参考:
https://www.kaggle.com/aruchomu/yolo-v3-object-detection-in-tensorflow/notebook
https://blog.csdn.net/KKKSQJ/article/details/83587138
GitHub:https://github.com/heartkilla/yolo-v3
YOLO是目标检测算法,相较于目标识别算法,检测算法不仅能够预测出目标的类别,还能预测出目标的位置。
整个YOLO网络框架图如下图所示, 图片摘自博客:https://blog.csdn.net/KKKSQJ/article/details/83587138

以下代码来源:https://www.kaggle.com/aruchomu/yolo-v3-object-detection-in-tensorflow/data
搭建YOLO框架:
搭建YOLO框架需要用到Tensorflow、Numpy、Pillow(图像处理库)使用Seaborn库中的调色板为bounding boxes 着色。最后使用IPython中的disply函数显示图像。
import tensorflow as tf
import numpy as np
from PIL import Image, ImageDraw, ImageFont
from IPython.display import display
from seaborn import color_palette
import cv2
接下来设置模块参数:
_BATCH_NORM_DECAY = 0.9
_BATCH_NORM_EPSILON = 1e-05
_LEAKY_RELU = 0.1
_ANCHORS = [(10, 13), (16, 30), (33, 23),
(30, 61), (62, 45), (59, 119),
(116, 90), (156, 198), (373, 326)]
_MODEL_SIZE = (416, 416)
不同尺寸特征图对应不同大小的先验框。
13*13feature map对应【(116*90),(156*198),(373*326)】
26*26feature map对应【(30*61),(62*45),(59*119)】
52*52feature map对应【(10*13),(16*30),(33*23)】
原因:特征图越大,感受野越小。对小目标越敏感,所以选用小的anchor box。
特征图越小,感受野越大。对大目标越敏感,所以选用大的anchor box。
其中_BATCH_NORM_EPSILON代表公式中参数的精确度(小数点的位数),_BATCH_NORM_DECAY代表批量移动的动能(momentum),它用来计算移动的平均值和方差,在训练的过程中,正向传播会用到这些参数。
moving_average = momentum * moving_average + (1 - momentum) * current_average
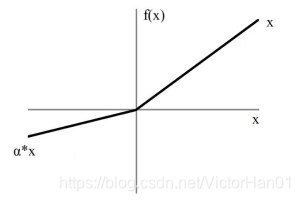
Leaky ReLU:
该激活函数是在ReLU的基础上做的轻微修改,目的是防止出现“神经元死亡”的现象,即大量的激活值变为0。_LEAKY_RELU 是指图中的α。
.锚框(Anchors):
Anchors是一种先验框,是在COCO数据集上通过K均值聚类估算得到的,我们将预测的框的宽高,作为簇中心的补偿。 利用sigmoid函数预测了box相对于filter application位置的中心坐标。
锚框的作用:Yolov3根据图像特征,对每一个像素都预测出对应的锚框,再根据IOU值,置信度对锚框进行筛选,得到与目标框最接近的锚框后,再利用回归训练以下参数值,使这些参数对应的预测框最大程度接近真实目标框。
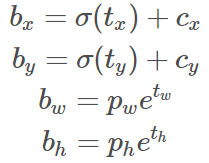
其中bx,by是框的坐标中心,bw,bh是框的宽高。Cx 和cy是filter application的位置,ti是经过回归预测的。
模块定义:
我参考了Tensorflow中的官方ResNet(残差网络)实现,了解了如何对代码进行重新排列。
Batch norm and fixed padding
定义batch_norm函数很有用,因为模型大量使用具有共享参数的批处理规范(batch norm)。此外,与ResNet相同,Yolo使用固定padding的卷积,这意味着padding仅由内核的大小定义。
### 批量标准化和固定填充 ###
def batch_norm(inputs, training, data_format):
"""用一组标准参数执行批量标准化"""
return tf.layers.batch_normalization(
inputs=inputs, axis=1 if data_format == 'channels_first' else 3,
momentum=_BATCH_NORM_DECAY, epsilon=_BATCH_NORM_EPSILON,
scale=True, training=training)
def fixed_padding(inputs, kernel_size, data_format):
"""ResNet implementation of fixed padding.
Pads the input along the spatial dimensions independently of input size.
