这一讲是承接《 C++基础精讲篇第2讲》的内容补充之一。读者们可以先把上一讲的知识学习了以后,再学习这一讲的相关知识。这一讲主要为大家分享C++特有的内联函数、auto关键字、基于范围的for循环以及指针空值。希望大家在我的文章的帮助下,能有所收获,那我们就开始学习吧。

目录
1、内联函数
1.1 定义
以inline修饰的函数叫做内联函数,编译时C++编译器会在调用内联函数的地方展开,没有函数压栈的开销,其可以提高程序运行的效率。
1.2 用法介绍
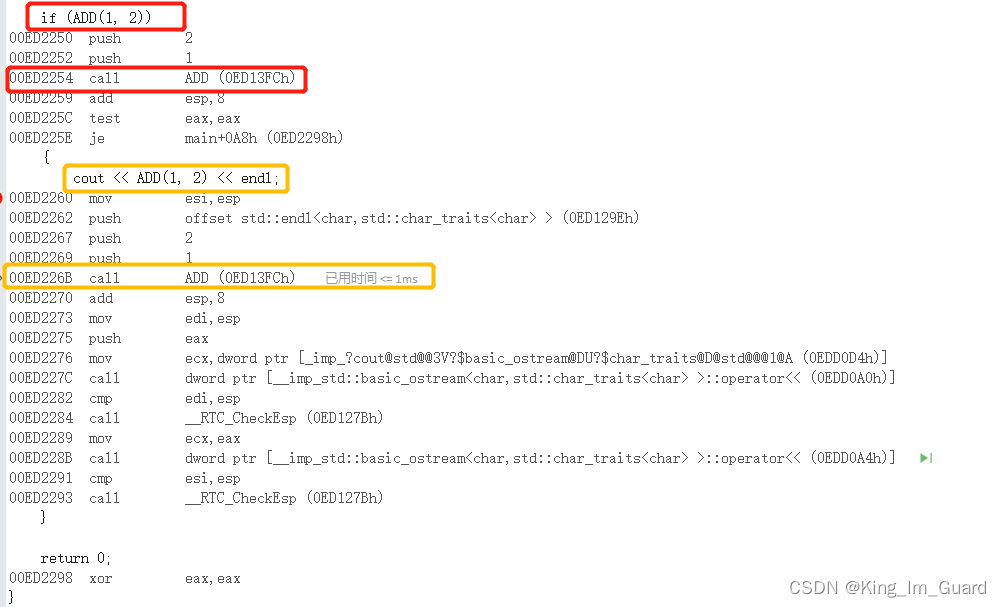
首先我们写一个常规的求和函数,如下图所示,在调试过程中,利用vs编译器的“反汇编”命令查看程序的底层原理,从汇编中可以看出,利用push命令将实参1和2传递给形参a和b,然后利用call命令调用ADD函数,最终得到求和结果。这是常规的函数调用的利用汇编查看的底层原理。
#include<stdio.h>
using namespace std;
int ADD(int a, int b)
{
return a + b;
}
int main()
{
cout << ADD(1, 2) << endl;
if (ADD(1, 2))
{
cout << ADD(1, 2) << endl;
}
return 0;
}
在分析内联函数的工作原理时,首先需要对VS编译器进行设置,首先需要确保在Debug模式下,因为在release条件下,可能会被系统优化,使得查看不了内联函数的效果,然后分以下三步骤进行设置即可。
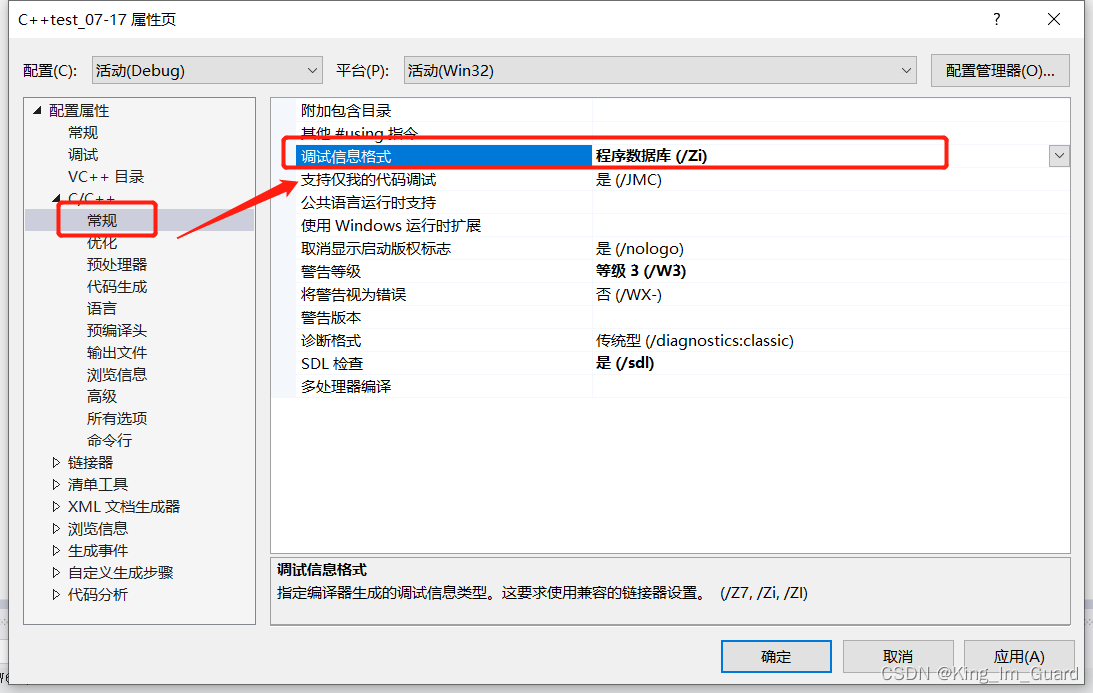
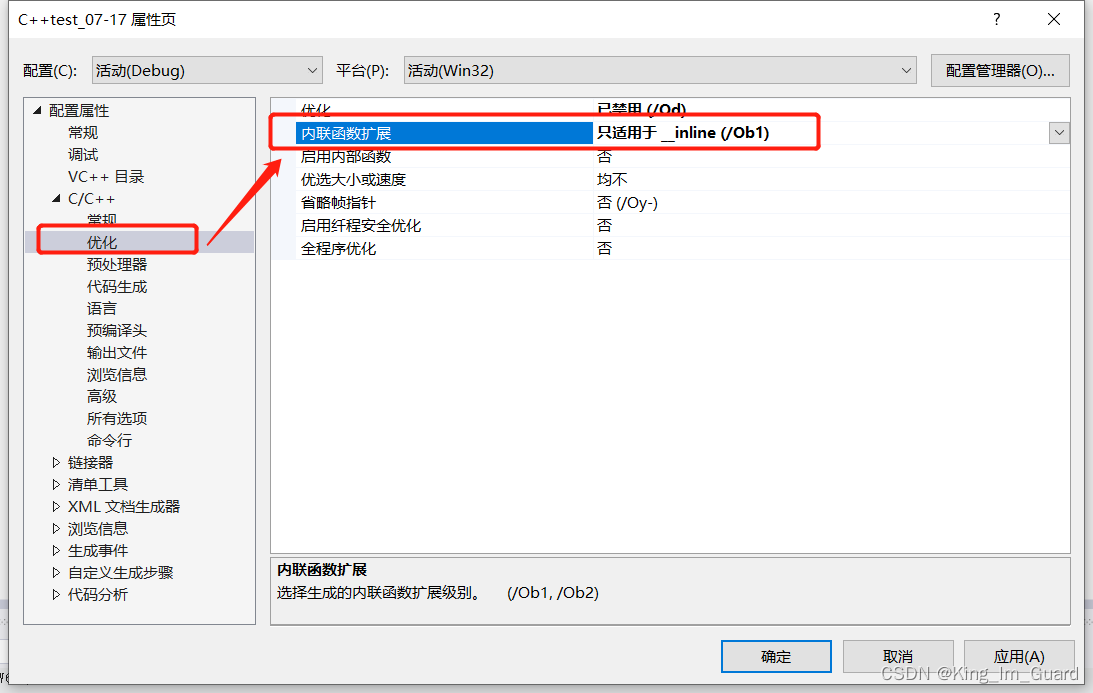
当我们完成以上步骤设置后,采用以下函数分析:同样利用上面分析的ADD求和函数,此时我们在ADD函数前面加上“inline”,我们才用同样的调试方法,利用vs编译器的“反汇编”命令查看程序的底层原理,从汇编中可以看出,利用inline将函数展开,而不是采用call命令进行调用。
#include<stdio.h>
