首先urllib库是爬虫中用到的比较多的一个库,也算是比较基础的一个库,对于入门来说,urllib是蛮重要的。后面会介绍一下requests的使用。
1、urllib的介绍
按我的理解来说,要想爬取到网页中想要的东西,首先必须要爬取到网页的源码。只有爬取到了网站的源码,才能进行下一步的操作——对源码进行解析。解析完之后,才可以得到爬取到的数据。
而urllib对于初学者来说,爬取一般网页的源码来说是比较容易的。为什么说是一般?因为对于初学者来说,找到网页的接口是比较难的,特别是一般大型网站的接口特别难找。下面我来放两张图对比一下。
图一: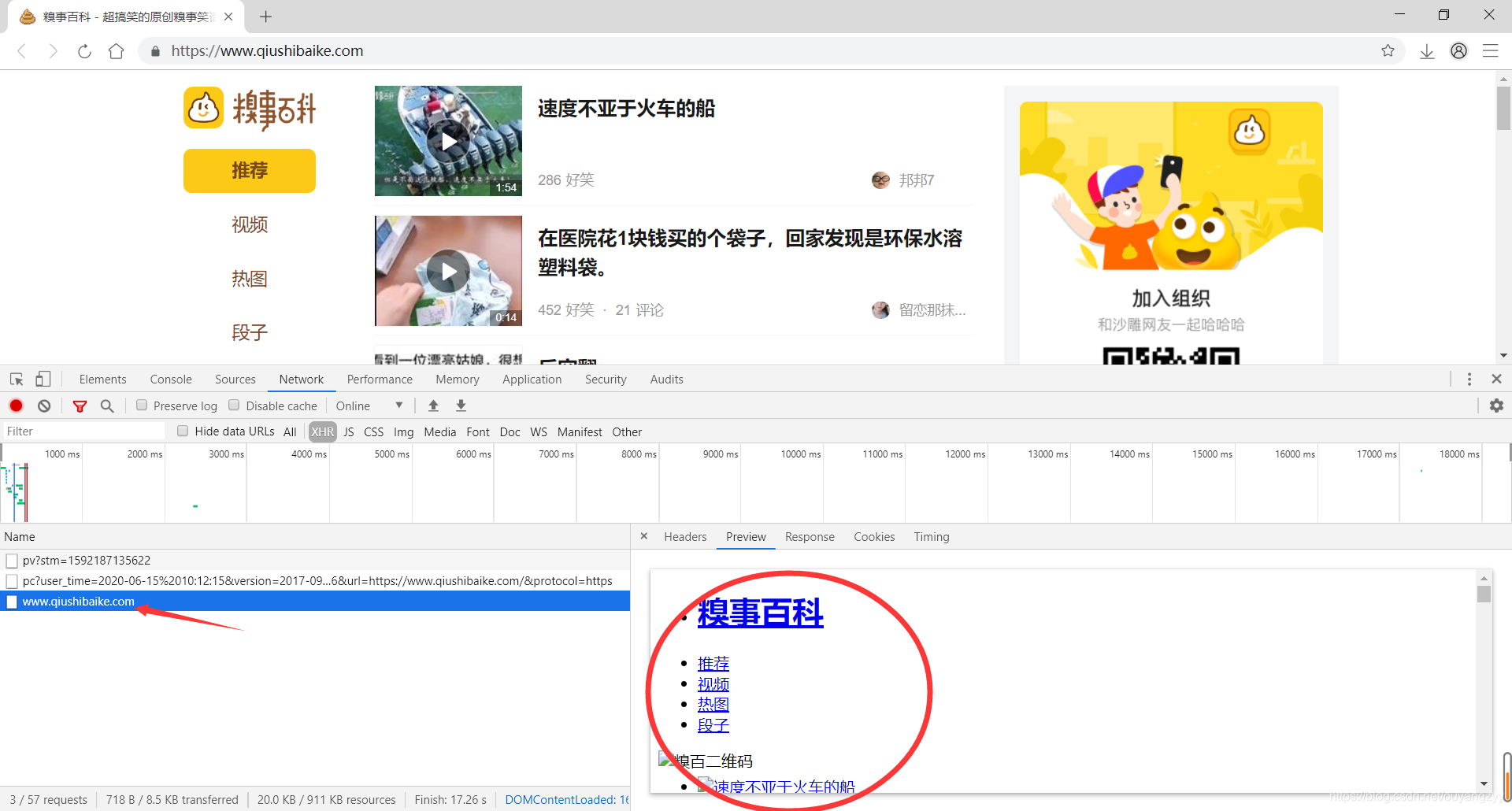
这是比较容易找到网站页面,能够从图中看出页面是直接显示出来的。我这里访问的是“糗事百科”。
图二: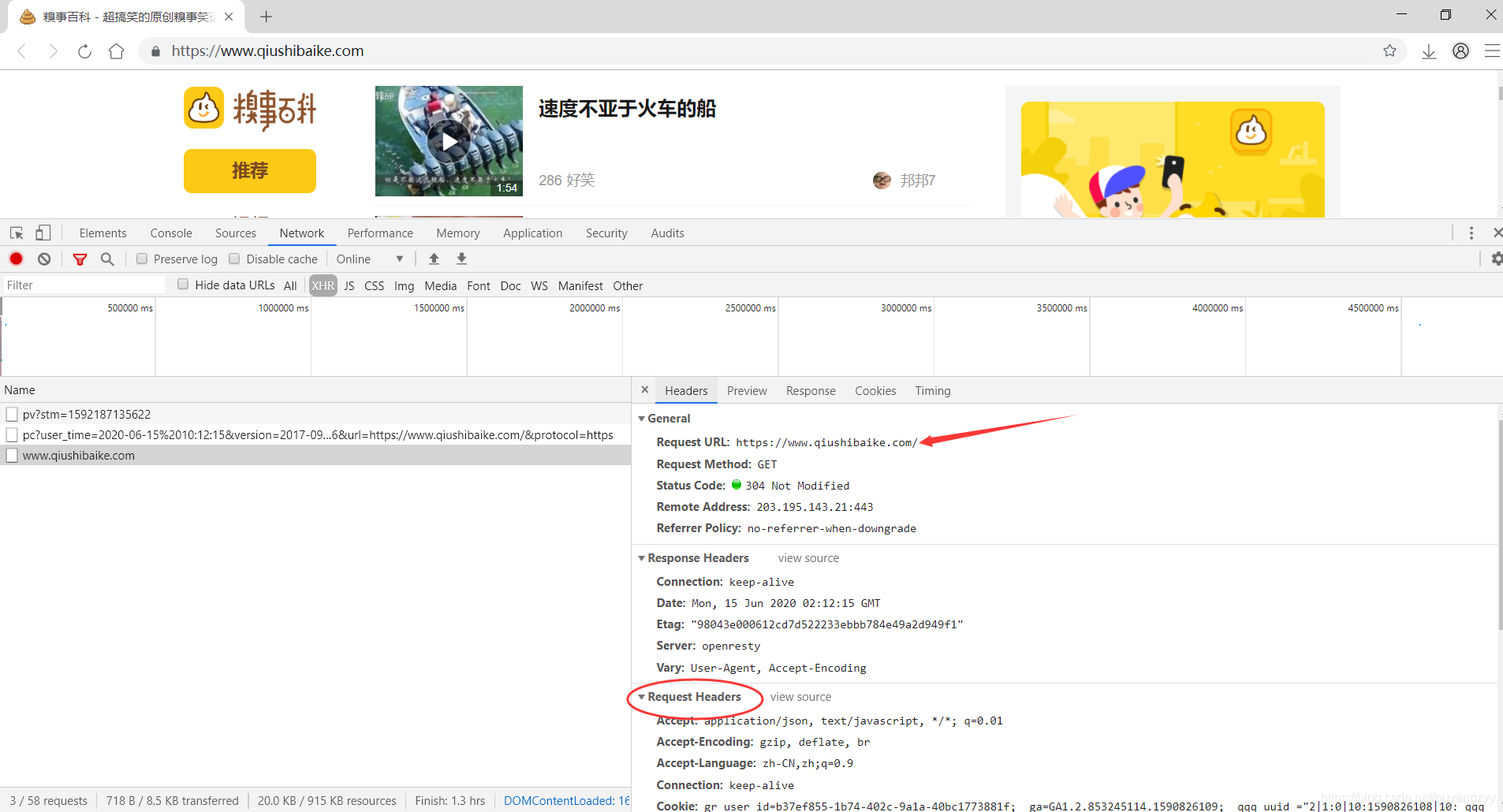
从这张图中可以获取我们需要的URL,所谓的URL,就是访问这个地址就可以跳转到页面。而下面的Request Headers也是需要的。从接口中主要获取的就是URL和Headers。而这个一般来说对于新手是比较难找的,因为找不到网站的页面。
图三: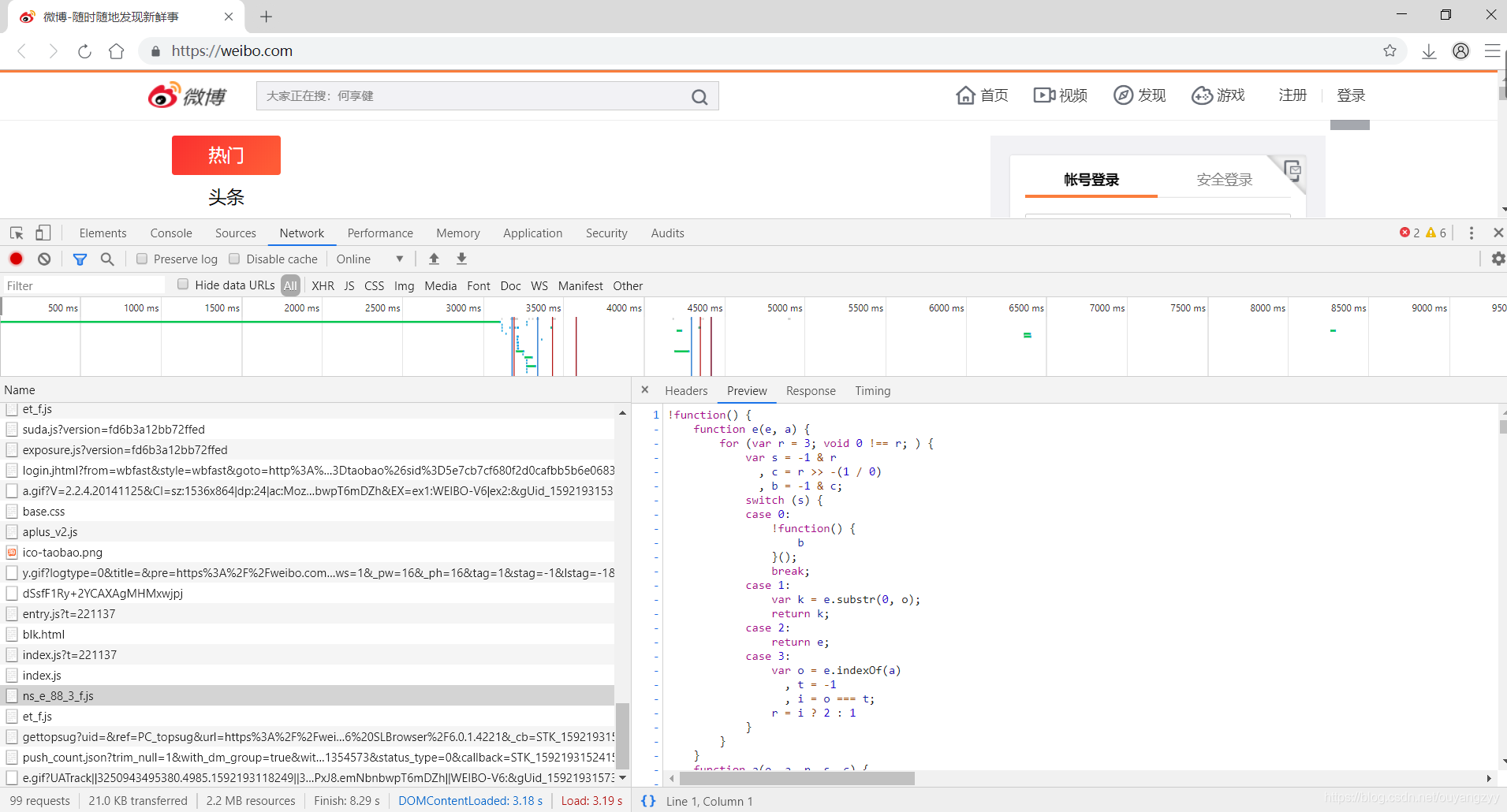
而对于一些网站(上图是微博),它把其网站的URL隐藏的很好,就特别的难以发现,能看到有特别多的其它的页面信息来混淆”爬虫”,所以需要长时间的累计经验才能熟练的去寻找。对于刚入门的来说,我还是建议去爬取一些简单的网站练手,多去练习。
2、urllib库使用
import urllib.request 导入库
