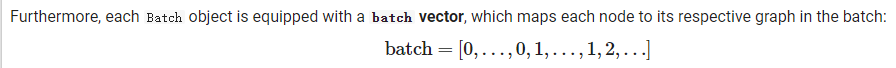一、mini-batch
在graph classification的一些基准数据集中,每个图的样本都很小,如果每次只操作一个,不能充分利用GPU资源。所以考虑把它们分成多个mini-batch。
1、原理
mini-batch就是并行处理多个图,这里把多个图的邻接矩阵A1、A2、……拼接成一个大的矩阵,可以看作一个对角矩阵(出现了很多0元素,即稀疏矩阵的存储)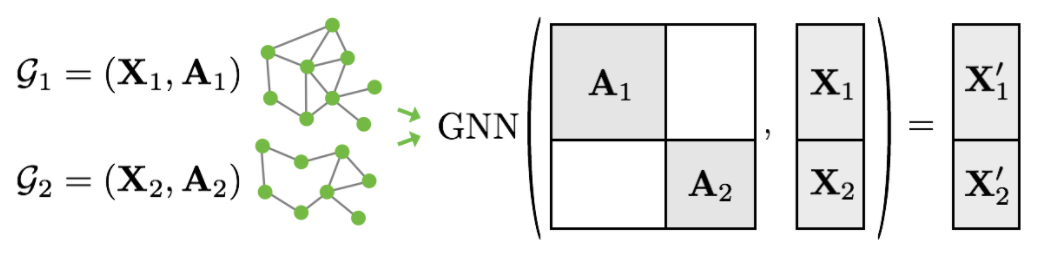
在imgae、language领域中的mini-batch有两种方法:rescaling、padding,把每个样本都处理成一样的size、一样的shape。
但是这两种方法都不适用于graph,会造成很多不必要的内存浪费。
2、代码
PyG框架中的dataloader事先封装好了
from torch_geometric.loader import DataLoader
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=64, shuffle=False)
for step, data in enumerate(train_loader):
print(f'Step {step + 1}:')
print('=======')
print(f'Number of graphs in the current batch: {data.num_graphs}')
print(data)
print()
输出结果:
Step 1:
=======
Number of graphs in the current batch: 64
Batch(edge_attr=[2560, 4], edge_index=[2, 2560], x=[1154, 7], y=[64], batch=[1154], ptr=[65])
Step 2:
======= Number of graphs in the current batch: 64 Batch(edge_attr=[2454, 4], edge_index=[2, 2454], x=[1121, 7], y=[64],
batch=[1121], ptr=[65])
Step 3:
======= Number of graphs in the current batch: 22 Batch(edge_attr=[980, 4], edge_index=[2, 980], x=[439, 7], y=[22],
batch=[439], ptr=[23])