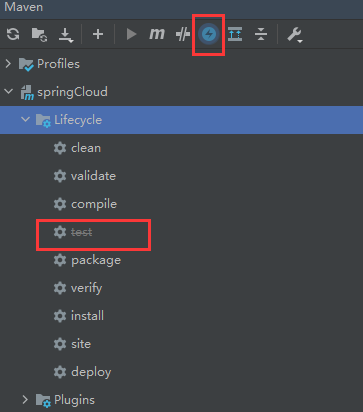
跳过maven的test单元测试,项目可以跑的更快
一个微服务模块搭建的基本流程
1、建module
2、改POM
3、写YML
4、主启动
5、业务类
RestTemplate
RestTemplate提供了多种便捷访问远程Http服务的方法,
是一种简单便捷的访问restful服务模板类,是Spring提供的用于访问Rest服务的客户端模板工具集
1、创建一个父类总工程
pom.xml
<dependencyManagement>: 子模块继承之后,提供作用:锁定版本+子module不用写groupId和version
</dependencyManagement>
2、编写服务的生产者
1、建module
cloud_provider_payment8001
2、改POM
需要的依赖
<artifactId>spring-boot-starter-web</artifactId>
<artifactId>spring-boot-starter-actuator</artifactId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<artifactId>druid-spring-boot-starter</artifactId>
<artifactId>mysql-connector-java</artifactId>
<artifactId>spring-boot-starter-jdbc</artifactId>
<artifactId>spring-boot-devtools</artifactId>
<artifactId>lombok</artifactId>
<artifactId>spring-boot-starter-test</artifactId>
3、写YML
改端口号8001,mysql jdbc 驱动 数据源 ,mybatis扫描
4、主启动
编写主启动类
5、业务类
5.1、编写Payment.java 的bean
5.2、编写CommontResult.java 的bean 面相前端开放的一个bean,前端只需要调用这个bean的结果即可
5.3、Dao、DaoImpl、mapper.xml
5.4、service、serviceImpl
5.5、controller
消费者调用该写入数据库的业务时,会给生产者传回一个json字符串,造成写入数据库错误,写入一个null值,所以需要在形参中加上==@RequestBody== 注解 将传回来的字符串转换成对象
@Autowired
private PaymentService paymentService;
@PostMapping(value="/payment/create")
public CommonResult create(@RequestBody Payment payment){
int result = paymentService.create(payment);
log.info("=====插入结果====="+payment);
if(result > 0){
return new CommonResult(200,"插入成功",payment);
}
return new CommonResult(444,"插入失败",payment);
}
3、编写服务的消费者
1、建module
cloud_consumer_order80
2、改POM
<artifactId>spring-boot-starter-web</artifactId>
<artifactId>spring-boot-starter-actuator</artifactId>
<artifactId>spring-boot-devtools</artifactId>
<artifactId>lombok</artifactId>
<artifactId>spring-boot-starter-test</artifactId>
3、写YML
改端口号80 默认不用写就是80端口,所以消费者只用写ip地址即可访问服务
4、主启动
主启动类
5、业务类
5.1、编写Payment.java 的bean
5.2、 编写CommonResult.java 的 bean
5.3 编写config配置类 ApplicationContextConfig.java
// 配置类
@Configuration
public class ApplicationContextConfig {
// 可以复用的restTemplate方法
@Bean
public RestTemplate getRestTemplate(){
return new RestTemplate();
}
}
5.4、编写controller层
使用到了RestTemplate , 写操作使用postForObject() , 读操作使用getForObject()
@RestController
@Slf4j
public class OrderController {
@Resource
private RestTemplate restTemplate;
public static final String PAYMENT_URL = "http://localhost:8001";
@GetMapping("/consumer/payment/create")
public CommonResult<Payment> create(Payment payment) {
// 用于访问Rest服务的客户端模板工具集 ( URL访问地址,传参类型,返回类型 )
return restTemplate.postForObject(PAYMENT_URL + "/payment/create", payment, CommonResult.class);
}
@GetMapping("/consumer/payment/getPayment/{id}")
public CommonResult<Payment> getPayment(@PathVariable("id") long id){
return restTemplate.getForObject(PAYMENT_URL+"/payment/getPayment/"+id,CommonResult.class);
}
}
创建一个抽取公用API的模块
1、pom.xml
新加入了一个hutool工具包
<artifactId>hutool-all</artifactId>
2、将entities实体类包抽取出来
3、使用maven的生命周期的方法
3.1、clean清空
3.2、install安装打包一下
4、在需要使用到该实体类的模块中引入依赖
<dependency><!-- 引入自己定义的api通用包,可以使用Payment支付Entity -->
<groupId>com.study</groupId>
<artifactId>cloud_api_commons</artifactId>
<version>${project.version}</version>
</dependency>
Eureka
( 已停止更新 )
Eureka包含两个组件 : Eureka Server 和 Eureka Client
Eureka Server提供服务注册服务
各个微服务节点通过配置启动后,会在EurekaServer中进行注册,这样EurekaServer中的服务注册表中将会存储所有 可用服务节点的信息,服务节点的信息可以在界面中直观看到。
EurekaClient通过注册中心进行访问
是一个lava客户端,用于简化Eureka Server的交互,客户端同时也具备一个内置的、使用轮询(round- robin)负载算 法的负载均衡器。在应用启动后,将会向Eureka Server发送心跳(默认周期为30秒)。如 果Eureka Server在多个心 跳周期内没有接收到某个节点的心跳,EurekaServer将会从服务注册表中把这 个服务节点移除(默认90秒)
服务注册中心
需要先启动服务注册中心,再服务的提供者。
创建服务注册中心模块
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-server</artifactId>
</dependency>
服务注册中心的yaml
server:
port: 7001
eureka:
instance:
hostname: localhost # eureka服务端的实例名称
client:
#false表示不向注册中心注册自己
register-with-eureka: false
#false 表示自己端就是注册中心,我的职责就是维护服务实例,并不需要去检索服务
fetch-registry: false
service-url:
#设置与Eureka Server交互的地址查询服务和注册服务都需要依赖这个地址
defaultZone: http://${eureka.instance.hostname}:${server.port}/eureka/
服务注册中心的主启动类
@SpringBootApplication
@EnableEurekaServer // 表示自己是Eureka服务注册中心
public class EurekaMain7001 {...}
服务提供者
依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
服务提供者的yaml
eureka:
client:
#表示是否将自己注册进EurekaServer 默认为true
register-with-eureka: true
#是否从EurekaServer抓取已有的注册信息,默认为true。单节点无所谓,集群必须设置为true才能配合ribbon使用负载均衡
fetch-registry: true
service-url:
# 向哪个注册中心注册服务
defaultZone: http://localhost:7001/eureka
服务提供者的主启动类
@SpringBootApplication
@EnableEurekaClient // 服务提供者,让注册中心发现、并扫描到该服务
public class PaymentMainAPP {...}
集群版Eureka
1、新建一个服务的注册中心 eureka7002
2、在windows的hosts文件中加上本机的ip地址,服务注册中心的服务名( 相当于域名 )
127.0.0.1 eureka7001.com
127.0.0.1 eureka7002.com
3、修改服务注册中心的yaml文件
3.1、修改eureka服务名 eureka7001.com 在浏览器地址栏中输入,可以映射到127.0.0.1
(127.0.01 localhost 192.168.177.1(127.0.0.1 = 本机ip地址 ,localhost = 本机的域名,192.168.177.1 = 本机网卡对外的ip))
3.2、修改 defaultZone :ip地址:port/eureka/
,之前是单机版本,只需要把自己的地址注册上即可,现在是集群,所以要写上其他服务注册中心的地址
多台服务注册中心需要 相互注册,互相关联,相互守望 , 如果有多台可以用 ==,==逗号隔开
server:
port: 7001
eureka:
instance:
hostname: eureka7001.com # eureka服务端的实例名称
client:
#false表示不向注册中心注册自己
register-with-eureka: false
#false 表示自己段就是注册中心,我的职责就是我维护服务实例,并不需要去检索服务
fetch-registry: false
service-url:
#设置与Eureka Server交互的地址查询服务和注册服务都需要依赖这个地址
# defaultZone: http://${eureka.instance.hostname}:${server.port}/eureka/
#使用集群的方式
defaultZone: http://eureka7002.com:7002/eureka/
Client向集群注册中心注册服务
修改yaml文件
eureka:
client:
#表示是否将自己注册进EurekaServer 默认为true
register-with-eureka: true
#是否从EurekaServer抓取已有的注册信息,默认为true。单节点无所谓,集群必须设置为true才能配合ribbon使用负载均衡
fetch-registry: true
service-url:
# 向哪个注册中心注册服务
# defaultZone: http://localhost:7001/eureka
#向集群注册中心注册服务
defaultZone: http://eureka7001.com:7001/eureka,http://eureka7002.com:7002/eureka
Client端集群(提供者)
不仅要做服务注册中心的集群,还要做服务提供者的集群,这样可用性更高
1、再创建一个服务提供者的模块 cloud_provider_payment8002
1.1、改 POM
1.2、写YAML
yaml的端口号改成8002,(多个服务提供者的服务名需要保持一致,让消费者可以通过一个服务名找到多个提供者)
1.3 、主启动类
1.4、业务类
可选: 可以在controller层加上 以便以端口号识别的参数
@Value("${server.port}") // 从配置文件中读取端口号
private String serverPort ;
....
return new CommonResult(200,"查询成功 + " + serverPort,paymentById);
2、在消费者 (80端口)修改controller层的URL访问地址
// public static final String PAYMENT_URL = "http://localhost:8001";
// URL访问地址从服务提供者的ip改成服务提供者集群对外暴露的服务名(需要在RestTemplate的配置上加上@LoadBalanced 在可以生效)
public static final String PAYMENT_URL = "http://CLOUD-PAYMENT";
2.1、给RestTemplate加上注解@LoadBalance 赋予它负载均衡的能力 (默认轮询的方式来负载均衡)
// 配置类
@Configuration
public class ApplicationContextConfig {
// 可以复用的restTemplate方法
@Bean
@LoadBalanced // 赋予RestTemplate 负载均衡的能力
public RestTemplate getRestTemplate(){
return new RestTemplate();}}
完善微服务的配置信息(可选)
前台监控页面查看时可以显示更详细的信息
instance:
instance-id: payment8001 #显示服务的主机名
prefer-ip-address: true #访问路径可以显示服务的ip地址
服务发现Discover
使用参数DisCoverClient
@Resource//DiscoverClient服务发现
private DiscoveryClient discoveryClient;
写方法获取实例信息
@GetMapping(value = "/payment/discover")
public Object discover(){
// Eureka注册的微服务有哪些,服务列表清单
List<String> services = discoveryClient.getServices();
for (String element:services) {
log.info("services--->"+element);
}
------------------结果-----------------------------
services--->cloud-order-com.study.cloud.service
services--->cloud-payment-service
------------------------------------------------
//根据微服务的名称,获取微服务具体的信息
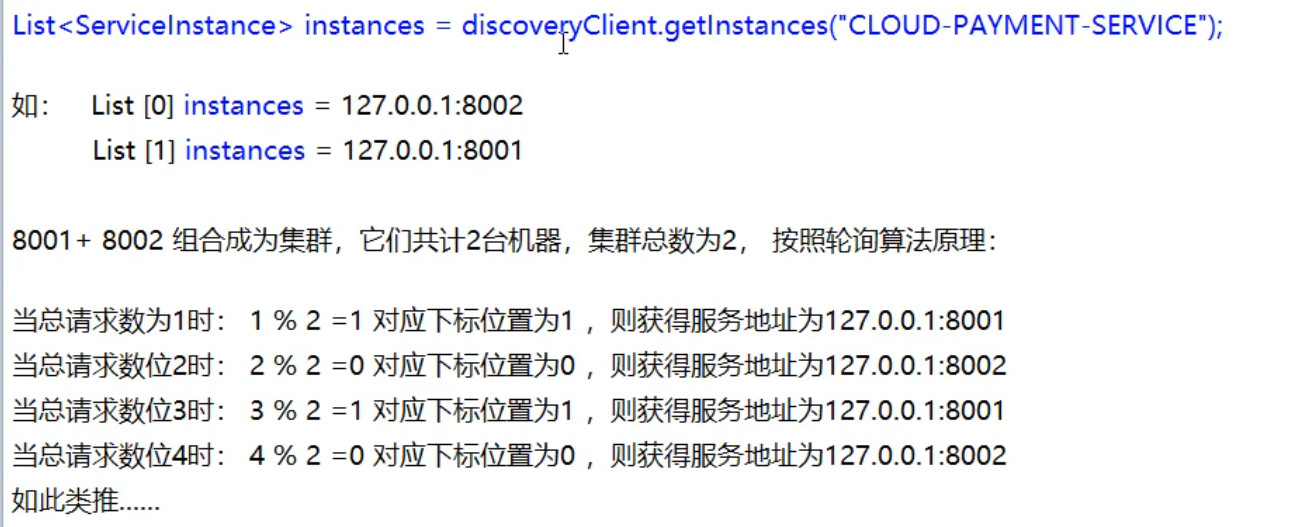
List<ServiceInstance> instances = discoveryClient.getInstances("CLOUD-PAYMENT-SERVICE");
for (ServiceInstance instance : instances) {
// 可以使用根据服务名实例获取到的内容来get该服务名的详细的信息
log.info("instance--->"+instance.getInstanceId()+"\t"+instance.getHost()+"\t"+instance.getPort()+"\t"+instance.getUri());
}
return this.discoveryClient;
}
------------------结果---------------------------
instance--->payment8002 192.168.1.6 8002 http://192.168.1.6:8002
instance--->payment8001 192.168.1.6 8001 http://192.168.1.6:8001
主启动类上加上@EnableDiscoveryClient注解
Euraka的自我保护
某时刻某一个微服务不可用了,Eureka不会立刻清理,依旧会对该微服务的信息进行保存
自我保护机制∶
默认情况下EurekaClient定时向EurekaServer端发送心跳包
如果Eureka在server端在一定时间内(默认90秒)没有收到EurekaClient发送心跳包,便会直接从服务注册列表中剔除 该服务,但是在短时间( 90秒中)内丢失了大量的服务实例心跳,这时候Eurekaserver会开启自我保护机制,不会剔 除该服务(该现象可能出现在如果网络不通但是EurekaClient为出现宕机,此时如果换做别的注册中心如果一定时 间内没有收到心跳会将剔除该服务,这样就出现了严重失误,因为客户端还能正常发送心跳,只是网络延迟问题, 而保护机制是为了解决此问题而产生的)
关闭自我保护机制
enable-self-preservation:false
Euraka客户端向服务端发送信条的时间间隔,单位为秒(默认30)秒
lease-renewal-interval-in-seconds:1
Zookeeper
在linux中启动zookeeper和它的客户端
引入zookeeper的依赖
<!-- spring整合zookeeper客户端 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zookeeper-discovery</artifactId>
</dependency>
不过这样直接引用可能会造成jar包和本地安装的zookeeper冲突,因为版本不一致
所以要排除掉spring给的ZK版本,来自己手动指定ZK的版本
<!-- SpringBoot整合zookeeper客户端 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zookeeper-discovery</artifactId>
<!--先排除自带的zookeeper3.5.3-->
<exclusions>
<exclusion>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
</exclusion>
</exclusions>
</dependency>
<!--添加zookeeper3.6.3版本-->
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.6.3</version>
</dependency>
可以再ZK客户端用 ls /查看所有的服务
spring启动完成之后,把服务注册进zookeeper
ZK客户端多出一个services服务
使用ls /services 可以查看该服务,本次显示的是8004的服务名
[zk: localhost:2181(CONNECTED) 0] ls /
[services, zookeeper]
[zk: localhost:2181(CONNECTED) 1] ls /services
[cloud-payment-service]
[zk: localhost:2181(CONNECTED) 2]
获取该服务具体信息,get 获取到的服务名
get cloud-payment-service
zookeeper的节点是临时节点,服务关闭,一段时间后,zookeeper没有收到服务的心跳,就会把这个服务的节点踢掉,当服务再次上线后,重新获取节点,但是这次的节点是一个全新的节点,不是之前的老节点
zookeeper消费端
@RestController
public class PaymentZKController {
// 调用提供者URL地址(地址为提供者注册到zookeeper的服务名)
private static final String INVOKE_URL="http://cloud-payment-service";
@Autowired
private RestTemplate restTemplate;
@GetMapping(value = "/consumer/payment/zk")
public String payment(){
String forObject = restTemplate.getForObject(INVOKE_URL + "/payment/zk", String.class);
return forObject;
}
}
Consul
- 能干嘛?
