目录
1. 图基础
图是一种数据结构,它对一组对象(节点)及其关系(边)进行建模。图对于机器学习来说,是一种独特的非欧式数据结构(对于数据中的某个点,难以定义出其邻居节点出来,或者是不同节点的邻居节点的数量是不同的),图分析侧重于节点分类,链路预测和聚类。图神经网络(GNN)是在图域上运行的基于深度学习的方法。对于解决图方面的问题,需要利用到本地连接、共享权重和多层的使用。图表示学习,利用低维向量表示图结点,边和子图。
2. 图构建
2.1 找到图结构
我们应该找到应用中的图结构。通常有结构场景和非结构场景。在结构场景中,图结构是明确的,例如分子结构,知识图谱。在非结构场景中,图结构是隐式的,因此我们必须首先从任务中构建图,例如为文本构建全连接的“单词”图或为图像构建场景图。
2.2 图类型和范围
在找到图结构后,我们必须找到图的类型和它的范围。复杂类型的图可以提供有关节点及边的更多信息。图的类型包括①有向图和无向图,有向图中的边都是由一个结点指向另一个节点,无向图中的每条边也可以看成两条有向边;②同构图和异构图,同构图中,节点的种类只有一种,一个node和另一个node的连接关系只有一种,异构图是包含不同类型节点和边的图;③动态和静态图,当输入特征和图的拓扑结构随时间变化时,该图被视为一个动态图,在动态图中应该考虑时间信息。这些类型可以组合,譬如可以处理动态有向异构图。当设备无法存储和处理图的邻接矩阵或图拉普拉斯算子时,我们讲图视为大规模图,考虑一些采样方法。
2.3 设计损失函数
对于图学习任务,通常有三种。节点级任务侧重于节点,包括节点分类,节点回归,节点聚类等。节点分类试图将节点分为若干类,节点回归预测节点的连续值,节点聚类旨在将将节点划分为几个不相交的组,其中相似节点在一组。边级任务是边分类和链路预测,这需要模型对边类型进行分类或者预测给定的两个节点间是否存在链路。图级任务包括图分类,图回归和图匹配,所有的这些任务都需要模型来学习图表示。通过任务类型和训练设置,我们可以为任务设计特定的损失函数。例如,对于节点级半监督分类任务,可以将交叉熵损失用于训练集中的标记节点。
2.4 使用计算块来建立模型
传播模块用于在节点之间传播信息,以便聚合信息能够捕获特征和拓扑信息。在传播模块中,卷积算子和循环算子通常用于聚合来自邻居的信息,而跳跃连接操作用于从节点的历史表示中收集信息并缓解过度平滑问题。当图很大时,通常需要采样模块,采样模块通常和传播模块一起使用。当我们需要高级子图或图的表示时,需要池化模块来从节点中提取信息。
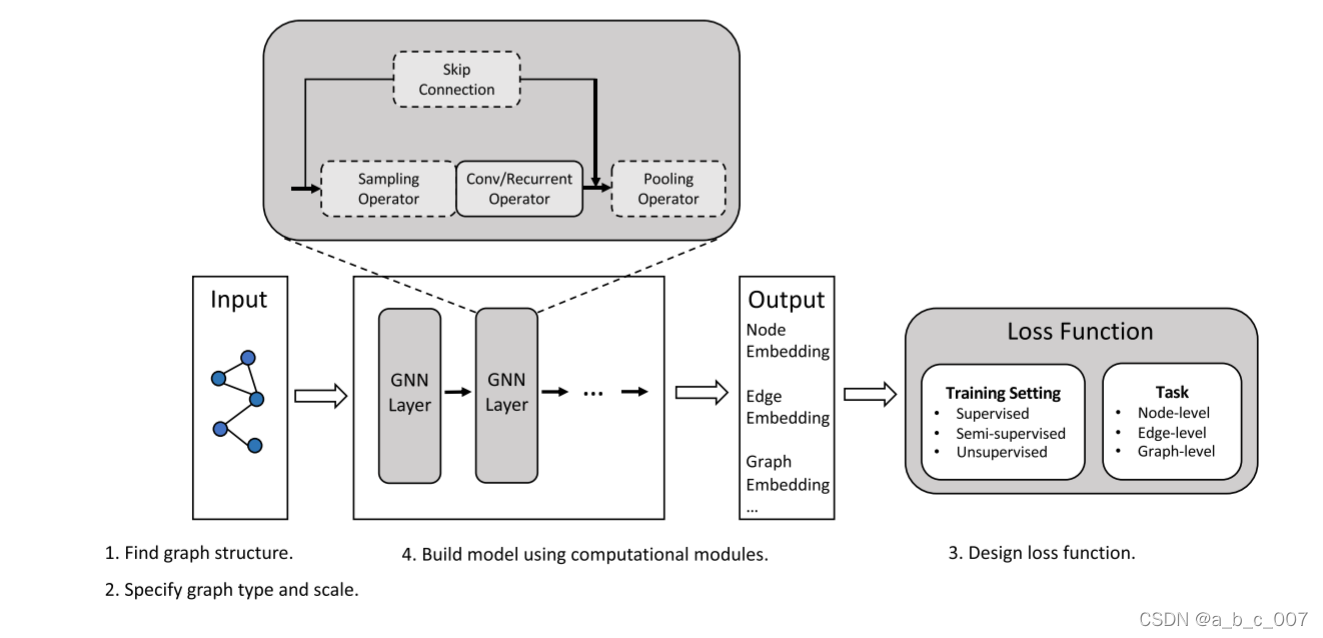
3 计算模块的实例化
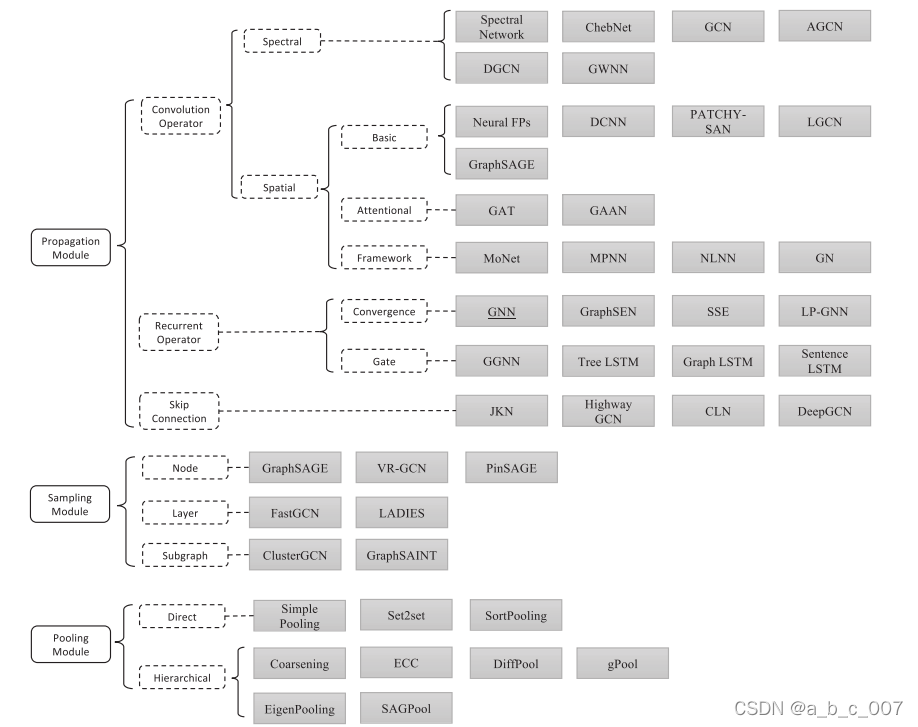
3.1 传播模块-卷积算子
卷积算子是 GNN 模型中最常用的传播算子。 卷积算子的主要思想是将卷积从其他域推广到图域。 在这个方向上的进展通常被归类为光谱方法和空间方法。
3.1.1. 频谱法
在频谱法中,图信号x首先通过图傅里叶变换F变换到谱域,然后进行卷积运算。 卷积之后,使用逆图傅里叶变换 F 1 将结果信号变换回来。Spectral Network;ChebNet;GCN;AGCN;DGCN;GWNN。
3.1.2 基本空间方法
空间方法是在图拓扑情况下直接在图上定义卷积。空间方法的主要挑战是定义不同大小邻域的卷积运算,并保持CNN的局部不变性。Neural FPs;DCNN.;PATCHY-SAN;LGCN;GraphSAG。
3.1.3.基于注意力的空间方法
注意机制已成功用于许多基于序列的任务,例如机器翻译、机器阅读等。还有几个模型试图在图上泛化注意力算子。与我们之前提到的算子相比,基于注意力的算子为邻居分配不同的权重,从而可以减轻噪声并取得更好的效果。GAT.;GaAN.。
3.1.4 空间方法的一般框架
除了空间方法的不同变体之外,还提出了几个通用框架,旨在将不同的模型集成到一个框架中。混合模型网络(MoNet)是一个试图统一非欧几里德域模型的空间框架,包括用于流形(流形学习的观点是认为,我们所能观察到的数据实际上是由一个低维流形映射到高维空间上的,即这些数据所在的空间是“嵌入在高维空间的低维流形。”。由于数据内部特征的限制,一些高维中的数据会产生维度上的冗余,实际上只需要比较低的维度就能唯一地表示。在极坐标的表示方法下,圆心在原点的圆,只需要一个参数就能确定:半径。当你连续改变半径的大小,就能产生连续不断的“能被转换成二维坐标表示”的圆。所以说,实际上二维空间中的圆就是一个一维流形。)的CNN和GNN(including CNNs for manifold and GNNs)。GCNN,ACNN,DCNN可以表述为MoNet的特殊实例。在MoNet中,流形上的每个点或图上的每个顶点,都用v表示,都被视为伪坐标系的原点。邻居 u 与伪坐标 u(v,u) 相关联。给定两个函数 f,g 定义在图的顶点(或流形上的点)上,MoNet 中的卷积算子定义为:
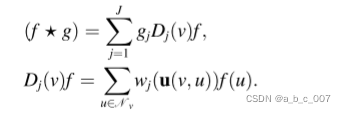
消息传递神经网络 (MPNN) 提取了几个经典模型中的一般特征。该模型包含两个阶段: 消息传递阶段和读出阶段。非局部神经网络(NLNN)推广和扩展了计算机视觉中经典的非局部平均运算。非局部操作将某个位置的隐藏状态计算为所有可能位置的特征的加权和。 潜在位置可以是空间、时间或时空。图网络(GN)通过学习节点级、边缘级和图级表示,与其他框架相比,是一个更通用的框架。
3.2. 传播模块 - 循环算子
循环方法是该研究领域的先驱。循环算子和卷积算子的主要区别在于卷积算子中的层使用不同的权重,而循环算子中的层共享相同的权重。
3.2.1.基于收敛的方法
在图中,每个节点自然地由其特征和相关节点定义。GNN的目标是学习一个嵌入hv的状态,该状态包含每个节点的邻域及其本身的信息。状态嵌入 hv 是节点 v 的 s 维向量,可用于生成输出 ov,例如预测节点标签的分布。GNN具有一定的局限性:①GNN 要求 f 是一个收缩图,这限制了模型的能力。并且迭代地更新节点的隐藏状态到固定点是低效的。②如果我们专注于节点的表示而不是图,则不适合使用固定点,因为固定点中的表示分布在值上会更加平滑,并且对于区分每个节点的信息较少。图回显状态网络(GraphESN)在图上概括了回声状态网络(echo state network)(ESN)。它使用固定的压缩编码功能,并且仅训练读出功能。为了提高 GNN 的效率,还提出了随机稳态嵌入 (SSE)。 SSE 提出了一个包含两个步骤的学习框架。 每个节点的嵌入由参数化算子在更新步骤中更新,并将这些嵌入投影到稳态约束空间以满足稳态条件。其以随机和异步的方式周期性更新节点的隐状态,它随机采样一批节点用于状态更新,随机采样一批节点用于梯度计算。拉格朗日传播 GNN (LP-GNN)将学习任务形式化为拉格朗日框架中的约束优化问题,避免了对不动点的迭代计算。收敛过程由约束满足机制隐式表达。
3.2.2 基于门的方法
有几项工作试图在传播步骤中使用GRU或LSTM等门机制,以减少GNN中的计算限制,并改善信息在图形结构中的长期传播。它们在不保证收敛的情况下运行固定数量的训练步骤。门控图神经网络 (GGNN)被提出来释放GNN的限制。它将函数f的要求释放为收缩图,并在传播步骤中使用门递归单位 (GRU)。它还使用时间反向传播 (BPTT) 来计算梯度。节点 v 首先聚合来自其邻居的消息。然后类似 GRU 的更新函数结合来自其他节点和前一个时间步的信息来更新每个节点的隐藏状态。 h收集节点 v 的邻域信息,而 z 和 r 是更新和重置门。
3.3.传播模块 - 跳跃连接
许多应用程序展开或堆叠图神经网络层旨在获得更好的结果,因为更多的层(即 k 层)使每个节点从 k 跳之外的邻居聚合更多的信息。然而,在许多实验中已经观察到,更深的模型无法提高性能,更深的模型甚至可能表现更差。这主要是因为更多的层也可以传播来自数量呈指数增长的扩展邻域成员的噪声信息。这也会导致过度平滑问题,因为当模型更深入时,在聚合操作之后,节点往往具有相似的表示。而对于较为边缘的节点,即使拓展其感受域,它的邻居还是很少。因此,许多方法试图添加“跳跃连接”,以使GNN模型更深入。在本小节中,我们将介绍三种跳跃连接的实例。Highway GCN,使用了层级的门控,门控可以使网络从新的和旧的隐藏状态中进行选择。因此,将早期隐藏状态传播到最终状态也是有可能的。在实验中模型性能在四层达到峰值,继续添加层带来的变化不大。徐等人 研究邻域聚合方案的特性和局限性。他们提出了可以学习自适应和结构感知表示的跳转知识网络(JKN)。 JKN 从最后一层的每个节点的所有中间表示(“跳转”到最后一层)中选择,这使得模型根据需要调整每个节点的有效邻域大小。DeepGCNs. Li等人 借鉴了ResNet和DenseNet(该网络在前馈时将每一层都与其他的任一层进行了连接。传统的 L层卷积网络有 L个连接——每一层与它的前一层和后一层相连——我们的网络有L*(L+1) /2个连接。每一层都将之前的所有层的特征图作为输入,而它自己的特征图是之后所有层的输入。DenseNets有一些很不错的优点:有助于解决梯度消失问题,有利于特征传播,鼓励特征的重复利用,还可以减少参数量)的思想。Reggcn和DenseGCN是通过合并残差连接和密集连接来解决梯度消失和过度平滑的问题而提出的。DeepGCNs 的实验是在点云语义分割任务上进行的,使用 56 层模型取得了最好的结果。
3.4. 采样模块
GNN 模型从前一层的邻域中聚合每个节点的消息。 直观地说,如果我们回溯多个 GNN 层,支持邻居的大小将随着深度呈指数增长。 为了缓解这种“邻居爆炸”问题,一种有效且有效的方法是采样。 此外,当我们处理大图时,我们不能总是存储和处理每个节点的所有邻域信息,因此需要采样模块来进行传播。 在本节中,我们介绍三种图采样模块:节点采样、层采样和子图采样。
3.4.1 节点采样
减少相邻节点大小的直接方法是从每个节点的邻域中选择一个子集。GraphSAGE(Hamilton等人,2017a)对固定数量的邻居进行采样,确保每个节点的邻域大小为2到50。为了减少抽样方差,Chen等人(2018a)引入了一种基于控制变量的GCN随机逼近算法,将节点的历史激活作为控制变量。这种方法限制了1-跳邻域中的感受区域,并使用历史隐藏状态作为可承受的近似值。PinSage (Ying等人,2018a) 提出了基于重要性的抽样方法。通过模拟从目标节点开始的随机游走,该方法选择具有最高归一化访问计数的前T个节点。
3.4.2. 层采样
层采样不是为每个节点采样邻居,而是在每个层中保留一小组节点用于聚合以控制扩展因子。 FastGCN (Chen et al., 2018b) 直接对每一层的感受域进行采样。 它使用重要性抽样,其中重要节点更有可能被抽样。与上述固定采样方法相比,Huang 等人引入了一个参数化和可训练的采样器来执行以前一层为条件的逐层采样。此外,这种自适应采样器可以优化采样重要性并同时减少方差。 LADIES (Zou et al., 2019) 打算通过从节点的邻居联合中生成样本来缓解分层采样中的稀疏问题。
3.4.3 子图采样
一种根本不同的方法是采样多个子图并限制这些子图中的邻域搜索,而不是采样基于完整图的节点和边。ClusterGCN (Chiang等人,2019) 通过图聚类算法对子图进行采样,而GraphSAINT (Zeng等人,2020) 直接对节点或边进行采样以生成子图。
3.5 池化模块
在计算机视觉领域,卷积层之后通常是一个池化层以获得更多的一般特征。复杂大规模的图通常具有丰富的层次结构,对于节点级和图级分类任务具有重要意义。与这些池化层类似,很多工作都集中在在图上设计分层池化层。在本节中,我们将介绍两个池化模块: 直接池化模块和分层池化模块。
3.5.1 直接池化模块
直接池化模块直接从具有不同节点选择策略的节点学习图级表示。 这些模块在某些变体中也称为读出功能。Simple Node Pooling,几种模型使用了简单的节点池化方法。在这些模型中,节点方向的最大/均值/总和/注意操作被应用于节点特征,以获得全局图表示。 MPNN 使用 Set2set方法 (Vinyals et al., 2015a) 作为读取函数以获取图形表示。 Set2set 旨在处理无序集 T,并使用基于 LSTM 的方法在预定义的步数后生成顺序不变表示。SortPooling (Zhang et al., 2018e) 首先根据节点的结构角色对节点嵌入进行排序,然后将排序后的嵌入输入 CNN 以获得表示。
