tensor的合并与分割

合并

tf.concat([a, b], axis = )
注:
(1)不创建新的维度;
(2)在哪个维度合并,哪个维度数量增加;其他维度必须相同。
a = tf.ones([4, 35, 8])
b = tf.ones([2, 35, 8])
c = tf.ones([4, 35, 8])
d = tf.concat([a, b], axis=0)
print(d.shape) # (6, 35, 8)
e = tf.concat([a, c], axis=-1)
print(e.shape) # (4, 35, 16)

tf.stack([a, b], axis = )
注意,会创建新的维度!
a = tf.ones([4, 35, 8])
b = tf.ones([4, 35, 8])
c = tf.stack([a, b], axis=0)
print(c.shape)
d = tf.stack([a, b], axis=-1)
print(d.shape) # (4, 35, 8, 2)
a、b的原始维度必须完全相同,否则报错:
a = tf.ones([4, 35, 8])
b = tf.ones([2, 35, 8])
c = tf.stack([a, b], axis=0)
print(c.shape)
# ensorflow.python.framework.errors_impl.InvalidArgumentError: Shapes of all inputs must match: values[0].shape = [4,35,8] != values[1].shape = [2,35,8] [Op:Pack] name: stack
分割
tf.unstack(a, axis = )
注意,返回一个list,list里面的内容是tensor
a = tf.ones([4, 35, 8])
b = tf.ones([4, 35, 8])
c = tf.stack([a, b], axis=0)
print(c.shape) # (2, 4, 35, 8)
d = tf.unstack(c, axis=0)
print(type(d)) # <class 'list'>
print(d[0].shape) # (4, 35, 8)
e = tf.unstack(c, axis=-1)
print(len(e)) # 8
print(e[0].shape) # (2, 4, 35) 范围e[0]~e[7]
tf.split(a, axis = , num_or_size_splits = )
a = tf.ones([4, 35, 8])
b = tf.ones([4, 35, 8])
c = tf.stack([a, b], axis=0)
print(c.shape) # (2, 4, 35, 8)
d = tf.split(c, axis=3, num_or_size_splits=2) # 分成两份
print(type(d)) # <class 'list'>
print(len(d)) # 2
print(d[0].shape) # (2, 4, 35, 4)
e = tf.split(c, axis=3, num_or_size_splits=[2, 2, 4])
print(e[0].shape) # (2, 4, 35, 2)
print(e[2].shape) # (2, 4, 35, 4)
数据统计

