参考:http://yli17.cn/LcNQ0
特点
- 是一个高效而强大的目标检测网咯。它使我们每个人都可以使用 GTX 1080Ti 或 2080Ti 的GPU来训练一个超快速和精确的目标检测器。这对于买不起高性能显卡的我们来说,简直是个福音!
- 在论文中,验证了大量先进的技巧对目标检测性能的影响,真的是非常良心!
- 对当前先进的目标检测方法进行了改进,使之更有效,并且更适合在单GPU上训练;这些改进包括CBN、PAN、SAM等。
网络结构
最简单清晰的表示: YOLOv4 = CSPDarknet53(主干) + SPP附加模块(颈) + PANet路径聚合(颈) + YOLOv3(头部)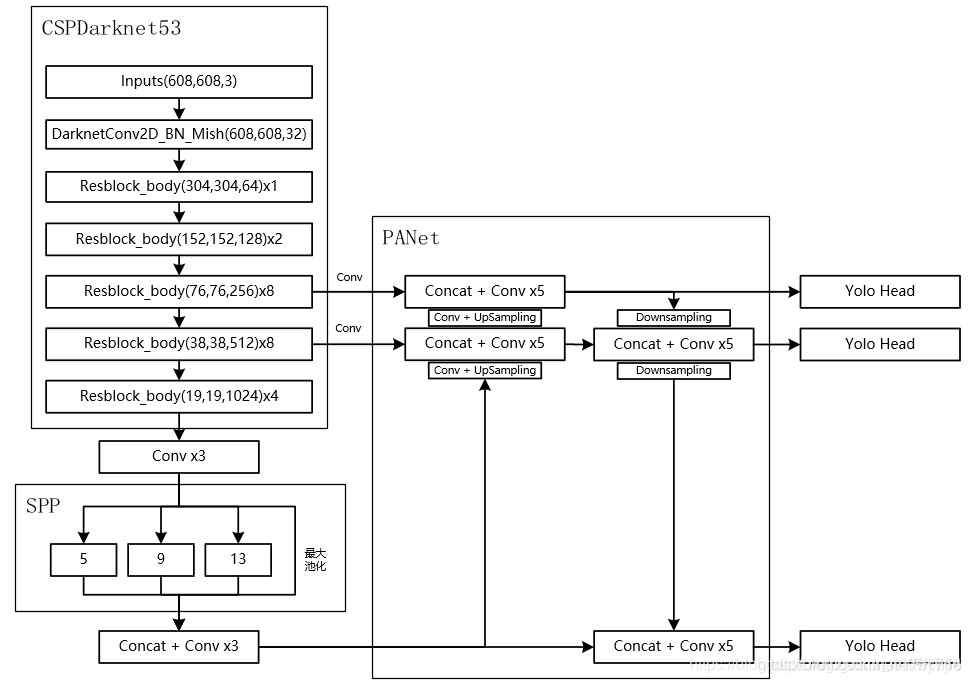
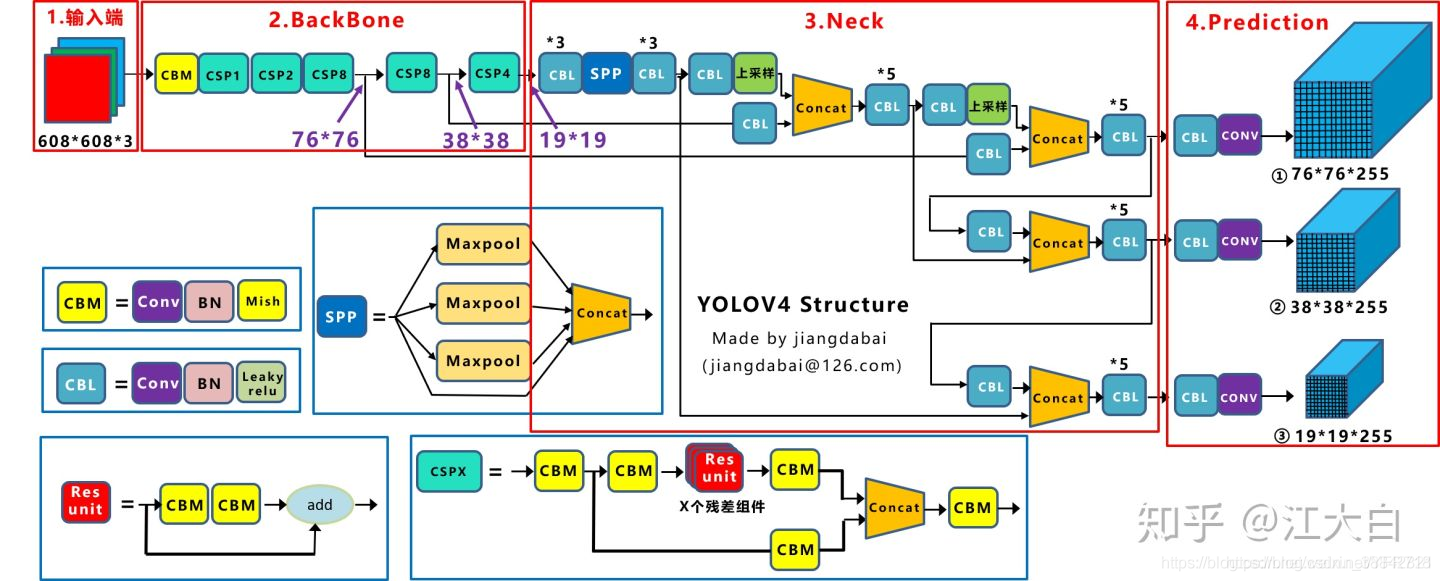
在YOLOv4中,将原来的Darknet53结构换为了CSPDarknet53,这在原来的基础上主要进行了两项改变:
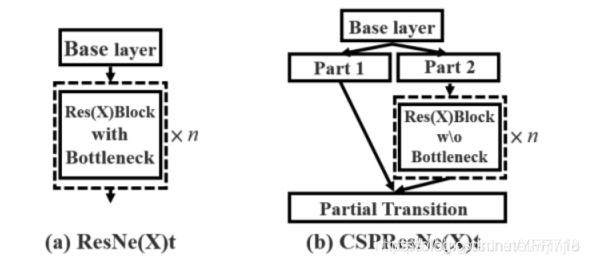
- 将原来的Darknet53与CSPNet进行结合。进行结合后,CSPnet的主要工作就是将原来的残差块的堆叠进行拆分,把它拆分成左右两部分:主干部分继续堆叠原来的残差块,支路部分则相当于一个残差边,经过少量处理直接连接到最后。具体结构如下:
使用MIsh激活函数代替了原来的Leaky ReLU。在YOLOv3中,每个卷积层之后包含一个批量归一化层和一个Leaky ReLU。而在YOLOv4的主干网络CSPDarknet53中,使用Mish代替了原来的Leaky ReLU。Leaky ReLU和Mish激活函数的公式与图像如下: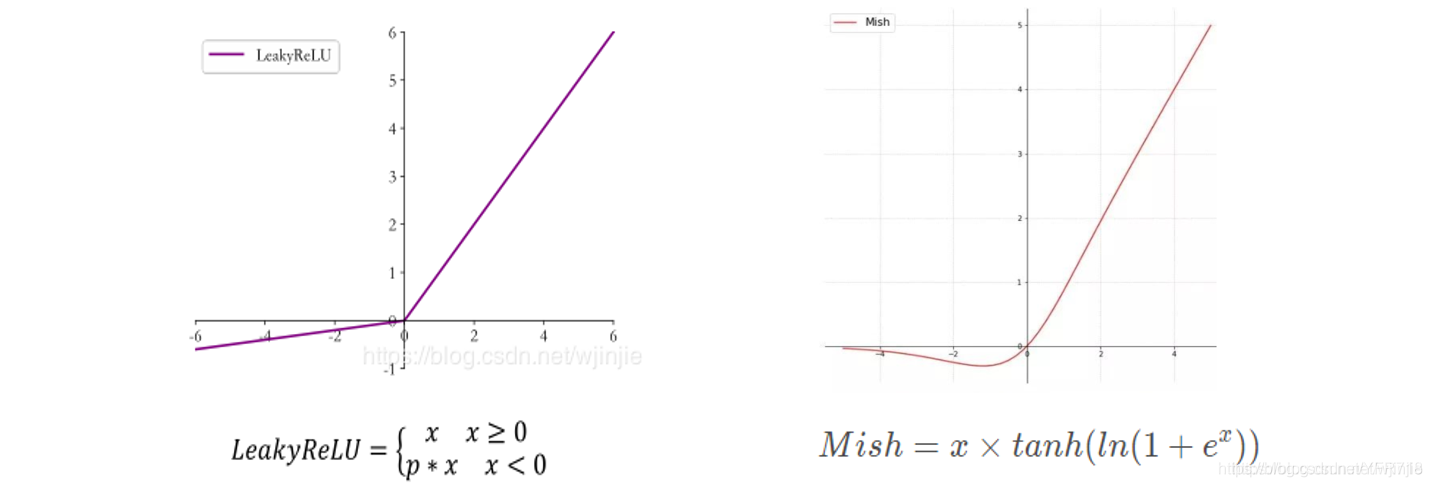
SPP
SPP最初的设计目的是用来使卷积神经网络不受固定输入尺寸的限制。在YOLOv4中,作者引入SPP,是因为它显著地增加了感受野,分离出了最重要的上下文特征,并且几乎不会降低的YOLOv4运行速度。如下图所示,就是SPP中经典的空间金字塔池化层。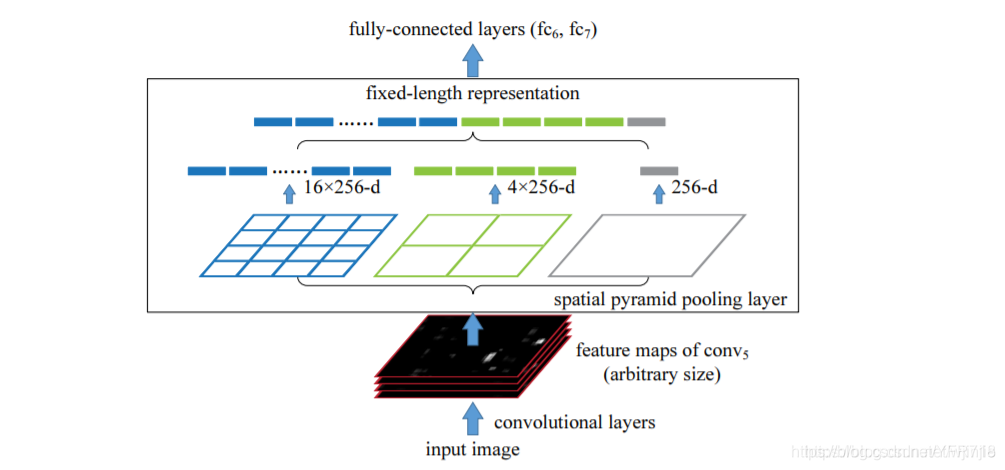
