链表通过指针将一组零碎的内存块串联起来
1.单链表

插入,删除:O(1)
不支持随机访问
2.循环链表

3.双向链表
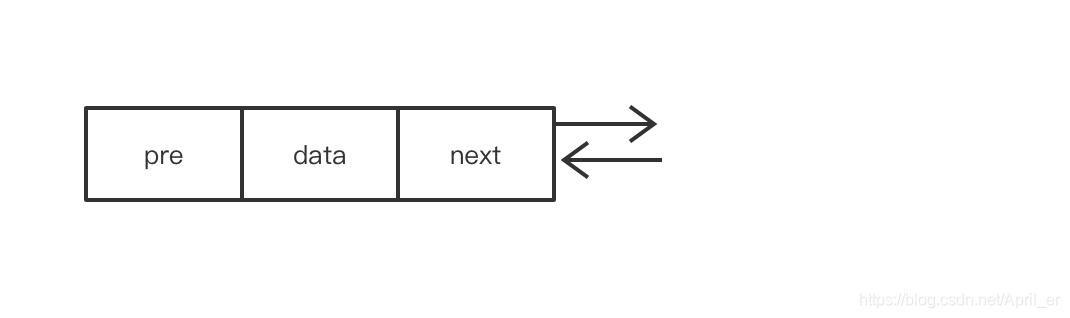
空间换时间
找前驱结点O(1)
4.时间复杂度比较
- 删除结点中“值等于某定值”的结点:
查找:O(n),删除O(1) - 删除结点中指定结点指向的结点
单向:O(n) 找前驱
双向:O(1)
5.数组vs链表
| 操作 | 数组 | 链表 |
|---|---|---|
| 插入/删除 | O(n) | O(1) |
| 随机访问 | O(1) | O(n) |
- 数组,连续存储空间,CPU缓存机制预读数据效率高;链表CPU缓存不友好
- 数据大小固定:声明过大五连续存储空间;过小频繁扩容,申请内容和数据迁移
内存使用苛刻时选择数组
6.应用:LRU缓存淘汰算法
有序单链表
访问新数据时:
- 该数据已缓存在链表中
遍历得到对应结点,置于链表头部 - 未缓存
- 缓存未满,插入头部
- 缓存已满,删除尾结点,插入头部
7.做题技巧
谨记!!
1.指针/引用
存储所指对象的内存地址
1.某个变量赋值给指针,实际是将这个变量的地址赋值给指针
2.指针中存储了变量的内存地址,指向这个变量(通过指针找到这个变量)
2. 警惕指针丢失和内存泄漏
如a,b之间插入x
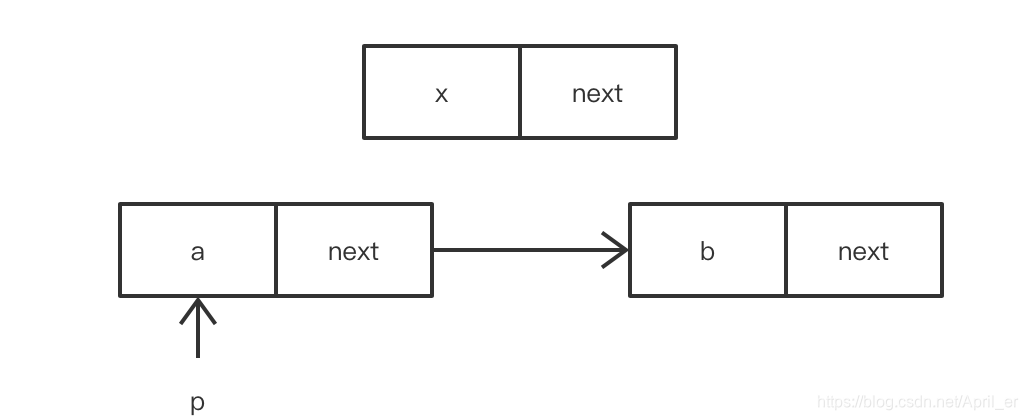
指针丢失:
p->next = x;
x ->next = p->next;
删除结点
对于c语言来说,要手动释放内存空间
JVM可自动管理内存
3.利用哨兵简化实现难度
// 在数组a中,查找key,返回key所在的位置
int find(char* a, int n, char key) {
if(a == null || n <= 0) {
return -1;
}
int i = 0;
// 这里有两个比较操作:i<n和a[i]==key.
while (i < n) {
if (a[i] == key) {
return i;
}
++i;
}
return -1;
}
// 在数组a中,查找key,返回key所在的位置
// 其中,n表示数组a的长度
// a = {4, 2, 3, 5, 9, 6} n=6 key = 7
int find(char* a, int n, char key) {
if(a == null || n <= 0) {
return -1;
}
// 这里因为要将a[n-1]的值替换成key,所以要特殊处理这个值
if (a[n-1] == key) {
return n-1;
}
// 把a[n-1]的值临时保存在变量tmp中,以便之后恢复。tmp=6。
// 之所以这样做的目的是:希望find()代码不要改变a数组中的内容
char tmp = a[n-1];
// 把key的值放到a[n-1]中,此时a = {4, 2, 3, 5, 9, 7}
a[n-1] = key;
int i = 0;
// while 循环比起代码一,少了i<n这个比较操作
//!!!!!!!!!!!!!!!!!!!!!!!增加哨兵a[n-1]=key,少了一个比较语句,减少n次执行
while (a[i] != key) {
++i;
}
// 恢复a[n-1]原来的值,此时a= {4, 2, 3, 5, 9, 6}
a[n-1] = tmp;
if (i == n-1) {
// 如果i == n-1说明,在0...n-2之间都没有key,所以返回-1
return -1;
} else {
// 否则,返回i,就是等于key值的元素的下标
return i;
}
}
4.留意边界条件!!!重要
1. 链表为空
2. 链表只包含一个结点
3. 链表只包含两个结点
4. 代码逻辑处理头尾结点
版权声明:本文为April_er原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。