向量的范数:
tf.norm (范数)
a = tf.ones([2, 2])
print(tf.norm(a)) # tf.Tensor(2.0, shape=(), dtype=float32)
# 不指定几范数和轴,默认二范数
print(tf.sqrt(tf.reduce_sum(tf.square(a)))) # 同样的效果
a = tf.ones([2, 3])
b = tf.norm(a, ord=2, axis=1)
print(b.shape) # (2,) 指定列方向,结果为行数
a = tf.ones([2, 3])
b = tf.norm(a, ord=1, axis=0)
print(b) # tf.Tensor([2. 2. 2.], shape=(3,), dtype=float32)
reduce_min/max/mean
注:reduce表示降维的意思。
tf.reduce_min(a, axis = )
a = tf.random.normal([4, 10])
print(tf.reduce_max(a)) # 不指定轴,默认全局最大值(返回值仍然是一个tensor)
# tf.Tensor(2.6767023, shape=(), dtype=float32)
a = tf.random.normal([4, 10])
print(tf.reduce_max(a, axis=0).shape) # (10,)
print(tf.reduce_max(a, axis=1).shape) # (4,)
a = tf.constant([1])
print(a.shape) # (1,)
b = tf.constant([[1]])
print(b.shape) # (1, 1)
tf.argmax、tf.argmin
返回最大值、最小值的索引位置(默认axis = 0,结果与列数相等)。
a = tf.random.uniform([3, 4], maxval=10, dtype=tf.int32)
print(a)
print(tf.argmax(a)) # tf.Tensor([0 1 1 1], shape=(4,), dtype=int64) 默认即为axis=0,形状与列数相等
print(tf.argmax(a, axis=0).shape) # (4,)
print(tf.argmax(a, axis=1).shape) # (3,)
import tensorflow as tf
a = tf.random.uniform([3, 4], maxval=10, dtype=tf.int32)
print(a)
print(tf.argmax(a, axis=0))
运行结果:
tf.equal(a, b)
返回内容为布尔型的tensor
a = tf.constant([1, 2, 3, 2, 4])
b = tf.range(5)
print(tf.equal(a, b)) # tf.Tensor([False False False False True], shape=(5,), dtype=bool)
用以下方法可以求得相同元素的个数(准确率):
a = tf.constant([1, 2, 3, 2, 4])
b = tf.range(5)
c = tf.equal(a, b)
print(tf.reduce_sum(tf.cast(c, dtype=tf.int32)))
# tf.Tensor(1, shape=(), dtype=int32)
# 假设a为神经网络经过softmax得到的结果(如手写数字识别)
a = tf.constant([[0.1, 0.2, 0.7],
[0.9, 0.05, 0.05]])
pred = tf.cast(tf.argmax(a, axis=1), dtype=tf.int32)
# 实际标签y
y = tf.constant([2, 1])
# 计算准确率
eq = tf.equal(y, pred)
correct_number = tf.reduce_sum(tf.cast(eq, dtype=tf.int32))
correct = correct_number/2 # 总数为2
print(correct) # tf.Tensor(0.5, shape=(), dtype=float64)
print(correct.numpy()) # 0.5
tf.unique(a)
a必须是一维的!
获得不重复的数据(类似于求集合中的元素),结果为两部分,一部分是包含数据的tensor, 一部分包含可以用来恢复原始数据的索引的tensor。
a = tf.constant([[0.1, 0.2, 0.7],
[0.2, 0.05, 0.05]])
print(tf.unique(a))
# 报错 InvalidArgumentError: unique expects a 1D vector. [Op:Unique]
a = tf.constant([[0.1, 0.2, 0.7],
[0.2, 0.05, 0.05]])
a = tf.reshape(a, [-1])
prit(a.numpy())
print(tf.unique(a)) # 结果有两部分,数据和index
# Unique(y=<tf.Tensor: shape=(4,), dtype=float32, numpy=array([0.1 , 0.2 , 0.7 , 0.05], dtype=float32)>, idx=<tf.Tensor: shape=(6,), dtype=int32, numpy=array([0, 1, 2, 1, 3, 3])>)
a = tf.constant([[0.1, 0.2, 0.7],
[0.2, 0.05, 0.05]])
a = tf.reshape(a, [-1])
print(a.numpy()) # [0.1 0.2 0.7 0.2 0.05 0.05]
b = tf.unique(a)
print(type(b)) # <class'tensorflow.python.ops.gen_array_ops.Unique'>
print(b.numpy()) # AttributeError: 'Unique' object has no attribute 'numpy'
print(b[0]) # tf.Tensor([0.1 0.2 0.7 0.05], shape=(4,), dtype=float32)
print(b[1]) # tf.Tensor([0 1 2 1 3 3], shape=(6,), dtype=int32)
c = tf.gather(b[0], b[1])
print(c) # tf.Tensor([0.1 0.2 0.7 0.2 0.05 0.05], shape=(6,), dtype=float32)
d = tf.gather(b[0], b[1].numpy())
print(d) # tf.Tensor([0.1 0.2 0.7 0.2 0.05 0.05], shape=(6,), dtype=float32)
a = tf.random.uniform([2, 5, 4])
a = tf.reshape(a, [-1]) # 用此方法可以将任意维转化为一维
print(a.shape) # (40,)
张量排序

