一、大数据与分布式计算(Distributed Computing)
有了大数据,就需要对其进行处理和分析,分析主要分为五个方面:可视化分析(Analytic Visualization)、数据挖掘算法(Date Mining Algorithms)、预测性分析能力(Predictive Analytic Capabilities)、语义引擎(Semantic Engines)和数据质量管理(Data Quality Management)。
对于如何处理大数据,计算机科学界有两大方向:第一个方向是集中式计算,第二个方向是分布式计算。
大数据的技术基础:MapReduce、Google File System和BigTable
分布式计算最初的技术起源都来自于Google的三篇论文:MapReduce、GFS(Google File System)和BigTable,随后逐步发展成为Hadoop,Spark和Storm三大主流的分布式计算系统。
Yahoo的工程师Doug Cutting和Mike Cafarella在2005年合作开发了分布式计算系统Hadoop。后来,Hadoop被贡献给了Apache基金会,成为了Apache基金会的开源项目。Doug Cutting也成为Apache基金会的主席,主持Hadoop的开发工作。
Hadoop采用MapReduce分布式计算框架,并根据GFS开发了HDFS分布式文件系统,根据BigTable开发了HBase数据存储系统。尽管和Google内部使用的分布式计算系统原理相同,但是Hadoop在运算速度上依然达不到Google论文中的标准。
不过,Hadoop的开源特性使其成为分布式计算系统的事实上的国际标准。Yahoo,Facebook,Amazon以及国内的百度,阿里巴巴等众多互联网公司都以Hadoop为基础搭建自己的分布式计算系统。
Spark也是Apache基金会的开源项目,它由加州大学伯克利分校的实验室开发,是另外一种重要的分布式计算系统。它在Hadoop的基础上进行了一些架构上的改良。Spark与Hadoop最大的不同点在于,Hadoop使用硬盘来存储数据,而Spark使用内存来存储数据,因此Spark可以提供超过Hadoop100倍的运算速度。但是,由于内存断电后会丢失数据,Spark不能用于处理需要长期保存的数据。
Storm是Twitter主推的分布式计算系统,它由BackType团队开发,是Apache基金会的孵化项目。它在Hadoop的基础上提供了实时运算的特性,可以实时的处理大数据流。不同于Hadoop和Spark,Storm不进行数据的收集和存储工作,它直接通过网络实时的接受数据并且实时的处理数据,然后直接通过网络实时的传回结果。
Hadoop,Spark和Storm是目前最重要的三大分布式计算系统,Hadoop常用于离线的复杂的大数据处理,Spark常用于离线的快速的大数据处理,而Storm常用于在线的实时的大数据处理。
1、Hadoop
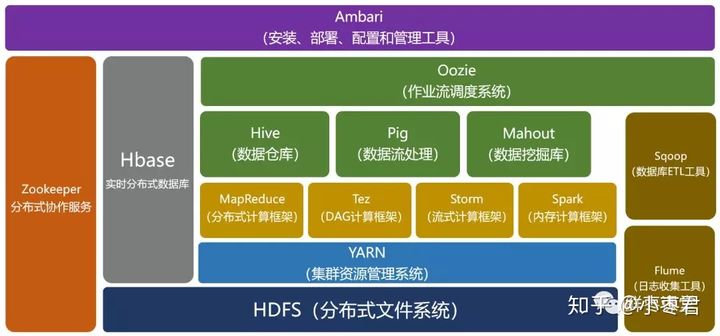
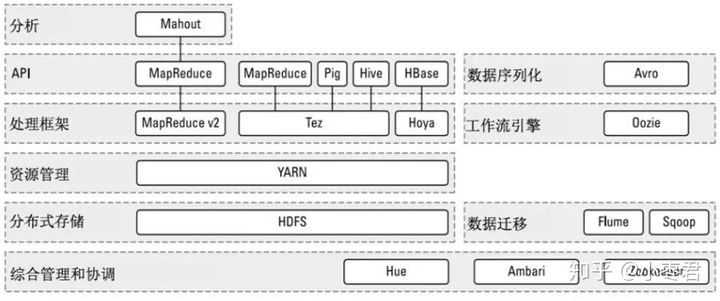
关于Hadoop的发展历史,详见参考资料2。
2、Spark
虽然Hadoop和Spark是两种不同的大数据处理框架,但它们不是互斥的,Spark与hadoop 中的MapReduce是一种相互共生的关系。
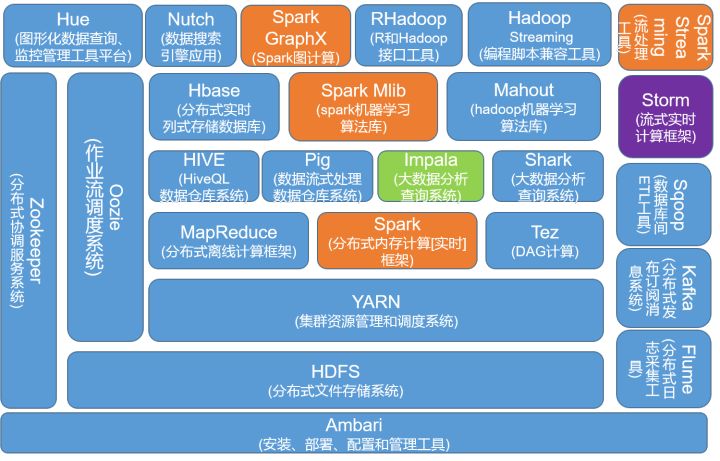
说明:上图中蓝色部分是Hadoop生态系统组件,黄色部分是Spark生态组件。
Apache Spark支持4种分布式部署方式,分别是Amazon EC2, standalone、spark on mesos和 spark on YARN 比如AWS。
从版本2.3.0起,Spark开始支持使用Kubernetes作为native的资源调度器,现在Spark一共支持如下四种资源调度方式:
- Standalone Deploy Mode
- Apache Mesos
- Hadoop YARN
- Kubernetes
现在使用Kubernetes作为原生调度器还只是一个试验功能,并且需要如下前提条件:
- Spark 2.3+
- Kubernetes 1.6+
- 有增删改查POD的能力
- Kubernetes配置了DNS
3、发展趋势
1)Spark的发展优于Hadoop中对等的一些组件。
2)在大数据争夺架构霸权之战中,云计算显然是赢家,而 Hadoop 明显落败了。
HPE(Hewlett Packard Enterprise) 在 8 月 5 日收购了 MapR ,这可以说是 Hadoop 走在消亡路上的一个标志。
参考:
2、hadoop和大数据的关系?和spark的关系? - 小枣君的回答 - 知乎
3、后 Hadoop 世界中的大数据(2019/08/23)