在YOLOv4中,具体的做法就是:分别利用四个不同尺度的最大池化对上层输出的feature map进行处理。最大池化的池化核大小分别为13x13、9x9、5x5、1x1,其中1x1就相当于不处理。
PANet
PANet整体上可以看做是在Mask R-CNN上做多处改进,充分利用了特征融合,比如引入Bottom-up path augmentation结构,充分利用网络浅特征进行分割;引入Adaptive feature pooling使得提取到的ROI特征更加丰富;引入Fully-conneFcted fusion,通过融合一个前背景二分类支路的输出得到更加精确的分割结果。
下图是PANet的示意图,主要包含FPN、Bottom-up path augmentation、Adaptive feature pooling、Fully-connected fusion四个部分。
- FPN发表于CVPR2017,主要是通过融合高低层特征提升目标检测的效果,尤其可以提高小尺寸目标的检测效果。
- Bottom-up Path Augmentation的引入主要是考虑网络浅层特征信息对于实例分割非常重要,因为浅层特征一般是边缘形状等特征。
- Adaptive Feature Pooling用来特征融合。也就是用每个ROI提取不同层的特征来做融合,这对于提升模型效果显然是有利无害。
- Fully-connected Fusion是针对原有的分割支路(FCN)引入一个前背景二分类的全连接支路,通过融合这两条支路的输出得到更加精确的分割结果。
在YOLOv4中,作者使用PANet代替YOLOv3中的FPN作为参数聚合的方法,针对不同的检测器级别从不同的主干层进行参数聚合。并且对原PANet方法进行了修改, 使用张量连接(concat)代替了原来的捷径连接(shortcut connection)。
YOLOv3 Head
在YOLOv4中,继承了YOLOv3的Head进行多尺度预测,提高了对不同size目标的检测性能。YOLOv3的完整结构在上文已经详细介绍,下面我们截取了YOLOv3的Head进行分析: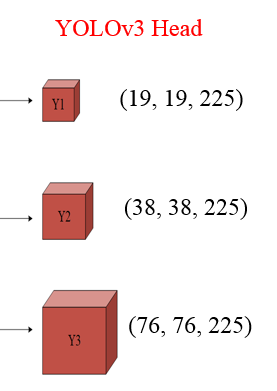