tf.sort (a, axis = -1, direction="")、tf.argsort (a, direction="")
a = tf.random.shuffle(tf.range(5))
print(a) # tf.Tensor([4 0 3 2 1], shape=(5,), dtype=int32)
b = tf.sort(a, direction="DESCENDING")
print(b) # tf.Tensor([4 3 2 1 0], shape=(5,), dtype=int32)
idx = tf.argsort(a, direction="DESCENDING")
print(idx) # tf.Tensor([0 2 3 4 1], shape=(5,), dtype=int32)
c = tf.gather(a, idx)
print(c) # tf.Tensor([4 3 2 1 0], shape=(5,), dtype=int32)
对矩阵排序:
a = tf.random.uniform([3, 3], maxval=10, dtype=tf.int32)
print(a.numpy())
# [[9 9 8]
# [5 0 3]
# [2 9 5]]
b = tf.sort(a)
print(b.numpy()) # 对矩阵,默认对行升序排列
# [[8 9 9]
# [0 3 5]
# [2 5 9]]
c = tf.sort(a, direction="DESCENDING")
print(c.numpy())
# [[9 9 8]
# [5 3 0]
# [9 5 2]]
ind = tf.argsort(a)
print(ind.numpy())
# [[2 1 0]
# [1 0 2]
# [1 2 0]]
tf.math.top_k (a, k)
a = tf.random.uniform([2, 3], maxval=10, dtype=tf.int32)
print(a.numpy())
# [[6 8 0]
# [7 9 2]]
res = tf.math.top_k(a, 2) # 依然是按行
print(res.values)
# tf.Tensor(
# [[8 6]
# [9 7]], shape=(2, 2), dtype=int32)
print(res.indices)
# tf.Tensor(
# [[1 0]
# [1 0]], shape=(2, 2), dtype=int32)

prob = tf.constant([[0.1, 0.2, 0.7], [0.2, 0.7, 0.1]])
target = tf.constant([2, 0])
k_b = tf.math.top_k(prob, 1).indices
print(k_b)
k_b = tf.transpose(k_b, [1, 0])
print(k_b)
target = tf.broadcast_to(target, [1, 2])
correct_bool = tf.equal(k_b, target)
correct_num = tf.cast(correct_bool, dtype=tf.int32)
result = tf.reduce_sum(correct_num)/2
print(result) # tf.Tensor(0.5, shape=(), dtype=float64)
填充与复制

tf.pad(a, [[行维度上,下],[列维度左,右]])


a = tf.reshape(tf.range(9), [3, 3])
print(a.numpy())
# [[0 1 2]
# [3 4 5]
# [6 7 8]]
b = tf.pad(a, [[1, 0], [0, 1]])
print(b.numpy())
# [[0 0 0 0]
# [0 1 2 0]
# [3 4 5 0]
# [6 7 8 0]]
Image padding:
a = tf.random.normal([4, 28, 28, 3])
b = tf.pad(a, [[0, 0], [2, 2], [2, 2], [0, 0]])
print(b.shape) # (4, 32, 32, 3)
tf.tile(a, [维度1复制倍数, 维度2复制倍数,……])

a = tf.reshape(tf.range(8), [2, 4])
print(a.numpy())
# [[0 1 2 3]
# [4 5 6 7]]
b = tf.tile(a, [1, 2])
print(b.numpy())
# [[0 1 2 3 0 1 2 3]
# [4 5 6 7 4 5 6 7]]
c = tf.tile(a, [2, 1])
print(c.numpy())
# [[0 1 2 3]
# [4 5 6 7]
# [0 1 2 3]
# [4 5 6 7]]
tf.tile 和 tf.broadcast_to() 都能实现复制,但是broadcast只在运行时复制,不占用内存,性能更好。
a.shape为(1, 3, 3)
tf.tile(a, [2, 1, 1])的效果与tf.broadcast_to(a, [2, 3, 3])相同。
张量限幅

tf.clip_by_value(a, min, max)
a = tf.range(10)
b = tf.maximum(a, 2) # 取两者中的大值
print(b.numpy()) # [2 2 2 3 4 5 6 7 8 9]
c = tf.minimum(a, 8)
print(c.numpy()) # [0 1 2 3 4 5 6 7 8 8]
d = tf.clip_by_value(a, 2, 8) # 将值限制在2~8之间(比2小的变为2,比8大的变为8)
print(d.numpy()) # [2 2 2 3 4 5 6 7 8 8]
实现relu函数(即y = max(0, x)):
a = tf.range(10)
a = a-5
print(tf.nn.relu(a).numpy()) # [0 0 0 0 0 0 1 2 3 4]
print(tf.maximum(a, 0).numpy()) # [0 0 0 0 0 0 1 2 3 4]
tf.clip_by_norm(a, 15)
将a的二阶范数限制为15.
a = tf.random.normal([2, 2], mean=10)
print(tf.norm(a)) # tf.Tensor(20.621208, shape=(), dtype=float32)
b = tf.clip_by_norm(a, 15)
print(tf.norm(b)) # tf.Tensor(14.999999, shape=(), dtype=float32)
tf.clip_by_global_norm(grads, 15)
-----Gradient Clippping
a = tf.Variable(1.)
b = tf.Variable(2.)
with tf.GradientTape() as tape:
y = a**2 + b**2
grad = tape.gradient(y, [a, b])
print(type(grad)) # <class 'list'>
print(grad) # [<tf.Tensor: shape=(), dtype=float32, numpy=2.0>, <tf.Tensor: shape=(), dtype=float32, numpy=4.0>]
函数源代码(ctrl+b):