urllib.request.urlopen() 模拟浏览器向服务器发送请求
response 服务器返回的数据
response的数据类型是HttpResponse
字节-->字符串
解码decode
字符串-->字节
编码encode
read() 字节形式读取二进制 扩展:read(5)返回前几个字节
readline() 读取一行
readlines() 一行一行读取 直至结束
getcode() 获取状态码
geturl() 获取url
getheaders() 获取headers
urllib.request.urlretrieve()
请求网页
请求图片
请求视频
这些是对于初学者来说是比较好的一个使用说明,是一些常用的方法,下面会有实例,可以结合着来看。
3、get请求方式
如何知道该用什么请求方式?
只要能找到接口在哪,确定了url,自然知道用什么请求方式。
这里说个我自己的想法,只有确定了接口,才能开始写爬虫的代码。因为找不到接口,最关键的url没有,是不可能知道怎么写的。不知道你们是怎么认为的?
下面是urllib.parse.urlencode()的实例
import urllib.request
import urllib.parse
url = 'http://www.baidu.com/s?' # get请求需要传入的参,需要url和data进行拼接
# https://www.baidu.com:80/s?wd=张三/#1 (此为对url的各参数进行解释)
# https 协议
# www.baidu.com 域名
# 80 端口号
# s 请求资源路径
# wd=张三 请求参数
# #1 锚点(不知道的可以百度,这是前端知识)
data = {