Args:
inputs: 被填充的张量.
kernel_size: 卷积和池化的核的大小
data_format: 输入的数据格式
Returns:
返回一个和输入格式相同的张量
"""
pad_total = kernel_size - 1
pad_beg = pad_total // 2 # 整数除法,返回整数
pad_end = pad_total - pad_beg
if data_format == 'channels_first':
padded_inputs = tf.pad(inputs, [[0, 0], [0, 0],
[pad_beg, pad_end],
[pad_beg, pad_end]])
else:
padded_inputs = tf.pad(inputs, [[0, 0], [pad_beg, pad_end],
[pad_beg, pad_end], [0, 0]])
return padded_inputs
def conv2d_fixed_padding(inputs, filters, kernel_size, data_format, strides=1):
"""带填充的二维卷积."""
if strides > 1: # 若步长大于1
inputs = fixed_padding(inputs, kernel_size, data_format)
return tf.layers.conv2d(
inputs=inputs, filters=filters, kernel_size=kernel_size,
strides=strides, padding=('SAME' if strides == 1 else 'VALID'),
use_bias=False, data_format=data_format)
特征提取:Darknet-53:
在特征提取方面,Yolo使用了在ImageNet上预处理的Darknet-53神经网络。与ResNet一样,Darknet-53具有快捷(残差)连接,这有助于更上层的信息进一步流动。Yolo省略了最后3层(Avgpool, Connected和Softmax),因为Yolo只用Darknet-53提取特征。框架中每个卷积核的参数是随机给出的,服从高斯分布,每次运行程序卷积核内的值都不一样,但都能提取图像特征,不会造成过拟合。
def darknet53_residual_block(inputs, filters, training, data_format,
strides=1):
"""为 Darknet 创建残差块"""
shortcut = inputs # 残差块的输入
inputs = conv2d_fixed_padding(
inputs, filters=filters, kernel_size=1, strides=strides,
data_format=data_format)
# conv2d_fixed_padding返回的是卷积层,赋值给inputs,即执行卷积核为1的卷积层
inputs = batch_norm(inputs, training=training, data_format=data_format)
# batch_norm返回的是batch_normalization层,赋值给inputs,即执行BN层
inputs = tf.nn.leaky_relu(inputs, alpha=_LEAKY_RELU)
# 执行激活函数Leaky_Relu
inputs = conv2d_fixed_padding(
inputs, filters=2 * filters, kernel_size=3, strides=strides,
data_format=data_format)
# 执行卷积核为3的卷积层,其输入为上一层的激活函数Leaky_Relu的输出,filters指卷积的通道个数
inputs = batch_norm(inputs, training=training, data_format=data_format)
# 执行BN层
inputs = tf.nn.leaky_relu(inputs, alpha=_LEAKY_RELU)
# 执行 激活函数Leaky_Relu
inputs += shortcut #残差连接部分,将残差块的输出与残差块之前的输出进行累加。
return inputs
def darknet53(inputs, training, data_format):
"""创建 Darknet53 模型进行特征提取"""
inputs = conv2d_fixed_padding(inputs, filters=32, kernel_size=3,
data_format=data_format)
# 使用32个3*3的卷积核对输入图像进行卷积,步长默认为1
inputs = batch_norm(inputs, training=training, data_format=data_format)
# 批量标准化BN层
inputs = tf.nn.leaky_relu(inputs, alpha=_LEAKY_RELU)
# 激活函数Leaky_Relu激活后输出
inputs = conv2d_fixed_padding(inputs, filters=64, kernel_size=3,
strides=2, data_format=data_format)
# 接上层输出,使用64个3*3的卷积和,步长为2(降维)
inputs = batch_norm(inputs, training=training, data_format=data_format)
# BN层
inputs = tf.nn.leaky_relu(inputs, alpha=_LEAKY_RELU)
# 激活函数Leaky_Relu激活后输出
inputs = darknet53_residual_block(inputs, filters=32, training=training,
data_format=data_format)
# 返回 上层的输出经过残差块后的值 与 上层输出值 的和
inputs = conv2d_fixed_padding(inputs, filters=128, kernel_size=3,
strides=2, data_format=data_format)
# 128个3*3的卷积核,步长为2
inputs = batch_norm(inputs, training=training, data_format=data_format)
# 每个卷积层后都接一个BN层
inputs = tf.nn.leaky_relu(inputs, alpha=_LEAKY_RELU)
for _ in range(2):
inputs = darknet53_residual_block(inputs, filters=64,
training=training,
data_format=data_format)
# 累加两个残差块
inputs = conv2d_fixed_padding(inputs, filters=256, kernel_size=3,
strides=2, data_format=data_format)
# 3*3*256 步长为2
inputs = batch_norm(inputs, training=training, data_format=data_format)