- 服务发现
- 提供HTTP和DNS两种发现方式
- 健康监测
- 支持多种方式,HTTP、TCP、Docker、Shell脚本定制化
- KV存储
- key、value存储
- 多数据中心
- Consul支持多数据中心
- 可视化Web界面
- 服务发现
代码基本与Euraka,zookeeper注册中心一致,就是需要添加一个Consul的依赖,YAML中添加Consul的地址 默认端口:8500
…
CAP的意思
C : Consistency (强一致性)
A : Avaliability (可用性)
P : Partition tolerance (分区容错性)
Euraka ----AP
Zookeeper ---- CP
Consul ---- CP
Ribbon
Ribbon是什么?
Spring Cloud Ribbon是基于Netflix Ribbon实现的一套客户端负载均衡的工具。
简单的说,Ribbon是Netflx发布的开源项目,主要功能是提供客户端的软件负载均衡算法和服务调用。Ribbon客户端组件提供一系列完善的配置项如连接超时,重试等。简单的说,就是在配置文件中列出Load Balancer (简称LB)后面所有的机器,Ribbon会自动的帮助你基于某种规则(如简单轮询,随机连接等)去连接这些机器。我们很容易使用Ribbon实现自定义的负载均衡算法。
LB负载均衡(Load Balance)是什么?
- LB(负载均衡)
- 集中式LB ( Nginx服务端的负载均衡就是集中式的LB )
- 进程内LB ( Ribbon本地的负载均衡就是进程内的LB )
简单的说就是将用户的请求平摊的分配到多个服务上,从而达到系统的HA(高可用)。常见的负载均衡有软件Nginx,
LVS,硬件F5等。
Ribbon本地负载均衡客户端 VS Nginx服务端负载均衡区别
Nginx是服务器负载均衡,客户端所有请求都会交给nginx,然后由nginx实现转发请求。即负载均衡是由服务端实现的。
Ribbon本地负载均衡,在调用微服务接口时候,会在注册中心上获取注册信息服务列表之后缓存到VM本地,从而在
本地实现RPC远程服务调用技术。
简单来说Ribbon就是 RestTemplate + 负载均衡的调用
这个Eureka 依赖 自带 Ribbon
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
Ribbon负载均衡和Rest调用
@GetMapping("/consumer/payment/getForEntities/{id}")
public CommonResult<Payment> getPayment1(@PathVariable("id") long id){
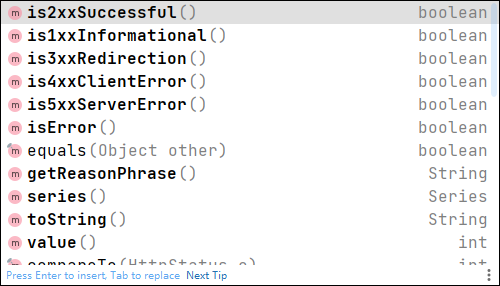
ResponseEntity<CommonResult> forEntity = restTemplate.getForEntity(PAYMENT_URL + "/payment/getPayment/" + id, CommonResult.class);
if(forEntity.getStatusCode().is2xxSuccessful()){
return forEntity.getBody();
}
return new CommonResult(444,"请求失败");
}
返回对象为ResponseEntity对象,包含了响应中的一些 重要信息,比如响应头、响应状态码、响应体等
Ribbon核心组件IRule
根据特定算法中从服务列表中选取一个要访问的服务,一共有7中负载均衡方式,(默认轮询)

如何替换IRule?
官方文档明确给出了警告:
这个自定义配置类不能放在@ComponentScan所扫描的包下以及子包下 (主程序的@SpringbootApplication注解就包含了@ComponentScan注解)
否则我们自定的这个配置类就会被所有的Ribbon客户端所共享,达不到特殊化定制的目的了。
自定义配置类
在主程序的包外新建一个包myrule ,再创建一个自定义的配置类MySelfRule
@Configuration
public class MySelfRule {
// 随机轮询的方式
@Bean
public IRule MyRule(){
return new RandomRule();
}
}
加载自定义配置类,让配置生效
@SpringBootApplication
@EnableEurekaClient
// RibbonClient 组件加载自定义的Ribbon配置类 (使用哪个服务,使用自定的轮询方式)
@RibbonClient(name= "CLOUD-PAYMENT-SERVICE", configuration = MySelfRule.class)
public class OrderMain80 {
public static void main(String[] args) {
SpringApplication.run(OrderMain80.class,args);
}
}
负载均衡算法
rest接口第几次请求数%服务器集群总数量=实际调用服务器位置下标,每次服务重启动后rest接口计数从1开始。
Feign
Feign是一个声明式WebService客户端。使用Feign能让编写Web Service客户端更加简单。
它的使用方法是定义一个服务接口然后在上面添加注解。Feign也支持可拔插式的编码器和解码器。Spring Cloud对Feign进行了封装,使其支持了Spring MVC标准注解和HttpMessageConverters。Feign可以与Eureka和Ribbon组合使用以支持负载均衡
简单来讲Feign就是使用方法上定义一个服务接口然后在上面添加注解(@FeignClient),Feign是在消费端使用的
Feign自带负载均衡,自带Ribbon的依赖
消费者80
主程序类中开启Feign功能
@SpringBootApplication
@EnableFeignClients // 开启Feign功能
public class FeignMain80 {
将需要调用的服务提取出来
@Component
@FeignClient(value = "CLOUD-PAYMENT-SERVICE")//调用的服务名
public interface PaymentService { // 写成一个接口,让消费者的controller去调用这个接口
//调用服务下的哪个方法(从服务提供者的controller层调用)
@GetMapping(value = "/payment/getPayment/{id}")
CommonResult getPaymentById(@PathVariable("id") long id);
}
80消费端controller调用service , service去调用服务端controller
@RestController
public class FeignController {
@Resource
private PaymentService paymentService;
@GetMapping(value = "/consumer/payment/getPayment/{id}")
public CommonResult<Payment> getPaymentById(@PathVariable("id") long id){
return paymentService.getPaymentById(id);
}
}
OpenFeign超时控制
openFeign 调用服务默认等待1秒钟,超出时间后报错
测试超出时间报错
服务提供者设置睡眠时间
@GetMapping("/payment/timeout")
public String feignTimeOut(){ //Feign超时时间,让调用该服务的时间超出默认的1秒钟
try {
TimeUnit.SECONDS.sleep(3);
} catch (InterruptedException e) {
e.printStackTrace();
}
return serverPort;
}
调用服务
@Component
@FeignClient(value = "CLOUD-PAYMENT-SERVICE")//调用的服务名
.....
@GetMapping("/payment/timeout")
public String feignTimeOut();
@GetMapping("/consumer/payment/timeout")
public String feignTimeOut(){
return paymentService.feignTimeOut();
}
Ribbon超时时间
不希望超出时间报错,想多等一会
可以再yaml中设置ribbon的连接时间(Feign中自带Ribbon)
# 请求连接的超时时间
ribbon:
ConnectTimeout: 5000
# 请求处理的超时时间
ReadTimeout: 5000
OpenFeign日志增强
日志级别:
NONE:默认的,不显示任何日志;
BASIC:仅记录请求方法、URL、响应状态码及执行时间;
HEADERS:除了BASIC中定义的信息之外,还有请求和响应的头信息;
FULL:除了HEADERS 中定义的信息之外,还有请求和响应的正文及元数据。
自定义一个配置类,定义打印的日志级别
@Configuration
public class FeignConfig {
@Bean
Logger.Level feignLoggerLevel(){
return Logger.Level.FULL;
}
}
日志打印的类型级别
logging:
level:
#feign日志以什么级别监控哪个接口
com.study.cloud.service.PaymentService: debug
[PaymentService#getPaymentById] <--- HTTP/1.1 200 (57ms)
[PaymentService#getPaymentById] connection: keep-alive
[PaymentService#getPaymentById] content-type: application/json
[PaymentService#getPaymentById] date: Fri, 24 Sep 2021 14:53:34 GMT
[PaymentService#getPaymentById] keep-alive: timeout=60
[PaymentService#getPaymentById] transfer-encoding: chunked
[PaymentService#getPaymentById]
[PaymentService#getPaymentById] {"code":200,"massage":"查询成功 + 8001","data":{"id":1,"serial":"abcdefg"}}
[PaymentService#getPaymentById] <--- END HTTP (79-byte body)
Flipping property: CLOUD-PAYMENT-SERVICE.ribbon.ActiveConnectionsLimit to use NEXT property: niws.loadbalancer.availabilityFilteringRule.activeConnectionsLimit = 2147483647
Hystrix
以停止更新、维护
Hystrix是一个用于处理分布式系统的延迟和容错的开源库,在分布式系统里,许多依赖不可避免的会调用失败,比如超时、异常等, Hystrix能够保证在一个依赖出问题的情况下,不会导致整体服务失败,避免级联故障,以提高分布式系统的弹性。
"断路器”本身是一种开关装置,当某个服务单元发生故障之后,通过断路器的故障监控〔类似熔断保险丝),向调用方返回一个符合顶期的、可处理的备选响应(FallBack),而不是长时间的等待或者抛出调用方无法处理的异常,这样就保证了服务调用方的线程不会波长时间、不必要地占用,从而避免了故障在分布式系统中的蔓延,乃至雪崩。
能干嘛?
- 服务降级
- 服务熔断
- 接近实时的监控
- …
fallback-降级、break-熔断、flowlimit-限流
d
服务熔断和限流是保证或提高系统服务可用的一种手段,而服务降级是体现熔断和限流的方法(个人理解)
- 服务降级( fallback )
- 服务器忙,请稍后再试,不让客户端等待并立刻返回一个友好提示,fallback
- 哪些情况会触发降级?
- 程序运行异常
- 超时
- 服务熔断触发服务降级
- 线程池/信号量打满也会导致服务降级
- 服务熔断 ( break )
- 类比保险丝达到最大服务访问后,直接拒绝访问,拉闸限电,然后调用服务降级的方法并返回友好提示( 就像保险丝 )
- 服务的降级–>进而熔断–>恢复调用链路
- 服务限流 ( flowlimit )
- 秒杀高并发等操作,严禁一窝蜂的过来拥挤,大家排队,一秒钟N个,有序进行
故障现象和导致原因
8001同一层次的其他接口服务被困死,因为tomc1at线程池里面的工作线程已经被挤占完毕-
80此时调用8001,客户端访问响应缓慢,转圈圈
出现问题如何解决?
