目录
一、实验目的及要求:
实验目的:
- 掌握数据仓库Hive的安装和配置
- 掌握数据仓库工具Hive的安装和配置
实验要求:
- 完成Hive工具的安装和配置
- Hive工具能够正常启动运行
- Hive控制台命令能够正常使用
- 能够正常操作数据库、表、数据
二、环境要求:
- 一台独立PC机或虚拟机
- 每台主机内存2G以上,磁盘剩余空间500M以上
- 已安装CentOS 7.4操作系统
- 已安装 JDK
- 已完成MySQL数据库平台的搭建
- 已完成Hadoop平台的搭建
软件版本:
选用Hive的2.1.1版本,软件包名apache-hive-2.1.1-bin.tar.gz
依赖软件:
Hive工具使用JDBC方式连接MySQL数据库,需要用到MySQL数据库连接工具软件,选用该软件的5.1.42版本,软件包名mysql-connector-java-5.1.42-bin.jar
三、具体步骤:
1、Hive工具安装配置
(1)Hive工具安装配置
★Hive安装过程的所有操作步骤都需要使用admin用户进行。
★本项步骤只在集群中Cluster-01主机上进行操作即可。
1.把相关软件包apache-hive-2.1.1-bin.tar.gz和mysql-connector-java-5.1.42-bin.jar上传到admin用户家目录的新建“setups”目录下。
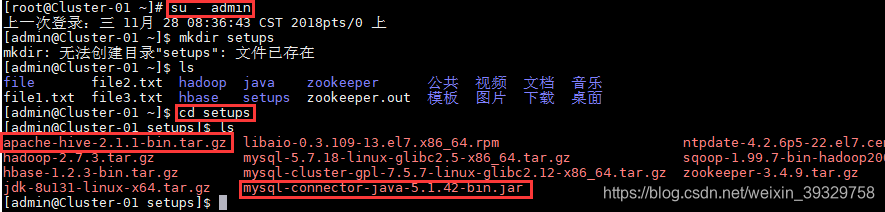
2.将软件包解压解包到“hive”目录下

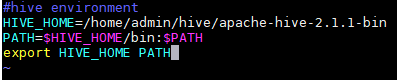
3.配置Hive相关的环境变量
★该路径以Hive软件包实际解压解包的路径为准
★确保此项输入正确,否则可能会导致所有命令无法使用
★必须按照前面的定义顺序书写
4.查看新添加和修改的环境变量是否设置成功,以及环境变量的值是否正确。
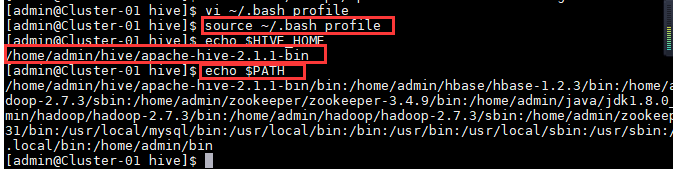
5.进入Hive的配置文件目录。
★Hive的配置文件默认都被命名为了模板文件,需要对其进行拷贝重命名之后才能使用:

6.对配置文件进行修改,找到相关配置项并对其值进行修改
找到配置项“HADOOP_HOME”,该项用于指定Hadoop所在的路径,将其值改为:
HADOOP_HOME=/home/admin/hadoop/hadoop-2.7.3
找到配置项“HIVE_CONF_DIR”,该项用于指定Hive的配置文件所在的路径,将其值改为:
export
HIVE_CONF_DIR=/home/admin/hive/apache-hive-2.1.1-bin/conf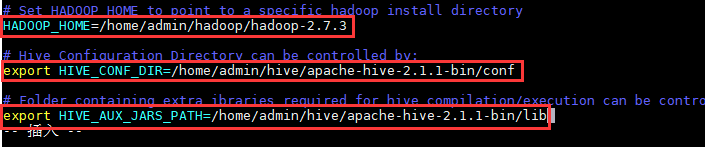
找到配置项“HIVE_AUX_JARS_PATH”,该项用于指定Hive的lib文件所在的路径,将其值改为:
export
HIVE_AUX_JARS_PATH=/home/admin/hive/apache-hive-2.1.1-bin/lib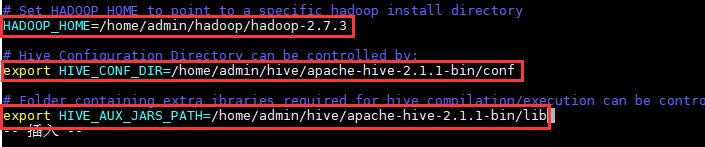
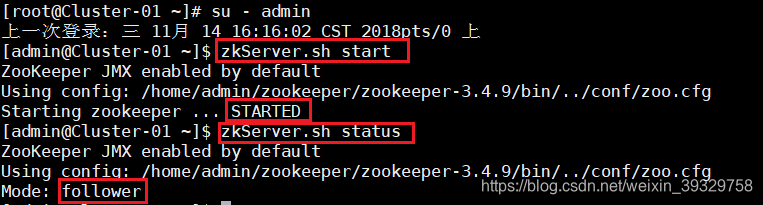
7.在集群中所有主机上使用命令“zkServer.sh status”查看该节点Zookeeper服务当前的状态,若集群中只有一个“leader”节点,其余的均为“follower”节点,则集群的工作状态正常。
如果Zookeeper未启动,则在集群中所有主机上使用命令“zkServer.sh start”启动Zookeeper服务的脚本。
★ 该项的所有操作步骤使用专门用于集群的用户admin进行。
★ 启动HBase集群之前首先确保Zookeeper集群已被开启状态。 (实验5台)Zookeeper的启动需要分别在每个计算机的节点上手动启动。如果家目录下执行启动报错,则需要进入zookeeper/bin目录执行启动命令。
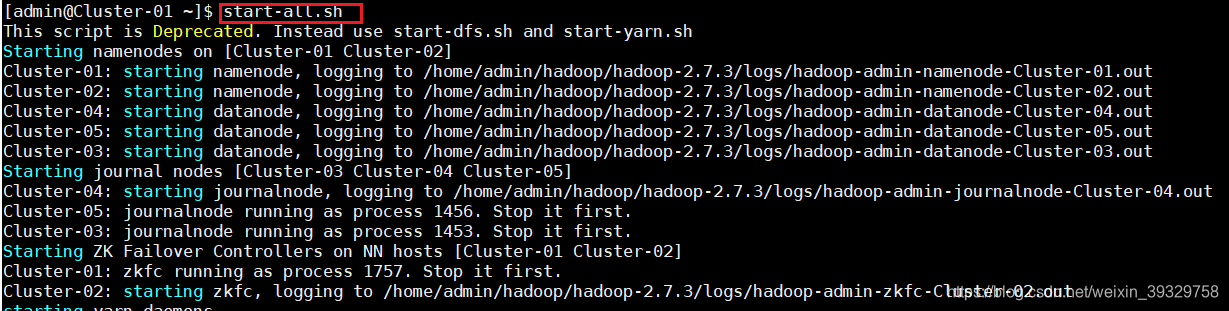
★ 启动HBase集群之前首先确保Hadoop集群已被开启状态。 (实验5台)Hadoop只需要在主节点执行启动命令。
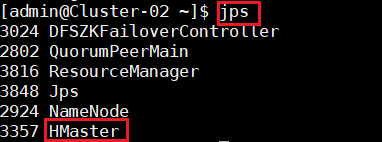
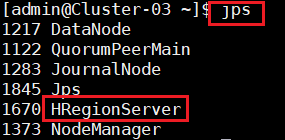
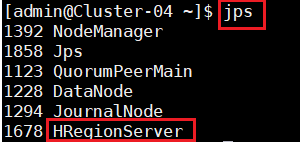
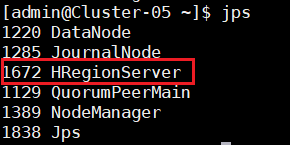