3.5.2.分层池化模块
前面提到的方法直接从节点学习图表示,它们没有研究图结构的层次属性。 接下来我们将讨论遵循分层池化模式并按层学习图表示的方法。Graph Coarsening,早期的方法通常基于图粗化算法(graph coarsening algorithms)。谱聚类算法是第一次使用,但由于特征分解步骤,它们效率低下。Graclus(Dhillon等人,2007)提供了一种更快的集群节点方式,并将其作为池模块应用。例如,ChebNet和MoNet使用Graclus合并节点对,并进一步添加其他节点,以确保池过程形成一个平衡的二叉树。边缘条件卷积 (ECC) (Simonovsky and Komodakis, 2017) 设计了具有递归下采样操作的池化模块。 下采样方法是基于拉普拉斯最大特征向量的符号将图分成两个分量。DiffPool。 gPool (Gao and Ji, 2019) 使用一个项目向量来学习每个节点的投影分数,并选择具有前 k 个分数的节点。与 DiffPool 相比,它在每一层都使用向量而不是矩阵,从而降低了存储复杂度。但是投影过程不考虑图结构。EigenPooling(Ma等人,2019a) 旨在共同使用节点特征和局部结构。它使用局部图傅立叶变换来提取子图信息,并且遭受图特征分解效率低下的困扰。SAGPool(Lee et al.,2019)也联合使用特征和拓扑来学习图表示。它使用基于自我注意的方法,具有合理的时间和空间复杂性。
4. 考虑图类型和范围(scale)的变体
在上面的部分中,我们假设图是最简单的格式。 然而,现实世界中的许多图都很复杂。 在本小节中,我们将介绍尝试解决复杂图类型挑战的方法。
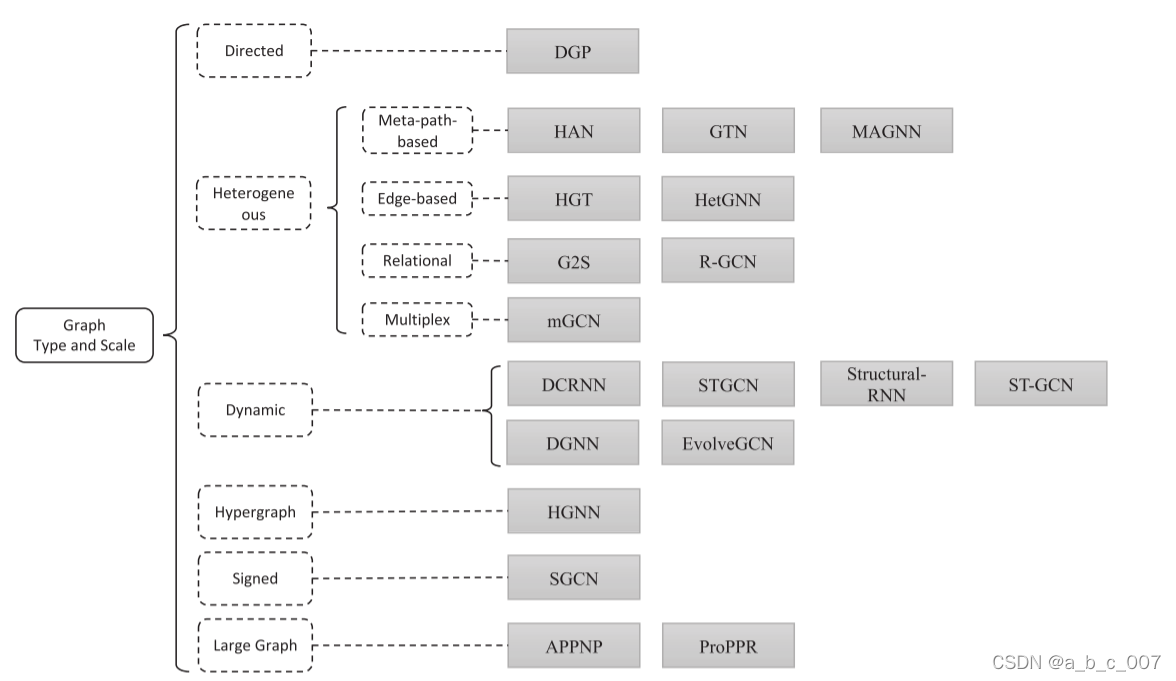
4.1 有向图
第一类是有向图。有向边通常比无向边包含更多信息。例如,在知识图中,头部实体是尾部实体的父类,边方向提供有关偏序的信息。我们不必简单地在卷积算子中采用非对称邻接矩阵,而是可以对边的正向和反向进行不同的建模。DGP(Kampffmeyer等人,2019年)使用两种权重矩阵Wp和Wc进行正向和反向卷积。
4.2. 异构图
图的第二种变体是异构图,其中节点和边是多类型或多模态的。
4.2.1 基于元路径的方法
这种图形类型的大多数方法都使用元路径的概念。元路径是一种路径方案,它确定路径的每个位置的节点类型,元路径的长度为L。在训练过程中,元路径被实例化为节点序列。通过连接元路径实例的两个端节点,元路径捕获可能不直接连接的两个节点的相似性。因此,可以将一个异构图简化为几个同质图,可以在其上应用图学习算法。在早期工作中,研究了基于元路径的相似性搜索 (Sun等人,2011)。最近,人们提出了更多利用元路径的GNN模型。HAN(Wang等人,2019a)首先对每个元路径下基于元路径的邻居使用图注意力,然后在所有元路径方案下对节点的输出嵌入使用语义注意来生成节点的最终表示。MAGNN(Fu等人,2020年)建议考虑元路径中的中间节点。它首先使用神经模块沿着元路径聚合信息,然后对与节点关联的不同元路径实例执行关注,最后对不同元路径方案执行关注。GTN (Yun et al., 2019) 提出了一种新颖的图变换器层,它在学习节点表示的同时识别未连接节点之间的新连接。学习到的新连接可以连接彼此相距若干跳但密切相关的节点,这些节点充当元路径。
4.2.2. 基于边缘的方法
还有一些工作不使用元路径。 这些工作通常在采样、聚合等方面对不同类型的邻居和边缘使用不同的函数。HetGNN (Zhang et al.,2019b) 通过在采样、特征编码和聚合步骤中不同地直接对待不同类型的邻居来解决这一挑战。HGT (Hu et al., 2020a) 将元关系定义为两个相邻节点的类型及其链接〈vi; eij; vj>。它将不同的注意力权重矩阵分配给不同的元关系,使模型能够考虑类型信息。
4.2.3. 关系图的方法
一些图的边缘可能包含比类型更多的信息,或者类型的数量可能太大,给应用基于元路径元关系的方法带来困难。我们将这种图称为关系图 (Schlichtkrull et al., 2018),为了处理关系图,G2S(Beck et al., 2018) 将原始图转换为二分图,其中原始边也成为节点并且一条原始边被分成两条新边,这意味着在边节点和开始/结束节点之间有两条新边。在这个转换之后,它使用一个门控图神经网络和一个循环神经网络将带有边缘信息的图转换成句子。GGNN的聚合函数以节点的隐藏表示和关系作为输入。作为另一种方法,R-GCN(Schlichtkrull等人,2018年)不需要转换原始图形格式。它为不同种类的边缘上的传播分配不同的权重矩阵。 然而,当关系的数量非常多时,模型中的参数数量就会爆炸式增长。 因此,它引入了两种正则化来减少建模关系量的参数数量:基分解和块对角分解。
4.2.4. 多重(multiplex)图的方法
在更复杂的场景中,图中的一对节点可以与多个不同类型的边相关联。 通过在不同类型的边下查看,图可以形成多层,其中每一层代表一种关系。因此,多重图也可以称为多视图图 (multi-dimensional graph)。例如,在YouTube中,两个用户之间可以存在三种不同的关系: 共享,订阅,评论。不假定边缘类型彼此独立,因此仅将图拆分为具有一种边缘类型的子图可能不是最佳解决方案。mGCN (Ma et al., 2019b) 为 GNN 的每一层中的节点引入了一般表示和特定维度的表示。特定维度的表示是使用不同的投影矩阵从一般表示中投影,然后聚合以形成下一层的一般表示。
4.3 动态图
图的另一种变体是动态图,其中的图结构,例如 边和节点的存在,随着时间的推移不断变化。 为了将图结构化数据与时间序列数据一起建模,DCRNN (Li et al., 2018b) 和 STGCN (Yu et al., 2018) 首先通过 GNN 收集空间信息,然后将输出输入到序列模型中,如 sequence- 序列模型或 RNN。不同的是,Structural-RNN (Jain et al., 2016) 和ST-GCN (Yan et al., 2018) 同时收集空间和时间信息。 他们使用时间连接扩展静态图结构,因此他们可以在扩展图上应用传统的 GNN。类似地,DGNN (Mannessi et al., 2020) 将来自 GCN 的每个节点的输出嵌入馈送到单独的 LSTM 中。 LSTM 的权重在每个节点之间共享。另一方面,EvolveGCN (Pareja et al., 2020) 认为,直接对节点表示的动态建模将阻碍模型在节点集不断变化的图上的性能。因此,它不是将节点特征作为 RNN 的输入,而是将 GCN 的权重输入 RNN 以捕获图交互的内在动态。最近,一篇综述 (Huang et al., 2020) 根据链接持续时间将动态网络分为几类,并根据其专业化将现有模型分为这些类别。 它还为动态图模型建立了一个通用框架,并将现有模型拟合到通用框架中。
4.4. 其他图类型
对于图的其他变体,例如超图和符号图,也有一些模型提出来解决挑战。
4.4.1 超图
超图可以用 G(V;E;We) 表示,其中一条边 e 连接两个或多个顶点,并分配权重 w。超图的邻接矩阵可以用一个 |V|x|E| 的矩阵 L 表示。
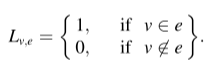
HGNN(Feng et al., 2019) 提出了超图卷积来处理节点之间的这些高阶交互。
4.4.2 符号图
符号图是具有符号边的图,即边可以是正的或负的。 SGCN (Derr et al., 2018) 不是简单地将负边视为缺失边或其他类型的边,而是利用平衡理论来捕捉正边和负边之间的相互作用。直观地说,平衡理论表明我朋友的朋友(正边)也是我的朋友,而我敌人的敌人(负边)也是我的朋友。因此,它为SGCN对正边缘和负边缘之间的相互作用进行建模提供了理论基础。
4.5.大图
正如我们在 3.4 节中提到的,采样算子通常用于处理大规模图。 除了采样技术之外,还有其他用于缩放问题的方法。Rossi等人 (2020) 提出了一种用于预先计算不同大小的图卷积滤波器以进行有效训练和推断的方法。基于PageRank的模型将多个GCN层压缩到一个单个传播层中,以减轻 “邻居爆炸” 问题,因此具有高度的可扩展性和效率。
5. 不同训练设置的变体
在本节中,我们将介绍不同训练设置的变体。对于监督设置和半监督设置,提供标签,以便易于为这些标记样本设计损失函数。对于无监督设置,没有标记样本,因此损失函数应取决于图形本身提供的信息,例如输入特征或图形拓扑。在本节中,我们主要介绍了无监督训练的变体,这些变体通常基于自动编码器或对比学习的思想。

5.1 图自动编码器
对于无监督图表示学习,有将自动编码器 (AE) 扩展到图的趋势。图自动编码器 (GAE) (Kipf and Welling, 2016) 首先使用 GCN 对图中的节点进行编码。然后它使用一个简单的解码器来重构邻接矩阵,并根据原始邻接矩阵和重构矩阵之间的相似性计算损失。Kipf 和 Welling (2016) 也以变分方式训练 GAE 模型,该模型被命名为变分图自动编码器(VGAE)。对抗正则化图自动编码器 (ARGA) (Pan等人,2018) 采用生成对抗网络 (gan) 来正则化基于GCN的图自动编码器,其可以学习更稳健的节点表示。
5.2 对比学习
除了图自动编码器之外,对比学习为无监督图表示学习铺平了另一种途径。深度图Infomax (DGI) (Velickovic等人,2019) 最大化节点表示与图表示之间的互信息。Infograph (Sun et al., 2020) 旨在通过图级表示与包括节点、边和三角形在内的不同尺度的子结构级表示之间的互信息最大化来学习图表示。 Multi-view(Hassani 和 Khasahmadi,2020)对比一阶邻接矩阵和图扩散的表示,在多个图学习任务上实现了最先进的性能。
6. GNN 的一个设计实例
在本节中,我们给出一个现有的 GNN 模型来说明设计过程。 以异构图预训练任务为例,我们使用 GPT-GNN (Hu et al., 2020b) 作为模型来说明设计过程。
1.找到图结构。本文主要研究了学术知识图和推荐系统的应用。在学术知识图中,图的结构是明确的。在推荐系统中,用户、条目和评论可以看作节点,它们之间的交互可以看作边,因此图结构也很容易构造。
2. 指定图类型和范围。这些任务侧重于异构图,因此应考虑节点和边的类型并将其合并到最终模型中。由于学术图和推荐图包含数百万个节点,因此模型应进一步考虑效率问题。总之,该模型应侧重于大规模异构图。
3.设计损失函数。由于 (Hu et al., 2020b) 中的下游任务都是节点级任务(例如学术图中的 Paper-Field 预测),因此模型应该在预训练步骤中学习节点表示。在预训练步骤中,没有可用的标记数据,因此自监督图生成任务旨在学习节点嵌入。在微调步骤中,根据每个任务的训练数据对模型进行微调,从而应用每个任务的监督损失。
4. 使用计算模块建立模型。 最后用计算模块建立模型。 对于传播模块,作者使用了我们之前提到的卷积算子 HGT (Hu et al., 2020a)。 HGT 将节点和边的类型合并到模型的传播步骤中,并且在架构中也添加了跳跃连接。 对于采样模块,应用了一种专门设计的采样方法 HGSampling(Hu et al., 2020a),它是 LADIES 的异构版本(Zou et al., 2019)。 由于模型专注于学习节点表示,因此不需要池化模块。 HGT 层堆叠多层以学习更好的节点嵌入。
7.GNN的分析
7.1 理论方面
在本节中,我们从各个角度总结了有关图神经网络的理论基础和解释的论文。
7.1.1 图信号处理