- 超时导致服务器变慢(转圈)————超时不在等待
- 出错(宕机或程序运行出错)————出错要有兜底
解决
- 对方服务(8001)超时了,调用者(80)不能一直卡死等待,必须有服务降级
- 对方服务(8001)down机了,调用者(80)不能一直卡死等待,必须要有服务降级
- 对方服务(8001)OK,调用者(80)自己出故障或有自我要求(自己的等待时间小于服务提供者),自己处理降级
容错方法、兜底方法(fallback)
// 如果该方法出现错误,(调用兜底方法(Dubbo的容错机制), commandProperties设置超时时间,如果超时就启动兜底方法)
@HystrixCommand(fallbackMethod = "paymentInfoHandler",commandProperties = {
@HystrixProperty(name="execution.isolation.thread.timeoutInMilliseconds",value="5000")})
public String paymentInfoTimeout(Integer id){
try {
int i = 10/0 ; // 这行代码会立即触发兜底方法,不会等待超时
int timeout = 3;
TimeUnit.SECONDS.sleep(timeout);
} catch (InterruptedException e) {
e.printStackTrace();
}
return Thread.currentThread().getName()+"paymentInfoTimeout-id="+id;
}
//兜底方法
public String paymentInfoHandler(Integer id){
return "程序出错请重试"+id;
}
主程序类上加注解
@SpringBootApplication
@EnableEurekaClient
@EnableCircuitBreaker
public class HystrixMain8001 {
@EnableHystrix 自带 @EnableCircuitBreaker
80controller调用feignHystrixService,feignHystrixService调用8001controller,测试超时时间
@HystrixCommand(fallbackMethod = "timeoutFallback" ,commandProperties = {
@HystrixProperty(name="execution.isolation.thread.timeoutInMilliseconds",value="5000")})
@GetMapping("/consumer/payment/timeout/{id}")
public String paymentInfoTimeout(@PathVariable("id") Integer id){
return feignHystrixService.paymentInfoTimeout(id);
}
public String timeoutFallback(@PathVariable("id") Integer id){
return "程序异常,请重试"+id;
}
80 yaml
server:
port: 80
eureka:
client:
register-with-eureka: false
service-url:
defaultZone: http://eureka7001.com:7001/eureka/
#feign:
# hystrix:
# # true 开启feign对hystrix的支持
# enabled: true
# 暂时注释掉,不知什么原因开启支持会报错,注释掉可以正常启动
hystrix:
command:
default:
execution:
isolation:
thread:
timeoutInMilliseconds: 3000
ribbon:
# 指的是建立连接后从服务器读取到可用资源所用的时间
ReadTimeout: 5000
# 指的是建立连接所用的时间,适用于网络状况正常的情况下,两端连接所用的时间
ConnectTimeout: 5000
controller中超时时间配置不生效原因:
关键在于feign:hystrix:enabled: true的作用,官网解释“Feign将使用断路器包装所有方法”,也就是将@FeignClient标记的那个service接口下所有的方法进行了hystrix包装(类似于在这些方法上加了一个@HystrixCommand),这些方法会应用一个默认的超时时间为1s,所以你的service方法也有一个1s的超时时间,service1s就会报异常,controller立马进入备用方法,controller上那个3秒那超时时间就没有效果了。
改变这个默认超时时间方法:
hystrix:
command:
default:
execution:
isolation:
thread:
timeoutInMilliseconds: 3000
然后ribbon的超时时间也需加上
ribbon:
ReadTimeout: 5000
ConnectTimeout: 5000
全局fallback方法@DufaultProperties(defaultFallback="")
@DefaultProperties(defaultFallback = “”)
一对一每个方法配置一个服务降级方法,技术上可以,但实际上是不明智的选择,代码很膨胀
一对N除了个别重要核心业务有专属,其它普通的可以通过@DefaultProperties(defaultFallback = ")统一跳转到统一处理结果页面
通用的和独享的各自分开,避免了代码膨胀,合理减少了代码量,
类上加上注解@DefaultProperties()设置统一降级的方法
@RestController
@DefaultProperties(defaultFallback = "globalFallback")
public class FeignHystrixOderController {
方法上加上@HystrixCommand注解 不指定特定的兜底方法
// @HystrixCommand(fallbackMethod = "timeoutFallback" ,commandProperties = {
// @HystrixProperty(name="execution.isolation.thread.timeoutInMilliseconds",value="5000")})
@HystrixCommand // 不指定特定的兜底方法
@GetMapping("/consumer/payment/timeout/{id}")
public String paymentInfoTimeout(@PathVariable("id") Integer id){
int i = 10/0;// 制造错误
return feignHystrixService.paymentInfoTimeout(id);
}
------------统一 --------------
public String globalFallback(){
return "全局降级方法";
}
统配服务降级FeignFallback
service 去调用LOUD-PROVIDER-HYSTRIX-PAYMENT这个微服务下的方法,如果出现错误 (超时、运行时异常、宕机…)
就会启动兜底方法,现给这个service接口下的所有方法统配一个兜底方法的实现类
@FeignClient()注解中添加内容 fallback=xxx.class
// 调用哪个服务,如果出现错误,采用哪个兜底方法,在消费端自处理
@FeignClient(value = "CLOUD-PROVIDER-HYSTRIX-PAYMENT",fallback = FeignHystrixServiceImpl.class)
public interface FeignHystrixService {
FeignHystrixFallback.class
@Component
public class FeignHystrixFallback implements FeignHystrixService {
@Override
public String paymentInfoOk(Integer id) {
return "消费端自处理异常";
}
@Override
public String paymentInfoTimeout(Integer id) {
return "消费端自处理异常";
} }
现在去调用正常运行的ok方法,方法上没有加@HystrixCommand,运行过程中,关闭8001提供者,造成宕机,消费端会自动启用自己的兜底方法
@GetMapping("/consumer/payment/ok/{id}")
public String paymentInfoOk(@PathVariable("id") Integer id){
return feignHystrixService.paymentInfoOk(id);
}
熔断机制
熔断机制概述
熔断机制是应对雪崩效应的一种微服务链路保护机制。当扇出链路的某个微服务出错不可用或者响应时间太长时,会进行服务的降级,进而熔断该节点微服务的调用,快速返回错误的响应信息。
当检测到该节点微服务调用响应正常后,恢复调用链路。
在Spring Cloud框架里,熔断机制通过Hystrix实现。Hystrix会监控微服务间调用的状况,
当失败的调用到一定阈值,缺省是5秒内20次调用失败,就会启动熔断机制。熔断机制的注解是@HystrixCommand。
1、调用失败会触发降级而降级会调用fal lback方法。
2、但无论如何降级的流程一定会先调用正常方法再调用fallback方法
3、假如单位时间内调用失败次数过多,也就是降级次数过多,则触发熔断
- 当失败的调用到一定阈值,缺省是5秒内20次调用失败,就会启动熔断机制。熔断机制的注解是@HystrixCommand。
4、熔断以后就会跳过正常方法直接调用fallback方法
5、所谓“熔断后服务不可用”就是因为跳过了正常方法直接执行fallback
8001提供者服务熔断
如果出现错误,降级次数过多,就会触发熔断,熔断后会直接跳过正常方法,直接执行fallback,一段时间后才会再次执行正常方法
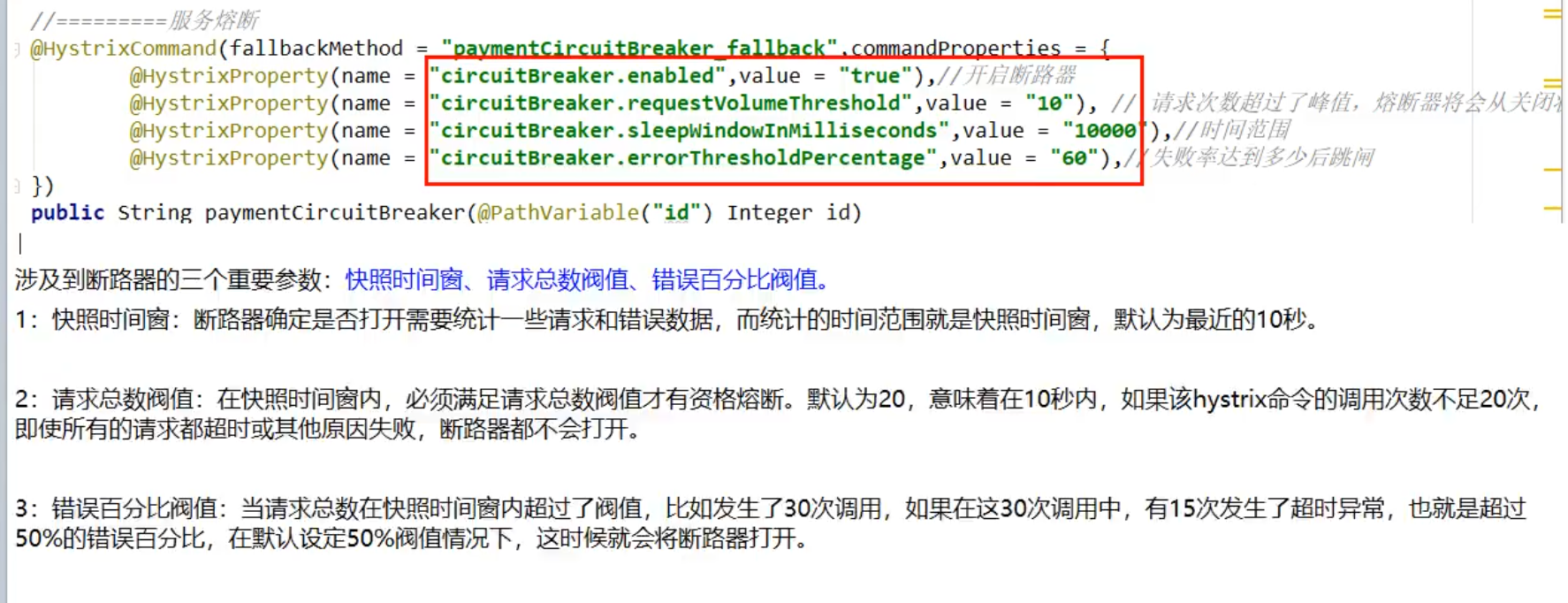
以下注解参数的含义,开启断路器,在10秒内 10次请求,错误率达到60% 就会触发熔断
//服务熔断
@HystrixCommand(fallbackMethod = "paymentCircuitBreaker_fallback",commandProperties = {
@HystrixProperty(name = "circuitBreaker.enabled", value = "true"),// 是否开启断路器
@HystrixProperty(name = "circuitBreaker.requestVolumeThreshold", value = "10"),// 请求次数
@HystrixProperty(name = "circuitBreaker.sleepWindowInMilliseconds", value = "10000"), // 时间窗口期
@HystrixProperty(name = "circuitBreaker.errorThresholdPercentage", value = "60"),// 失败率达到多少后跳闸
})
public String paymentCircuitBreaker(@PathVariable("id")Integer id){
if(id < 0){
throw new RuntimeException("id 不能小于0");
}
String serialNumber = IdUtil.simpleUUID();
return "调用 "+Thread.currentThread().getName()+"成功"+"流水号为:"+serialNumber;
}
// 服务熔断fallback方法
public String paymentCircuitBreaker_fallback(@PathVariable("id")Integer id)
{
return "id:"+id+" 不能小于0";
}
熔断三种类型
熔断打开
- 请求不再进行调用当前服务,内部设置时钟一般为MTTR(平均故障处理时间),当打开时长达到所设时钟则进入半熔断状态
熔断关闭
- 熔断关闭不会对服务进行熔断
熔断半开
- 部分请求根据规则调用当前服务,如果请求成功且符合规则则认为当前服务恢某正常,关闭熔断
断路器什么时候开始起作用?
断路器打开或者关闭的条件
当满足一定的阀值的时候(默认10秒内超过20个请求次数)
当失败率达到一定的时候(默认10秒内超过50%的请求失败)到达以上阀值,断路器将会开启
当开启的时候,所有请求都不会进行转发
一段时间之后(默认是5秒),这个时候断路器是半开状态,会让其中一个请求进行转发。如果成功,断路器会关闭,若失败,继续开启。重复4和5
DashBoard
服务监控
新的依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix-dashboard</artifactId>
</dependency>
新的注解
@EnableHystrixDashboard
public class DashBoardMain9001 {...}
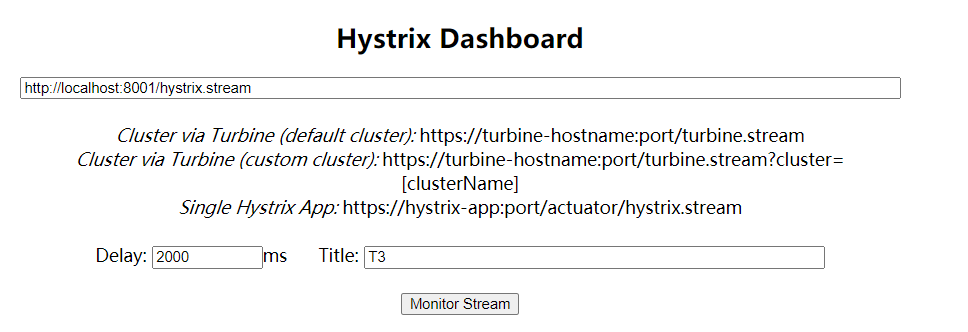
搭建完成后
http://localhost:9001/hystrix` 微服务监控页面
9001 监控 8001
被监控的服务一定要有actuator依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
被监控的服务主程序类上还要加上
/**
*此配置是为了服务监控而配置,与服务容错本身无关,springcloud升级后的坑
*ServletRegistrationBean因为springboot的默认路径不是"/hystrix.stream",
*只要在自己的项目里配置上下面的servlet就可以了
*/
@Bean
public ServletRegistrationBean getServlet() {
HystrixMetricsStreamServlet streamServlet = new HystrixMetricsStreamServlet();
ServletRegistrationBean registrationBean = new ServletRegistrationBean(streamServlet);
registrationBean.setLoadOnStartup(1);
registrationBean.addUrlMappings("/hystrix.stream");
registrationBean.setName("HystrixMetricsStreamServlet");
return registrationBean;
}
服务监控地址
地址后面的 /hystrix.stream 是固定的
网关
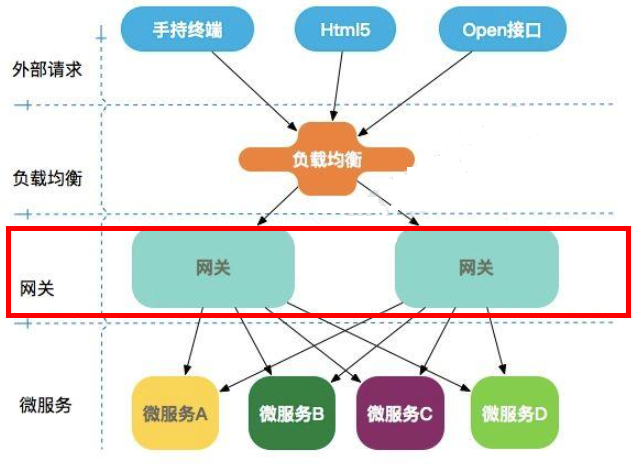
主流网关 : zuul zuul2 Gatway
Gateway是在Spring生态系统之上构建的API网关服务,基于Spring 5,Spring Boot 2和 Project Reactor等技术。
Gateway旨在提供一种简单而有效的方式来对API进行路由,以及提供一些强大的过滤器功能,例如:熔断、限流、重试等
能干嘛?
- 反向代理
- 鉴权
- 流量控制
- 熔断
- 日志监控
- …
微购物架构的网关在哪里?