a = tf.Variable(6.)
b = tf.Variable(8.)
with tf.GradientTape() as tape:
y = a**2 + b**2
grads = tape.gradient(y, [a, b])
print(grads)
print("after")
grads = tf.clip_by_global_norm(grads, 10)
print(grads)
for g in grads:
print(tf.norm(g))
运行结果:
修正:
a = tf.Variable(6.)
b = tf.Variable(8.)
with tf.GradientTape() as tape:
y = a**2 + b**2
grads= tape.gradient(y, [a, b])
print(grads)
print("after")
grads, _ = tf.clip_by_global_norm(grads, 5)
print(grads)
for g in grads:
print(tf.norm(g))

其他高阶操作

tf.where(mask)

a = tf.random.normal([3, 3])
mask = a > 0
print(mask)
b = tf.boolean_mask(a, mask)
print(b)
运行结果:
a = tf.random.normal([3, 3])
mask = a > 0
print(mask)
indices = tf.where(mask)
print(indices)
b = tf.gather_nd(a, indices)
print(b)
运行结果:
tf.where(cond, A, B)
mask = tf.cast(tf.random.uniform([3,3], minval=-2, maxval=3, dtype=tf.int32), dtype=tf.bool)
print(mask)
a = tf.ones([3, 3])
b = tf.zeros([3, 3])
# mask中true从a中对应位置取值,false从b中对应位置取值
c = tf.where(mask, a, b)
print(c)


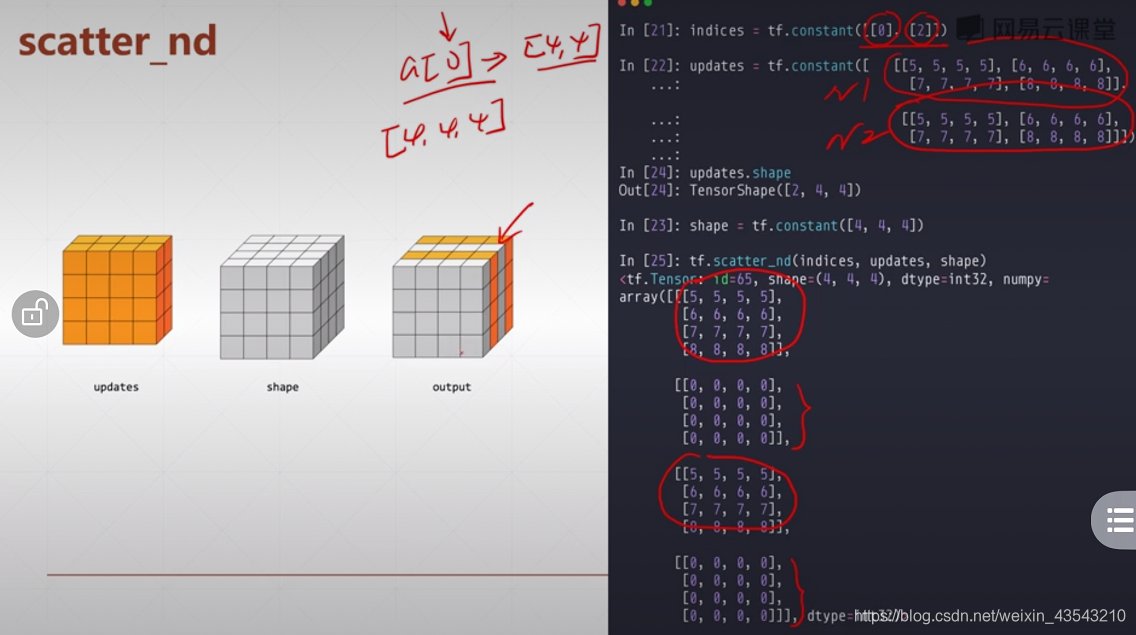
tf.scatter_nd(indices, updates, shape)
默认基底shape为全零
indices = tf.constant([[4], [3], [1], [7]])
updates = tf.constant([9, 10, 11, 12])
shape = tf.constant([8])
result = tf.scatter_nd(indices, updates, shape)
print(result) # tf.Tensor([ 0 11 0 10 9 0 0 12], shape=(8,), dtype=int32)

