1.GFS 的主要需求
在学习 GFS 的原理前,首先我们应当了解 GFS 在设计时所面对的需求场景。简单概括,GFS 的设计主要基于以下几个需求:
- 节点失效是常态。系统会构建在大量的普通机器上,这使得节点失效的可能性很高。因此,GFS 必须能有较高的容错性、能够持续地监控自身的状态,同时还要能够顺畅地从节点失效中快速恢复
- 存储内容以大文件为主。系统需要存储的内容在通常情况下由数量不多的大文件构成,每个文件通常有几百 MB 甚至是几 GB 的大小;系统应当支持小文件,但不需要为其做出优化
- 主要负载为大容量连续读、小容量随机读以及追加式的连续写
- 系统应当支持高效且原子的文件追加操作,源于在 Google 的情境中,这些文件多用于生产者-消费者模式或是多路归并
- 当需要做出取舍时,系统应选择高数据吞吐量而不是低延时
2.GFS架构
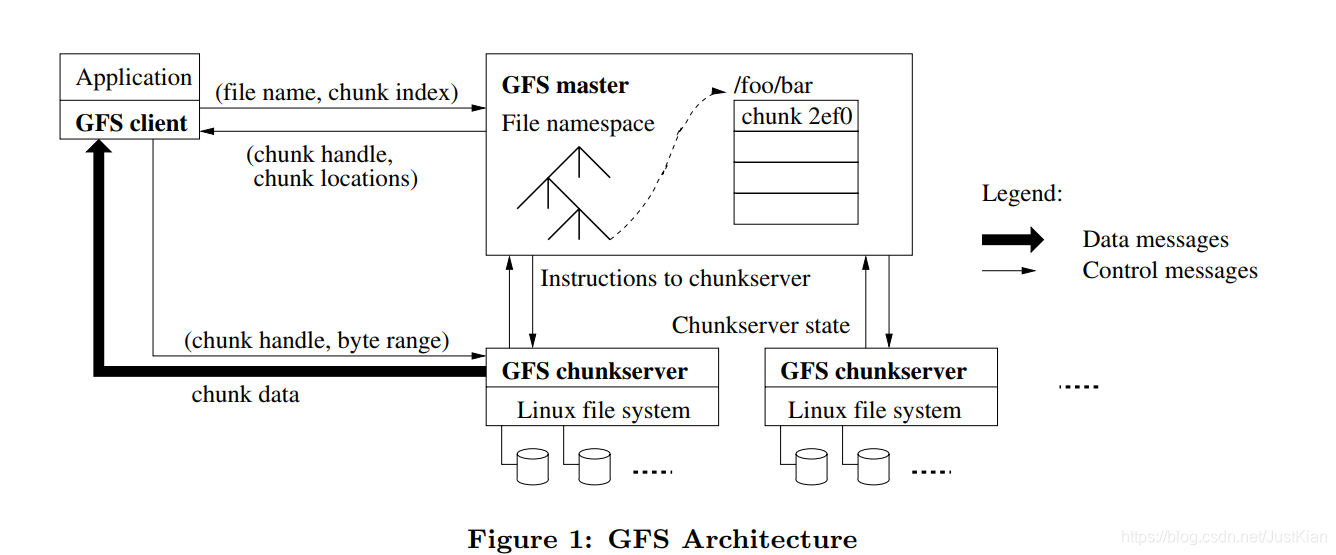
总体架构:GFS仍是按照目录层次结构来组织文件数据的,从上图可知,GFS由一个master和多个chunksevers组成,每个chunksever都对应一个linux文件系统,实际上所有的数据最终都是分散存储在各个Linux文件系统中。
客户端(GFS client)——以库的形式提供的,提供的就是对外要用的接口
主服务器(GFS master)——单点,存储文件信息,目录信息,文件服务器信息,那个文件存在哪些文件服务器上等元数据
存储服务器(GFS chunk-server)——集群,存储文件文件分块:在GFS中文件都是被划分成固定大小的块进行管理存储的(正好对应MapReduce中的文件划分),每块有一个64位标识符(chunk handle),它是在 chunk 被创建时由 master 分配的,每一个 chunk 会有3个备份,分别在不同的机器上。我们知道在OS中,文件系统也有块的概念(即block),即代表一次能够读取的最小单位。同理,对于GFS而言,如果块大小设置得太小如几KB,此时存储一个GB级的文件都会造成占用10^6个块,那GFS对于这一个文件而言,需要管理10^6个块(会对应生成并管理10^6个handle),这无疑代价是昂贵的。这个设计是和吞吐量有很大关系的。
Master 存储所有的 metadata,包括命名空间(namespace)、访问控制信息(access control)、文件与 chunk 的映射关系(mapping)以及 chunk 的存储位置。每一个chunk都是由一个chunk handle来标识和管理,和改文件块的所有交互都是通过与其对应的handle完成的,所以master必须要存储一些元信息,比如chunk handle等。
Master 管理 chunk 租约(lease)、chunk 迁移(如果 chunkserver 挂掉)、chunkserver 之间的通信(heartbeat,它也会向 chunkserver传达master 的命令,chunkserver 通过 heartbeat 向 master 报告自己的状态)
Client 会和 master 以及 chunkserver 进行交互,client向 master 请求 metadata,然后向 chunkserver 进行读写操作
client 与 chunkserver 都不会缓存文件数据,为的是防止数据出现不一致的状况。但是 client 会缓存 metadata 的信息(但是会出现一个问题,如果 metadata 过期怎么办呢?GFS 给出了自己的解决方案,也就是租约 lease)
根据上图,我们仔细来理一下,一个大型数据在GFS中的存储过程:
- 首先是客户端通过GFS提供的API向master发起读写请求
- 然后master通过客户端的请求参数(文件名,块偏移(即从该文件的第几个块开始))返回对应的chunk handle和其所在的chunk sever位置
- 然后客户端可以通过服务端返回的handle和location直接和具体某个chunk sever进行读写交互
- 另外,master得通过心跳检测(定时轮询)获取每一个chunk sever的状态
3.设计要点
单点master
GFS 为了简化设计,在整个系统中只有一个 master 进行管理。Master 不提供读写操作,它只会告诉 client,它所请求操作的文件在哪个 chunkserver 上,然后 client 会根据 master 提供的信息,与对应的 chunkserver 进行通信。
其更为重要的意义在于单点master意味着有一个节点可以避免分布式锁,可以拥有全局视野,能够统一调度与监控,系统整体复杂度降低很多。锁可以降级成本地锁,分布式调度可以降级为单点调度。
更具体的:
(1) master拥有所有文件目录结构,要操作某个文件,必须获得相应的锁;
一般情况下,不会对同一个网页进行并发写操作,应用场景决定锁冲突其实不大;
(2) master拥有全局视野,能够避免死锁;
(3) master知道chunk-server的信息,能够很容易的做chunk-server监控,负载均衡;
(4) master知道所有文件的副本分布信息,能够很容易的做文件大小的负载均衡;负载均衡分为请求量的均衡,文件存储的容量均衡。Chunk 大小
GFS 中将 chunk 的大小定为 64MB,它比一般的文件系统的块大小要大。
优点:(上面已经叙述过)
(1)减少 client 与 master 的交互
(2)client 可以在一个块上执行更多的操作,通过 TCP 长连接减少网络压力
(3)减小 metadata 的大小
缺点:
(1)一个 chunk 可以存更多的小文件了,这样的话如果有一个块存储了许多小文件,client 和它进行操作的几率大大提高,这个 chunk 的压力会很大,会形成热点块(然而在实际中,这个问题影响并不大)
(2)在批处理系统中存在很大问题(如果在一个 chunk 上有一个可执行文件,同时有许多 client 都要请求执行这个文件,它的压力会很大。解决方案是把该文件在不同的 chunkserver 上多添加几个备份,更长久的方案是应该允许 client 去读取其他 client 的文件)Metadata
把 metadata 存储于内存有许多优点,查看 metadata 信息时很方便,速度快,有利于 chunk 的垃圾回收(garbage collection)、再备份(re-replication)以及 chunk 迁移(为的是负载均衡)。
GFS 的 metadata 存储着 3 种类型的信息:
(1)文件名以及 chunk 的名称
(2)文件与 chunk 的映射关系
(3)各个备份(replicas)的位置
Metadata 通常存储于内存中,那么我们就会疑问这不会造成数据丢失吗?于是GFS也将前两种信息存于磁盘中,它们会作为操作记录(operation log)备份的一部分存储于磁盘,备份于远程机器。而 operation log作为唯一的持久化数据,它是至关重要的,如果master crash,那只能靠operation log来恢复数据。
我们思考一下,为什么不需要保存chunk的位置信息,因为master可以通过定期的 heartbeat 进行更新,得知每一个chunksever上的chunk信息(chunkserver 上有一个 final word,它表示了哪个 chunk 在它的磁盘上,哪个 chunk 不在)。而如果持久化保存其位置信息,每次chunkserver上的chunk位置发生变动都得同步到master上,这无疑造成了master的不必要的负担。☆☆☆一致性模型
这里有篇博文写的蛮好的:https://blog.csdn.net/qiaojialin/article/details/71574203
