作者:香港中文大学计算机科学与工程系,中国香港特别行政区、腾讯人工智能实验室,中国深圳的Zeng等人
参考阅读: https://www.sohu.com/a/270689666_129720
摘要
由于数据的稀疏性,许多分类模型在短文本上工作得很差。为了解决这个问题,我们提出了用于短文本分类的主题记忆网络,该网络使用一种新的主题记忆机制来表示类标签的潜在主题。与以往大多数侧重于利用外部知识或预先训练的主题扩展特征的工作不同,我们的模型以端到端的方式共同探索了使用记忆网络的主题推理和文本分类。在4个基准数据集上的实验结果表明,我们的模型在短文本分类方面优于目前最先进的模型,并能产生连贯的主题。
引言
短信已经成为个人在网络平台上表达意见和分享信息的一种重要形式。大量的每日生成的内容,如tweet、web搜索片段、新闻提要和论坛消息,已经远远超过了个人的阅读和理解能力。因此,迫切需要自动语言理解技术来处理和分析这类文本(Zhang et al., 2018)。在这些技术中,文本分类是一种关键和基本的技术,已被证明在各种下游应用中有用,如文本摘要(Hu et al., 2015)、推荐(Zhang et al., 2012)和情感分析(Chen et al., 2017)。
尽管许多分类模型如支持向量机(svm) (Wang and Manning, 2012)和神经网络(Kim, 2014;肖和赵,2016;Joulin等人,2017)已经证明了他们在处理正式和精心编辑的文本方面的成功,例如新闻文章,但当直接应用于简短和非正式的在线文本时,它们的性能不可避免地会受到影响。这种劣等的性能归因于短文本严重的数据稀疏性,这导致了可供分类器使用的特征有限(Phan等人,2008)。为了缓解数据稀疏问题,一些方法利用外部资源的知识,如维基百科(Jin et al., 2011)和知识库(Lucia和Ferrari, 2014;Wang et al., 2017a)。然而,这些方法依赖于大量高质量的外部数据,而这些数据对于某些特定领域或语言可能是不可用的(Li等人,2016a)。
基于上述观察,我们提出了一种新的神经网络框架——主题记忆网络(TMN),用于不依赖外部知识的短文本分类。我们的模型可以通过共同利用文档级单词共现模式,识别用于分类的指示性单词,如S中的“腕带”,如R2中的“腕带”和“比伯”。更具体地说,基于成功的神经主题模型(Srivastava和Sutton, 2017;苗等人,2017),我们的模型能够发现潜在的主题,能够捕获文档级别的词的共现。为了利用潜在主题进行短文本分类,我们提出了一种新的主题记忆机制,该机制受到记忆网络的启发(Weston et al., 2014;(Graves et al., 2014),它允许模型将注意力放在有助于分类的指示性潜在主题上。通过这种语料库级的潜在主题表示,每个短文本实例都得到了丰富,从而有助于缓解数据稀疏性问题。
在先前的研究中,尽管主题模型对短文本分类的影响已经被探索(Phan et al., 2008;Ren et al., 2016),现有的方法往往使用预先训练的主题作为特征。据我们所知,我们的模型是首次通过记忆网络编码潜在主题表示的短文本分类,这允许联合推断潜在主题。
为了评估我们的模型,我们在四个基准数据集上实验并与现有的方法进行了比较。实验结果表明,该模型在短文本分类方面优于现有的同类算法。定量和定性分析说明了我们的模型在生成有意义的、指示不同类别的主题表示方面的能力。
2 主题记忆网络
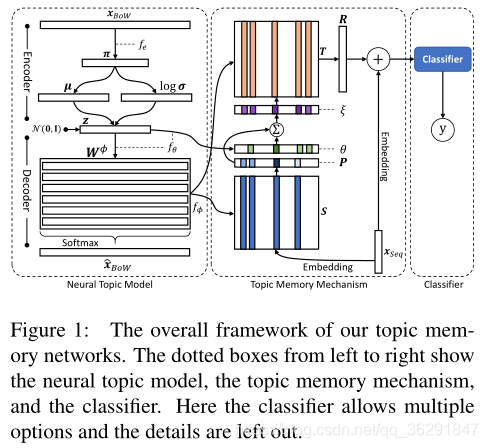
在本节中,我们将描述我们的主题内存网络(TMN),主题记忆网络一共可以分为三部分,从左到右分别是 Neural Topic Model (神经主题模型)、Topic Memory Mechanism(主题记忆机制)、以及 Classifier(文本分类器)。其中,神经主题模型主要用于学习主题表示;主题记忆机制主要用于将学到的主题表示映射到对文本分类有用的特征空间当中;文本分类器主要用于输出文本分类标签。这三个部分可以通过联合学习过程同时更新,具体来说,对于分类器,我们的TMN框架允许多个选项的组合,例如CNN和RNN,这可以根据具体的应用场景来决定。