从频谱的角度来看,GCNs对频谱域中的输入特征执行卷积运算,理论上遵循图信号处理。存在一些从图信号处理分析 GNN 的工作。 李等人。(2018c)首先解决图神经网络中的图卷积实际上是拉普拉斯平滑(零概率问题:在计算事件的概率时,如果某个事件在观察样本库(训练集)中没有出现过,会导致该事件的概率结果是0。这是不合理的,不能因为一个事件没有观察到,就被认为该事件一定不可能发生(即该事件的概率为0)。拉普拉斯平滑(Laplacian smoothing) 是为了解决零概率的问题。对每个类别下所有划分的计数加1),它对特征矩阵进行平滑处理,使附近的节点具有相似的隐藏表示。 拉普拉斯平滑反映了附近节点应该相似的同质性假设。 拉普拉斯矩阵用作输入特征的低通滤波器。 SGC (Wu et al., 2019b) 进一步去除了权重矩阵和层之间的非线性,表明低通滤波器是 GNN 工作的原因。遵循低通滤波的思想,Zhang 等人。 (2019c),崔等人。 (2020),NT 和 Maehara(Nt 和 Maehara,2019),Chen 等人 (2020b) 分析不同的过滤器并提供新的见解。 为了实现对所有特征值的低通滤波,AGC (Zhang et al., 2019c) 根据频响函数设计了图滤波器I-1/2L。AGE (Cui et al., 2020) 进一步证明了使用 I-1/λmaxL 的滤波器可以获得更好的结果,其中 λmax 是拉普拉斯矩阵的最大特征值。尽管线性滤波器,GraphHeat (Xuet al.,2019a) 还是利用热核(heat kernels)获得更好的低通特性。NT和Maehara(NT和Maehara,2019)表示图卷积主要是输入特征的去噪过程,模型性能很大程度上依赖于特征矩阵中的噪声量。为了缓解过度平滑问题,Chen等 (2020b) 提出了测量节点表示的平滑度和GNN模型的过度平滑度的两个指标。作者得出结论,信噪比是过度平滑的关键因素。
7.1.2. 概括
GNN 的泛化能力最近也受到了关注。 斯卡塞利等人,(2018)证明了有限类别的 GNN 的 VC 维度(VC 维所表征的是模型的复杂程度,当模型越复杂的时候,vc维越大,泛化能力就越差;当模型越简单的时候,vc维越小)。 加格等人,(2020)基于神经网络的 Rademacher 边界进一步给出了更严格的泛化边界。Verma 和 Zhang (2019) 分析了具有不同卷积滤波器的单层 GNN 的稳定性和泛化特性。 作者得出结论,GNN 的稳定性取决于滤波器的最大特征值。 克尼亚泽夫等(2019)专注于 GNN 中注意力机制的泛化能力。 他们的结论表明,注意力有助于 GNN 泛化到更大和嘈杂的图。
7.1.3 表现力
关于 GNN 的表达能力,Xu 等人(2019b),莫里斯等人 (2019) 表明,GCN 和 GraphSAGE 的判别力不如 Weisfeiler-Leman (WL) 测试,这是一种图同构测试算法。徐等人(2019a)还为更具表现力的 GNN 提出了 GIN。超越 WL 测试,Barcel o 等人(2019 年)讨论 GNN 是否可用于FOC2(一阶逻辑的一个片段)。作者发现现有的 GNN 很难符合逻辑。为了学习图拓扑结构,Garg 等人(2020)证明局部依赖的 GNN 变体无法学习全局图属性,包括直径、最大/最小循环或图案。Loukas (2020) 和 Dehmamy 等人(2019) 认为,现有工作仅在 GNN 具有无限层和单元时才考虑表达性。他们的工作研究了具有有限深度和宽度的 GNN 的表示能力。 Oono 和 Suzuki (2020) 讨论了 GNN 在模型加深时的渐近行为,并将它们建模为动态系统。
7.1.4 不变性
由于图中没有节点顺序,因此gnn的输出嵌入应该是对输入特征的置换不变或等变。马龙等人。 (2019a)表征置换不变或等变线性层以构建不变的 GNN。马龙等人(2019b)进一步证明了可以通过高阶张量获得通用不变 GNN 的结果。 Keriven 和 Peyre (2019) 提供了另一种证明,并将这一结论扩展到等变情况。陈等人(2019)在排列不变性和图同构测试之间建立联系。为了证明它们的等价性,Chen 等人(2019) 利用 sigma-algebra 来描述 GNN 的表现力。
7.1.5 可迁移性
GNN 的一个确定性特征是参数化与图无关,这表明在性能保证的情况下跨图传输的能力(所谓的可迁移性)。Levie等人 (2019) 研究了光谱图滤波器的可传递性,表明这种滤波器能够在同一域中的图上进行迁移。Ruiz等人 (2020) 分析graphons上的GNN行为。Graphon是指图序列的极限,也可以看作是密集图的生成器。作者得出的结论是,gnn可以跨从具有不同大小的同一图确定性获得的图迁移。
7.1.6 标签效率
Gnn的 (半) 监督学习需要大量的标记数据才能达到令人满意的性能。从主动学习的角度研究了提高标签效率的方法,其中主动选择信息节点以由oracle标记以训练gnn。Cai等 (2017) 、Gao等 (2018b) 、Hu等 (2020c) 证明,通过选择诸如度大的节点和不确定节点的信息性节点,可以显著提高标记效率。
7.2.经验方面
除了理论分析,还需要对GNN进行实证研究,以便更好地进行比较和评估。这里我们包括几个GNN评估和基准的实证研究。
7.2.1. 评价
评估机器学习模型是研究中必不可少的一步。 多年来,人们对实验的可重复性和可复制性提出了担忧。 GNN 模型是否以及在多大程度上起作用? 模型的哪些部分对最终性能有贡献? 为了调查这些基本问题,迫切需要关于公平评估策略的研究。关于半监督节点分类任务,Shchur等人 (2018a) 探讨了GNN模型在相同的训练策略和超参数调谐下的表现。他们的工作得出的结论是,不同的数据集分裂导致模型的排名截然不同。此外,在适当的设置下,简单的模型可能胜过复杂的模型。Errica等人 (2020) 回顾了几种图分类模型,并指出它们的相对不正确。基于严格的评估,结构信息没有被充分利用来进行图分类。you等人(2020) 讨论了 GNN 模型的架构设计,例如层数和聚合函数。通过大量实验,这项工作为 GNN 指定各种任务提供了全面的指导方针。
7.2.2.基准
ImageNet 等高质量和大规模的基准数据集在机器学习研究中具有重要意义。 然而,在图学习中,广泛采用的基准是有问题的。例如,大多数节点分类数据集仅包含 3000 到 20,000 个节点,与现实世界的图相比,这些节点很小。 此外,跨研究的实验方案不统一,这对文献是有害的。 为了缓解这个问题,Dwivedi 等人(2020),胡等人 (2020d) 为图学习提供可扩展且可靠的基准。 Dwivedi 等人 (2020) 在多个领域和任务中构建中等规模的基准数据集,而 OGB (Hu et al., 2020d) 提供大规模的数据集。 此外,这两项工作都评估了当前的 GNN 模型并提供了排行榜以供进一步比较。