首先解释一下和一致性有关的几个基本概念:
(1)一致性(consistent):所有客户端无论读取哪个 Replica 都会读取到相同的内容,那这部分文件就是一致的;相反,如果客户端读取到的内容不同,那这部分文件就是不一致的。
(2)确定性(Defined):在某种程度上讲,这个是比一致性更高的要求。Defined 的意思是知道这个文件是谁写的(那么谁知道呢?肯定是自己知道,其他客户端看不到文件的创建者)。也就是当前客户端在写完之后,再读数据,肯定能读到刚才自己写的。——可能有点不好理解,想想一个MySQL集群的多个MySQL实例,是如何保证多个实例的数据一致性的。bingo!确定一个主实例,串行化所有写操作,然后在其他实例重放相同的操作序列,以保证多个实例数据的一致性。master也是同样的方法。我们举个栗子:两个并发写请求A、B操作同一个文件的同一个位置,此时master得到了之后,会随机对这两个指令进行排序,自然后面执行的指令会覆盖前一个指令的操作。而对于A、B而言,他们都无法预料到最终是谁写成功了,所以这时就为undefined,但是这种情况确是满足一致性的(保证最终一致性)。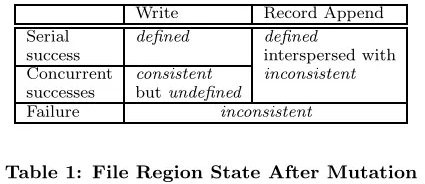
讲到这里,不得不提到,GFS的两种写模式:随机写,追加写(推荐)。回想一下操作系统的读写方式,包括随机读写,和顺序读写两种:(1) 顺序读写(追加写)——文件指针只能从头移动到尾,耗时短(2)随机读写——文件指针可以随意移动,根据需要,耗时长(需要寻道时间和旋转延迟)
从上面的图片我们可看出,追加写的方式始终保证确定性(穿插了不一致的确定性,后面会谈到),而随机写方式,并发的情况下会造成不确定,但是保证最终一致性,而如果操作失败,则会导致不一致。
具体可以分如下几种情况具体分析:(1)并发随机写(2)并发追加写(3)顺序随机写(4)顺序追加写
仔细思考便可以回答这个问题:为什么原子记录追加操作是至少一次(At Least Once),而不是确定一次(Exactly Once)?
答:我们知道追加写始终保持确定性,但是由于至少一次则会导致中间过程可能会包含一些不一致的冗余数据(填充或者重复的),引用一段解释:两个客户端分别向同一个文件追加数据a和b
client1:追加a
client2:追加b
最后一个文件块的primary接收到追加操作后进行序列化
primary:b,a
然后执行,b失败了一次,于是client2再发送一次追b。primary再追加一次。
(1)primary:原始数据,off1:b,off2:a,off3:b
(2)second1:原始数据,off1:b,off2:a,off3:b
(3)second2:原始数据,off1: ,off2:a,off3:b
client1收到GFS返回的off2(表示a追加到了文件的off2位置),client2收到off3
也满足off2和off3是 defined ,off1是 inconsistent ,所以总体来说是 defined interspersed with inconsistent
可以看到,不管有没有并发,追加数据都不能保证数据全部 defined,只能保证有 defined ,但是可能会与 inconsistent 相互交叉。由于primary最终只会返回最终的数据偏移位置给client,所以如果client进行了失败重试,则会读取到冗余数据,不过对于client而言,这个问题很好解决,即增设一个检验和字段,即可去除冗余的数据。但是如果想要确实保证确定一次的操作,那Primary 必须执行回滚操作,而回滚操作意味着Primary 得保存此次操作的起始数据偏移状态,而这些信息也需要复制到其他服务器上,所以还得保证回滚操作的一致性。这无疑给系统带来了极大的不便。相反交给client自己去处理,则是更为容易的。