inputs = tf.nn.leaky_relu(inputs, alpha=_LEAKY_RELU)
for _ in range(8):
inputs = darknet53_residual_block(inputs, filters=128,
training=training,
data_format=data_format)
# 累加8个残差块
route1 = inputs
# 存储输出,若输入为416*416,此时为52*52*256,用于输出前的两个输出的合并(concat)
inputs = conv2d_fixed_padding(inputs, filters=512, kernel_size=3,
strides=2, data_format=data_format)
# 3*3*512 步长为2
inputs = batch_norm(inputs, training=training, data_format=data_format)
inputs = tf.nn.leaky_relu(inputs, alpha=_LEAKY_RELU)
for _ in range(8):
inputs = darknet53_residual_block(inputs, filters=256,
training=training,
data_format=data_format)
# 累加8个残差块
route2 = inputs
# 存储输出,此时为26*26*512,用于输出前的两个输出的合并(concat)
inputs = conv2d_fixed_padding(inputs, filters=1024, kernel_size=3,
strides=2, data_format=data_format)
# 3*3*1024 步长为2
inputs = batch_norm(inputs, training=training, data_format=data_format)
inputs = tf.nn.leaky_relu(inputs, alpha=_LEAKY_RELU)
for _ in range(4):
inputs = darknet53_residual_block(inputs, filters=512,
training=training,
data_format=data_format)
# 累加4个残差块,此时输出为13*13*1024
return route1, route2, inputs
# 使用darknet53进行特征提取的部分结束,返回52*52*256,26*26*512,3*3*1024 三个特征提取输出结果
用于分组的卷积层:
Yolo定义了大量的卷积层用于对提取的特征进行分组。
### 对提取的特征进行分组 ###
def yolo_convolution_block(inputs, filters, training, data_format):
"""使用Darknet后创建卷积操作层"""
inputs = conv2d_fixed_padding(inputs, filters=filters, kernel_size=1,
data_format=data_format)
# 1*1*filters 其中filters对应Darknet层输出的filters
inputs = batch_norm(inputs, training=training, data_format=data_format)
inputs = tf.nn.leaky_relu(inputs, alpha=_LEAKY_RELU)
inputs = conv2d_fixed_padding(inputs, filters=2 * filters, kernel_size=3,
data_format=data_format)
# 3*3*(filters*2)
inputs = batch_norm(inputs, training=training, data_format=data_format)
inputs = tf.nn.leaky_relu(inputs, alpha=_LEAKY_RELU)
inputs = conv2d_fixed_padding(inputs, filters=filters, kernel_size=1,
data_format=data_format)
# 1*1*filters
inputs = batch_norm(inputs, training=training, data_format=data_format)
inputs = tf.nn.leaky_relu(inputs, alpha=_LEAKY_RELU)
inputs = conv2d_fixed_padding(inputs, filters=2 * filters, kernel_size=3,
data_format=data_format)
# 3*3*(filters*2)
inputs = batch_norm(inputs, training=training, data_format=data_format)
inputs = tf.nn.leaky_relu(inputs, alpha=_LEAKY_RELU)
inputs = conv2d_fixed_padding(inputs, filters=filters, kernel_size=1,
data_format=data_format)
# 1*1*filters
inputs = batch_norm(inputs, training=training, data_format=data_format)
inputs = tf.nn.leaky_relu(inputs, alpha=_LEAKY_RELU)
route = inputs
# 存储输出数据,用于上采样后与DarkNet相应的输出数据合并(concat)
inputs = conv2d_fixed_padding(inputs, filters=2 * filters, kernel_size=3,
data_format=data_format)
# 3*3*(filters*2)
inputs = batch_norm(inputs, training=training, data_format=data_format)
inputs = tf.nn.leaky_relu(inputs, alpha=_LEAKY_RELU)
return route, inputs
Yolov3最终检测层:
Yolo有3个检测层,分别使用各自的锚框在3个不同的尺度上进行检测。对于feature map中的每个单元(cell),检测层使用1x1卷积预测n_anchor * (5 + n_classes)值。(5是指5个参数:tx,ty,tw,th,to表示框的4个坐标信息和1个置信度信息。n_anchor=3,n_classes=类的个数,每个参数代表属于该类的概率。) 对于每个scale,我们都有n_anchor = 3。5 + n_classes表示,对于3个锚点我们分别预测4个坐标。
### 检测层 ###
def yolo_layer(inputs, n_classes, anchors, img_size, data_format):
"""创建Yolo最终检测层。
检测与锚框相关的框
参数:
inputs: 张量(三维矩阵)输入.