各种Tricks总结
作者将所有的Tricks可以分为两类:
- 在不增加推理成本的前提下获得更好的精度,而只改变训练策略或只增加训练成本的方- 法,作着称之为 “免费包”(Bag of freebies);
- 只增加少量推理成本但能显著提高目标检测精度的插件模块和后处理方法,称之为“特价包”(Bag of specials)
下面分别对这两类技巧进行介绍。
(1)免费包
以数据增强方法为例,虽然增加了训练时间,但不增加推理时间,并且能让模型泛化性能和鲁棒性更好。像这种不增加推理成本,还能提升模型性能的方法,作者称之为"免费包",非常形象。下面总结了一些常用的数据增强方法:
随机缩放
翻转、旋转
图像扰动、加噪声、遮挡
改变亮度、对比对、饱和度、色调
随机裁剪(random crop)
随机擦除(random erase)
Cutout
MixUp
CutMix
常见的正则化方法有:DropOut
DropConnect
DropBlock
平衡正负样本的方法有:Focal loss
OHEM(在线难分样本挖掘)
除此之外,还有回归 损失方面的改进:GIOU
DIOU
CIoU
(2)特价包
增大感受野技巧:SPP
ASPP
RFB
注意力机制:Squeeze-and-Excitation (SE)
Spatial Attention Module (SAM)
特征融合集成:FPN
SFAM
ASFF
BiFPN (出自于大名鼎鼎的EfficientDet)
更好的激活函数:ReLU
LReLU
PReLU
ReLU6
SELU
Swish
hard-Swish
后处理非极大值抑制算法:soft-NMS
DIoU NMS
改进方法
已经提到的各种Tricks,为了使目标检测器更容易在单GPU上训练,作者也提出了5种改进方法:
(1)Mosaic
这是作者提出的一种新的数据增强方法,该方法借鉴了CutMix数据增强方式的思想。CutMix数据增强方式利用两张图片进行拼接,但是Mosaic使利用四张图片进行拼接。如下图所示:
Mosaic数据增强方法有一个优点:拥有丰富检测目标的背景,并且在BN计算的时候一次性会处理四张图片!