tf.meshgrid(x, y)




y = tf.linspace(-2., 2, 5) # 浮点型,否则报错
print(y) # tf.Tensor([-2. -1. 0. 1. 2.], shape=(5,), dtype=float32)
x = tf.linspace(-2., 2, 5)
points_x, points_y = tf.meshgrid(x, y)
print(points_x)
# tf.Tensor(
#[[-2. -1. 0. 1. 2.]
# [-2. -1. 0. 1. 2.]
# [-2. -1. 0. 1. 2.]
# [-2. -1. 0. 1. 2.]
# [-2. -1. 0. 1. 2.]], shape=(5, 5), dtype=float32)
print(points_y)
# tf.Tensor(
#[[-2. -2. -2. -2. -2.]
# [-1. -1. -1. -1. -1.]
# [ 0. 0. 0. 0. 0.]
# [ 1. 1. 1. 1. 1.]
# [ 2. 2. 2. 2. 2.]], shape=(5, 5), dtype=float32)
points = tf.stack([points_x, points_y], axis=2)
print(points.shape) # (5, 5, 2)
print(points) # 变成坐标

例: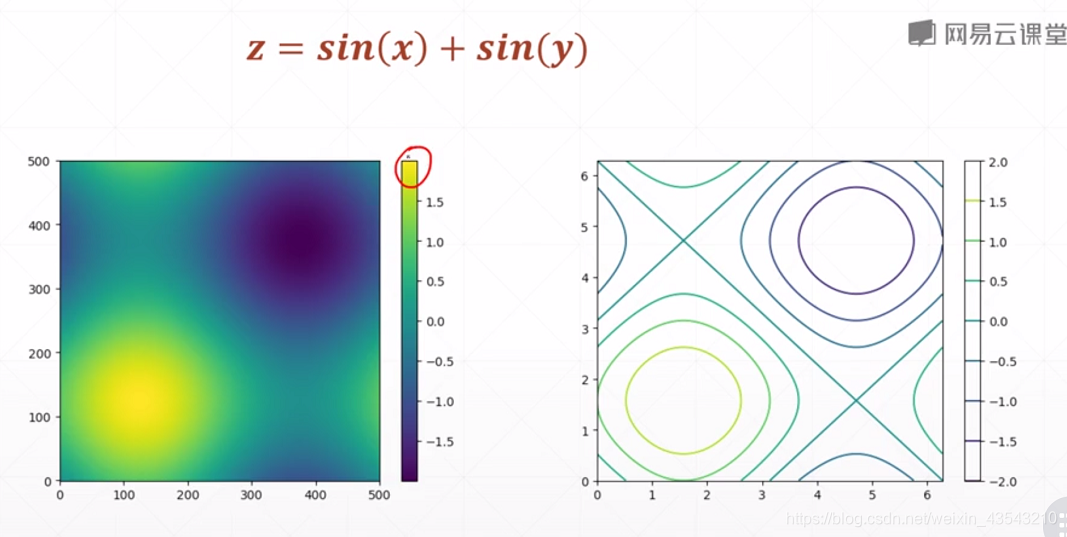
import tensorflow as tf
import matplotlib.pyplot as plt
def func(x):
z = tf.math.sin(x[..., 0]) + tf.math.sin(x[..., 1])
return z
if __name__ == '__main__':
x = tf.linspace(0., 2 * 3.14, 500)
y = tf.linspace(0., 2 * 3.14, 500)
point_x, point_y = tf.meshgrid(x, y)
points = tf.stack([point_x, point_y], axis=2) # [50, 50, 2 ]
z = func(points)
print(z.shape) # (500,500)
plt.figure('plot 2d func value')
plt.imshow(z, origin='lower', interpolation='none')
plt.colorbar()
plt.figure('plot 2d func contour')
plt.contour(point_x, point_y, z)
plt.colorbar()
plt.show()
版权声明:本文为weixin_43543210原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。