n_classes: 类的数量
anchors: 锚框大小组成的列表
img_size: 模型的输入大小
data_format: 输入数据的格式
Returns:
Tensor output.
"""
n_anchors = len(anchors) # n_anchors 是由元组组成的列表
inputs = tf.layers.conv2d(inputs, filters=n_anchors * (5 + n_classes),
kernel_size=1, strides=1, use_bias=True,
data_format=data_format)
# 1*1*filter 卷积层,取出每一个单元的数据
shape = inputs.get_shape().as_list()# get_shape()只有张量才能使用,返回一个元组,as_list(),将元组转换为列表
grid_shape = shape[2:4] if data_format == 'channels_first' else shape[1:3]
if data_format == 'channels_first':
inputs = tf.transpose(inputs, [0, 2, 3, 1])
inputs = tf.reshape(inputs, [-1, n_anchors * grid_shape[0] * grid_shape[1],
5 + n_classes])
#将inputs reshape 成 (3*h*w) * (5+n_classes) 的矩阵。
strides = (img_size[0] // grid_shape[0], img_size[1] // grid_shape[1])
#计算步长img_size是模型的输入大小,此处比值应该为1
box_centers, box_shapes, confidence, classes = \
tf.split(inputs, [2, 2, 1, n_classes], axis=-1)
#沿着最后一个下标变化的方向进行切分,即按列切分
x = tf.range(grid_shape[0], dtype=tf.float32)
# 返回数字序列,若grid_shape[0]=3,则x=[0 1 2]
y = tf.range(grid_shape[1], dtype=tf.float32)
x_offset, y_offset = tf.meshgrid(x, y)
# 将x_offset, y_offset都转换为x行y列. 相当于给每一个元素添加一个“组”标签
x_offset = tf.reshape(x_offset, (-1, 1))
# -1可看做事一个未知数,reshape成一列,自动计算行数
y_offset = tf.reshape(y_offset, (-1, 1))
x_y_offset = tf.concat([x_offset, y_offset], axis=-1)
# 按列合并(行数不变,列数增加)
x_y_offset = tf.tile(x_y_offset, [1, n_anchors])
# 行不变,列复制3次(列扩充3倍)
x_y_offset = tf.reshape(x_y_offset, [1, -1, 2])
# reshape 成1行2列,维数自动(该列表只有一个元素,元素事列表,该列表有2列,很多行)
box_centers = tf.nn.sigmoid(box_centers)
# 与tf.sigmoid 相同
box_centers = (box_centers + x_y_offset) * strides
# box_centers 是n维2列的数组
anchors = tf.tile(anchors, [grid_shape[0] * grid_shape[1], 1])
# 锚框大小,列不变,行复制 h*w 次
box_shapes = tf.exp(box_shapes) * tf.to_float(anchors)
# 按照公式计算预测框的实际大小
confidence = tf.nn.sigmoid(confidence)
# 归一化置信度
classes = tf.nn.sigmoid(classes)
# 归一化类的概率
inputs = tf.concat([box_centers, box_shapes,
confidence, classes], axis=-1)
# 将处理后的数据按列拼接(行数不变,列数增加)赋给inputs
return inputs
上采样层:
为了将dark-53的快捷输出连接起来用到不同尺度的检测中,YOLO使用最近邻插值法对输出图像进行上采样。
### 上采样层 ###
def upsample(inputs, out_shape, data_format):
"""使用最近邻插值法将inputs的size调整为out_shape描述的size."""