GatWay 三大核心概念
- Route ( 路由 )
- 路由是构建网关的基本模块,它由ID,目标URI,一系列的断言和过滤器组成,如果断言为true则匹配该路由
- Predicate ( 断言 )
- 参考的是Java8的java.util.function.Predicate
开发人员可以匹配HTTP请求中的所有内容(例如请求头或请求参数),如果请求与断言相匹配则进行路由
- 参考的是Java8的java.util.function.Predicate
- Filter ( 过滤 )
- 指的是Spring框架中GatewayFilter的实例,使用过滤器,可以在请求被路由前或者之后对请求进行修改。
断言是判断具体哪个路由过滤器是找到路由然后做一些前置操作
新建项目
新的依赖
<!-- getway 不需要添加web 和 actuator 依赖 添加会报错 -->
<!--gateway-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-gateway</artifactId>
</dependency>
配置路由的方式一
gatway 的 yaml
server:
port: 9527
spring:
application:
name: cloud-gateway
cloud:
gateway:
routes:
- id: payment_routh #payment_route #路由的ID,没有固定规则但要求唯一,建议配合服务名
uri: http://localhost:8001 #匹配后提供服务的路由地址
predicates:
# 断言 8001外面套了一个9527 通过9527可以访问到8001 判断8001下是否有以下的路径,如果为true访问成功,false失败
# 后面的 ** 通配符,匹配地址栏中输入的{id}
- Path=/payment/getPayment/** # 断言,路径相匹配的进行路由
# 可以添加多个路由
# - id: payment_routh2 #payment_route #路由的ID,没有固定规则但要求唯一,建议配合服务名
# uri: http://localhost:8001 #匹配后提供服务的路由地址
# predicates:
# - Path=/payment/lb/** # 断言,路径相匹配的进行路由
eureka:
client: #服务提供者provider注册进eureka服务列表内
register-with-eureka: true
fetch-registry: true
defaultZone: http://eureka7001.com:7001/euraka
这样配置完成之后,相当于在配置的8001 的服务前面挡了一层,来做路由转发,执行过滤链等
访问的话既可以用8001端口访问,也可以用9527访问
配置路由的方式二
硬编码的方式
@Configuration
public class RouteConfig {
@Bean
public RouteLocator customerRouteLocator(RouteLocatorBuilder routeLocatorBuilder){
RouteLocatorBuilder.Builder routes = routeLocatorBuilder.routes();
// ( id名字随意,路由(http://localhost:9527/guonei),映射的地址 )
routes.route("routeLocator",r->r.path("guonei").uri("http://news.baidu.com/guonei")).build();
return routes.build();
}
}
动态路由
默认情况下Gateway会根据注册中心注册的服务列表,
以注册中心上微服务名为路径创建动态路由进行转发,从而实现动态路由的功能
需要注意的是uri的协议为lb,表示启用Gateway的负载均衡功能。
routes:
- id: payment_routh #payment_route #路由的ID,没有固定规则但要求唯一,建议配合服务名
#uri: http://localhost:8001 #匹配后提供服务的路由地址
uri: lb://cloud-payment-service #使用负载均衡的方式,匹配提供服务的路由地址
predicates:
# 断言 8001外面套了一个9527 通过9527可以访问到8001 判断8001下是否有以下的路径,如果为true访问成功,false失败
# 后面的 ** 通配符,匹配地址栏中输入的{id}
- Path=/payment/getPayment/** # 断言,路径相匹配的进行路由
常用的 route Predicate
1、After Route Predicate
地址匹配成功后,还需要时间匹配,到了设定的时间之后,才可以正常访问路径(类似商城秒杀开始时间)
ZonedDateTime zbj = ZonedDateTime.now(); // 默认时区 获取当前时区时间
...
- id: payment_routh2 #payment_route #路由的ID,没有固定规则但要求唯一,建议配合服务名
# uri: http://localhost:8001 #匹配后提供服务的路由地址
uri: lb://cloud-payment-service #匹配后提供服务的路由地址
predicates:
- Path=/payment/lb/** # 断言,路径相匹配的进行路由
- After=2020-02-05T15:10:03.685+08:00[Asia/Shanghai] # 断言,路径相匹配的进行路由
2、Before Route Predicate
设定时间之前才可以访问路径
3、Between Route Predic
设定时间之间才可以访问路径
4、Cookie Route Predicate
带cookie才可以访问,不带cookie才可以访问,带什么cookie才可以访问,
...
- id: payment_routh2 #payment_route #路由的ID,没有固定规则但要求唯一,建议配合服务名
# uri: http://localhost:8001 #匹配后提供服务的路由地址
uri: lb://cloud-payment-service #匹配后提供服务的路由地址
predicates:
- Path=/payment/lb/** # 断言,路径相匹配的进行路由
- Cookie= username,hhqq # kv键值对 路径访问时,需要携带这个kv的cookie才可以正常访问
可以用cmd的 curl进行测试
C:\Users\guoqi>curl http://localhost:9527/payment/port --cookie "username=hhqq"
8001
C:\Users\guoqi>curl http://localhost:9527/payment/port --cookie "username=hhqq"
8002
5、Header Route Predicate
6、Host Route Predicate
7、Method Route Predicate
8、Path Route Predicate
9、Query Route Predicate
自定义全局GlobalFilter
能干嘛?
- 全局日志记录
- 统一网关鉴权
- …
@Component
@Slf4j
// 自定义全局过滤
public class MyLogGetWayFilter implements GlobalFilter, Ordered {
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
String uname = exchange.getRequest().getQueryParams().getFirst("uname");// 请求路径中需要包含uname参数
if(uname == null){
log.info("用户错误,不可接受");
exchange.getResponse().setStatusCode(HttpStatus.NOT_ACCEPTABLE);
return exchange.getResponse().setComplete();
}
return chain.filter(exchange);
}
@Override
public int getOrder() {
return 0;
}
}
Config配置
总控中心搭建
首先在git上创建一个远程库 ,并拉取到本地,再提交三个配置文件上去,以模拟不同的生产环境,可以做到任意切换配置文件
配置文件中,正常的yaml格式的键值对即可,以dev配置文件为例
config:
info: dev branch,springloud-config/config-dev/yml version=1
创建配置中心模块 cloud-config-center
新的pom依赖模块后缀名带有server 说明这是config的服务端,客户端不带server
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-config-server</artifactId>
</dependency>
修改yaml文件
server:
port: 3344
spring:
application:
name: cloud-config-center #注册进Eureka服务器的微服务名
cloud:
config:
server:
git:
uri: https://gitee.com/gitgqH/cloud-study.git #Gitee上面的git仓库名字
####搜索目录
search-paths:
- cloud-study
####读取分支
label: master
#服务注册到eureka地址
eureka:
client:
service-url:
defaultZone: http://localhost:7001/eureka
主程序类加上新的注解@EnableConfigServer
配置读取规则
/{label}/{application}-{profile}.yml
- /分支/配置-文件名.yaml ( 配置文件名字中心需要加 - 减号 )
- http://localhost:3344/master/config-test.yaml
- /分支/配置-文件名.yaml ( 配置文件名字中心需要加 - 减号 )
/{application}-{profile}.yml
- 路径取消掉分支 默认是master
/{application}/{profile}[/{label}]
- 。。。。
Config 配置中心客户端的配置
新建模块cloud-config-center-3355 yaml不再是applicaton.yaml了,而是bootstrap.yaml
因为bootstrap.yml (系统级别)是比application.yml (用户级别)先加载的。bootstrap.yml优先级高于application.yml
config 客户端配置的内容会自己进行拼接 减号 和 .yaml 会自动拼接起来
server:
port: 3355
spring:
application:
name: config-client
cloud:
#Config客户端配置
config:
label: master #分支名称
name: config #配置文件名称
profile: dev #读取后缀名称 上述3个综合:master分支上config-dev.yml的配置文件被读取http://config-3344.com:3344/master/config-dev.yml
uri: http://localhost:3344 #配置中心地址k
#服务注册到eureka地址
eureka:
client:
service-url:
defaultZone: http://localhost:7001/eureka

编写业务类
编写业务类,去拿到配置中心的配置文件的config.info 的内容
@RestController
public class ConfigController {
@Value("${config.info}")
private String configInfo;
@GetMapping(value = "/configInfo")
public String getInfo(){
return configInfo;
}
}
正确拿到之后,会出现一个问题
如果运维工程师在git中修改了配置中心的配置文件
3344 可以刷新一下获取最新的配置文件,但是3355却不行(因为3344 是直连git配置中心的,3355 是拿到的java硬编码,死的),只有重启服务才可以拿到,这样会很浪费时间
所以需要动态刷新配置文件
手动版动态刷新配置文件
修改添加yaml,暴露监控模块
# 暴露监控端点
management:
endpoints:
web:
exposure:
include: "*"
引入pom.xml
如果发生改变会被监控到
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
在业务类上添加新的注解@RefreshScope 来动态获取并刷新配置
@RestController
@RefreshScope
public class ConfigController {
这样配置完成之后,发现3355还是获取不到最新的配置文件
因为需要运维人员发送Post请求刷新3355才可以
可以使用curl命令 post 请求 ,也可以使用postman…
curl -X POST “http://localhost:3355/actuator/refresh”
SpringBus消息总线
是什么?
Spring Cloud Bus 配合 Spring Cloud Config 使用可以实现配置的动态刷新。
Spring Cloud Bus是用来将分布式系统的节点与轻量级消息系统链接起来的框架,
它整合了Java的事件处理机制和消息中间件的功能。Spring Clud Bus目前支持RabbitMQ和Kafka。
能干嘛?
Spring Cloud Bus能管理和传播分布式系统间的消息,就像一个分布式执行器,可用于广播状态更改、事件推送等,也可以当作微服务间的通信通道。
配置
1、安装windows版本的erlang、rabbitmq
进入rabbitmq的sbin目录 cmd 输入命令
rabbitmq-plugins enable rabbitmq_management安装可视化插件( 前台监控页面 )
检查是否成功http://localhost:15672/
2、创建cloud-center-3366 模块,此模块也是像3355一样 客户端的配置
创建过程与3355一致
3、需要给三个配置中心的新添加一个依赖
<!--添加消息总线RabbitMQ支持-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-bus-amqp</artifactId>
</dependency>
添加yaml的rabbitmq的相关配置
#rabbitmq相关配置
rabbitmq:
host: localhost
port: 5672
username: guest
password: guest
4、3344配置暴露bus刷新的端点
##rabbitmq相关配置,暴露bus刷新配置的端点
management:
endpoints: #暴露bus刷新配置的端点
web:
exposure:
include: 'bus-refresh'
这样只用请求更新服务端配置中心3344配置中心即可,一次发送,处处更新
curl -X POST http://localhost:3344/actuator/bus-refesh
springBud动态刷新定点通知
只想通知消息总线中的一部分服务配置刷新
请求刷新连接后面加上 需要刷新的服务名加端口号
公式:http://localhost:配置中心的端口号/actuator/bus-refresh/{destination}
curl -X POST http://localhost:3344/actuator/bus-refesh/config-client:3366
springStream 消息驱动
是什么?
屏蔽底层消息中间件的差异,降低切换成本,统一消息的编程模型
stream凭什么可以统一底层差异?
通过定义绑定器Binder作为中间层,实现了应用程序与消息中间件细节之间的隔离。
bander有input、output
其中 INPUT 对应于消费者
OUTPUT对应于生产者
Spring Cloud Stream标准流程套路
- Binder
- 很方便的连接中间件,屏蔽差异
- Channel
- 通道,是队列Queue的一种抽象,在消息通讯系统中就是实现存储和转发的媒介,通过Channel对队列进行配置
- Source和Sink
- 简单的可理解为参照对象是Spring Cloud Stream自身,
从Stream发布消息就是输出,接受消息就是输入。
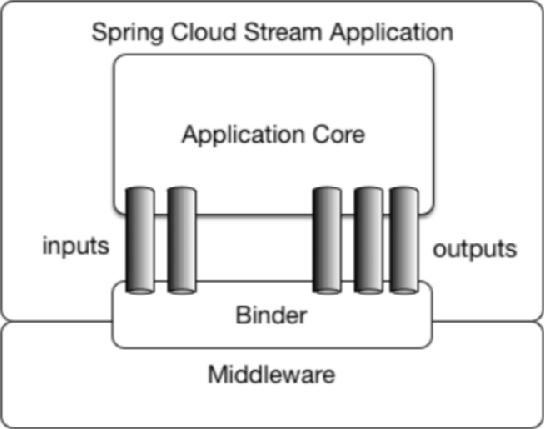
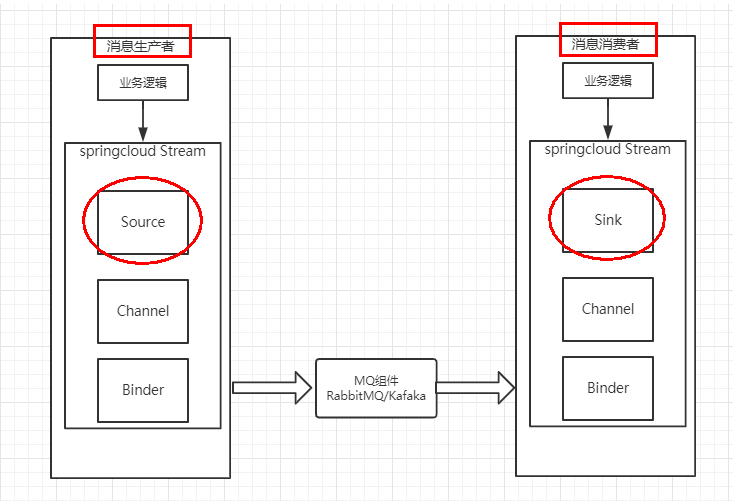
生产者 8801
新建一个cloud-stream-rabbitmq-provider8801 模块
yaml
server:
port: 8801
spring:
application:
name: cloud-stream-provider
cloud:
stream:
binders: # 在此处配置要绑定的rabbitmq的服务信息;
defaultRabbit: # 表示定义的名称,用于于binding整合
type: rabbit # 消息组件类型
environment: # 设置rabbitmq的相关的环境配置
spring:
rabbitmq:
host: localhost
port: 5672
username: guest
password: guest
bindings: # 服务的整合处理
output: # 这个名字是一个通道的名称
destination: studyExchange # 表示要使用的Exchange名称定义
content-type: application/json # 设置消息类型,本次为json,文本则设置“text/plain”
binder: defaultRabbit # 设置要绑定的消息服务的具体设置
eureka:
client: # 客户端进行Eureka注册的配置
service-url:
defaultZone: http://localhost:7001/eureka
instance:
lease-renewal-interval-in-seconds: 2 # 设置心跳的时间间隔(默认是30秒)
lease-expiration-duration-in-seconds: 5 # 如果现在超过了5秒的间隔(默认是90秒)
instance-id: send-8801.com # 在信息列表时显示主机名称
prefer-ip-address: true # 访问的路径变为IP地址
service
public interface IMessageProvider {
String sent();
}
impl
这里的impl调用的不再是dao了,而是创建一个消息发送的管道
@EnableBinding(Source.class) MessageChannel
@EnableBinding(Source.class) // 可以理解为是一个消息的发送管道的定义
public class MessageProviderImpl implements IMessageProvider {
@Resource
private MessageChannel output; // 消息的发送管道
@Override
public String sent() {
String msg = UUID.randomUUID().toString();
output.send(MessageBuilder.withPayload(msg).build()); // 创建并发送消息
System.out.println("***消息发送***"+msg);
return msg;//返回什么无所谓
}
}
最后controller调用
消费者8802
消费者的yaml 中 发生改变的地方
output变成input 这个是重点,区分生产者和消费者的地方
instance-id: provider-8801.com变成instance-id: receive-8802.com 这个无所谓只是显示的名称问题
bindings: # 服务的整合处理
input: # 这个名字是一个通道的名称
destination: studyExchange # 表示要使用的Exchange名称定义
content-type: application/json # 设置消息类型,本次为json,文本则设置“text/plain”
binder: defaultRabbit # 设置要绑定的消息服务的具体设置
.....
instance:
lease-renewal-interval-in-seconds: 2 # 设置心跳的时间间隔(默认是30秒)
lease-expiration-duration-in-seconds: 5 # 如果现在超过了5秒的间隔(默认是90秒)
instance-id: receive-8802.com # 在信息列表时显示主机名称
prefer-ip-address: true # 访问的路径变为IP地址
业务类
@EnableBinding(Sink.class) @StreamListener(Sink.INPUT)
@Component
@EnableBinding(Sink.class)
public class ReceiveMessageController {
@Value("${server.port}")
private String serverPort;
@StreamListener(Sink.INPUT) //监听
public void receive(Message<String>message){// 发送用的String类型,接收就用String
System.out.println("接收到的消息--->" + message.getPayload()+",端口号--->"+serverPort);
} }
重复消费问题
发生原因
注意在Stream中处于同一个group中的多个消费者是竞争关系,就能够保证消息只会被其中一个应用消费一次。
不同组是可以全面消费的(重复消费),
同一组内会发生竞争关系,只有其中一个可以消费。
所以把不同的消费者都改为同一个组,让它们造成竞争关系,即可避免重复消费
可以理解为发送给同一个queue,会用轮询的方式进行消费
在绑定关系的配置下,给不同的消费者添加相同的组名即可
bindings: # 服务的整合处理
input: # 这个名字是一个通道的名称
destination: studyExchange # 表示要使用的Exchange名称定义
content-type: application/json # 设置消息类型,本次为json,文本则设置“text/plain”
binder: defaultRabbit # 设置要绑定的消息服务的具体设置
group: gq1
持久化的问题
基本mq的理论
8802 8803 两个消费者都关闭服务,并且8802把group组名去掉了。
8801提供者发送消息。
重新启动8802 8803
这是只有8803可以消费到关闭服务时 ,提供者8801 发送的消息,8802是接收不到的。
原因
个人理解是,由于8802 没有绑定group组名,所以它默认归属的是随机的组名,
假设 :服务关闭时,提供者分别给 axx1 (对应着8802)和 gq1(对应着8803) 两个组发送消息 , 由于gq1绑定的是固定的组,所以再次启动也可以接收到消息。
而8802是随机的组名 再次启动服务,就会被分配到另一个组名上,发送给axx1的消息自然接收不到
Sleuth
Sleuth分布式请求链路跟踪
完整的调用链路
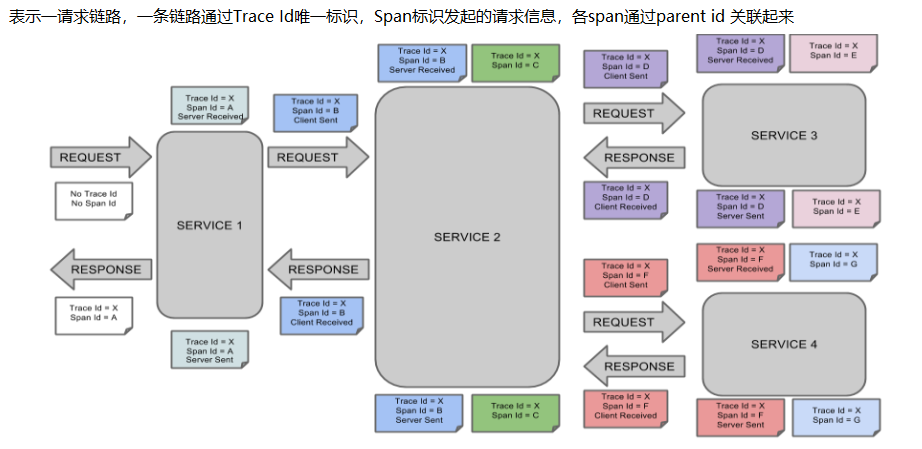
简易版
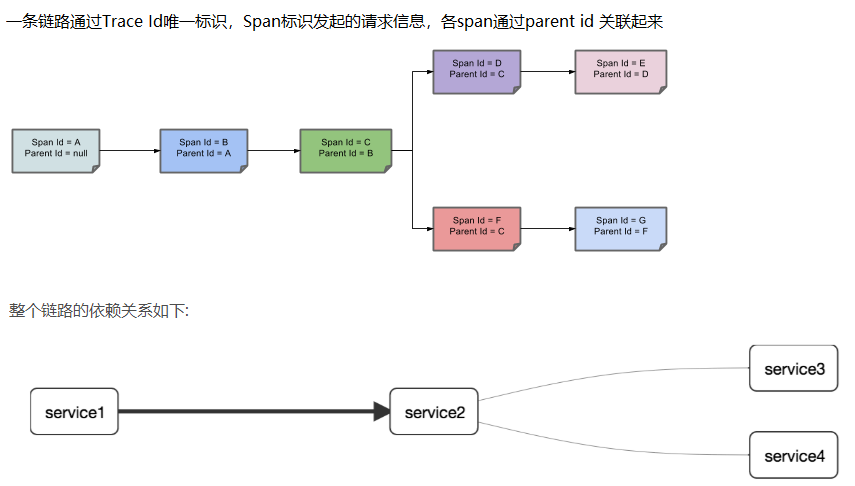
Trace:类似于树结构的Span集合,表示一条调用链路,存在唯一标识
span:表示调用链路来源,通俗的理解span就是一次请求信息
链路,简单来讲就是可以查看服务调用和被调用之间的关系,和相关依赖等等
安装zipkin 的jar包 (和sleuth是一个东西,你中有我我中有你,sleuth收购了zipkin)
cmd运行 java -jar zipkin-server-2.19.2-exec.jar
打开前台监控页面,默认端口号9411
提供者和消费者都要加上zipkin的依赖
<!--包含了sleuth+zipkin-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
新增yml
spring:
application:
name: cloud-payment-service
zipkin:
base-url: http://localhost:9411
sleuth:
sampler:
#采样率值介于 0 到 1 之间,1 则表示全部采集
probability: 1
写一个简单的业务类,让消费者调用
测试使用的是 80调用 8001 测试时去掉了80的@loadbalance负载均衡的注解,因为只启动了8001一个提供者,开启负载均衡会报错
此时就可以在 zipkin 9411 前台查看到调用和依赖的关系
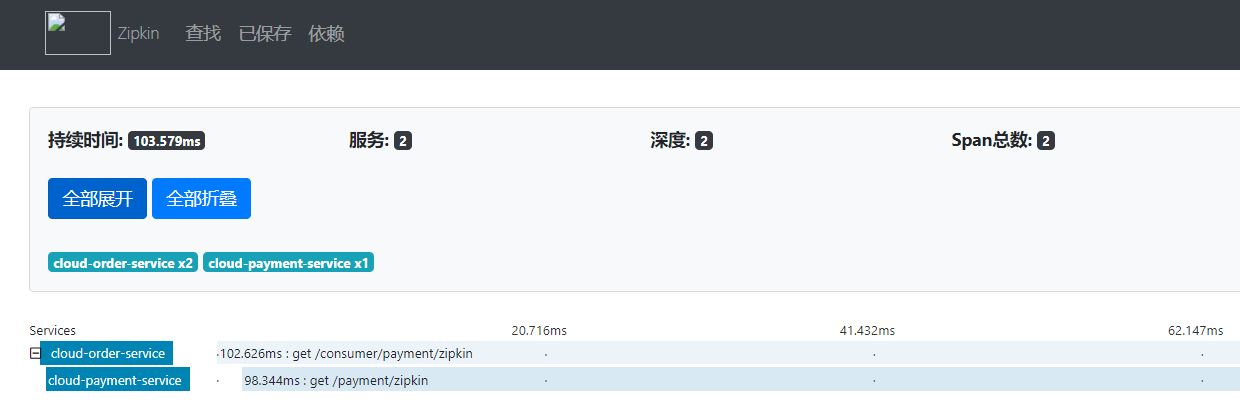
springCloud Alibaba
nacos服务注册
在nacos的bin目录下运行 startup.cmd 命令即可启动nacos
http://localhost:8848/nacos 访问nacos页面 ,服务注册中心的管理页面
默认账户、密码 nacos
springcloud父类引入依赖alibaba-dependencies
<!--spring cloud alibaba 2.1.0.RELEASE-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-alibaba-dependencies</artifactId>
<version>2.1.0.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
本类引入依赖alibaba-nacos-discovery
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
yaml 配置nacos
server:
port: 9001
spring:
application:
name: nacos-provider-service
cloud:
nacos:
discovery:
server-addr: localhost:8848 # 配置nacos地址
# 监控端点
management:
endpoints:
web:
exposure:
include: '*'
nacos整合了ribbon,自带负载均衡
nacos配置中心
新建项目cloud-nacos-cconfig-center3377
导入新的依赖
<!--nacos-config-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId>
</dependency>
新建两个配置文件 bootstrap.yaml application.yaml ,预先加载bootstap.yaml
bootstap.yaml
配置文件读取规则:
prefix 默认为 spring.application.name 的值
spring.profile.active 即为当前环境对应的 profile,可以通过配置项 spring.profile.active 来配置。
file-exetension 为配置内容的数据格式,可以通过配置项 spring.cloud.nacos.config.file-extension 来配置
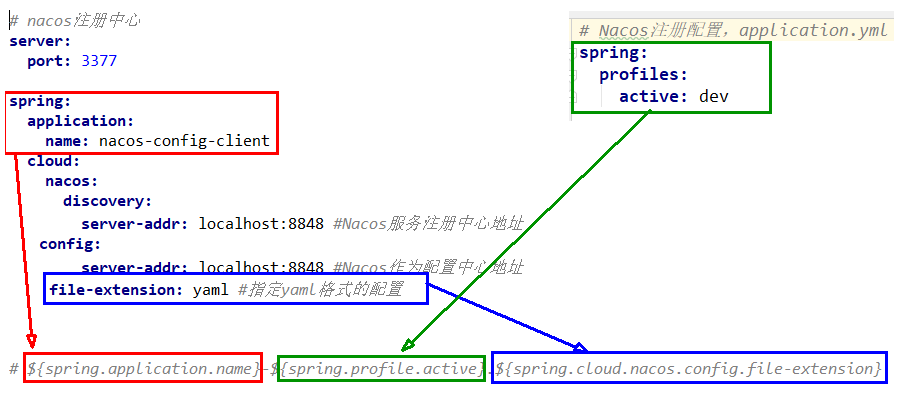
server:
port: 3377
spring:
application:
name: nacos-config-center
cloud:
nacos:
discovery:
server-addr: localhost:8848 #Nacos服务注册中心地址
config:
server-addr: localhost:8848
file-extension: yaml #指定yaml格式的配置
# 配置文件读取规则${spring.application.name}-${spring.profile.active}.${spring.cloud.nacos.config.file-extension}
application.yaml
spring:
profiles:
active: dev
在nacos页面新建配置文件
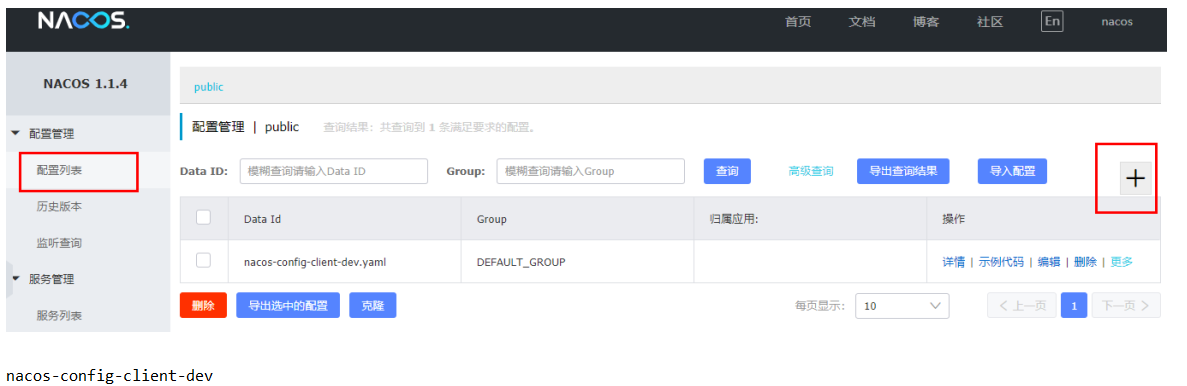
最后业务类加上注解@RefreshScope,在控制器类加入@RefreshScope注解使当前类下的配置支持Nacos的动态刷新功能。
配置文件的三种加载方案
1、GroupID 的方式
通过配置文件的名字来区分
默认空间+默认分组+新建dev和test两个DataID
application.yaml配置
spring:
profiles:
# active: info
active: dev
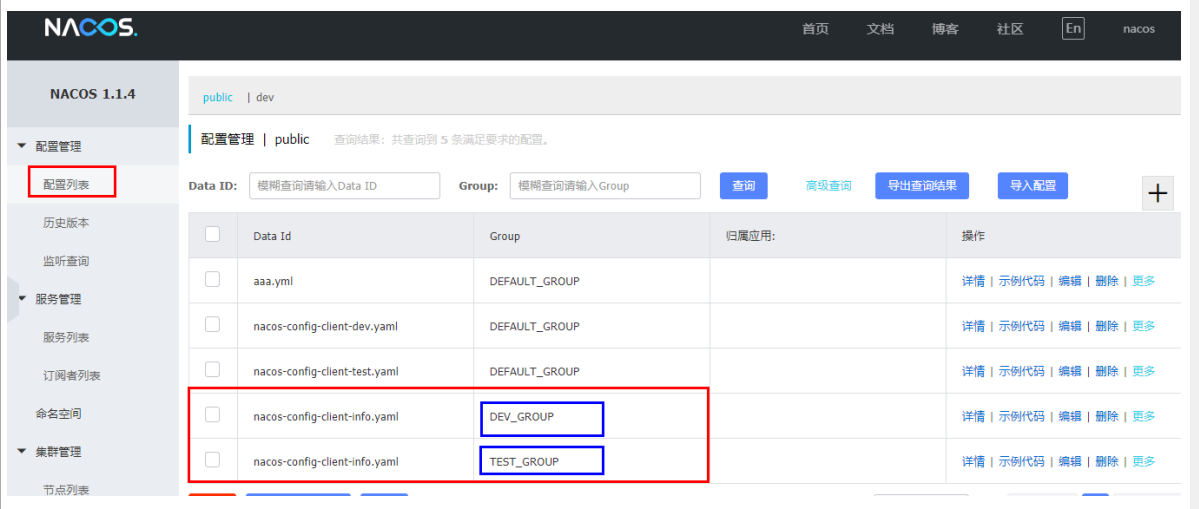
2、Group的方式
通过group来实现环境的区分
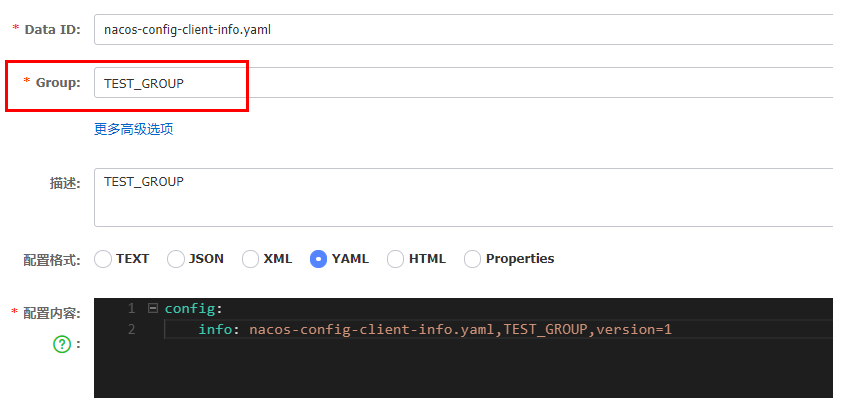
bootstrap.yaml中加上group的配置信息
config:
server-addr: localhost:8848
file-extension: yaml #指定yaml格式的配置
group: TEST_GROUP
3、namespace的方式
新建命名空间
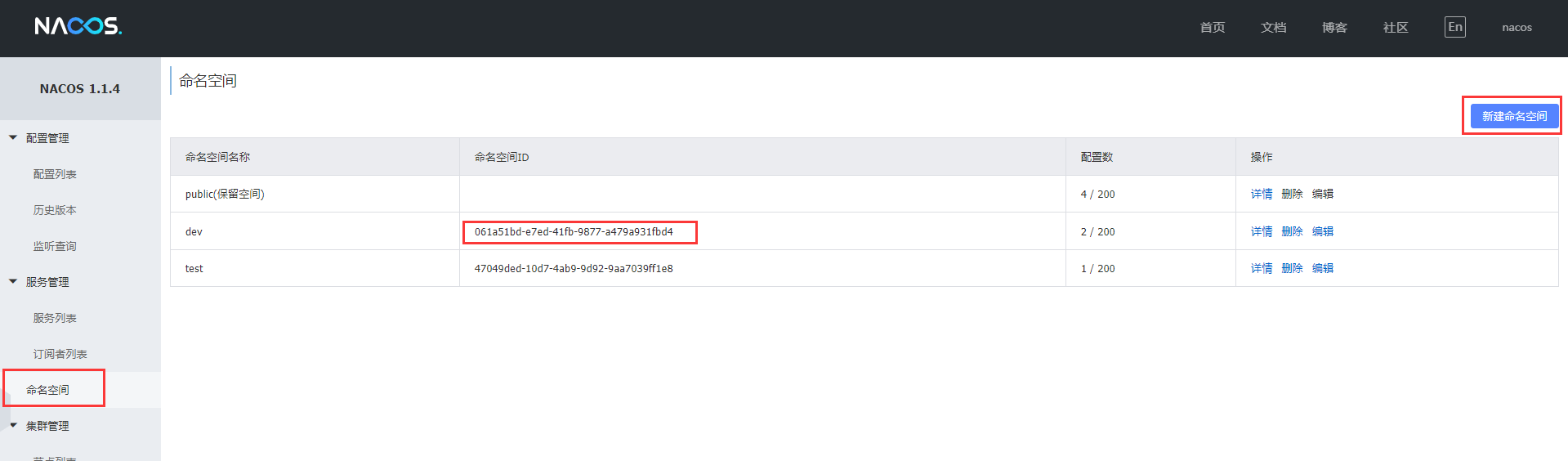
再根据命名空间分类,来获取不同组的配置文件
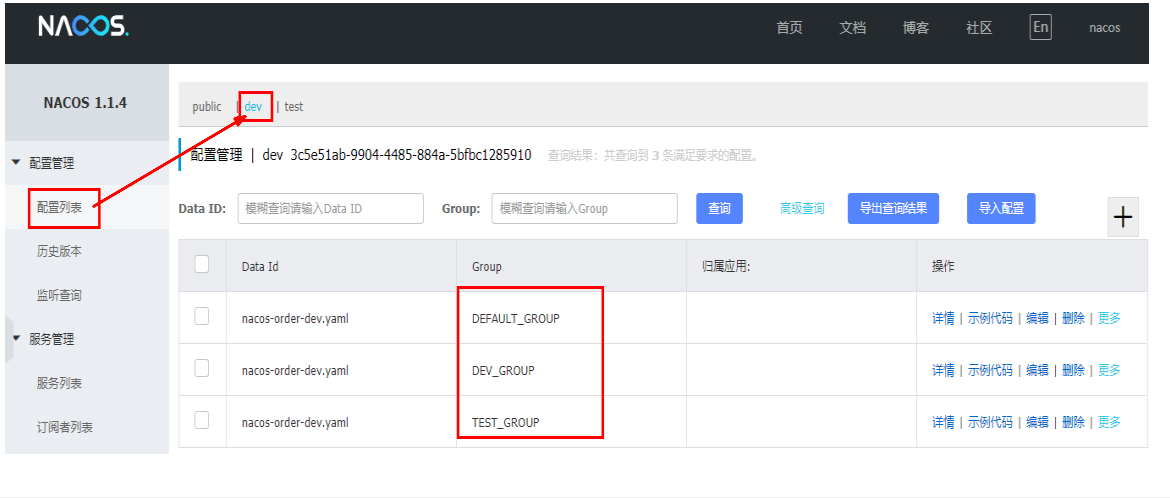
bootstrap.yaml加上namespace的配置信息
config:
server-addr: localhost:8848
file-extension: yaml #指定yaml格式的配置
group: TEST_GROUP
namespace: 061a51bd-e7ed-41fb-9877-a479a931fbd4
配置文件的名字后缀都统一在spring.profiles.active中配置
简单来讲三种方案就是分组再分组
持久化
nacos默认自带一个嵌入式数据库derby
集群中的每一个服务都会把数据存到这里,会造成数据不一致的问题
所以需要一个统一的数据源,nacos官方建议使用mysql
将nacos/conf文件夹给的nacos-config.sql文件夹来建表
nacos/conf 文件夹中的application.properties新增内容
#使用的数据源
spring.datasource.platform=mysql
db.num=1
db.url.0=jdbc:mysql://127.0.0.1:3306/nacos_config?characterEncoding=utf8&connectTimeout=1000&socketTimeout=3000&autoReconnect=true
db.user=root
db.password=3333
此时nacos的数据源已经切换到了mysql
linux系统nacos的使用
解压nacos安装包
在bin目录下使用命令启动
使用mysql数据源
在linux下安装mysql( mysql笔记下有记录 )
与windows一样
使用nacos给的sql脚本,建库建表
修改并备份一份 bin/application.properties
修改添加使用的数据源信息,与windows一致
集群
进入nacos的conf目录
再拷贝一份cluster.conf.example 并重命名为cluster.conf
在里面添加集群主机的ip地址和端口号
192.168.177.130:3333
192.168.177.130:4444
192.168.177.130:5555
编辑Nacos的启动脚本startup.sh,使它能够接受不同的启动端口
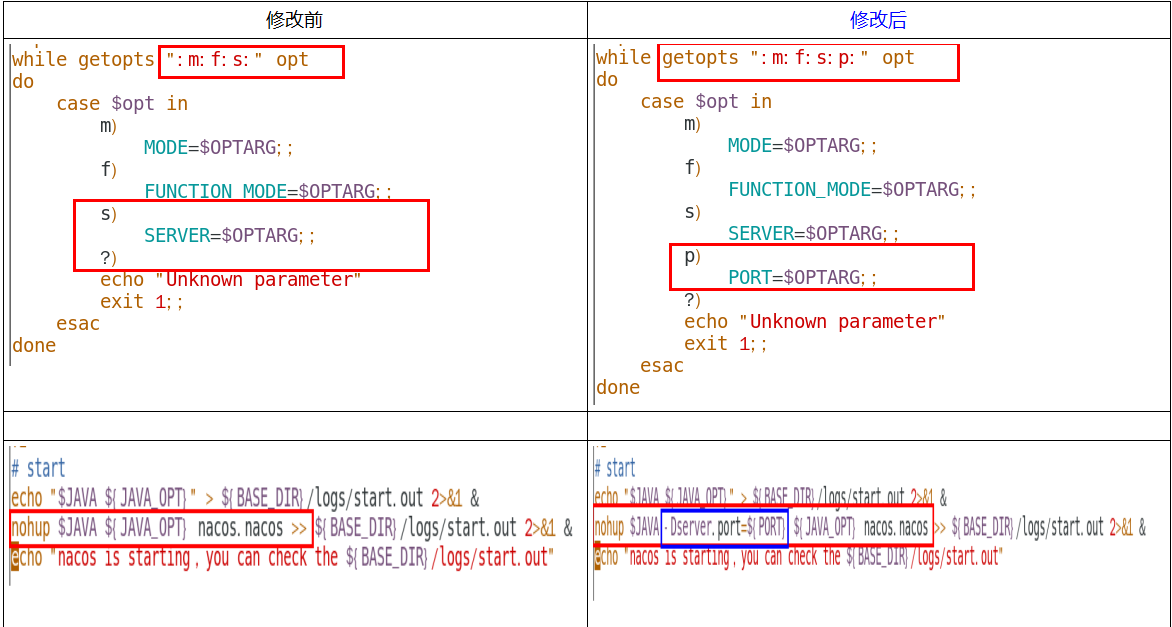
nginx的集群配置
upstream cluster{
server 192.168.177.130:3333;
server 192.168.177.130:4444;
server 192.168.177.130:5555;
}
server {
listen 1111;
server_name localhost;
#charset koi8-r;
#access_log logs/host.access.log main;
location / {
# root html;
# index index.html index.htm;
proxy_pass http://cluster;
}
启动nacos集群
使用bin目录的命令 ./startip.sh -p 3333 后面跟上配置好的nacos集群端口号 3333、4444、5555
可以使用ps -ef | grep nacos| grep -v grep | wc -l 查看成功的启动了几台nacos
启动nginx
使用命令./nginx -c /usr/local/nginx/conf/nginx.conf -c 指定配置文件
测试
访问http://192.168.177.130:1111/nacos 因为修改了nginx的配置文件 , 监听的是1111端口
进入到nacos的页面, 添加配置
查看linux的MySQL 的nacos_info 表是否有新增的记录。
最后测试将微服务 payment9002 注册进Linux的nacos
Slibaba Sentinel
类似hystirx 可以做服务监控 服务降级 服务限流…
下载安装
访问GitHub的sintinel页面下载sentinel的jar包
使用java命令运行java -jar sentinel.xxxx
前台默认端口8080 用户名&密码 都是sentinel
使用
创建cloudalibaba-sentinel-service8401 微服务
添加新的依赖
<!--SpringCloud ailibaba nacos -->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
<!--SpringCloud ailibaba sentinel-datasource-nacos 后续做持久化用到-->
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-datasource-nacos</artifactId>
</dependency>
<!--SpringCloud ailibaba sentinel -->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-sentinel</artifactId>
</dependency>
yaml配置
server:
port: 8401
spring:
application:
name: cloudalibaba-sentinel-service
cloud:
nacos:
discovery:
#Nacos服务注册中心地址
server-addr: localhost:8848
sentinel:
transport:
#配置Sentinel dashboard地址
dashboard: localhost:8080
#默认8719端口,假如被占用会自动从8719开始依次+1扫描,直至找到未被占用的端口
port: 8719
management:
endpoints:
web:
exposure:
include: '*'
写一个简单的业务类。
启动微服务,访问sentinel的控制台,发现并没有监控到服务
因为sentinel使用的懒加载,需要客户端和服务端相互连通( 服务端可以访问到客户端,客户端也要执行一次访问(controller业务类的访问即可)连接一下服务端 )
Sentinel流控
- 资源名:唯一名称,默认请求路径
- 针对来源: Sentinel可以针对调用者进行限流,填写微服务名,默认default(不区分来源)
- 阈值类型/单机阈值:
- QPS(每秒钟的请求数量):当调用该api的QPS达到阈值的时候,进行限流
- 线程数:当调用该api的线程数达到阈值的时候,进行限流
- 是否集群:不需要集群
- 流控模式:
- 直接:api达到限流条件时,直接限流