(2)SAT
SAT是一种自对抗训练数据增强方法,这一种新的对抗性训练方式。在第一阶段,神经网络改变原始图像而不改变网络权值。以这种方式,神经网络对自身进行对抗性攻击,改变原始图像,以制造图像上没有所需对象的欺骗。在第二阶段,用正常的方法训练神经网络去检测目标。
(3)CmBN
CmBN的全称是Cross mini-Batch Normalization,定义为跨小批量标准化(CmBN)。CmBN 是 CBN 的改进版本,它用来收集一个batch内多个mini-batch内的统计数据。BN、CBN和CmBN之间的区别具体如下图所示:
(4)修改过的SAM
作者在原SAM(Spatial Attention Module)方法上进行了修改,将SAM从空间注意修改为点注意。如下图所示,对于常规的SAM,最大值池化层和平均池化层分别作用于输入的feature map,得到两组shape相同的feature map,再将结果输入到一个卷积层,接着是一个 Sigmoid 函数来创建空间注意力。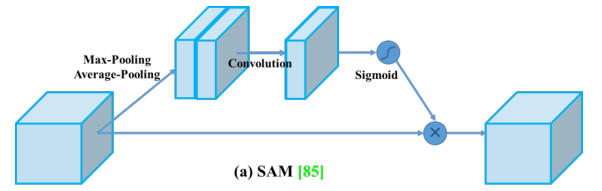
将SAM(Spatial Attention Module)应用于输入特征,能够输出精细的特征图。
在YOLOv4中,对原来的SAM方法进行了修改。如下图所示,修改后的SAM直接使用一个卷积层作用于输入特征,得到输出特征,然后再使用一个Sigmoid 函数来创建注意力。作者认为,采用这种方式创建的是点注意力。
(5)修改过的PAN
作者对原PAN(Path Aggregation Network)方法进行了修改, 使用张量连接(concat)代替了原来的快捷连接(shortcut connection)。如下图所示: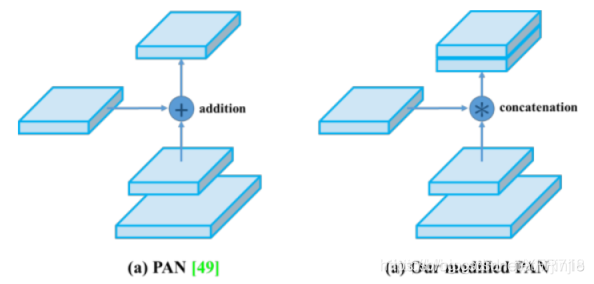
注:想具体了解原PANet网络结构,可参考上文中的PANet介绍部分。
4.5 性能表现
如下图所示,在COCO目标检测数据集上,对当前各种先进的目标检测器进行了测试。可以发现,YOLOv4的检测速度比EfficientDet快两倍,性能相当。同时,将YOLOv3的AP和FPS分别提高10%和12%,吊打YOLOv3!
综合以上分析,总结出YOLOv4带给我们的优点有:
- 与其它先进的检测器相比,对于同样的精度,YOLOv4更快(FPS);对于同样的速度,YOLOv4更准(AP)。
- YOLOv4能在普通的GPU上训练和使用,比如GTX 1080Ti和GTX 2080Ti等。
- 论文中总结了各种Tricks(包括各种BoF和BoS),给我们启示,选择合适的Tricks来提高自己的检测器性能。