# data_format 是指 inputs 的数据格式名称
# input 和 out_shape 的数据格式相同
if data_format == 'channels_first':
inputs = tf.transpose(inputs, [0, 2, 3, 1]) # 转换为channels_last数据格式
new_height = out_shape[3]# channels_first格式的行数
new_width = out_shape[2]# channels_first格式的列数
else:
new_height = out_shape[2]# channels_last格式的行数
new_width = out_shape[1]# channels_last格式的列数
inputs = tf.image.resize_nearest_neighbor(inputs, (new_height, new_width))
# 此时inputs 是 challels_last 格式,使用最近邻插值调整input的高宽,调整为new_height, new_width
if data_format == 'channels_first':
inputs = tf.transpose(inputs, [0, 3, 1, 2])
# 再input 调整为cahnnels_first的格式
return inputs
非极大值抑制:
YOLOv3模型会产生很多个预测框,所以需要一种方法来丢弃那些置信度低的预测框。此外,为了避免为一个对象使用多个预测框预测,还丢弃具有高重叠度的预测框,并对每个类做非极大值抑制。
### 非极大值抑制 ###
def build_boxes(inputs):
"""计算框的左上角和右下角的点."""
center_x, center_y, width, height, confidence, classes = \
tf.split(inputs, [1, 1, 1, 1, 1, -1], axis=-1)
# -1是未知数,自动填写
top_left_x = center_x - width / 2
top_left_y = center_y - height / 2
bottom_right_x = center_x + width / 2
bottom_right_y = center_y + height / 2
boxes = tf.concat([top_left_x, top_left_y,
bottom_right_x, bottom_right_y,
confidence, classes], axis=-1)
# 将Boxe中的数据重新合并(列不变,对行进行调整)
return boxes
def non_max_suppression(inputs, n_classes, max_output_size, iou_threshold,
confidence_threshold):
"""分别对每一个类执行非极大值抑制。
Args:
inputs: 张量输入.
n_classes: 类的数量.
max_output_size: 为每个类选择的框数的最大值
iou_threshold: IOU的阈值
confidence_threshold: 置信度的阈值
Returns:
返回批次中每个样本的{类:预测框}字典所组成的列表
"""
batch = tf.unstack(inputs)
# 对inputs进行分解,默认axis=0 安装样本数进行分解, 每个样本有一个boxes矩阵
boxes_dicts = []
for boxes in batch:
boxes = tf.boolean_mask(boxes, boxes[:, 4] > confidence_threshold)
#只保留boxes中,与不等式结果为Ture的下标相同的部分(保留置信度大于阈值的box)
classes = tf.argmax(boxes[:, 5:], axis=-1)
# 对每一行的从第5到最后一列的数,按行比较,返回最大值的索引
classes = tf.expand_dims(tf.to_float(classes), axis=-1)
# 给calsse的最后一维添加一个维度
boxes = tf.concat([boxes[:, :5], classes], axis=-1)
# 合并两个矩阵,按列拼接
# 合并两个矩阵,行不变,按列拼接(类的最后加一个类别置信度的最大值)
boxes_dict = dict()
# 创建一个字典
for cls in range(n_classes):
mask = tf.equal(boxes[:, 5], cls)
# 比较所有行的第五列的元素与cls,相等则返回Ture不等则返回False
mask_shape = mask.get_shape()
if mask_shape.ndims != 0:
class_boxes = tf.boolean_mask(boxes, mask)
# 只保留boxes中 与mask的元素中值为Ture的下标相同 的元素
# 此处boxes的元素是一个向量
boxes_coords, boxes_conf_scores, _ = tf.split(class_boxes,
[4, 1, -1],
axis=-1)
boxes_conf_scores = tf.reshape(boxes_conf_scores, [-1])
# reshape成一个向量
indices = tf.image.non_max_suppression(boxes_coords,
boxes_conf_scores,
max_output_size,
iou_threshold)
# tf.image中自带的最大值抑制函数,返回符合要求的boxes_coords的索引
class_boxes = tf.gather(class_boxes, indices)
# 可以使用tf.gather操作获取与所选索引对应的边界框坐标
boxes_dict[cls] = class_boxes[:, :5]
# 将符合要求的预测框信息存入字典。
boxes_dicts.append(boxes_dict)
#将字典存入列表,直到循环结束
return boxes_dicts
定义最终的模型类:
最后,使用前面描述的所有层来定义模型类。
class Yolo_v3:
"""Yolo v3 模型类"""
def __init__(self, n_classes, model_size, max_output_size, iou_threshold,
confidence_threshold, data_format=None):
# 类中构造函数,第一个参数必须是self
"""创建 model.