8.在主节点,查看Java进程信息,若有名为“NameNode”、“ResourceManager”的两个进程,则表示Hadoop集群的主节点启动成功。在每台数据节点,若有名为“DataNode”和“NodeManager”的两个进程,则表示Hadoop集群的数据节点启动成功。
如果不存在以上三个进程,则在主节点使用此命令,启动Hadoop集群。
9.确定Hadoop集群已启动状态,然后在主节点使用此命令,启动HBase集群。并在集群中所有主机上使用命令“jps”。

Cluster-01
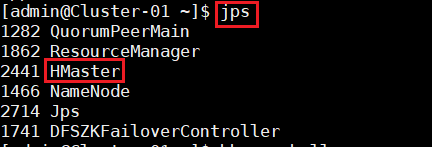
Cluster-02
Cluster-03
Cluster-04
Cluster-05
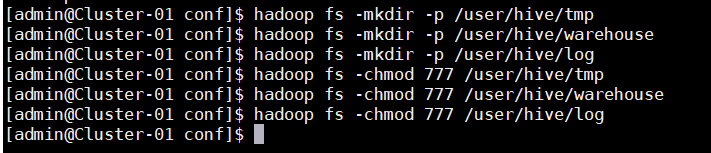
10.在HDFS中分别创建Hive的临时文件目录“tmp”
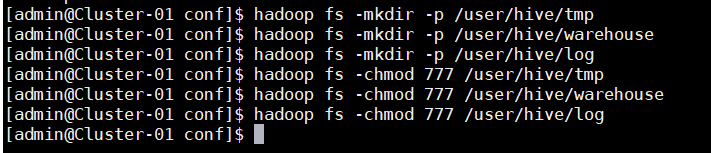
11.在HDFS中分别创建Hive的数据存储目录“warehouse”
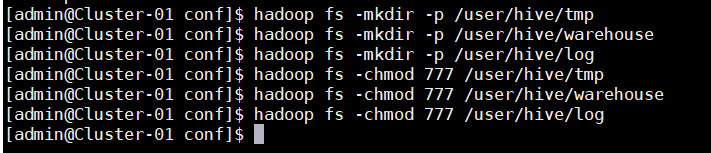
12.在HDFS中分别创建Hive的日志文件目录“log”
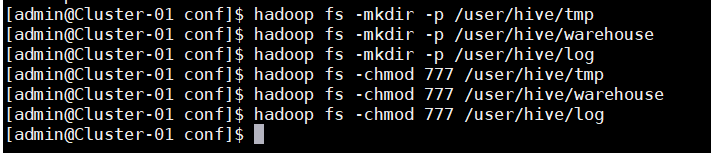
13.添加三个目录的用户组写权限
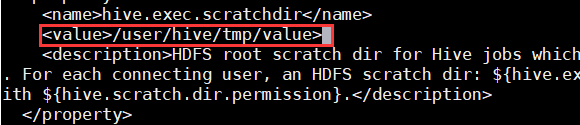
14.对配置文件hive-site.xml进行修改
★该文档内容较多,可以在编辑器内使用命令“/关键字”直接进行搜索,使用快捷键“n”可以切换到下一个关键字的所在位置。
![]()


启动mysql




(2)创建Hive元数据数据库
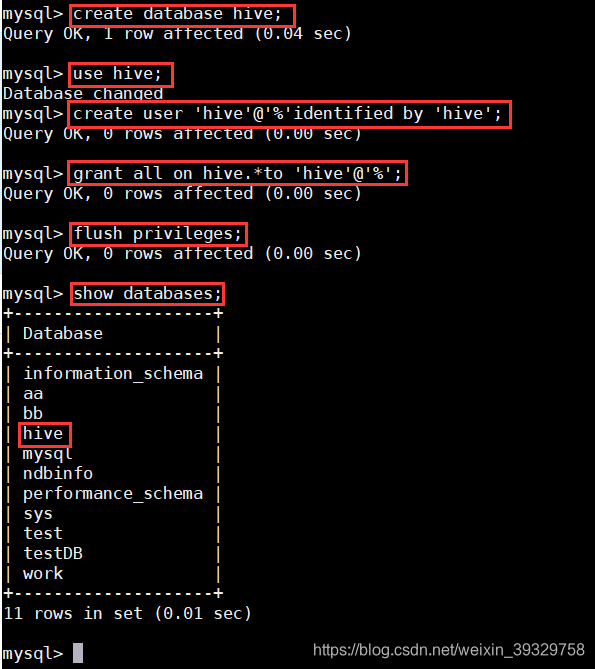
1. 在MySQL数据库SQL服务节点Cluster-04中创建一个数据库“hive”用于存放Hive的元数据,该数据库的用户名和密码均为“hive”,数据库名、用户名、密码均可以自行设定,但需要与Hive配置文件中的内容相对应,连接MySQL数据库:

2. 在控制台执行以下命令进行数据库的创建:
CREATE DATABASE hive;(创建数据库hive)