'name':'小刚',
'sex':'男',
}
data = urllib.parse.urlencode(data)
url = url + data # 进行拼接
print(url)
headers = { # 请求头相关参数,这里是字典!
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36'
}
request = urllib.request.Request(url=url,headers=headers) # 请求对象定制
response = urllib.request.urlopen(request)
print(response.read().decode('utf-8')) # 这里注意decode和post的encode不同。encode为编码,decode为解码。当然这里的编码个解码并不是一成不变的'utf-8',需要根据爬取网页的编码方式进行替换。
4、post请求方式
eg:百度翻译
import urllib.request
import urllib.parse
url = 'https://fanyi.baidu.com/sug'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36'
}
keyword = input('请输入您要查询的单词')
data = {
'kw':keyword
}
data = urllib.parse.urlencode(data).encode('utf-8') # post请求,这里的encode是必须的,如果不加会出现错误,说白了就是模式化,爬虫代码并不难,大多都是模式化。
request = urllib.request.Request(url=url,headers=headers,data=data) # 请求对象定制
response = urllib.request.urlopen(request)
print(response.read().decode('utf-8'))
这里可以发现,get请求方式和post请求方式非常的相似。
总结一下,get和post区别?
1:get请求方式的参数必须编码, 参数是拼接到url后面,编码之后不需要调用encode方法
2:post请求方式的参数必须编码,参数是放在请求对象定制的方法中,编码之后需要调用encode方法
总的来说,get请求和post请求的方式还是比较简单的,但是这里说明一下,现在爬下来的都是网页的源码,也只是在终端中打印。想要将其下载下来需要如下代码:
#上面的代码没什么不同,只要注意下载文件的存储,命名注意,编码encoding这里也要注意。
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
with open('baidu_'+str(page)+'.html', 'w', encoding='utf-8') as fb:
fb.write(content)
这里感谢大家的阅读,有错误的地方敬请指出。下次还是介绍请求方式方面的,不过是复杂类型的,这次介绍的相当于是最简单的吧。