Args:
n_classes: 类的数量
model_size: 模型的输入大小.
max_output_size: 每个类选择的框数的最大值
iou_threshold: IOU阈值
confidence_threshold: 置信度阈值
data_format: 输入格式
Returns:
None.
"""
if not data_format:
if tf.test.is_built_with_cuda():
data_format = 'channels_first'
else:
data_format = 'channels_last'
# 确定data_format
self.n_classes = n_classes
self.model_size = model_size
self.max_output_size = max_output_size
self.iou_threshold = iou_threshold
self.confidence_threshold = confidence_threshold
self.data_format = data_format
# 给变量赋值
def __call__(self, inputs, training):
"""为一批输入图像添加检测框
Args:
inputs: 代表一批输入图像的张量
training:一个布尔值,用于训练或推理模型
Returns:
对于每个批次返回一个包含{类:框}字典的列表
"""
with tf.variable_scope('yolo_v3_model'):
# tf.variable_scope可以让不同命名空间中的变量取相同的名字
if self.data_format == 'channels_first':
inputs = tf.transpose(inputs, [0, 3, 1, 2])
# 输入转为channels_last格式
inputs = inputs / 255
# 归一化
route1, route2, inputs = darknet53(inputs, training=training,
data_format=self.data_format)
# 利用datknet53提取3种尺寸的特征
route, inputs = yolo_convolution_block(
inputs, filters=512, training=training,
data_format=self.data_format)
# Yolov3的卷积操作,输出数据用于上采样与合并
# 此处选取的输入是input13*13*1024
detect1 = yolo_layer(inputs, n_classes=self.n_classes,
anchors=_ANCHORS[6:9],
img_size=self.model_size,
data_format=self.data_format)
# 锚框列表选择后三个(116, 90), (156, 198), (373, 326)大尺寸,对应特征图13*13
# 特征图越小感受野越大,选用大的锚框
# 输出未带有预测框信息的张量,赋给的detect1
inputs = conv2d_fixed_padding(route, filters=256, kernel_size=1,
data_format=self.data_format)
# 待填充的2维卷积,用卷积核大小未1的卷积对route进行卷积
# 将13*13*512的张量变为13*13*256
inputs = batch_norm(inputs, training=training,
data_format=self.data_format)
# BN层 批量标准化
inputs = tf.nn.leaky_relu(inputs, alpha=_LEAKY_RELU)
# 激活函数Leaky_Relu
upsample_size = route2.get_shape().as_list()
# 获取route2的size作为上采样后的size
inputs = upsample(inputs, out_shape=upsample_size,
data_format=self.data_format)
# 上采样,最近邻插值法将route 的size转为route2的size
axis = 1 if self.data_format == 'channels_first' else 3
# 根据数据类型选择通道维度
inputs = tf.concat([inputs, route2], axis=axis)
# # 根据通道与低级特征进行合并
route, inputs = yolo_convolution_block(
inputs, filters=256, training=training,
data_format=self.data_format)
# 经过5个卷积分为route,inputs 两组
detect2 = yolo_layer(inputs, n_classes=self.n_classes,
anchors=_ANCHORS[3:6],
img_size=self.model_size,
data_format=self.data_format)
# 输出未带有预测框信息的张量,赋给的detect2
inputs = conv2d_fixed_padding(route, filters=128, kernel_size=1,
data_format=self.data_format)
inputs = batch_norm(inputs, training=training,
data_format=self.data_format)
inputs = tf.nn.leaky_relu(inputs, alpha=_LEAKY_RELU)
upsample_size = route1.get_shape().as_list()
inputs = upsample(inputs, out_shape=upsample_size,
data_format=self.data_format)
inputs = tf.concat([inputs, route1], axis=axis)
# 根据通道与低级特征进行合并
route, inputs = yolo_convolution_block(
inputs, filters=128, training=training,
data_format=self.data_format)
# 同样的方式再分为route,inputs 两组
detect3 = yolo_layer(inputs, n_classes=self.n_classes,
anchors=_ANCHORS[0:3],
img_size=self.model_size,
data_format=self.data_format)
# 输出未带有预测框信息的张量,赋给的detect3
inputs = tf.concat([detect1, detect2, detect3], axis=1)
# 根据通道将三种尺寸的预测结果合并
inputs = build_boxes(inputs)
# 根据输出得到预测框的真实值
boxes_dicts = non_max_suppression(
inputs, n_classes=self.n_classes,
max_output_size=self.max_output_size,
iou_threshold=self.iou_threshold,
confidence_threshold=self.confidence_threshold)
# 分别对每一类进行非极大值抑制
# 返回批次中每个样本的{类:预测框}字典所组成的列表
return boxes_dicts
5.公用函数:
公用函数主要用来,以数组形式加载图像,从文件中读取类名,绘制预测框
### 公用函数 ###
def load_images(img_names, model_size):
"""以4维数组的形式加载图像
Args(参数):
img_names: 图像名称列表.