- 关联:当关联的资源达到阈值时,就限流自己
- 链路:只记录指定链路上的流量(指定资源从入口资源进来的流量,如果达到阈值,就进行限流)【api级别的针对来源】
- 流控效果:
- 快速失败:直接失败,抛异常
- Warm Up:根据codeFactor (冷加载因子,默认3)的值,从阈值/codeFactor,经过预热时长,才达到设置的QPS阈值
- 排队等待:匀速排队,让请求以匀速的速度通过,阈值类型必须设置为QPS,否则无效
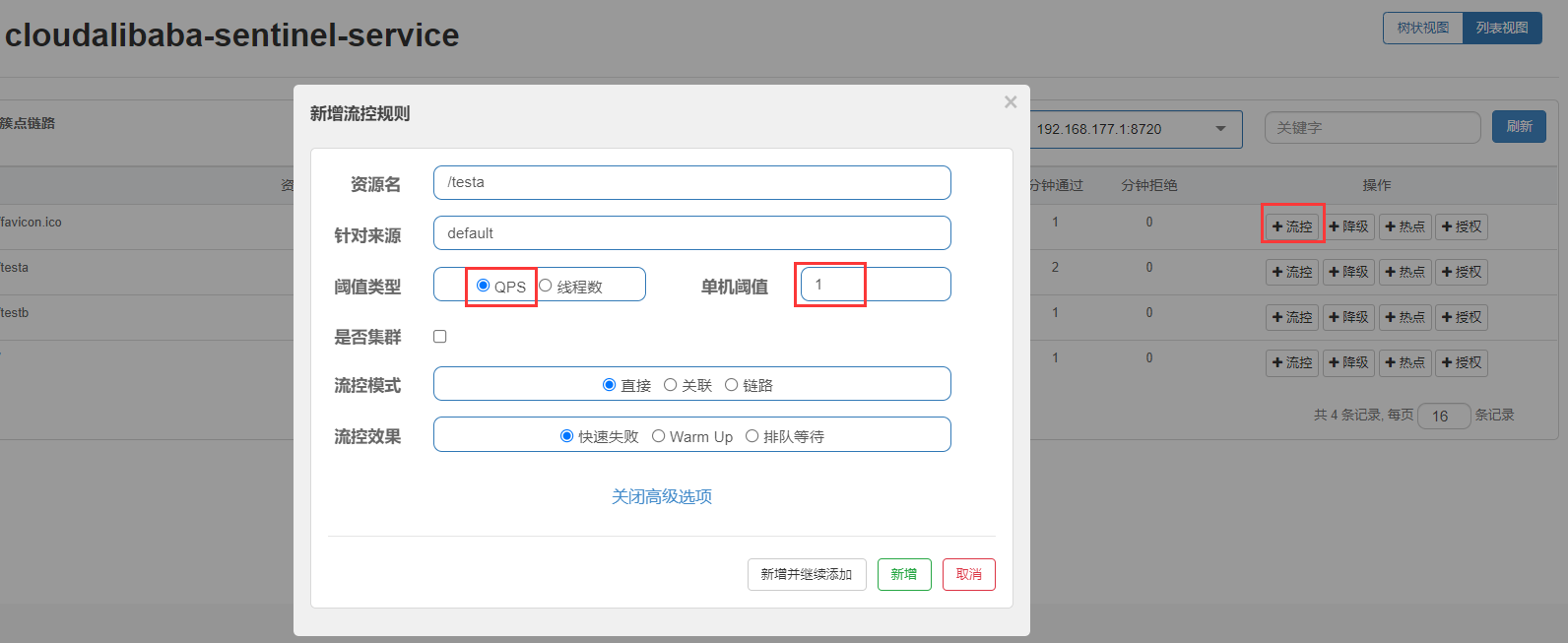
QPS(每秒钟的请求数量)∶当调用该api的QPS达到阈值的时候,进行限流
设置QPS 单机阈值为 1 : 每秒请求/testa 超过1次 ,则进行限流,会在前台展示限流信息
线程数限流:每秒超出设定的线程数量访问,则进行限流
关联流控模式
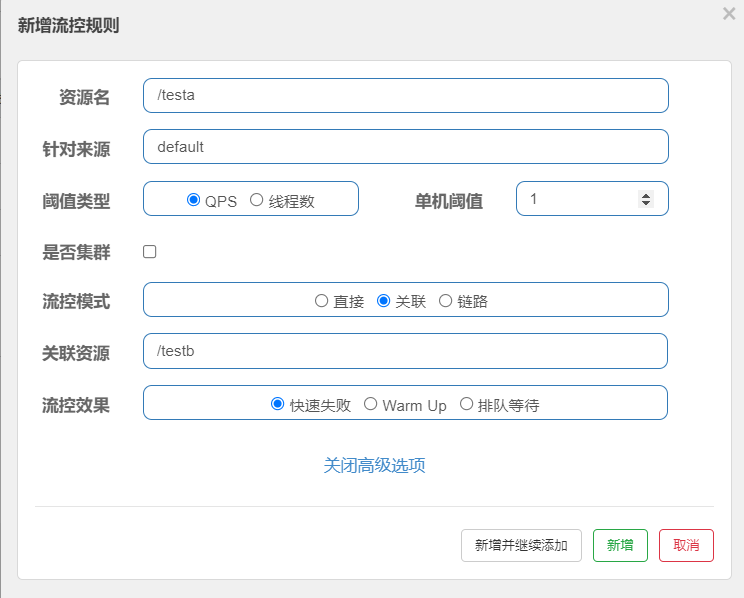
/testa 关联资源 /testb 如果B 的每秒请求数量超出阈值,则会限流A
Warm UP
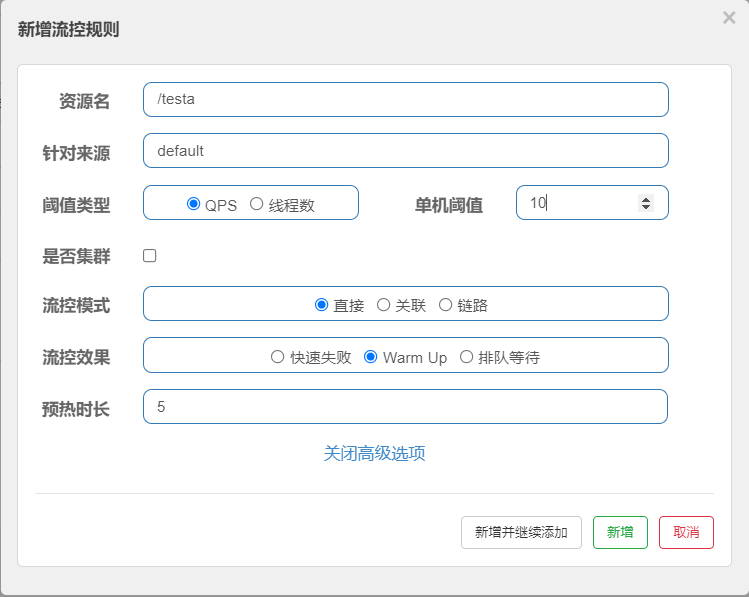
默认 coldFactor 为 3,即请求QPS从(threshold / 3) 开始,经多少预热时长才逐渐升至设定的 QPS 阈值。
案例,阀值为10+预热时长设置5秒。
系统初始化的阀值为10 / 3 约等于3,即阀值刚开始为3;然后过了5秒后阀值才慢慢升高恢复到10
( 10/3 =3 一开始的每秒访问量为3,过5秒后,恢复10的访问量 )
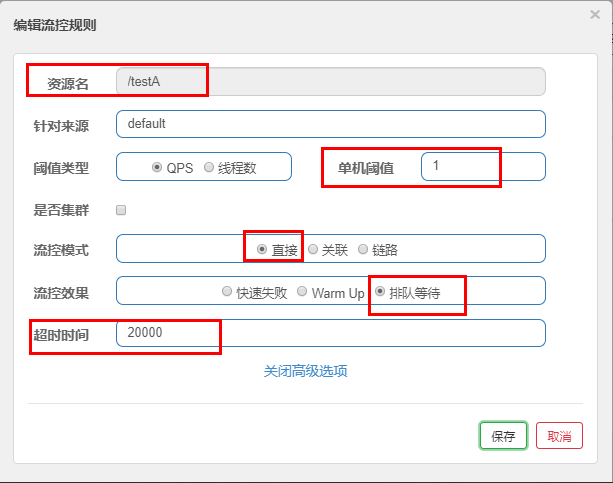
排队等待
匀速排队,让请求以均匀的速度通过,阀值类型必须设成QPS,否则无效。
设置含义:/testA每秒1次请求,超过的话就排队等待,等待的超时时间为20000毫秒。
熔断降级
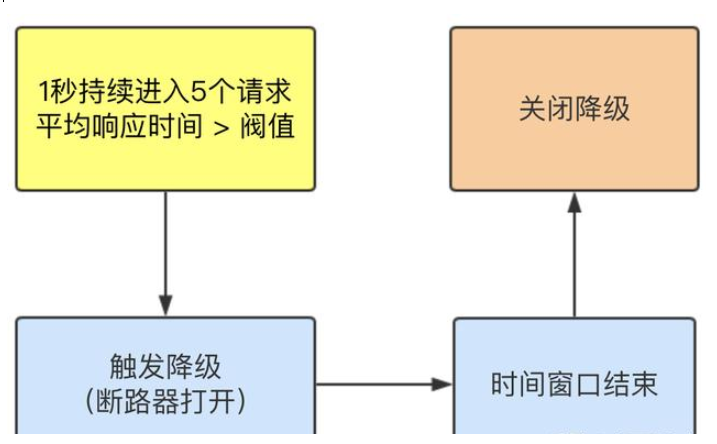
Sentinel 熔断降级会在调用链路中某个资源出现不稳定状态时(例如调用超时或异常比例升高),对这个资源的调用进行限制,
让请求快速失败,避免影响到其它的资源而导致级联错误。当资源被降级后,在接下来的降级时间窗口之内,对该资源的调用都自动熔断(默认行为是抛出 DegradeException)。
Sentinel的断路器是没有半开状态的
半开的状态系统自动去检测是否请求有异常,
没有异常就关闭断路器恢复使用,
有异常则继续打开断路器不可用。具体可以参考Hystrix
RT
( 平均响应时间,秒级 )

请求 总体响应的平均时间 > 设定的阈值 则会触发降级(默认上限4900ms),才会触发降级
测试
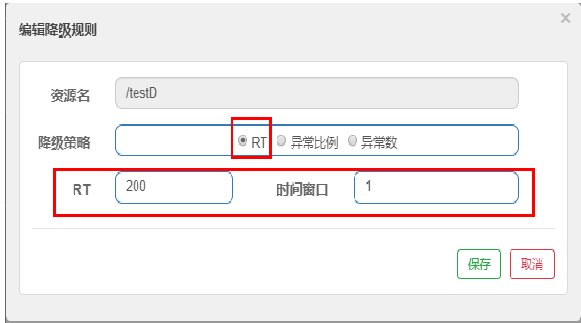
RT 每秒的请求数量 5 个
设定200ms 每个请求需要在200ms内完成。
也就是 5 个请求 总体响应的平均时间 > 设定的阈值 则会触发降级
时间窗口:降级时间间隔,设定10秒的时间窗口,每过10秒就会进行监控是否满足降级条件
按照上述配置,
永远一秒钟打进来10个线程(大于5个了)调用testD,我们希望200毫秒处理完本次任务,
如果超过200毫秒还没处理完,在未来1秒钟的时间窗口内,断路器打开(保险丝跳闸)微服务不可用,保险丝跳闸断电了
后续停止jmeter,没有这么大的访问量了,断路器关闭(保险丝恢复),微服务恢复OK
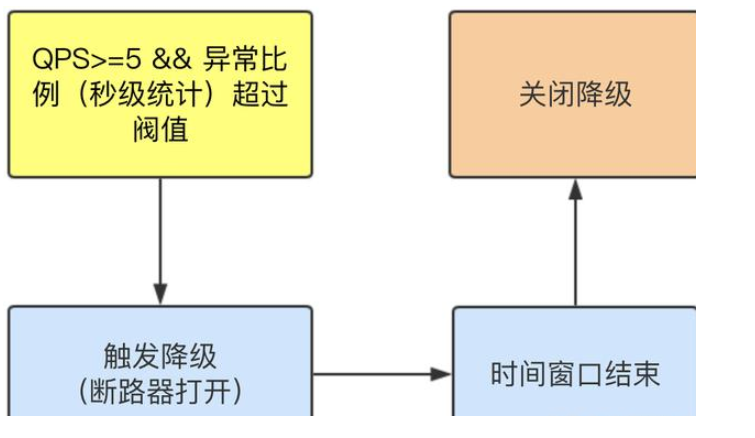
异常比例

同时满足两点,触发降级
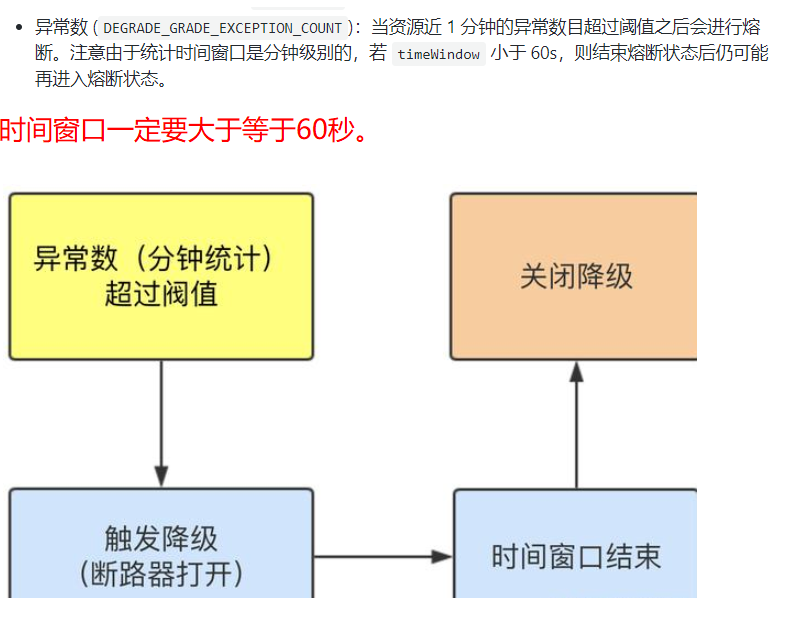
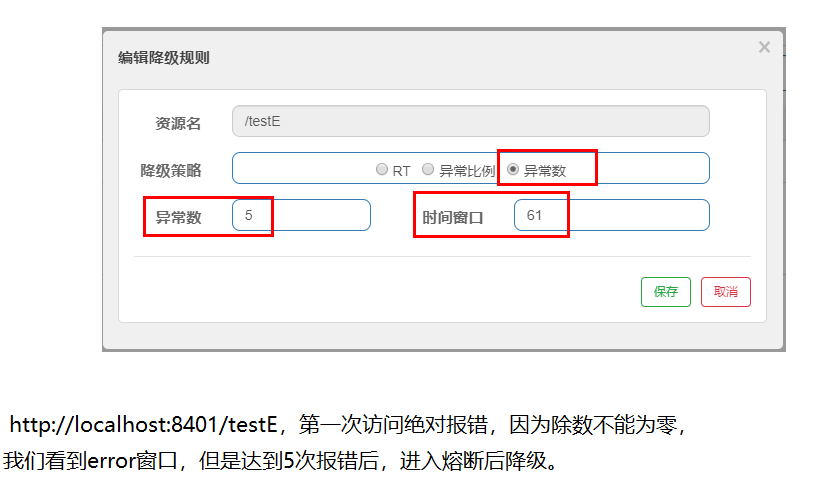
异常数
出现的异常超过设定的次数,触发降级
热点限流
何为热点
热点即经常访问的数据,很多时候我们希望统计或者限制某个热点数据中访问频次最高的TopN数据,并对其访问进行限流或者其它操作
新的注解@SentinelResource 类似 @HystrixCommand
@GetMapping(value = "/hotKey")
//热点,value: 监控的资源名,自定义的,命名规范是与请求地址一致,去掉/ , blockHandler: 兜底方法
@SentinelResource(value = "hotKey",blockHandler = "dieHandler")
public String hotKey(@RequestParam(value = "p1",required = false)String p1,//required 请求地址的参数可加可不加
@RequestParam(value = "p2",required = false)String p2){
return "---hotKey---";
}
//兜底方法,需要携带相同的参数,并且需要加上参数BlockException
public String dieHandler(String p1, String p2, BlockException blockException){
return "---hotkey die---";
}
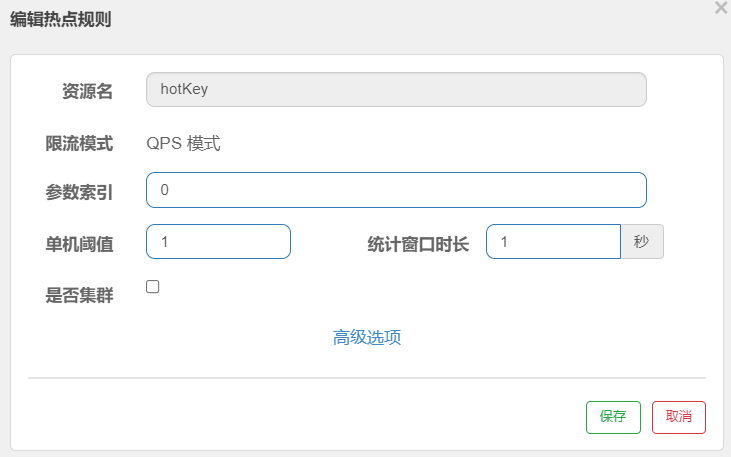
配置
资源名:SentinelResource 的value 不是请求地址
参数索引:代码形参中第几个参数进行热点监控,现在设定第0个,只有请求地址中携带了这个参数才会被限流
@SentinelResource 处理的仅仅是Sentinel控制台配置的违规情况,如果程序本身出现了错误,不会执行兜底方法
如果希望程序出现异常也执行兜底方法可以加参数fallback
参数例外项
我们期望p1参数当它是某个特殊值时,它的限流值和平时不一样,类似一些网站的VIP用户,普通用户无法访问,但是VIP用户可以。
第0个参数正常阈值为 1 ,但是当它携带参数值 5 时,阈值只变成了200
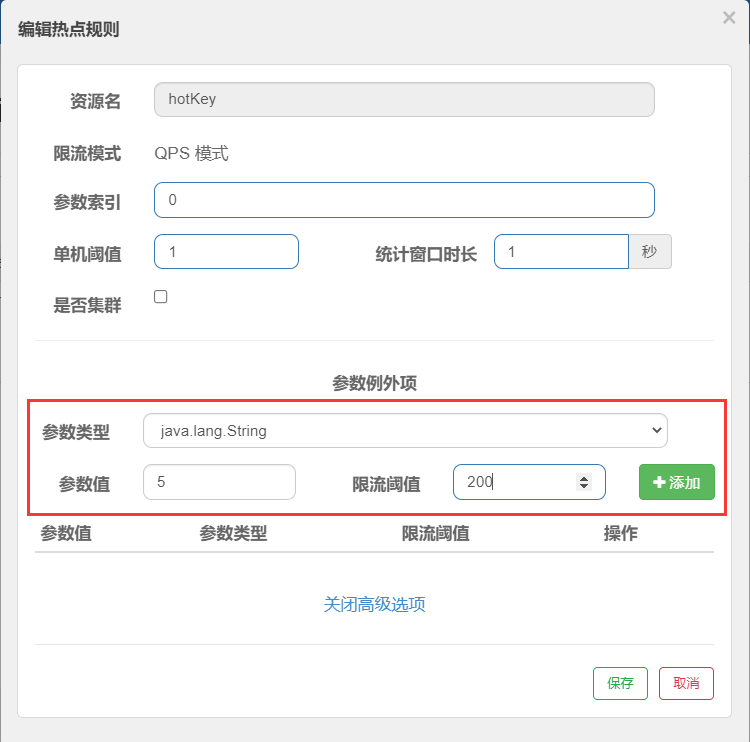
热点参数的注意点,参数必须是基本类型或者String
URL限流:
上面使用的是资源名(hotkey)限流,也可以使用URL 请求地址(/hotkey)进行限流。
设置限流后,如果 @SentinelResource 参数中不加 blockHandler 兜底方法,那么就会返回sentinel自带的限流结果
// 通过URL进行限流,没有写blockHandler 默认使用sentinel自带的限流结果
@GetMapping(value = "/byurl")
// @SentinelResource("byurl") // 可写可不写,因为是通过URL限流
public String byURL(){
return "通过URL限流";
}
全局兜底方法
跟Hystrix一样,为了防止出现大量的兜底方法,使得代码冗余肿胀,而采用的方式。
@GetMapping(value = "/globalA")
// 使用全局兜底方法,blockHandlerClass:使用哪个类,blockHandler:哪个方法
@SentinelResource(value = "globalA",
blockHandlerClass = CommonResource.class,
blockHandler = "globalA")
public CommonResult testGlobalA(){
return new CommonResult(200,"200用户自定义 流量正常",new Payment(20,"正常"));
}
兜底方法配置类
public class CommonResource {
// 全局兜底方法,需要是静态的,返回值要一致
public static CommonResult globalA (BlockException blockException){
return new CommonResult(404404,"A限流A,采用全局兜底方法");
}
// 一个A 一个B 可以任意选择使用哪个兜底方法
public static CommonResult globalB (BlockException blockException){
