前面已经和大家说过MongoDB 的基本查询和删除、修改等用法,下面就和大家说下MongoDB的一些高阶使用。
索引
MongoDB也和其它数据库一样,可以添加索引来查找,但也有很多不同的地方。在 MongoDB 上,索引能够提高读操作及查询性能。没有索引,MongoDB 必须扫描集合中的每一个文档,然后选择与查询条件匹配的文档,这种全表扫描的方式是非常低效的。
MongoDB 索引的数据结构也是 B+树,它能存储一小部分集合的数据,具体来说就是存储集合中建有索引的一个或多个字段的值,而且按照值的升序或降序排列。对于一个查询说,如果存在合适的索引,MongoDB 能够利用这个索引减少文档的扫描数量。
MongoDB 3.0.0 版本之后,使用 createIndex() 方法来创建索引。
注意在 3.0.0 版本前创建索引方法为 db.collection.ensureIndex(),之后的版本 使 用了 db.collection.createIndex() 方 法, ensureIndex() 还 能用 , 但只 是createIndex() 的别名。
createIndex()方法基本语法格式如下所示:
db.collection.createIndex(keys, options)其中 Key 值为要创建的索引字段,1 为指定按升序创建索引,如果你想按降序来创建索引指定为 -1 即可。示例如下:
db.col.createIndex({"title":1})createIndex() 方法中也可以设置使用多个字段创建索引(关系型数据库中称作复合索引)。示例如下:
db.col.createIndex({"title":1,"description":-1})副本集
数据库总是会遇到各种失败的场景,如网络连接断开、断电等。尽管lounialing日志功能也提供了数据恢复的功能,但它通常是针对单个节点来说的,只能保证单节点数据的一致性。而副本集通常是由多个节点组成,每个节点除了 Journaling日志恢复功能外,整个副本集还具有故障自动转移的功能,这样能保证数据库的高可用性。
在生产环境中一个副本集最少应该包含三个节点,其中有一个必须是主节点,典型的部署结构如下图所示:
每个节点都是一个 mongod 进程对应的实例,节点之间互相周期性地通过心跳检查对方的状态。默认情况下 primary 节点负责数据的读写,secondary 节备份 primary 节点上的数据,但是 arbiter 节点不会从 primary 节点同步数据。
从它的名字 arbiter 可以看出,它起到的作用只是当 primary 节点故障时,能够参与到副本集剩下的节点中,选择出一个新的 primary 节点,它自己永远不会变为primary 节点,也不会参与数据的读写。
也就是说,数据库的数据会存在 primary和 secondary 节点中,secondary 节点相当于一个备份。当然 secondary 节点可以有多个,当 primary 节点故障时,secondary 节点有可能变为 primary 节点,典型流程如下图所示: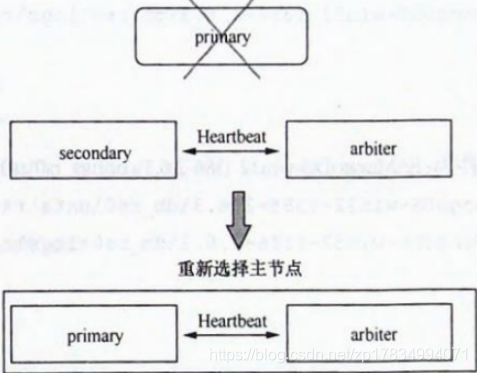
聚集操作分析
聚集操作是对数据进行分析的有效手段。MongoDB 主要提供了三种对数据进行分析计算的方式:
- 管道模式聚集分析
- MapReduce 聚集分析
- 简单函数和命令的聚集分析
1.管道模式进行聚集
这里所说的管道类似于 UNIX 上的管道命令。数据通过一个多步骤的管道,每个步骤都会对数据进行处理,最后返回需要的结果集。管道提供了高效的数据分析流程,是 MongoDB 中首选的数据分析方法。一个典型的管道操作流程如下图所示: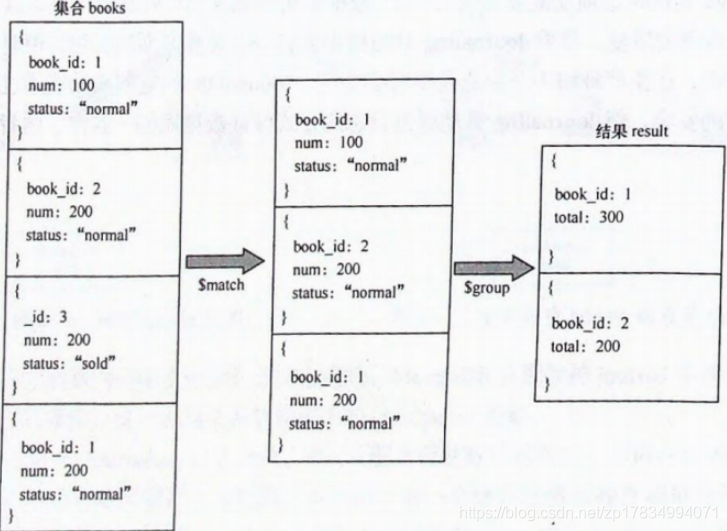
对应的操作语句如下:
db.books.aggregate(
[
{
$match: {status:"normal"}
},
{
$group:{id: "$book id", total:{ $sum: "num"}}
}
]
)数据依次通过数组中的各管道操作符进行处理,常用的管道操作符有以下几个:
$match:过滤文档,只传递匹配的文档到管道中的下一个步骤。
$limit:限制管道中文档的数量。
$skip:跳过指定数量的文档,返回剩下的文档。
$sort:对所有输入的文档进行排序。
$group:对所有文档进行分组然后计算聚集结果。
$out:将管道中的文档输出到一个具体的集合中,这个必须是管道操作中的最后一步。
与$group 操作一起使用的计算聚集值的操作符有以下几个:
$first:返回 group 操作后的第一值。
$last:返回 group 操作后的最后一个值。
$max:返回 group 操作后的最大值。
$min:返回 group 操作后的最小值。
$avg:返回 group 操作后的平均值。
$sum:返回 group 操作后所有值的和。
常用的关系数据库中的 SQL 语句与 MongoDB 聚集操作语句比较如下:
| SQL 语句 | MongoDB 聚集操作语句 |
|---|---|
| select count(*) as count from books | db.books.aggregate([ {$group: {_id:null,count:{$sum: 1}} } ]) |
| select sum(num) as total from books | db.books.aggregate([ {$gruop:{_id:null,total:{$sum: “$num”}} } ]) |
| select book_id, sum(num) as total from books group by book_id | db.books.aggregate([ { $group:{_id:"$book_id",total:{$sum:"$num"}} } ]) |
| select book_id count() from books group by book_id having count() >1 | db.books.aggregate([ {$group: {_id:"$book_id",count:{$sum:1}} },{$match:{count:{$gt:1}} } ]) |
2.MapReduce 模式聚集
MongoDB 也提供了当前流行的 MapReduce 的并行编程模型,为海量数据的查询分析供了一种更加高效的方法,用 MongoDB 做分布式存储,然后再用MapReduce 来做分析。典型 MapReduce 流程如下图所示:
实现代码如下:
db.books.mapReduce(
function()
{
emit (this.book_id,this.num);
},
function(key, values)
{
return Array.sum( values )
},
{
query: { status: "normal" },
outresult: "books totals"
}
)上面的需求实际上是要统计出每种类型的书可以销售的总数。在传统关系数据库上 SQL 语句如下所示:
select sum (num) as value, book id as _id
from books where status = "normal" group by book_id; 接下来我们看看 MapReduce 方式如何解决这种问题,首先定义了一个 map函数,如下所示:
function()
{
emit ( this.book_id, this.num);
} 接着定义 Reduce 函数,如下所示;
function(key, values)
{
return Array.sum( values )
} 最后在集合上执行 MapReduce 函数。
这里有一过滤条件 query: {status: “normal” },返回状态为 normal 的值,同时定义了保存结果的集合名,最后的输出结果将保存在集合 books_totals 中,这里的map、reduce 函数都是利用 JavaScript 编写的函数,其中 map 函数的关键部分是emit(key,value)函数,
此函数的调用使集合中的 document 对象按照 key 值生成一个 value, 形成一个键值对。
其中 key 可以单一 filed,也可以由多个 filed 组成,MongoDB 会按照 key 生成对应的 value 值,value 为一个数组。
reduce 函数的定义中有参数 key 和 value,其中 key 就是上面 map 函数中指定的 key 值,value 就是对应 key 对应的值,Array.sum(value)这里是对数组中的值求和,按照不同的业务需要,我们可以编写自己的 javascript 函数来处理。
3.简单聚集函数
管道模式和 MapReduce 模式都是重型武器,基本上可以解决数据分析中的所有问题,但有时在数据量不是很大的情况下,直接调用基于集合的函数会更简单,常用的简单聚集函数有以下几种:
(1)distinct 函数,用于返回不重复的记录,返回值是数组,函数原型如下:
db.orders.distinct( key,<query>) 第一个参数为 filed,第二个参数为查询选择器,返回值不能大于系统规定的单个文档的最大值,如下图所示:
(2)count 函数,用于统计查询返回的记录总数,函数原型如下:
db.books.find().count ()事务管理
MongoDB 支持 ACID 事务。
1、单文档的原子性。
- 在 MongoDB 中,写操作是单个文档级别的原子操作。
- 当单个写入操作(db.collection.updateMany())修改多个文档时,每个文档的修改都是原子的,但整个操作不是原子的。
2、多文档的原子性。
- 跨多个操作,集合,数据库和文档。
- 要么全成功,要么全失败。
- 在提交事务之前,在外部看不到该事务中的任何写操作。
- 仅适用于副本集。
- 仅适用于使用 WiredTiger 存储引擎的部署。