model_size: 模型的输入大小.
data_format: 4维数组的格式
('channels_first' or 'channels_last').
Returns:
返回一个4维数组
"""
imgs = []
for img_name in img_names:
#从图像名称列表中提取每一个名称
img = Image.open(img_name)
# 打开该图像名称对应的图像
img = img.resize(size=model_size)
# 将图像大小转换未model_size的大小,此处model_size=416*416
img = np.array(img, dtype=np.float32)
# 转换为2维数组
img = np.expand_dims(img, axis=0)
# 增加一个维度变为3维
imgs.append(img)
# 三维数组存入列表,此时列表为4维
imgs = np.concatenate(imgs)
# 将多个4维数组拼接起来
return imgs
def load_class_names(file_name):
"""返回从' file_name '读取的类名列表."""
with open(file_name, 'r') as f:
class_names = f.read().splitlines()
return class_names
def draw_boxes(img_names, boxes_dicts, class_names, model_size):
"""画预测框
Args:
img_names: 输入的图像名称列表
boxes_dict:{类:框}字典
class_names: 类名组成的列表
model_size: 模型size
Returns:
None.
"""
colors = ((np.array(color_palette("hls", 80)) * 255)).astype(np.uint8)
# 颜色列表
for num, img_name, boxes_dict in zip(range(len(img_names)), img_names,
boxes_dicts):
img = Image.open(img_name)
# 打开图片
draw = ImageDraw.Draw(img)
# 画图
# font = ImageFont.truetype(font='../input/futur.ttf', size=(img.size[0] + img.size[1]) // 100)
font = ImageFont.truetype("arial.ttf", size=(img.size[0] + img.size[1]) // 100)
resize_factor = (img.size[0] / model_size[0], img.size[1] / model_size[1])
# 获取比例
for cls in range(len(class_names)):
boxes = boxes_dict[cls]
# 类名对应的boxes信息
if np.size(boxes) != 0:
color = colors[cls]
for box in boxes:
xy, confidence = box[:4], box[4]
xy = [xy[i] * resize_factor[i % 2] for i in range(4)]
x0, y0 = xy[0], xy[1]
thickness = (img.size[0] + img.size[1]) // 200
for t in np.linspace(0, 1, thickness):
xy[0], xy[1] = xy[0] + t, xy[1] + t
xy[2], xy[3] = xy[2] - t, xy[3] - t
draw.rectangle(xy, outline=tuple(color))
text = '{} {:.1f}%'.format(class_names[cls],
confidence * 100)
text_size = draw.textsize(text, font=font)
# 文字大小
draw.rectangle(
[x0, y0 - text_size[1], x0 + text_size[0], y0],
fill=tuple(color))
# 绘制矩形
draw.text((x0, y0 - text_size[1]), text, fill='black',
font=font)
# 在图片上添加文字
display(img)
6.加载权重文件
遍历文件并逐步创建tf.assign操作
### 将权重转换为Tensorflow格式 ###
### 不了解权重文件格式,这部分没看懂 ###
def load_weights(variables, file_name):
"""重塑和加载 Yolo 权重
Args:
variables: 待分配的 tf.Variable权重列表
file_name: 权重文件名称
Returns:
一个分配操作的列表
"""
with open(file_name, "rb") :
# rb:以二进制格式打开一个文件用于只读
# with模块结束后f会自动关闭
np.fromfile(file_name, dtype=np.int32, count=5)
# 跳过不含相关信息的前5个值,按照int32类型读入数据
weights = np.fromfile(file_name, dtype=np.float32)
# 按照float32类型读入数据
assign_ops = []
ptr = 0
# 加载Darknet53部分的权重
# 每个卷积层都有批量归一化
for i in range(52):
conv_var = variables[5 * i]
gamma, beta, mean, variance = variables[5 * i + 1:5 * i + 5]
batch_norm_vars = [beta, gamma, mean, variance]
for var in batch_norm_vars:
shape = var.shape.as_list()
num_params = np.prod(shape)
var_weights = weights[ptr:ptr + num_params].reshape(shape)
ptr += num_params
assign_ops.append(tf.assign(var, var_weights))
# tf.assign(): 把var_weights 的值赋给var ,按照var原来的数据格式返回
shape = conv_var.shape.as_list()
num_params = np.prod(shape)
var_weights = weights[ptr:ptr + num_params].reshape(
(shape[3], shape[2], shape[0], shape[1]))
var_weights = np.transpose(var_weights, (2, 3, 1, 0))
ptr += num_params
assign_ops.append(tf.assign(conv_var, var_weights))
