文章目录
一、scrapy_selenium安装
pip install scrapy_selenium
二、配置scrapy
1.修改settings
SELENIUM_DRIVER_NAME 要和启动浏览器名一致,SELENIUM_DRIVER_EXECUTABLE_PATH 是驱动路径使用which方法可以返回出驱动器路径
也可直接写驱动器路径,which 效果如下:(返回在cmd中可执行文件路径)
如果不想设置无头启动就给一个空内容可以是空字符串空列表等但必须有
SELENIUM_DRIVER_ARGUMENTS = []
代码如下(示例):
from shutil import which
SELENIUM_DRIVER_NAME = 'chrome'
SELENIUM_DRIVER_EXECUTABLE_PATH = which('chromedriver')
SELENIUM_DRIVER_ARGUMENTS = ['-headless']
开启中间件,这是scrapy_selenium自带中间件
2.spider
scrapy会优先使用scrapy.Request,这里需要先用selenium打开浏览器,因此可以重写父类的start_requests方法 使用SeleniumRequests发起请求
代码如下(示例):
from scrapy_selenium import SeleniumRequest
def start_requests(self):
for url in self.start_urls:
yield SeleniumRequest(url=url,
callback=self.parse,
)
SeleniumRequests的参数
SeleniumRequests与Requests参数是一致的区别在于多了几个参数,wait_time,wait_until,screenshot,script
1.wai_time 和 wait_until
与selenium中显示等待一致wait_time=5设置等待时间为整型
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
yield SeleniumRequest(url=url,
callback=self.parse,
wait_time=10,
wait_until=EC.element_located_to_be_selected((By.ID, 'id'))
)
等价于
WebDriverWait(browser, 10)
wait.until(EC.element_located_to_be_selected((By.ID, 'id')))
2.screenshot
此参数为布尔型 默认False,开启后将会对浏览器截屏
yield SeleniumRequest(url=url,
callback=self.parse,
screenshot=True
)
并且会储存在响应的meta中,如需要下载下来则
def parse(self, response):
with open('./screenshot.png', 'wb') as f:
f.write(response.meta['screenshot'])
f.close()
3.script
script是将要执行的js代码为字符串 类型 示例如下:
浏览器页面将下拉一屏
yield SeleniumRequest(url=url,
callback=self.parse,
script='window.scrollTo(0,document.body.scrollHeight);'
)
注意:这里的参数虽然顺序可变,但是执行顺序是固定的,先会执行wait_time,wait_until的内容,然后是screenshot,最后才是js代码。
因此这里会出现一个问题在打开一些下滑显示的网页时,可能会因网页限制(网页已经响应完成,内容延迟展示)
但是selenium响应已经完成,因此返回出来的数据是没有变化的。对于无id classname 一样的节点使用显示等待也并不好用,因为这等待完成才会执行js代码。使用js代码中的setTimeout也无法解决这个问题。
这里我的解决办法就是重写SeleniumMiddleware中间件的process_request方法
DOWNLOADER_MIDDLEWARES = {
'OneSpider.middlewares.SeleniumSpidermiddlewares': 543,
# 'scrapy_selenium.SeleniumMiddleware': 800,
}
settings中关闭之前开启的中间件,打卡自定义中间件
代码如下(这是父类中process_request写法)为了简单可直接复制下来在需要的地方加以修改
对于以上问题只需要在执行完js代码后加一个延时即可:
from scrapy_selenium import SeleniumMiddleware
class SeleniumSpidermiddlewares(SeleniumMiddleware):