return new CommonResult(404404,"B限流B,采用全局兜底方法");
}
}
日后整合ribbon,sentinel,openfeign,fallback
想要达到的目的是,blockHandler管理配置的违规问题,fallback管理运行异常

两个同时都配,都会起作用,运行中,符合哪个异常标准就走哪个兜底方法
exceptionToIngNore:排除某个异常,不走兜底方法,正常报错
规则配置持久化
一旦我们重启应用,sentinel规则将消失,生产环境需要将配置规则进行持久化
将限流配置规则持久化进Nacos保存,只要刷新8401某个rest地址,sentinel控制台
的流控规则就能看到,只要Nacos里面的配置不删除,针对8401上sentinel上的流控规则持续有效
pom.xml 新增的依赖
<!--SpringCloud ailibaba sentinel-datasource-nacos -->
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-datasource-nacos</artifactId>
</dependency>
新增的yaml配置信息
在sentinel 下面的配置
sentinel:
...
datasource:
ds1:
nacos:
server-addr: localhost:8848
dataId: cloudalibaba-sentinel-service # nacos新建配置的DataID
groupId: DEFAULT_GROUP
data-type: json
rule-type: flow
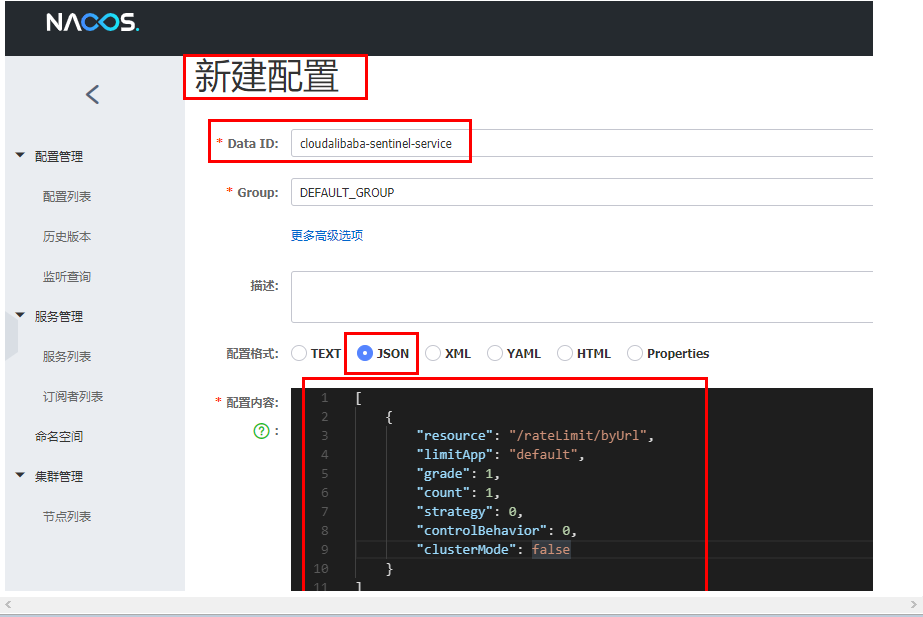
[
{
"resource": "/retaLimit/byUrl", # sentinel资源名 监控的Urlf
"limitApp": "default",
"grade": 1,
"count": 1,
"strategy": 0,
"controlBehavior": 0,
"clusterMode": false
}
]
****************内容解析*****************
resource:资源名称;
limitApp:来源应用;
grade:阈值类型,0表示线程数,1表示QPS;
count:单机阈值;
strategy:流控模式,0表示直接,1表示关联,2表示链路;
controlBehavior:流控效果,0表示快速失败,1表示Warm Up,2表示排队等待;
clusterMode:是否集群。
这样配置就可以让sentine读取到nacos里保存的服务配置信息
Seata
TC 事务协调者
- 事务协调器,维护全局事务的运行状态,负责协调并驱动全局事务的提交或回滚;
TM 事务管理器
- 控制全局事务的边界,负责开启一个全局事务,并最终发起全局提交或全局回滚的决议;
RM 资源管理器
- 控制分支事务,负责分支注册、状态汇报,并接收事务协调器的指令,驱动分支(本地)事务的提交和回滚
blockHandler 兜底方法,那么就会返回sentinel自带的限流结果
// 通过URL进行限流,没有写blockHandler 默认使用sentinel自带的限流结果
@GetMapping(value = "/byurl")
// @SentinelResource("byurl") // 可写可不写,因为是通过URL限流
public String byURL(){
return "通过URL限流";
}
全局兜底方法
跟Hystrix一样,为了防止出现大量的兜底方法,使得代码冗余肿胀,而采用的方式。
@GetMapping(value = "/globalA")
// 使用全局兜底方法,blockHandlerClass:使用哪个类,blockHandler:哪个方法
@SentinelResource(value = "globalA",
blockHandlerClass = CommonResource.class,
blockHandler = "globalA")
public CommonResult testGlobalA(){
return new CommonResult(200,"200用户自定义 流量正常",new Payment(20,"正常"));
}
兜底方法配置类
public class CommonResource {
// 全局兜底方法,需要是静态的,返回值要一致
public static CommonResult globalA (BlockException blockException){
return new CommonResult(404404,"A限流A,采用全局兜底方法");
}
// 一个A 一个B 可以任意选择使用哪个兜底方法
public static CommonResult globalB (BlockException blockException){
return new CommonResult(404404,"B限流B,采用全局兜底方法");
}
}
日后整合ribbon,sentinel,openfeign,fallback
想要达到的目的是,blockHandler管理配置的违规问题,fallback管理运行异常
[外链图片转存中…(img-P0naaSh5-1646986384132)]
两个同时都配,都会起作用,运行中,符合哪个异常标准就走哪个兜底方法
exceptionToIngNore:排除某个异常,不走兜底方法,正常报错
规则配置持久化
一旦我们重启应用,sentinel规则将消失,生产环境需要将配置规则进行持久化
将限流配置规则持久化进Nacos保存,只要刷新8401某个rest地址,sentinel控制台
的流控规则就能看到,只要Nacos里面的配置不删除,针对8401上sentinel上的流控规则持续有效
pom.xml 新增的依赖
<!--SpringCloud ailibaba sentinel-datasource-nacos -->
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-datasource-nacos</artifactId>
</dependency>
新增的yaml配置信息
在sentinel 下面的配置
sentinel:
...
datasource:
ds1:
nacos:
server-addr: localhost:8848
dataId: cloudalibaba-sentinel-service # nacos新建配置的DataID
groupId: DEFAULT_GROUP
data-type: json
rule-type: flow
[外链图片转存中…(img-cREFq3WT-1646986384136)]
[
{
"resource": "/retaLimit/byUrl", # sentinel资源名 监控的Urlf
"limitApp": "default",
"grade": 1,
"count": 1,
"strategy": 0,
"controlBehavior": 0,
"clusterMode": false
}
]
****************内容解析*****************
resource:资源名称;
limitApp:来源应用;
grade:阈值类型,0表示线程数,1表示QPS;
count:单机阈值;
strategy:流控模式,0表示直接,1表示关联,2表示链路;
controlBehavior:流控效果,0表示快速失败,1表示Warm Up,2表示排队等待;
clusterMode:是否集群。
这样配置就可以让sentine读取到nacos里保存的服务配置信息
Seata
TC 事务协调者
- 事务协调器,维护全局事务的运行状态,负责协调并驱动全局事务的提交或回滚;
TM 事务管理器
- 控制全局事务的边界,负责开启一个全局事务,并最终发起全局提交或全局回滚的决议;
RM 资源管理器
- 控制分支事务,负责分支注册、状态汇报,并接收事务协调器的指令,驱动分支(本地)事务的提交和回滚