public class UserProfileTest {
//static String filePath = "hdfs:///user/daily/20200828/*.parquet";
static String filePath = "/user/daily/20200828/part-00057-0e0dc5b5-5061-41ca-9fa6-9fb7b3e09e98-c000.snappy.parquet";
public static void main(String[] args) {
SparkConf sparkConf = new SparkConf()
.setMaster("local")
.setAppName("user_profile_test")
.set(ConfigurationOptions.ES_NODES, "")
.set(ConfigurationOptions.ES_PORT, "")
.set(ConfigurationOptions.ES_MAPPING_ID, "uid");
SparkSession sparkSession = SparkSession.builder().config(sparkConf).getOrCreate();
Dataset<Row> userProfileSource = sparkSession.read().parquet(filePath);
userProfileSource.count();
userProfileSource.write().parquet("hdfs:///user/daily/result2020082808/");
}
}
对应的parquet的read变成了一个job,一个stage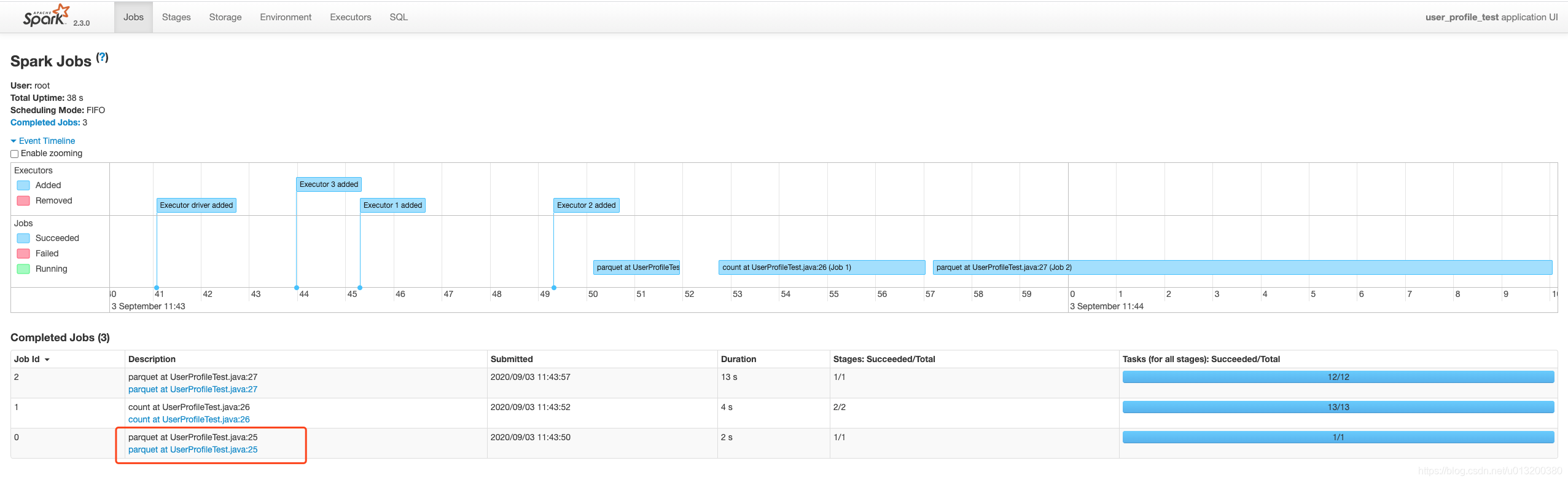
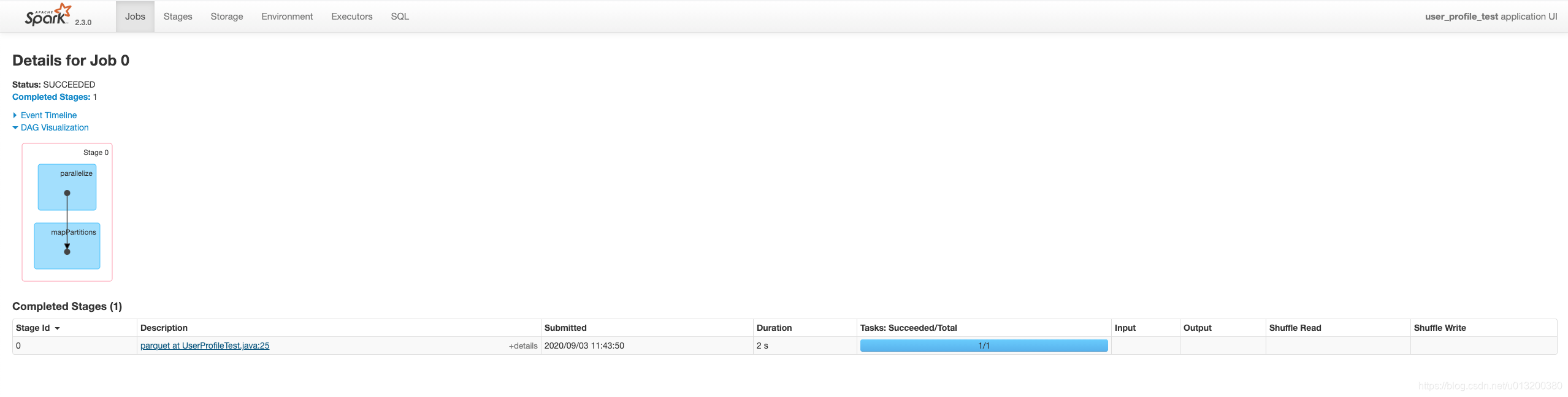
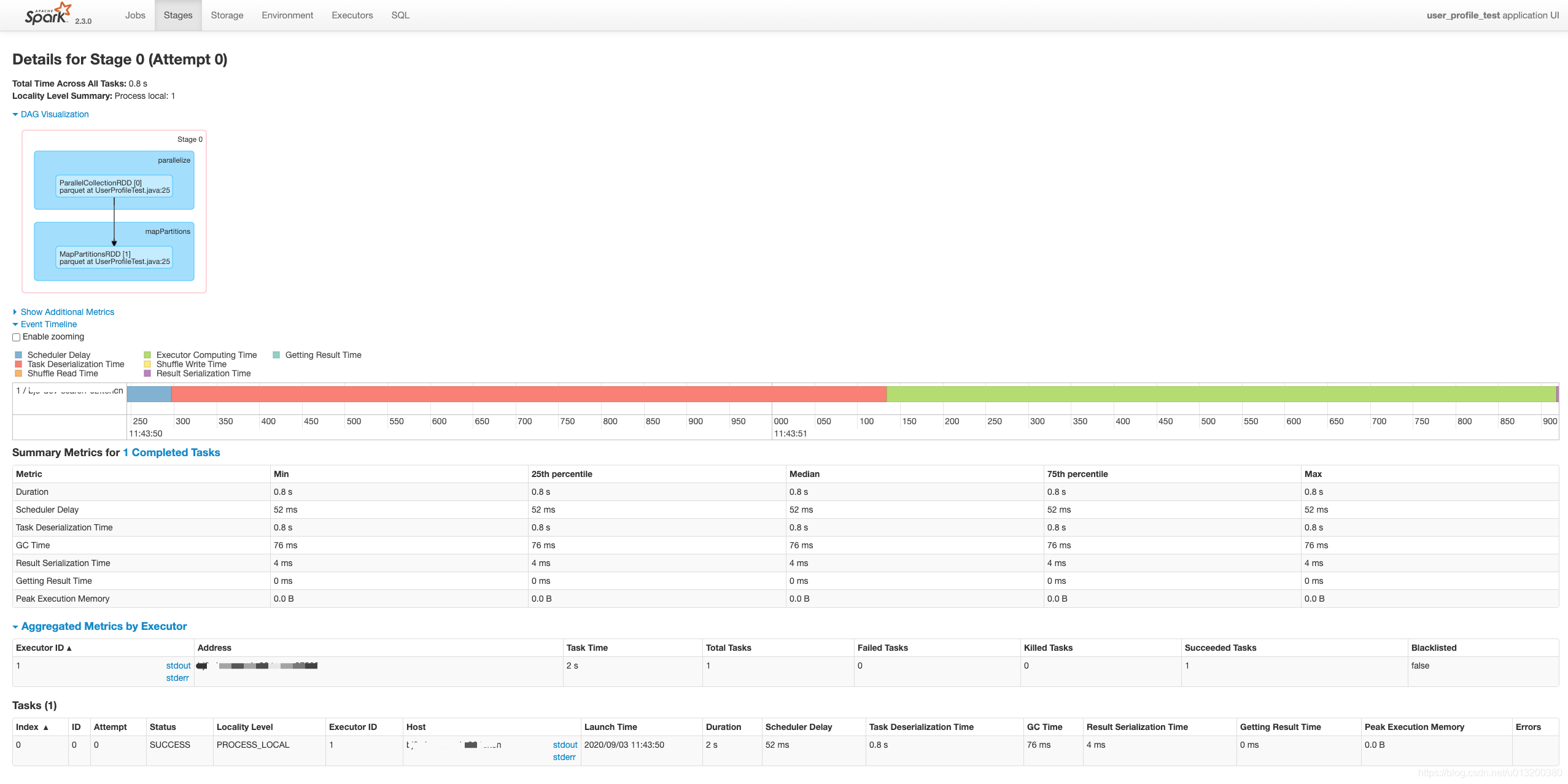
好像是在文件数大于32的时候会多一个job来执行Listing leaf files and directories
版权声明:本文为u013200380原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。