using namespace std;
//内联:在函数名前用inline表示
//在符合其条件的情况下,在调用的地方展开
inline int ADD(int a, int b)
{
return a + b;
}
int main()
{
cout << ADD(1, 2) << endl;
if (ADD(1, 2))
{
cout << ADD(1, 2) << endl;
}
return 0;
}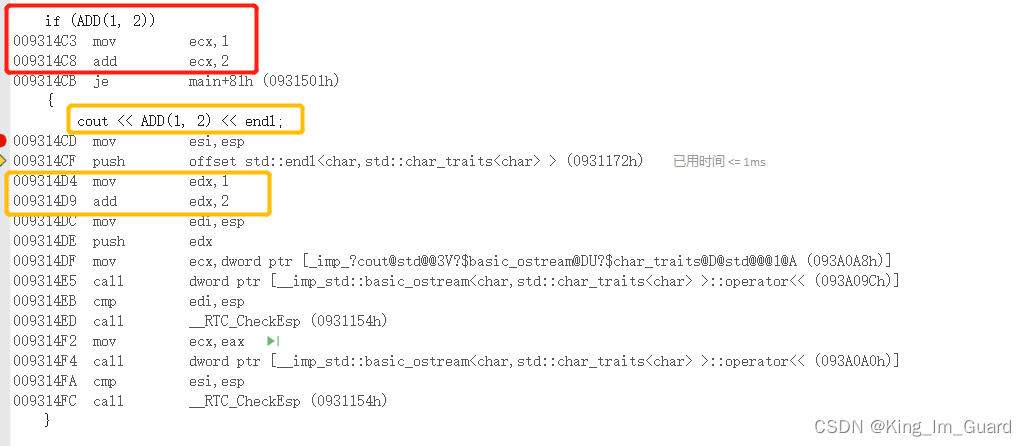
通过上面的对比,我们可以看到,利用inline将函数变成内联函数,相比于正常的通过开辟函数栈帧进行函数调用的方法,利用内联函数则是直接将函数展开,可以极大的提高程序的运行效率。但inline不是无所不能的,其也是需要在一定条件下使用,下面我将重点分析。
1.3 特性
1.3.1 使用注意事项
1、inline是一种以空间换时间的做法,省去调用函数的开销。但正是因为如此,如果代码很长,或者有循环/递归的函数不适宜将其作为内联函数,因为在编译过程中如果将代码展开,则经过编译出来的可执行程序会变很大。
2、inline对于编译器而言只是一种建议,编译器会自动优化,如果定义为inline的函数体内有循环/递归等,编译器优化时会忽略掉内联。
3、inline不建议声明和定义分离,分离会导致链接错误,因为inline将函数展开以后,就不存在函数地址了,此时链接就不能在符号表中找到该函数,即链接失效。
1.3.2 举例说明
针对使用注意事项1和2,我将一起举例为读者说明原因:
举例1:含有多条语句时的情况(此时inline不展开)
如下程序所示,在函数fun中,我多次调用C++中的打印函数打印变量“a+b”,可以我们发现当重复执行多条打印语句时,此时inline就别编译器忽略了,从汇编角度可以看到增加了内联常规的函数二者汇编指令是一致的,这也能更好的证实这第1点。
#include<stdio.h>
using namespace std;
inline void fun(int a, int b)
{
cout << a + b << endl;