# 加载YoloV3部分的权重.
# 第7、15、23层有偏差,没有批量归一化
ranges = [range(0, 6), range(6, 13), range(13, 20)]
unnormalized = [6, 13, 20]
for j in range(3):
for i in ranges[j]:
current = 52 * 5 + 5 * i + j * 2
conv_var = variables[current]
gamma, beta, mean, variance = \
variables[current + 1:current + 5]
batch_norm_vars = [beta, gamma, mean, variance]
for var in batch_norm_vars:
shape = var.shape.as_list()
num_params = np.prod(shape)
var_weights = weights[ptr:ptr + num_params].reshape(shape)
ptr += num_params
assign_ops.append(tf.assign(var, var_weights))
shape = conv_var.shape.as_list()
num_params = np.prod(shape)
var_weights = weights[ptr:ptr + num_params].reshape(
(shape[3], shape[2], shape[0], shape[1]))
var_weights = np.transpose(var_weights, (2, 3, 1, 0))
ptr += num_params
assign_ops.append(tf.assign(conv_var, var_weights))
bias = variables[52 * 5 + unnormalized[j] * 5 + j * 2 + 1]
shape = bias.shape.as_list()
num_params = np.prod(shape)
var_weights = weights[ptr:ptr + num_params].reshape(shape)
ptr += num_params
assign_ops.append(tf.assign(bias, var_weights))
conv_var = variables[52 * 5 + unnormalized[j] * 5 + j * 2]
shape = conv_var.shape.as_list()
num_params = np.prod(shape)
var_weights = weights[ptr:ptr + num_params].reshape(
(shape[3], shape[2], shape[0], shape[1]))
var_weights = np.transpose(var_weights, (2, 3, 1, 0))
ptr += num_params
assign_ops.append(tf.assign(conv_var, var_weights))
return assign_ops
7.运行模型
目标检测
将IOU阈值和置信度阈值都设置为0.5来测试模型。
### 运行模型 ###
img_names = ['dog.jpg', 'person.jpg']
for img in img_names:
imgShow=Image.open(img)
display(imgShow) # 展示图片信息
### 测试模型 ###
batch_size = len(img_names)
batch = load_images(img_names, model_size=_MODEL_SIZE)
# print(batch)
class_names = load_class_names('coco.names')
n_classes = len(class_names)
max_output_size = 20
iou_threshold = 0.5
confidence_threshold = 0.5
model = Yolo_v3(n_classes=n_classes, model_size=_MODEL_SIZE,
max_output_size=max_output_size,
iou_threshold=iou_threshold,
confidence_threshold=confidence_threshold)
inputs = tf.placeholder(tf.float32, [batch_size, 416, 416, 3])
detections = model(inputs, training=False)
model_vars = tf.global_variables(scope='yolo_v3_model')
assign_ops = load_weights(model_vars, 'yolov3.weights')
with tf.Session() as sess:
sess.run(assign_ops)
detection_result = sess.run(detections, feed_dict={inputs: batch})
draw_boxes(img_names, detection_result, class_names, _MODEL_SIZE)