赛题介绍
NLP之新闻文本分类挑战赛(赛题链接)。
赛题以自然语言处理为背景,要求选手根据新闻文本字符对新闻的类别进行分类,这是一个经典文本分类问题。
赛题数据
赛题数据为新闻文本,并按照字符级别进行匿名处理。整合划分出14个候选分类类别:财经、彩票、房产、股票、家居、教育、科技、社会、时尚、时政、体育、星座、游戏、娱乐的文本数据。
赛题数据由以下几个部分构成:训练集20w条样本,测试集A包括5w条样本,测试集B包括5w条样本。为了预防人工标注测试集的情况,将比赛数据的文本按照字符级别进行了匿名处理。处理后的赛题训练数据如下:
| label | text |
|---|---|
| 6 | 57 44 66 56 2 3 3 37 5 41 9 57 44 47 45 33 13 63 58 31 17 47 0 1 1 69 26 60 62 15 21 12 49 18 38 20 50 23 57 44 45 33 25 28 47 22 52 35 30 14 24 69 54 7 48 19 11 51 16 43 26 34 53 27 64 8 4 42 36 46 65 69 29 39 15 37 57 44 45 33 69 54 7 25 40 35 30 66 56 47 55 69 61 10 60 42 36 46 65 37 5 41 32 67 6 59 47 0 1 1 68 |
在数据集中标签的对应的关系如下:
{'科技': 0, '股票': 1, '体育': 2, '娱乐': 3, '时政': 4, '社会': 5, '教育': 6, '财经': 7, '家居': 8, '游戏': 9, '房产': 10, '时尚': 11, '彩票': 12, '星座': 13}
评测标准
评价标准为类别f1_score的均值,选手提交结果与实际测试集的类别进行对比,结果越大越好。
计算公式:F 1 = 2 ∗ p r e c i s i o n ∗ r e c a l l p r e c i s i o n + r e c a l l F1 = 2 ∗ \frac{precision∗recall}{precision+recall}F1=2∗precision+recallprecision∗recall
赛题理解
读取数据
使用Pandas库完成数据读取操作:
#导入包
import pandas as pd
train_df = pd.read_csv('./data/训练集数据/train_set.csv',sep='\t',nrows=100)
这里使用到的read_csv由三部分构成:
1.读取文件路径;
2.分隔符sep,为每列分割的字符,本赛题存储的数据分隔符为\t;
3.读取行数nrows,由于数据集比较大,可以先设置为100预览。
读取完后可以浏览下数据:
#预览数据
train_df.head()

上图是读取好的数据,是表格形式。第一列(label)为新闻的类别,第二列(text)为新闻的字符。
分析数据
使用Pandas库分析赛题数据的分布规律。
1.数据整体情况:
train_df = pd.read_csv('./data/训练集数据/train_set.csv',sep='\t')
train_df.info()

train_df.describe()
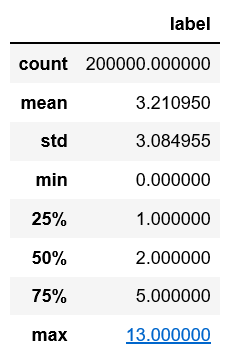
训练集样本20w条,没有空的数据。
2.新闻文本句子长度分布情况:
#新闻文本句子长度分布情况
train_df['text_len'] = train_df['text'].apply(lambda x : len(x.split(' ')))
print(train_df['text_len'].describe())

对新闻句子的统计看出,本赛题给定的句子文本比较长,每个句子平均由907个字符构成,最短的句子长度为2,最长的句子长度为57921。
绘制句子长度的直方图,以便分析句子长度的分布:
#绘制句子长度的直方图
import matplotlib.pyplot as plt
%pylab inline
_ = plt.hist(train_df['text_len'],bins=200)
plt.xlabel('Text char count')
plt.title('Histogram of char count')

由上可见赛题数据的大部分句子长度都在2000字符以内。
2.新闻类别分布情况:
在数据集中标签的对应关系如下:{‘科技’: 0, ‘股票’: 1, ‘体育’: 2, ‘娱乐’: 3, ‘时政’: 4, ‘社会’: 5, ‘教育’: 6, ‘财经’: 7, ‘家居’: 8, ‘游戏’: 9, ‘房产’: 10, ‘时尚’: 11, ‘彩票’: 12, ‘星座’: 13}
#绘制新闻类别的直方图
train_df['label'].value_counts().plot(kind='bar')
plt.title('News class count')
plt.xlabel("category")