cout << a + b << endl;
cout << a + b << endl;
cout << a + b << endl;
cout << a + b << endl;
cout << a + b << endl;
}
int main()
{
fun(100, 200);
return 0;
}
#include<stdio.h>
using namespace std;
void fun(int a, int b)
{
cout << a + b << endl;
cout << a + b << endl;
cout << a + b << endl;
cout << a + b << endl;
cout << a + b << endl;
cout << a + b << endl;
}
int main()
{
fun(100, 200);
return 0;
}
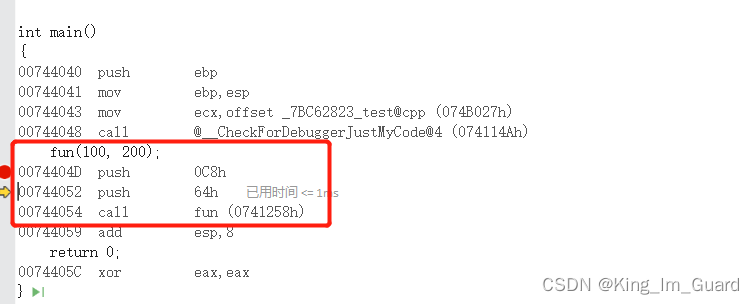
举例2:函数中含有循环语句时的情况
在fun函数中,我创建了两个循环语句,两个循环共计循环24次,对比增加了内联和常规的函数,我们会发现,其汇编指令是一致的,说明在编译中,编译器自动忽略内联,这也证实了第2点。
#include<stdio.h>
using namespace std;
void fun(int a, int b)
{
int c = 0;
for (c = 0; c < (a + b); c++)
{
cout << c ;
}
cout << endl;
int d = 0;
for (d = 0; d < (a + b); d++)
{
cout << d << endl;
}
}
int main()
{
fun(10, 2);
return 0;
}
#include<stdio.h>
using namespace std;
inline void fun(int a, int b)
{
int c = 0;
for (c = 0; c < (a + b); c++)
{
cout << c ;
}