def process_request(self, request, spider):
if not isinstance(request, SeleniumRequest):
return None
self.driver.get(request.url)
for cookie_name, cookie_value in request.cookies.items():
self.driver.add_cookie(
{
'name': cookie_name,
'value': cookie_value
}
)
if request.wait_until:
WebDriverWait(self.driver, request.wait_time).until(
request.wait_until
)
if request.screenshot:
request.meta['screenshot'] = self.driver.get_screenshot_as_png()
if request.script:
self.driver.execute_script(request.script)
time.sleep(2) # 修改部分
body = str.encode(self.driver.page_source)
# Expose the driver via the "meta" attribute
request.meta.update({'driver': self.driver})
return HtmlResponse(
self.driver.current_url,
body=body,
encoding='utf-8',
request=request
)
其实细看源码就可以知道它的执行顺序如果想改变之前执行顺序重写的process_request方法可以自行发挥,根据自己需求修改。
对于连接远程selenium中目前还在测试阶段scrapy_selenium0.0.7并不支持。
具体情况可以去 scrapy_selenium官方中了解
官方说法在设置中添加以下内容代替驱动器路径:
SELENIUM_DRIVER_NAME = 'chrome'
# SELENIUM_DRIVER_EXECUTABLE_PATH = which('chromedriver')
SELENIUM_DRIVER_ARGUMENTS = []
SELENIUM_COMMAND_EXECUTOR = 'http://localhost:4444/wd/hub'
对于0.0.7版本这将会报出警告,这不会执行SeleniumRequests 取而代之的时使用Requests直接响应。从官方中下载测试的包测试,测试结果是可以连接的但是在我执行时会报错错误内容: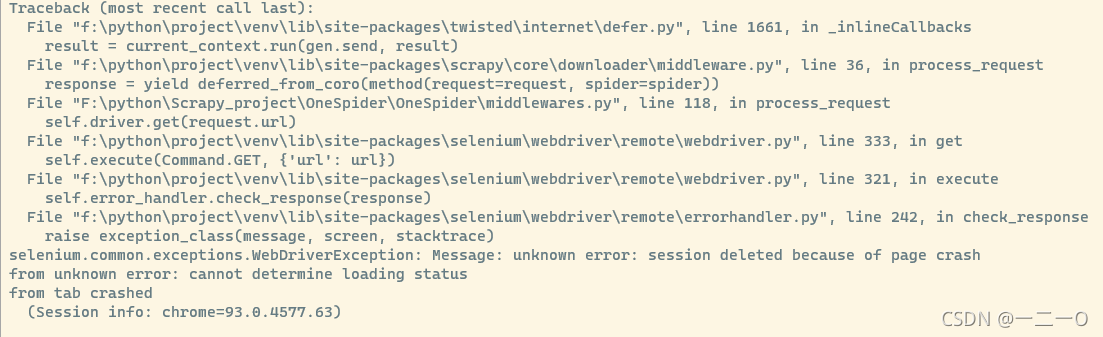
具体原因是(设置容器 /dev/shm 分区的大小)具体方法见参考博客,也可自行网上查找这里就不过多阐述。
附件:
测试的scrapy_selenium
链接: https://pan.baidu.com/s/1LTfHbLEn0TrZALKueux4Og 提取码: iiw7
将此文件解压下来替换python的包即可
连接远程的selenium可用docker开启端口
具体参考博客
如果只是测试玩玩的话只需开启两个容器
docker run -d --name wxhub -p 4444:4444 selenium/hub
docker run -d -P -p 5900:5900 --link wxhub:hub selenium/node-chrome-debug
docker下载方法可以查考docker官网,非常详细。下载好开启docker服务直接执行上述代码即可(在终端中执行),docker会自动下载,
选择需要的版本
点击docker desktop for windos即可下载windows版本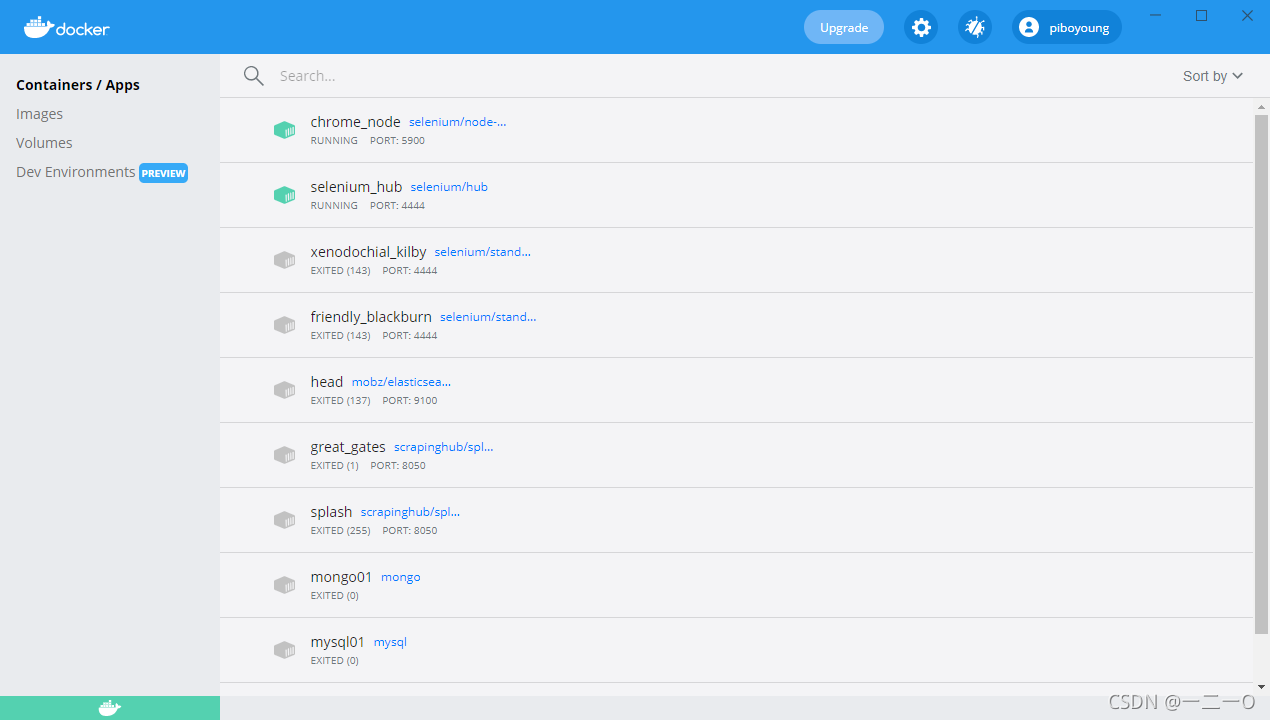
安装完成界面
开始这里容器都是空的,images镜像也是空的执行完上面代码都会显示,
注意:windows使用docker需要启用WSL 2 功能官方有打开方法
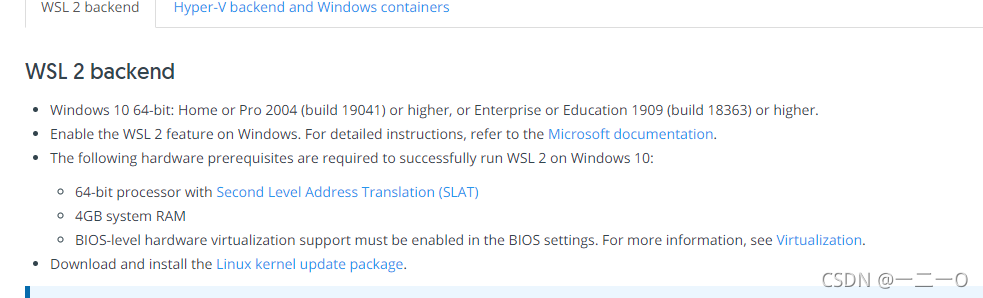
如果想进一步看到远程执行效果可以使用VNC查看, 下载链接
链接: https://pan.baidu.com/s/1AENu65vc5ckf7BC-B3h-Fg提取码: mhne
安装完成后,新建连接只需填写这一项,连接会需要输入密码, 密码secret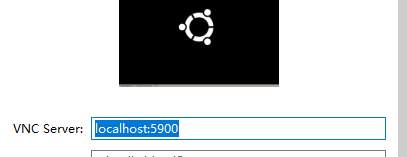
效果如下: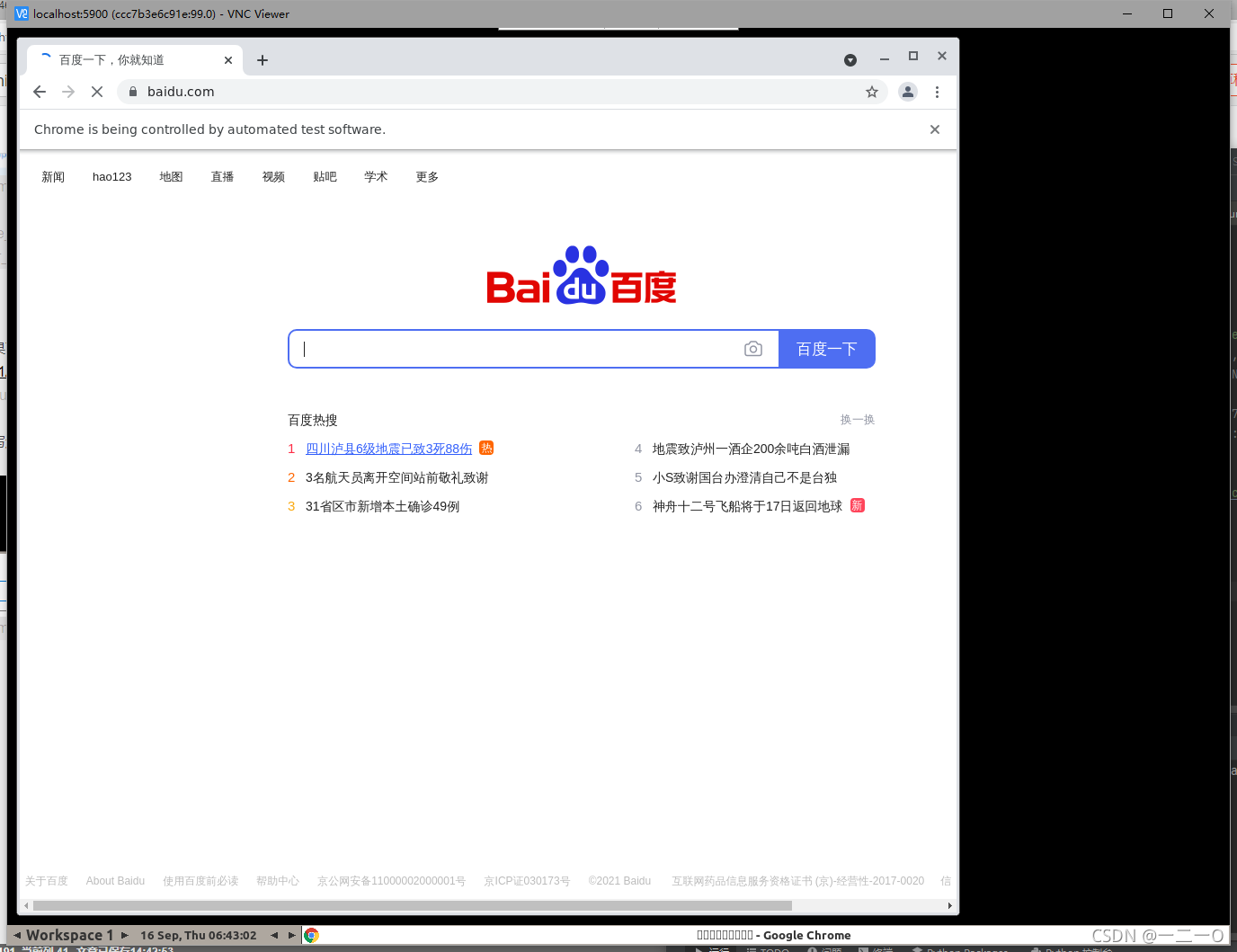
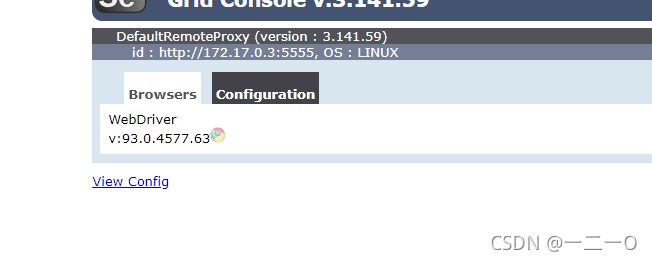
http://localhost:4444/grid/console可以看到使用状态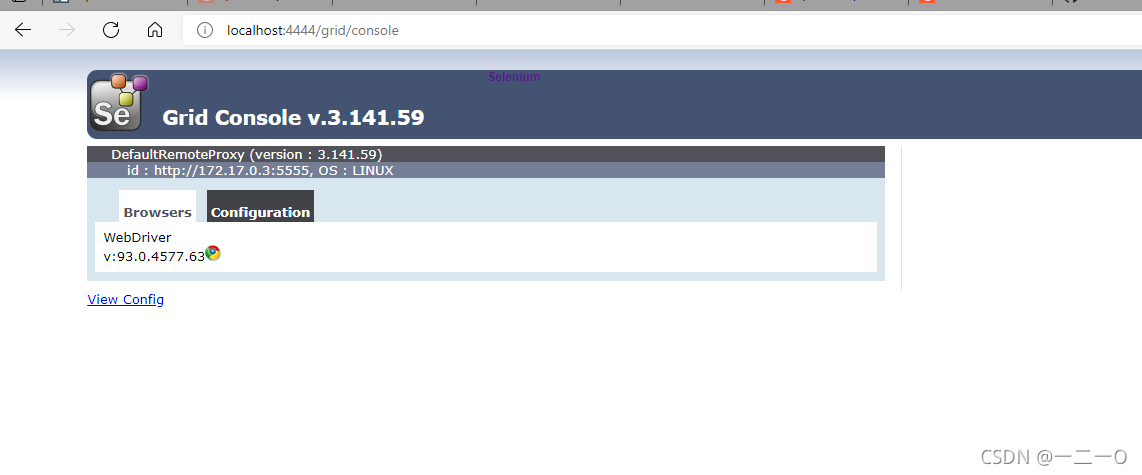
变灰则正在使用