从以上统计结果可以看出,赛题的数据集类别分布存在较为不均匀的情况。在训练集中科技类新闻最多,其次是股票类新闻,最少的新闻是星座新闻。
3.字符的分布情况:
a.词频统计
新闻各句子的字符分布情况,即词频统计:首先将训练集中所有的句子进行拼接,然后划分为字符,并统计每个字符的个数。
#句子词频统计
#from collections import Counter 也可以使用计数的包,但是个人电脑内存不足,报MemoryError。
word_count = {}
for i in range(len(train_df['text'])):
for word in train_df['text'][i].split(' '):
if word not in word_count:
word_count[word] = 0
word_count[word] += 1
word_count = sorted(word_count.items(),key=lambda w:w[1],reverse=True)
print(len(word_count))
print(word_count[0])
print(word_count[-1])
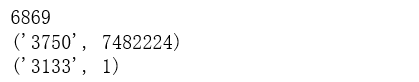
从统计结果可以看出,在训练集中总共包括了6869个字符,其中编号’3750’的字符出现次数最多,编号’3133’的字符出现次数最少。
b.句子统计
查看唯一字符在每条新闻中出现的频率,通过出现次数太过频繁的反推为标点符号。
#唯一字符在每条新闻中出现的频率,top3
train_df['text_unique'] = train_df['text'].apply(lambda x : ' '.join(list(set(x.split(' ')))))
all_lines = ' '.join(list(train_df['text_unique']))
word_count = Counter(all_lines.split(' '))
word_count = sorted(word_count.items(),key=lambda w:w[1],reverse=True)
print(word_count[0:3])
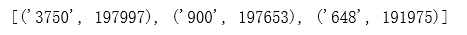
从统计结果可以看出,top3为编号’3750’、‘900’、‘648’字符,在20w新闻中的覆盖率分别为99.00%、98.83%、95.99%,很有可能是标点符号。
以下假设字符’3750’、‘900’、'648’是新闻text的标点符号,分析每篇新闻的句子数:
#split一次指定多个分隔符可以用re模块
#假设3750、900、648为标点符号,统计平均每篇新闻由多少个句子组成
import re
train_df['text_sentence'] = train_df['text'].apply(lambda x : re.split('3750|900|648',x))
train_df['text_sentence_count'] = train_df['text_sentence'].apply(lambda x : int(len(x)))
print(train_df['text_sentence_count'].describe())
#绘制句子长度的直方图
_ = plt.hist(train_df['text_sentence_count'],bins=200)
plt.xlabel('Text sentence count')
plt.title('Histogram of text sentence count')


从统计结果可以看出,在假设字符’3750’、‘900’、'648’是新闻text的标点符号前提下,赛题每篇新闻平均由81个句子构成,最少由1个句子构成,最多由3460个句子构成。
c.按类别词频统计
以下按类别进行词频统计,统计每类新闻中出现次数最多的字符。
#按类别进行词频统计
from collections import Counter
category_text = {}
for i in range(len(train_df['label'])):
if train_df['label'][i] not in category_text:
category_text[train_df['label'][i]] = train_df['text'][i]
category_text[train_df['label'][i]] += ' '
category_text[train_df['label'][i]] +=train_df['text'][i]
category_text_count = {}
for key in category_text:
word_count = Counter(category_text[key].split(' '))
word_count = sorted(word_count.items(),key=lambda w:w[1],reverse=True)
category_text_count[key] = word_count[0]
print(category_text_count)
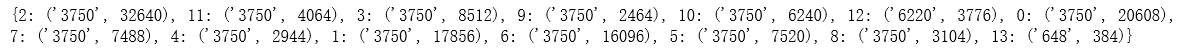
根据数据集中标签的对应关系:{‘科技’: 0, ‘股票’: 1, ‘体育’: 2, ‘娱乐’: 3, ‘时政’: 4, ‘社会’: 5, ‘教育’: 6, ‘财经’: 7, ‘家居’: 8, ‘游戏’: 9, ‘房产’: 10, ‘时尚’: 11, ‘彩票’: 12, ‘星座’: 13},从统计结果可以看出,类别为 ‘体育’、‘时尚’、 ‘娱乐’、‘游戏’、 ‘房产’、‘科技’、‘财经’、 ‘时政’、 ‘股票’、‘教育’、‘社会’、 '家居’的新闻字符出现最多的是’3750’字符,类别为’彩票’的新闻字符出现最多的是’6220’字符,类别为’星座’的新闻字符出现最多的是’648’字符。
通过上述分析,可以得出如下结论:
1.赛题中每个新闻包含的字符个数平均为1000个左右,还有一些新闻字符较长;
2.赛题中新闻类别分布不均匀;
3.赛题总共包括7000~8000个字符。
根据结论,如下注意点:
1.每个新闻平均字符个数较多,可能需要截断;
2.由于类别不均衡,会严重影响模型的精度。
解题思路
赛题思路分析:赛题本质是一个文本分类问题,需要根据每句的字符进行分类。但赛题给出的数据是匿名化的,不能直接使用中文分词等操作,这个是赛题的难点。因此本次赛题的难点是需要对匿名字符进行建模,进而完成文本分类的过程。由于文本数据是一种典型的非结构化数据,因此可能涉及到特征提取和分类模型两个部分。以下解题思路供大家参考:
思路1:TF-IDF + 机器学习分类器
直接使用TF-IDF对文本提取特征,并使用分类器进行分类。在分类器的选择上,可以使用SVM、LR、或者XGBoost。
思路2:FastText
FastText是入门款的词向量,利用Facebook提供的FastText工具,可以快速构建出分类器。
思路3:WordVec + 深度学习分类器
WordVec是进阶款的词向量,并通过构建深度学习分类完成分类。深度学习分类的网络结构可以选择TextCNN、TextRNN或者BiLSTM。
思路4:Bert词向量
Bert是高配款的词向量,具有强大的建模学习能力。