cout << endl;
int d = 0;
for (d = 0; d < (a + b); d++)
{
cout << d << endl;
}
}
举例3:函数的声明和定义分开时
从下面的例子中可以看到:当函数声明和定义分开时,此时采用inline将函数展开,会发现出现找不到函数地址了,也就是说在链接的过程中,call找不到函数名,在符号表中没有找到该函数。为此,不能在函数声明和定义分开的情况下使用内联。
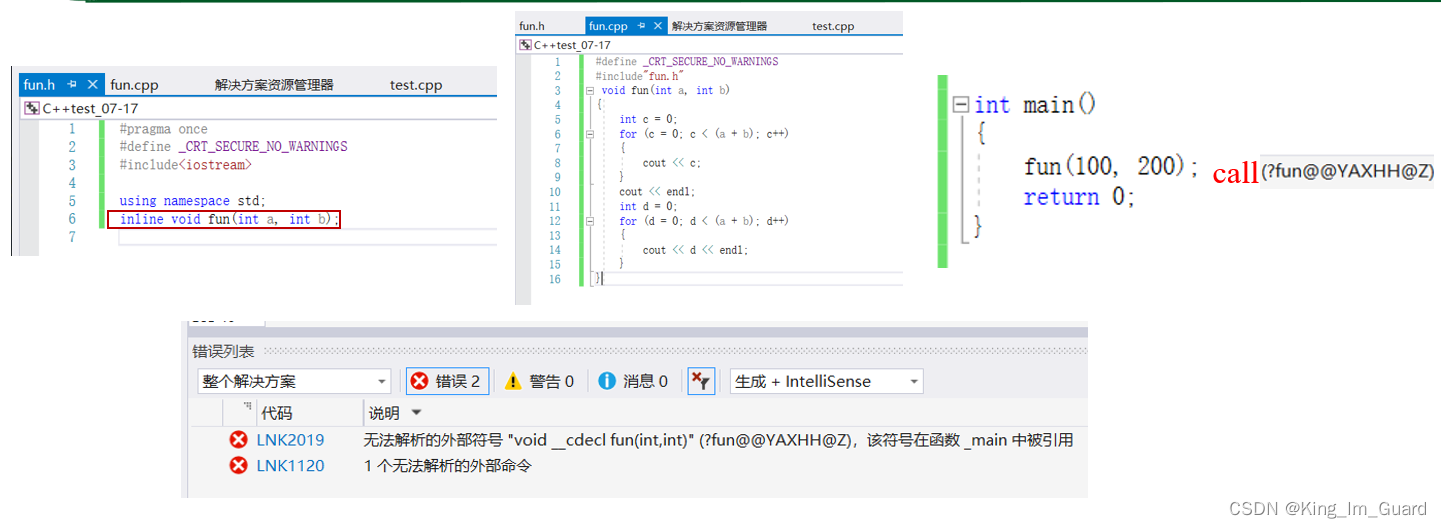
经过上面的分析,可以总结一点就是:内联只有在符合条件的情况下展开。 读者们在使用的过程中要特别注意。
1.4 与宏相比内联的优势
在c++中设计内联函数的目的就是为了替代C语言中宏函数的优化,在C++中不在建议使用宏,具体原因我将在下面给出分析。首先我们先来看看宏使用的优缺点:
优点:
1、增强代码的复用性。比如在定义某一常变量时,#define x 10 ,诸如此类情况,通过需求改变x待取的值,就可以实现不同的作用,这也印证了宏在增强代码的复用性方面的作用;
2、提高性能;比如:#define Add(a,b) ((a)+(b)),在此类程序代码少情况中,如果采用函数的形式,当我们在程序中需要多次调用该Add函数时,正常情况下,使用一次就会开辟一次函数栈帧,这样就会导致效率低下,而如果采用宏函数,则程序执行效率则会提高很多;
缺点:
1、不方便调试宏:因为在预编译阶段,就进行了替换,此时不方便调试;
2、由于第一条在预编译阶段进行替换,会导致代码可读性差,可维护性差,容易误用等;
3、因为宏在编译过程中是进行替换,为此就不存在类型安全检查。
综合以上宏的优缺点分析,我们会发现:内联函数很好的继承了宏的优点以及避开了宏的缺点,这也就是为什么在C++中不在建议使用宏的原因(这不是个人建议,而是统一是这样。)
总结:C++中在这两方面替代宏:1、常量定义,换用const;2、函数定义,换用内联函数。
2、auto关键字
2.1 概念
