分析
爬取地址:https://www.58pic.com/piccate/10-0-0-p1.html
可以看出p1、p2代表页数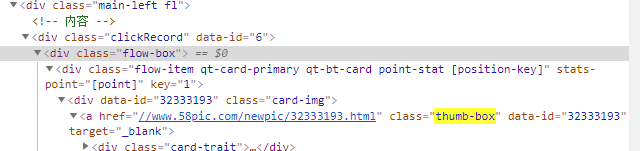
详情页在class="thumb-box"元素里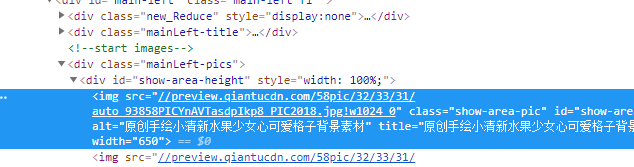
具体图片在class="show-area-pic"里
数据库创建
import pymysql
db = pymysql.connect('localhost','root','','_pro')
cursor = db.cursor()
cursor.execute('drop table if exists pageTable')
cursor.execute('''CREATE TABLE `pageTable` (
`num` int NOT NULL AUTO_INCREMENT ,
`title` varchar(255) NOT NULL ,
`md5` varchar(255) NOT NULL ,
PRIMARY KEY (`num`)
);
''')
db.close()
爬虫代码
import requests
from lxml import etree
import pymysql
import hashlib
from multiprocessing.pool import Pool
import os,time
from PIL import Image
import numpy as np
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36',
'Referer':'https://www.58pic.com/piccate/10-0-0-p1.html',
}
def get_html(url):
'''下载网页代码'''
html = requests.get(url,headers).text
return html
def get_page_url(data):
'''提取详情页url'''
html = etree.HTML(data)
url_list = html.xpath('//a[@class="thumb-box"]/@href')
#print(url_list)
return url_list
def get_img_url(data):
'''提取高清大图url'''
html = etree.HTML(data)
url = html.xpath('//img[@class="show-area-pic"]/@src')[0]
title = html.xpath('//img[@class="show-area-pic"]/@title')[0]+'.jpg'
#print('get img success')
return url,title
def insert_data(file,md5):
'''存数据'''
db = pymysql.connect('localhost', 'root', '', '_pro')
cursor = db.cursor()
data = [file,md5]
cursor.execute('insert into pagetable(title,md5) values (%s,%s)',data)
db.commit()
db.close()
def get_img(url,file):
'''下载图片'''
file_name = r'picture/'+file
img = requests.get(url,headers=headers).content
with open (file_name,'wb') as save_img:
save_img.write(img)
fd = np.array(Image.open(file_name)) * np.random.randint(10)
fmd5 = hashlib.md5(fd)
md5 = fmd5.hexdigest()
insert_data(file,md5)
def sp(m):
'''爬虫'''
for i in range(1,m+1):
main_url = 'https://www.58pic.com/piccate/10-0-0-p{}.html'.format(m)
html = get_html(main_url)
#print(html)
url_list = get_page_url(html)
for url in url_list:
html = get_html('http:'+url)
img_url,img_title = get_img_url(html)
get_img('http:'+img_url,img_title)
print ('正在下载{}'.format(img_title))
time.sleep(10)
if __name__ == '__main__':
m = int(input('输入爬取页数:'))
# p = Pool(1)
# n = list(range(1,1+m))
# p.map(sp,n)
sp(m)
结果截图
这里我爬取了5页数据
版权声明:本文为qq_40386321原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。