USE hive;(切换到新创建的hive数据库)
CREATE USER 'hive'@'%' IDENTIFIED BY 'hive';(创建数据库用户hive)
GRANT ALL ON hive.* TO 'hive'@'%';(设置hive数据库的访问权限,hive用户拥有所有操作权限并支持远程访问)
FLUSH PRIVILEGES;(刷新数据库权限信息)
show databases;
quit;(退出MySQL数据库控制台)
3. 在配置文件hive-site.xml添加MySQL连接的相关配置信息
★MySQL的配置信息hive-site.xml是在控制主机的admin用户下进行
![]()




4. 将MySQL的数据库连接工具包添加到Hive的“lib”目录下


5. 添加MySQL连接的相关配置信息
![]()
![]()
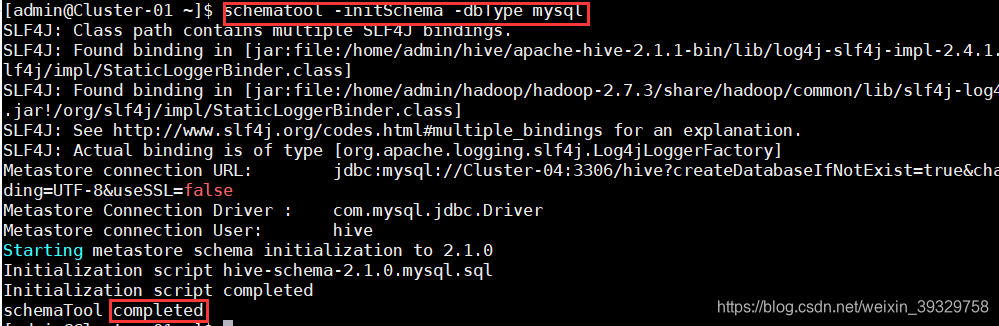
6. 对Hive进行初始化。
二、Hive工具启动和验证
★ Hive安装过程的所有操作步骤都需要使用admin用户进行。
★本项步骤只在集群中Cluster-01主机上进行操作即可。
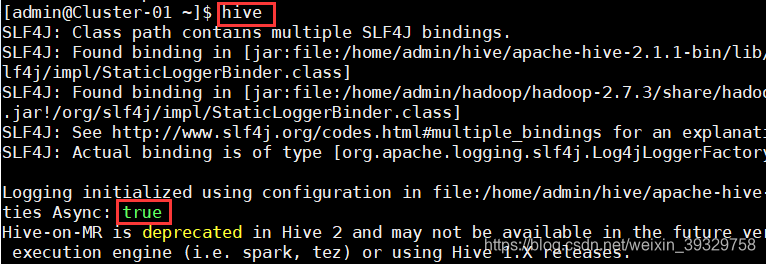
1. 使用命令“hive”启动Hive,启动成功后能够进入Hive的控制台。
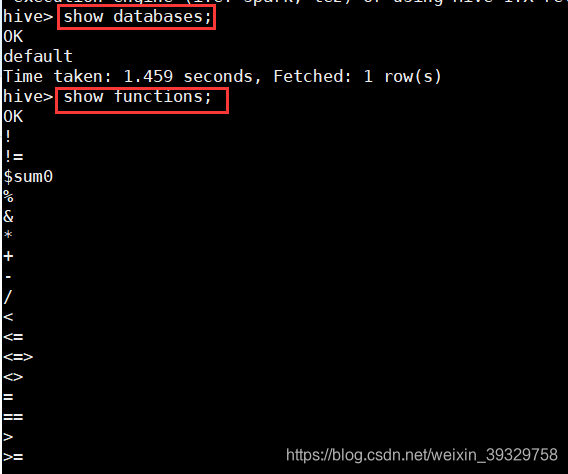
2. 在控制台中使用命令“show databases;”查看当前的数据库列表。
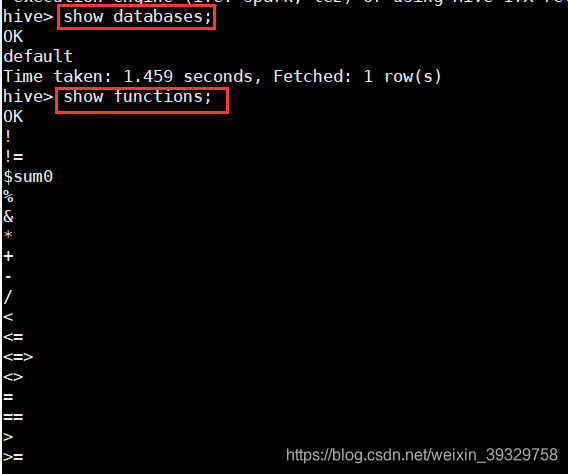
3. 在控制台中使用命令“show functions;”查看Hive的功能函数。
4. 在控制台中使用命令“desc function sum;”或“desc function extended sum;”查看Hive的功能函数的详细信息。
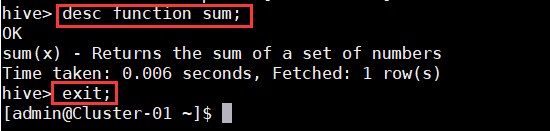
5. 在控制台中使用命令“quit;”或“exit;”退出Hive的控制台。
四:总结:
Hive由 Facebook 实现并开源
2、是基于 Hadoop 的一个数据仓库工具
3、可以将结构化的数据映射为一张数据库表