在早期的C/C++中auto的含义是:使用auto修饰的变量,是具有自动存储器的局部变量。但当时很少有人采用,在C++11中,标准委员会赋予了auto全新的含义即:auto不再是一个存储类型指示符,而是作为一个新的类型指示符来指示编译器,auto声明的变量必须由编译器在编译时期推导而得。
注意:使用auto定义变量时必须对其进行初始化,在编译阶段编译器需要根据初始化表达式来推导auto的实际类型。因此auto并非是一种“类型”的声明,而是一个类型声明时的“占位符”,编译器在编译时期会将auto替换为变量实际的类型。
简而言之,就是auto能够自动推导类型,但其不是诸如int、char等的类型声明符。
2.2 使用细则
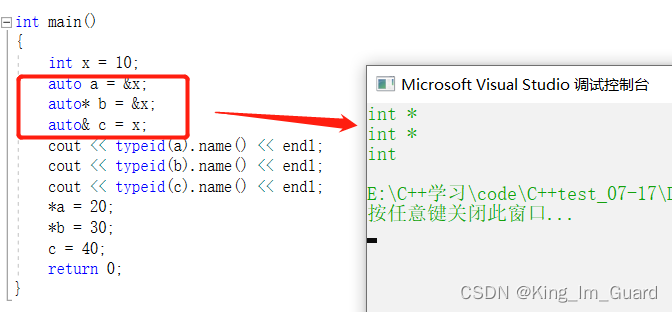
2.2.1 auto与指针和引用结合起来使用
#include<stdio.h>
using namespace std;
int main()
{
int x = 10;
auto a = &x;
auto* b = &x;
auto& c = x;
cout << typeid(a).name() << endl;
cout << typeid(b).name() << endl;
cout << typeid(c).name() << endl;
*a = 20;
*b = 30;
c = 40;
return 0;
}
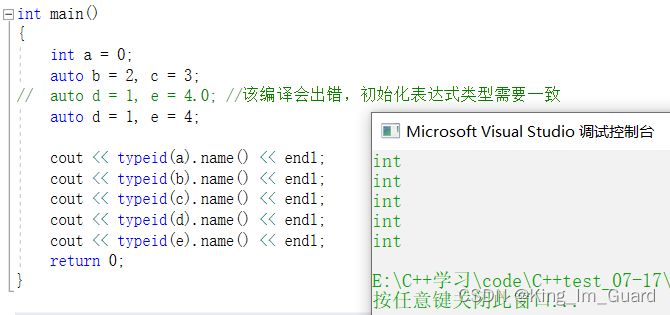
2.2.2 在同一行定义多个变量时的场景
当在同一行声明多个变量时,这些变量必须是相同的类型,否则编译器将会报错,因为编译器实际只对第一个类型进行推导,然后用推导出来的类型定义其他变量。
#include<stdio.h>
using namespace std;
int main()
{
int a = 0;
auto b = 2, c = 3;
// auto d = 1, e = 4.0; //该编译会出错,初始化表达式类型需要一致
auto d = 1, e = 4;
cout << typeid(a).name() << endl;
cout << typeid(b).name() << endl;
cout << typeid(c).name() << endl;
cout << typeid(d).name() << endl;
cout << typeid(e).name() << endl;
return 0;
2.2.3 auto不能推导的场景
1、auto不能作为函数的参数

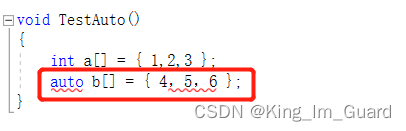
2、auto不能直接用来声明数组
2.3 auto用法举例
在这里引入一个C++11中才有的新名词“基于范围的for循环”,auto可以和“范围for”一起使用,以下面例子为例说明:
#include<stdio.h>
using namespace std;
int main()
{
int a[] = { 1,2,3,4,5,6 };
//常规写法
for (int i = 0; i < sizeof(a) / sizeof(a[0]); i++)
{
cout << a[i] << ' ';
}
cout << endl;
//auto用法:结合范围for使用
//自动取a的值给e,自动++,自动判断结束
//自动迭代
for (auto e : a)
{
cout << e << ' ';
}
cout << endl;
return 0;
}
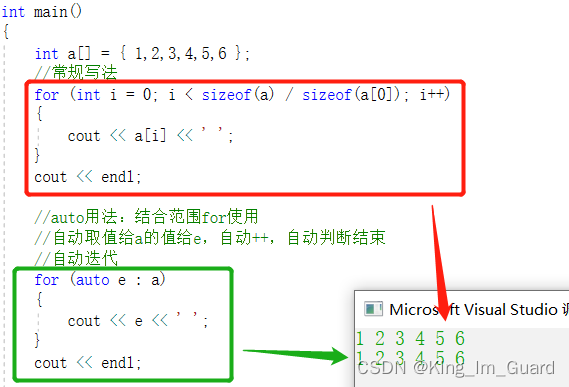
从上面的例子可以看出,auto和“范围for”配合使用,在书写循环程序方面会带来很多便利,下面简要介绍“范围for”的用法。
for循环后的括号由冒号":"分为两部分:前一部分是范围内用于迭代的变量,后部分则是表示被迭代的范围,即自动取变量a中的值给e,自动赋值,自动++,自动迭代。
注意事项:for循环迭代的范围必须是确定的(对于数组而言,就是数组中的第一个元素和最后一个元素的范围);迭代的对象要实现++和==的操作。
3、结语
今天这一讲是承接前面两篇文章的继承和补充,也是在学习C++我们需要掌握的基本概念及用法,在后面的章节中,我们将要开始C++中的类和对象环节,欢迎大家点赞、关注、支持!!!