8. 应用
图神经网络已在监督,半监督,无监督和强化学习设置的广泛领域中进行了探索。图神经网络已在监督,半监督,无监督和强化学习设置的广泛领域中进行了探索。在本节中,我们通常将应用程序分为两种场景:(1)数据具有显式关系结构的结构场景。一方面,这些场景来自科学研究,例如图挖掘、物理系统建模和化学系统建模。另一方面,它们源于知识图谱、交通网络和推荐系统等工业应用。(2) 关系结构隐含或不存在的非结构性场景。 这些场景通常包括图像(计算机视觉)和文本(自然语言处理),这是人工智能研究中发展最活跃的两个分支。
8.1 结构场景
在接下来的小节中,我们将介绍 GNN 在结构场景中的应用,其中数据自然地在图结构中执行。
8.1.1. 图挖掘
第一个应用是解决图挖掘中的基本任务。通常,图挖掘算法用于识别下游任务的有用结构。传统的图挖掘挑战包括频繁子图挖掘、图匹配、图分类、图聚类等。虽然通过深度学习,一些下游任务可以直接解决,无需图挖掘作为中间步骤,但基本挑战值得研究 GNN 的观点。图匹配:第一个挑战是图匹配。传统的图匹配方法通常存在计算复杂度高的问题。GNN 的出现使研究人员能够使用神经网络捕获图的结构,从而为该问题提供了另一种解决方案。里巴等人(2018) 提出了一种孪生 MPNN 模型来学习图编辑距离。 siamese框架是两个具有相同结构和权重共享的并行MPNN,训练目标是将一对编辑距离小的图嵌入到紧密的潜在空间中。 李等人(2019b)设计类似的方法,同时在更真实的场景(例如控制流程图中的相似性搜索)上进行实验。图聚类:图聚类是根据图的结构和/或节点属性将图的顶点分组。在节点表示学习方面开展了各种工作(Zhang et al.,2019c),节点表示可以传递给传统的聚类算法。除了学习节点嵌入,图池化(Ying等人,2018b)也可以被视为一种聚类。最近,Tsitsulin等人(2020年)直接针对聚类任务。他们研究了一种良好的图聚类方法的理想特性,并提出了优化谱模块性的方法,这是一种非常有用的图聚类度量。
8.1.2 物理特性
对现实世界的物理系统进行建模是理解人类智能的最基本方面之一。 物理系统可以建模为系统中的对象以及对象之间的成对交互。 物理系统中的模拟要求模型学习系统的规律并预测系统的下一个状态。 通过将对象建模为节点和成对交互建模为边,系统可以简化为图。例如,在粒子系统中,粒子可以通过多个相互作用,包括碰撞 (Hoshen,2017) 、弹簧连接、电磁力 (Kipf等人,2018) 等,其中粒子被视为节点,相互作用被视为边缘。另一个示例是机器人系统,其由与关节连接的多个主体 (例如,臂、腿) 形成。身体和关节可以分别看作节点和边缘。该模型需要根据系统的当前状态和物理原理来推断物体的下一个状态。
在图形神经网络出现之前,工作使用可用的神经块处理系统的图表示。交互网络(Battaglia et al.,2016)利用MLP对图的关联矩阵进行编码。CommNet(Sukhbatar Ferguset al.,2016)使用节点以前的表示和所有节点以前表示的平均值执行节点更新。VAIN(Hoshen,2017)进一步引入了注意机制。VIN(Watters等人,2017年)结合了CNN、RNN和IN(Battaglia等人,2016年)。
GNN 的出现让我们能够以一种简化但有效的方式对对象、关系和物理进行基于 GNN 的推理。 NRI (Kipf et al., 2018) 将物体的轨迹作为输入,推断出显式交互图,同时学习动态模型。交互图是从以前的轨迹中学习的,并且轨迹预测是通过对交互图进行解码来生成的。
8.1.4 知识图谱
知识图(KG)表示现实世界实体的集合以及实体对之间的关系事实。它在问答、信息检索和知识引导生成等领域有着广泛的应用。KGs的任务包括学习包含丰富实体和关系语义的低维嵌入,预测实体之间缺失的链接,以及知识图上的多跳推理。一项研究将图视为三元组的集合,并提出各种损失函数来区分正确的三元组和错误的三元组(Bordes et al.,2013)。另一条线利用 KG 的图性质,并使用基于 GNN 的方法来完成各种任务。当将 KG 视为图时,可以将 KG 视为异构图。然而,与社交网络等其他异构图不同,逻辑关系比纯图结构更重要。
一个更具挑战性的设置是知识库外(OOKB)实体的知识库完成。OOKB实体在训练集中不可见,但直接连接到训练集中观察到的实体。OOKB实体的嵌入可以从观察到的实体中聚合。Hamaguchi等人(2017年)使用GNNs解决了这个问题,在标准KBC设置和OOKB设置中都取得了令人满意的性能。
除了知识图表示学习,Wang 等人(2018b)利用 GCN 解决跨语言知识图谱对齐问题。该模型将来自不同语言的实体嵌入到一个统一的嵌入空间中,并根据嵌入相似度对它们进行对齐。为了对齐大规模异构知识图谱,OAG (Zhang et al., 2019d) 使用图注意力网络对各种类型的实体进行建模。 Xu 等人将实体表示为其周围的子图。 (2019c) 将实体对齐问题转化为图匹配问题,然后通过图匹配网络解决。
8.1.5. 生成模型
现实世界图的生成模型因其重要的应用而备受关注,包括建模社交互动、发现新的化学结构和构建知识图谱。由于深度学习方法具有学习图隐式分布的强大能力,因此最近神经图生成模型激增。
NetGAN(Shchur et al., 2018b) 是最早建立神经图生成模型的工作之一,该模型通过随机游走生成图。它将图生成问题转化为游走生成问题,该问题将来自特定图的随机游走作为输入,并使用 GAN 架构训练游走生成模型。生成的图虽然保留了原图的重要拓扑性质,但在生成过程中节点的数量不能改变,与原图相同。GraphRNN (You et al.,2018b) 通过逐步生成每个节点的邻接向量来管理生成图的邻接矩阵,该邻接向量可以输出具有不同节点数的网络。Li等人 (2018d) 提出了一种模型,该模型按顺序生成边和节点,并利用图神经网络提取当前图的隐藏状态,该隐藏状态用于在顺序生成过程中决定下一步的动作。GraphAF (Shi et al., 2020) 也将图生成定义为一个顺序决策过程。 它将基于流的生成与自回归模型相结合。 对于分子生成,它还在生成的每个步骤之后使用现有的化学规则对生成的分子进行有效性检查。
其他工作不是按顺序生成图,而是一次生成图的邻接矩阵。MolGAN (De Cao和Kipf,2018) 利用置换不变判别器(permutation-invariant discriminator)来解决邻接矩阵中的节点变异问题。此外,它还将奖励网络应用于基于RL的优化,以达到所需的化学性质。此外,Ma等人 (2018) 提出了约束变分自动编码器(constrained variational auto-encoders),以确保生成的图的语义有效性。并且,GCPN(You等人,2018a) 通过强化学习整合了特定领域的规则。GNF(Liu et al., 2019) 将标准化流适应于图数据。归一化流是一种生成模型,它使用可逆映射将观察到的数据转换为潜在向量空间。使用逆矩阵将潜在向量转换回观测数据作为生成过程。 GNF 将归一化流程与置换不变的图自动编码器相结合,以图结构化数据作为输入并在测试时生成新图。Graphite (Grover et al., 2019) 将 GNN 集成到变分自动编码器中,以将图结构和特征编码为潜在变量。 更具体地说,它使用各向同性高斯作为潜在变量,然后使用迭代细化策略从潜在变量中解码。
8.1.6 组合优化
图上的组合优化问题是一组 NP-hard 问题,引起了各领域科学家的广泛关注。旅行商问题 (TSP) 和最小生成树 (MST) 等一些具体问题有各种启发式解决方案。最近,使用深度神经网络解决此类问题已成为热点,其中一些解决方案由于其图结构而进一步利用了图神经网络。
Bello等人(2017年)首先提出了一种解决TSP的深度学习方法。他们的方法由两部分组成:用于参数化奖励的指针网络(Pointer Network)(Vinyals等人,2015b)和用于训练的策略(policy)梯度(Sutton和Barto,2018)模块。这项工作已被证明与传统方法具有可比性。然而,指针网络是为文本等序列数据设计的,而顺序不变编码器更适合这种工作。
Khalil et al.(2017), Kool et al.(2019)通过包括图神经网络来改进上述方法。前一项工作首先从structure2vec(戴等人,2016)中获得节点嵌入,然后将它们馈入Q学习模块用于决策。后一项构建了基于注意力的编码器-解码器系统。通过用基于注意力的解码器替换强化学习模块,它对训练更高效。这些工作比以前的算法实现了更好的性能,这证明了图神经网络的表示能力。更一般地说,Gasse 等人。 (2019)将组合问题的状态表示为二分图,并利用 GCN 对其进行编码。
对于特定的组合优化问题,Nowak 等人。 (2018)专注于二次分配问题,即测量两个图的相似性。基于 GNN 的模型独立学习每个图的节点嵌入,并使用注意力机制匹配它们。即使在标准的基于松弛(relaxation-based)的技术似乎受到影响的情况下,这种方法也能提供令人感兴趣的良好性能。郑等人 (2020a) 使用生成图神经网络对 DAG 结构学习问题进行建模,这也是一个组合优化和 NP-hard 问题。 NeuroSAT (Selsam et al., 2019) 学习消息传递神经网络来对 SAT 问题的可满足性进行分类。它证明了学习模型可以推广到新的 SAT 分布和其他可以转换为 SAT 的问题。
与以前试图设计特定 GNN 来解决组合问题的作品不同,Sato 等人(2019)对这些问题的 GNN 模型进行了理论分析。 它在 GNN 和分布式局部算法之间建立连接,分布式局部算法是一组用于解决这些问题的图上的经典算法。 此外,它展示了最强大的 GNN 可以达到的最优解的最优逼近比。 这也证明了大多数现有的 GNN 模型都不能超过这个上限。 此外,它为节点特征添加了着色以提高近似比。
8.1.7. 交通网络
预测交通状态是一项具有挑战性的任务,因为交通网络是动态的并且具有复杂的依赖关系。 崔等人(2018b)结合 GNN 和 LSTM 来捕获空间和时间依赖性。STGCN(Yu et al., 2018) 使用空间和时间卷积层构造 ST-Conv 块,并将残差连接与瓶颈策略应用。 郑等人(2020b),郭等人(2019)两者都结合了注意力机制来更好地模拟时空相关性。
8.1.8 推荐系统
用户-项目交互预测是推荐中的经典问题之一。通过将交互建模为图形,GNN 可用于该领域。 GCMC (van den Berg et al., 2017) 首先将 GCN 应用于用户-项目评分图来学习用户和项目嵌入。为了在网络规模的场景中有效地采用 GNN,PinSage (Ying et al., 2018a) 为二分图构建了具有加权采样策略的计算图,以减少重复计算。社交推荐试图结合用户社交网络来提高推荐性能。GraphRec(Fan等人,2019年)从项目侧和用户侧学习用户嵌入。Wu等人(2019c)超越了静态社会效应。他们试图通过双重关注来模拟同质性和影响效应。
8.1.9 结构场景中的其他应用
由于图形结构数据的普遍性,GNN已被应用于比我们上面介绍的更多种类的任务。我们列出了更多非常简单的场景。在金融市场中,GNN被用来模拟不同股票之间的相互作用,以预测股票的未来趋势(Matsunaga等人,2019年;Yang等人,2019年;Chen等人,2018c;Li等人,2020年)。Kim等人(2019年)还通过将市场指数的变动表述为一个图形分类问题来预测市场指数的变动。在软件定义网络(SDN)中,GNN用于优化路由性能(Rusek等人,2019年)。在抽象意义表示(AMR)图形到文本生成任务中,Song等人(2018a),Beck等人(2018)使用GNNs对抽象意义的图形表示进行编码。
8.2. 非结构性情景
在本节中,我们将讨论非结构场景上的应用程序。通常,有两种方法可以将gnn应用于非结构化场景 :( 1) 合并来自其他领域的结构信息以提高性能,例如使用知识图中的信息来缓解图像任务中的零拍摄问题;(2) 推断或假设任务中的关系结构,然后应用该模型来解决定义在图形上的问题,例如 (Zhang et al.,20 1 8d) 中的方法将文本建模为图形。常见的非结构场景包括图像、文本和编程源代码 (Allamanis等人,2018; Li等人,2016)。但是,我们仅对前两种情况进行详细介绍。
8.2.1 图
少(零)次图像分类。 图像分类是计算机视觉领域一项非常基础和重要的任务,备受关注,拥有许多著名的数据集,如 ImageNet (Russakovsky et al., 2015)。 最近,零样本和少样本学习在图像分类领域变得越来越流行。 在 N-shot learning 中,为了对某些类别的测试数据样本进行预测,训练集中只提供相同类别的 N 个训练样本。 因此,few-shot learning 将 N 限制为小,而 zero-shot 则要求 N 为 0。模型必须学会从有限的训练数据中进行泛化,以便对测试数据做出新的预测。 另一方面,图神经网络可以在这些具有挑战性的场景中帮助图像分类系统。
8.2.2. 文本
图神经网络可以应用于基于文本的多个任务。它可以应用于句子级任务(例如文本分类)以及单词级任务(例如序列标记)。我们在下面列出了几个主要的文本应用。
文本分类。 文本分类是自然语言处理中一个重要且经典的问题。 传统的文本分类使用词袋特征。 然而,将文本表示为单词图可以进一步捕捉非连续单词和长距离单词之间的语义(Peng et al., 2018)。 彭等人 (2018) 使用基于图 CNN 的深度学习模型首先将文本转换为单词图,然后使用 (Niepert et al., 2016) 中的图卷积操作对单词图进行卷积。 张等人(2018d)提出了句子 LSTM 来编码文本。他们将整个句子视为一个单一状态,该状态由单个单词的子状态和整个句子级别的状态组成。他们使用全局句子级表示来进行分类任务。这
序列标记。 给定一系列观察到的变量(如单词),序列标注就是为每个变量分配一个分类标签。 典型的任务包括 POS 标记,我们通过词性标记句子中的单词,以及命名实体识别 (NER),我们预测句子中的每个单词是否属于命名实体的一部分。 如果我们将序列中的每个变量视为一个节点,将依赖项视为边,我们可以利用 GNN 的隐藏状态来解决任务。 张等人。 (2018d) 利用 Sentence LSTM 来标记序列。 他们对 POS 标记和 NER 任务进行了实验,并取得了可喜的表现。些方法可以将文档或句子视为单词节点的图。Yao等人 (2019) 将文档和单词作为节点来构建语料库图,并使用文本GCN来学习单词和文档的嵌入。情感分类也可以被视为文本分类问题,并且 (Tai等人,2015) 提出了Tree-LSTM方法。
语义角色标注是序列标注的另一项任务。 Marcheggiani 和 Titov (2017) 提出了一个句法 GCN 来解决这个问题。 在带有标记边的直接图上运行的句法 GCN ,它是 GCN 的一个特殊变体(Kipf 和 Welling,2017)。 它集成了边门,让模型调节个体依赖边的贡献。 句法依赖树上的句法 GCN 被用作句子编码器来学习句子中单词的潜在特征表示。
神经机器翻译。神经机器翻译 (NMT) 任务是使用神经网络自动将文本从源语言翻译成目标语言。它通常被认为是一个序列到序列的任务。 Transformer (Vaswani et al., 2017) 引入了注意力机制并替换了最常用的循环层或卷积层。实际上,Transformer 假设单词之间是完全连接的图结构。可以使用 GNN 探索其他图结构。
GNN 的一种流行应用是将句法或语义信息合并到 NMT 任务中。 巴斯廷斯等人(2017)在句法感知 NMT 任务上使用句法 GCN。 Marcheggiani 等人(2018 年)使用 Syntactic GCN 合并有关源句的谓词-参数结构(即语义角色表示)的信息,并比较仅合并句法信息、仅合并语义信息和两种信息的结果。 贝克等人。 (2018)在语法感知 NMT 中使用 GGNN。 他们通过将边转换为附加节点,将句法依赖图转换为称为 Levi 图 (Levi, 1942) 的新结构,因此边标签可以表示为嵌入。
关系提取。 提取文本中实体之间的语义关系有助于扩展现有的知识库。 传统方法使用 CNN 或 RNN 来学习实体的特征并预测一对实体的关系类型。 更复杂的方法是利用句子的依存结构。 可以构建文档图,其中节点表示单词,边表示各种依赖关系,例如邻接、句法依赖和话语关系。 张等人(2018f)提出了图卷积网络的扩展,该扩展专为关系提取而定制,并将修剪策略应用于输入树。
跨句N元关系提取检测跨多个句子的n个实体之间的关系。Peng等人 (2017) 通过在文档图上应用图LSTMs,探索了用于跨句n元关系提取的一般框架。Song等人 (2018b) 还使用图LSTM模型,并通过允许更多的并行化来加快计算速度。
事件提取。事件提取是识别文本中指定类型事件实例的重要信息提取任务。这总是通过识别事件触发器,然后预测每个触发器的参数来进行。Nguyen和Grishman(2018)研究了一个基于依赖树的卷积神经网络(这正是语法GCN)来执行事件检测。Liu等人(2018)提出了一个联合多个事件提取(JMEE)框架,通过引入语法快捷弧来联合提取多个事件触发器和参数,以增强信息流向基于注意力的图卷积网络来建模图信息。
事实验证。 事实验证是一项需要模型提取证据来验证给定声明的任务。 然而,有些主张需要对多条证据进行推理。 提出了基于 GNN 的方法,如 GEAR (Zhou et al., 2019) 和 KGAT (Liu et al., 2020),用于基于完全连接的证据图进行证据聚合和推理。 钟等人(2020)使用来自语义角色标签的信息构建句子内图并取得可喜的结果。
文本上的其他应用。Gnn也可以应用于文本上的许多其他任务。例如,gnn还用于问题回答和阅读理解 (Song等人,2018c; De Cao等人,2019; Qiu等人,2019; Tu等人,2019; Ding等人,2019)。另一个重要的方向是关系推理,提出了关系网络 (Santoro等人,2017) 、交互网络 (Battaglia等人,2016) 和递归关系网络 (Palm等人,2018) 来解决基于文本的关系推理任务。