具体来说,给定M个句子的输入X = x 1 , x 2 , . . . , x M X = {x^1,x^2, . . . ,x^M}X=x1,x2,...,xM
2.1 神经主题模型
我们的主题模型是受神经主题模型(NTM)的启发(Miao et al., 2017;Srivastava和Sutton, 2017)在神经网络中诱导潜在主题。NTM基于变分自动编码器(VAE) (Kingma and Welling, 2013),使用连续潜在变量z作为中间表示。在NTM中,潜在变量z ∈ R K z ∈ R^Kz∈RK,其中K为主题数量。接下来,我们将依次描述模型的生成和推理。
NTM生成
NTM推理
2.2 主题记忆机制
我们利用主题记忆机制将NTM产生的潜在主题(在2.1节中描述)映射到用于分类的特征。
2.3 联合学习
3 实验设置
数据集
Snippts
TagMyNews
Twitter
Weibo:中文数据集
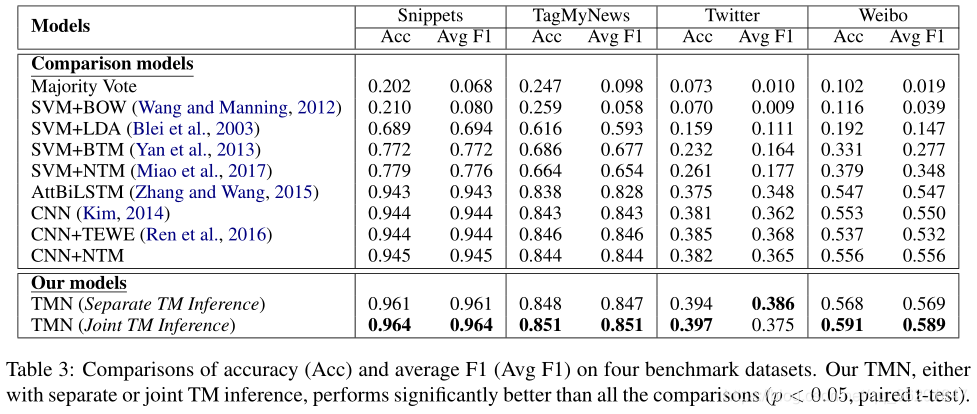
4 实验结果
5 相关工作
我们的工作主要建立在两个先前的工作的基础上:短文本分类和主题模型。
短的文本分类。在短文本分类方面,大部分工作集中在缓解短文本中严重的稀疏性问题(Yan et al., 2013)。之前的一些工作从外部资源编码知识(Jin et al.,2011;Lucia and Ferrari, 2014;Wang等,2017a;Ma等,2018)。相反,我们的工作只从内部数据中学习有效的表示。对于一些特定的分类任务,如情感分析,手工制作的特征被设计来适应目标任务(Pak和Paroubek, 2010;Jiang et al., 2011)。与之不同的是,我们采用深度学习框架进行表示学习,不需要特征工程过程,从而保证了其对不同分类场景的普遍适用性。与已建立的应用深度学习方法的分类器比较(dos Santos and Gatti, 2014;Lee和Dernoncourt, 2016),我们的工作不同于他们在利用语料库级潜在主题表示缓解数据稀疏问题。在使用主题特征的现有分类模型中,预先训练的主题混合被用作特征的一部分(Phan et al., 2008;Ren等,2016;Chen等人,2017)。不同的是,我们的模型在一种记忆机制中对主题表示进行编码,其中主题与文本分类以端到端方式共同诱导。
主题模型。众所周知的主题模型,如概率潜在语义分析(pLSA) (Hofmann, 1999)和潜在Dirichlet分配(LDA) (Blei et al., 2003),已经显示出在捕获有效语义表示方面的优势,并被证明有利于各种下游应用,如摘要(Haghighi和V anderwende,2009)和推荐(Zeng et al., 2018;Bai等,2018)。对于短文本数据,为了减少稀疏性问题对主题建模的影响,已经提出了主题模型变式,如biterm主题模型(BTM) (Yan et al., 2013)和LeadLDA (Li et al., 2016b)。最近,由于变分自编码器(VAE) (Kingma and Welling, 2013)的流行,它能够在神经网络中诱导潜在的主题,即神经主题模型(NTM) (Miao et ., 2017;Srivastava和Sutton, 2017)。虽然Cao et al.(2015)早前已经提到NTM的概念,但他们的模型是基于矩阵分解的。不同,V ae风格的NTM (Srivastava和Sutton, 2017;苗等,2017)遵循LDA的风格,作为概率生成模型,易于解释和扩展。我们框架中的NTM是V ae风格的,它对短文本分类的影响是我们工作的重点。
6 结论
我们提出了利用语料库级主题表示和主题记忆机制进行短文本分类的主题记忆网络。该模型通过共同学习潜在主题和文本类别,缓解了数据稀疏性问题。在四个基准数据集上与最先进的模型进行了实证比较,证明了该模型的有效性和有效性,在短文本分类和主题一致性评价方面都取得了较好的结果。