4、并提供 HQL(Hive SQL)查询功能
5、底层数据是存储在 HDFS 上
6、Hive的本质是将 SQL 语句转换为 MapReduce 任务运行
7、使不熟悉 MapReduce 的用户很方便地利用 HQL 处理和计算 HDFS 上的结构化的数据,适用于离线的批量数据计算。
数据仓库之父比尔·恩门(Bill Inmon)在 1991 年出版的“Building the Data Warehouse”(《建 立数据仓库》)一书中所提出的定义被广泛接受——数据仓库(Data Warehouse)是一个面 向主题的(Subject Oriented)、集成的(Integrated)、相对稳定的(Non-Volatile)、反映历史 变化(Time Variant)的数据集合,用于支持管理决策(Decision Making Support)。
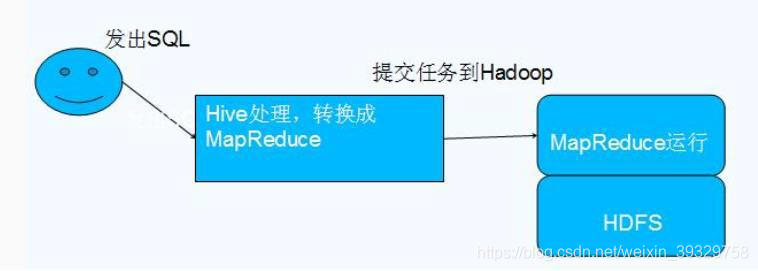
Hive 依赖于 HDFS 存储数据,Hive 将 HQL 转换成 MapReduce 执行,所以说 Hive 是基于 Hadoop 的一个数据仓库工具,实质就是一款基于 HDFS 的 MapReduce 计算框架,对存储在 HDFS 中的数据进行分析和管理。
Hive的优点:
1、可扩展性,横向扩展,Hive 可以自由的扩展集群的规模,一般情况下不需要重启服务 横向扩展:通过分担压力的方式扩展集群的规模 纵向扩展:一台服务器cpu i7-6700k 4核心8线程,8核心16线程,内存64G => 128G
2、延展性,Hive 支持自定义函数,用户可以根据自己的需求来实现自己的函数
3、良好的容错性,可以保障即使有节点出现问题,SQL 语句仍可完成执行
Hive的缺点:
1、Hive 不支持记录级别的增删改操作,但是用户可以通过查询生成新表或者将查询结 果导入到文件中(当前选择的 hive-2.3.2 的版本支持记录级别的插入操作)
2、Hive 的查询延时很严重,因为 MapReduce Job 的启动过程消耗很长时间,所以不能 用在交互查询系统中。
3、Hive 不支持事务(因为不没有增删改,所以主要用来做 OLAP(联机分析处理),而 不是 OLTP(联机事务处理),这就是数据处理的两大级别)。
Hive的架构:
