关于传统的DIP中的图像特征,描述子提取及匹配问题,参考
结合openCV学习DIP之传统图像特征与匹配
第一部分DIP基础
图像的简单操作
- imread()加载图像
- imread加载图像文件成为Mat对象
- imread(图像文件名,图像类型,p3)
- p3是附加操作
- IMREAD_UNCHANGED(<0)不做改变加载图像
- IMREAD_GRAYSCALE(0)原图作为灰度图像加载进来
- IMREAD_COLOR(>0)原图作为RGB图像加载进来
- namedWindow
- 创建一个openCV窗口,自动创建与释放
- namedWindow(图像名,p2)
- p2调节图像大小, WINDOW_AUTOSIEZE为自动调节
- imshow()
- 显示图像到指定窗口
- imshow(窗口名,Mat对象)
- cvtColor
- 图像色彩空间转换
- cvtColor(源图像,目标图像,转换操作)
- 转换操作COLOR_BGR2HLS COLOR_BGR2GRAY
- 上述2是to
- imwrite()
- 保存图像
- imwrite(路径,Mat对象)
- 路径包含格式,即保存格式
- 基本的数据类
Point p = Point(20,30);
Size s = Size(1920,1080);
Scalar color = Scalar(255,0,0);
Rect rect = Rect(0,0,1920,1080);cout<<rect.tl();
cout<<rect.br();
cout<<rect.x;
cout<<rect.y;
cout<<rect.width();
cout<<rect.height();显示图片的基本参数
int channels = src.channels();
int height = src.rows;
int width = src.cols;
当图片的像素值超过255时,可以通过如下算子进行调整
src.at<uchar>(row, col) = saturate_cast(12*9);
图像尺寸,色彩空间,元素类型变换
resize(Mat src,
Mat output,
Size(newWidth, newHeight),
interPolation);
src.convertTo(dst, CV_32F); //把CV_8UC1,转换成CV_32F, 32位float数据
cvtColor(Mat, Mat, cv::COLOR_BGR2GRAY);上述的interPolation参数是插值算法,主要有如下参数设置
interPolation参数
INTER_NEAREST //最近邻插值算法
INTER_LINEAR //双线性插值, 默认该参数设置
INTER_AREA. //基于局部像素的重采样
INTER_CUBIC //基于4x4像素邻域的3次插值算法
INTER_LANCZOS4 //基于8x8像素邻域的Lanczos插值算法掩膜
- 图片像素3通道的矩阵是如下排列的:
- [[r11,g11,b11, r12, g12, b12, r13, g13, b13,.........], [r_ij, g_ij, b_ig,],[............]]
- 即第一行有:[r11, g11, b11, r12, g12, b12, r13,g13,b13]
- 第ij个像素的RGB值是连续在一起的,而不是:[r11,r12,r13, g11,g12, g13, b11,b12,b13]
- 掩膜
- 源于硅片雕刻, 意思就是在硅片上选择一个区域, 用一个板子盖住, 然后除了板子盖住的地方, 都被雕刻了.
图像掩膜
就是 用一个图像\图形\物体\矩阵, 对待处理的图像进行遮盖, 来影响处理的区域.
- 掩膜的用法:
- 感兴趣区: 就是上述的图像\图形\物体\矩阵, 用预先制作的感兴趣区掩膜和待处理图像相乘, 得到感兴趣图像, 感兴趣区内
- 首先要获取到图像像素的值:by图像像素指针
- 然后确保输入图像是uchar类型,使用CV_Assert函数判别,参数为FALSE则返回ERROR
- CV_Assert(MyImage.depth() == CV_8U);
- 最后对某些像素值进行处理
- I(i,j) = 5*I(i,j) - [ I(i-1,j) + I(i+1,j) + I(i, j-1)+ I(i, j+1)]
#include "pch.h"
#include <iostream>
#include <opencv2/opencv.hpp>
#include <cmath>
using namespace std;
using namespace cv;
int main(int argc, char ** argv)
{
Mat myImage = imread("图片地址");
CV_Assert(myImage.depth() == CV_8U);
namedWindow("mask_demo", WINDOW_AUTOSIZE);
imshow("mask_demo", myImage);
Mat resultImage;
myImage.copyTo(resultImage);
int nchannels = myImage.channels();
int height = myImage.rows;
int cols = myImage.cols;
int width = myImage.cols*nchannels;
for (int row = 1; row < height - 1; row++)
{
const uchar * previous = myImage.ptr<uchar>(row - 1);
const uchar*current = myImage.ptr<uchar>(row);
const uchar* next = myImage.ptr<uchar>(row + 1);
uchar * output = resultImage.ptr<uchar>(row);
for (int col = nchannels; col < nchannels*(myImage.cols - 1); col++)
{
*output = saturate_cast<uchar>(5 * current[col] - previous[col] - next[col] - current[col - nchannels] - current[col + nchannels]);
output++;
}
}
namedWindow("mask_result", WINDOW_AUTOSIZE);
imshow("mask_result", resultImage);
waitKey(0);
return 0;
}- 如图,行不变列变, 确定row很容易,但是col比较困难
- 困难在于先前我没有弄清楚像素矩阵的具体排列方式,查询后自制了下表(假设从11开始)
- 连着的灰色和白色是像素其下的三通道的值
- current[col-nchannels]就是 g22的下标-3就是g21的下标
- rgb的值是对应加减的,不能用r通道的值去和g通道的值做运算
- 11表示图片的第(1,1)个像素位置,显然每个像素位置存储了3个元素,分别是bgr的元素值

掩模filter2D()
Mat kernel = (Mat_<char>(3,3)<<0,-1,0,-1,5,-1, 0,-1,0);
filter2D(src, dst, src.depth(), kernel);filter即分类器
src.depth是位图深度,32,24,8等
src和dst是Mat对象
int main(int argc, char ** argv)
{
Mat src,dst;
src = imread("地址");
if(!src.data)
{
cout<<"no imgae";
return -1;
}
namedWindow("src_image", WINDOW_AUTOSIZE);
imshow("src_image", src);
Mat Kernel = (Mat_<char>(3,3)<<0,-1,0,-1,5,-1,0,-1,0);
filter2D(src, dst,src.depth(),Kernel);
namedWindow("kernel_image", WINDOW_AUTOSIZE);
imshow("kernel_image", dst);
waitKey(0);
return 0;
}图像在内存中的存储
图像矩阵如何存储在内存中?
在灰度图像的情况下,我们有一些像:
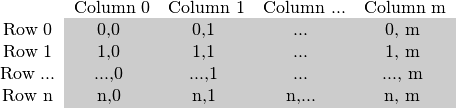
对于多通道图像,列包含与通道数一样多的子列。例如在BGR颜色系统的情况下:

图片中第(0,0) 位置的像素,在存储时实际上是横向存储了三个值,(B(0,0),G(0,0),R(0,0))
注意,通道的顺序是反向的:BGR而不是RGB。因为在许多情况下,内存足够大以便以连续的方式存储行,所以这些行可以一个接一个地跟随,创建一个长行。因为一切都在一个地方,这可能有助于加快扫描过程。
色彩空间
这是关于如何存储像素值。您可以选择使用的颜色空间和数据类型。
颜色空间是指我们如何组合颜色分量以编码给定的颜色。
最简单的一个是灰色,我们可以使用的颜色是黑色和白色。这些组合使我们能够创建许多灰色阴影。
最流行的是RGB,主要是因为这也是我们的眼睛如何建立颜色。其基色为红,绿,蓝。为了编码颜色的透明度有时是第四个元素:添加了α(A)。
然而,还有许多其他颜色系统都有自己的优势:
- RGB是最常见的,因为我们的眼睛使用类似的东西,但请记住,OpenCV标准显示系统使用BGR颜色空间(红色和蓝色通道的开关)组成颜色。
- HSV和HLS将颜色分解为色调,饱和度和值/亮度分量,这是我们描述颜色的更自然的方式。例如,您可能会忽略最后一个组件,使您的算法对输入图像的光线条件不太敏感。
- YCrCb被流行的JPEG图像格式使用。
- CIE L * a * b *是感知统一的颜色空间,如果您需要测量给定颜色与其他颜色的距离,则可方便使用。
每个建筑组件都有自己的有效域。这导致使用的数据类型。我们如何存储组件定义了我们在其域中的控件。可能的最小数据类型是char,这意味着一个字节或8位。这可能是无符号的(因此可以存储从0到255的值)或带符号(从-127到+127的值)。尽管在三个组件的情况下,这已经提供了1600万个可能的颜色来表示(像在RGB情况下),我们可以通过使用浮点数(4字节= 32位)或双(8字节= 64位)数据来获得更精细的控制每个组件的类型。然而,请记住,增加组件的大小也会增加内存中整个画面的大小。
Mat对象
- 学习笔记00和01的问题:
- 出现两个交互窗口,一个灰色,一个是结果,如下图

- 解决:打开项目-属性-链接器-输入-附加依赖项,将配置opencv时添加的依赖项删除一个即可
- dst.size是错误的, size不是对象dst的属性,而是一个方法函数, dst.size(),同理dst.type();
- 出现两个交互窗口,一个灰色,一个是结果,如下图
Mat
Mat对象分两个部分:头部+数据部分
创建Mat对象时,应给出row和col,和元素类型如CV_8UC3,必要时可以同时给出元素值
Mat对象的使用(程序也有一些,此处不再列举)
1). 构造函数Mat()
cv::Mat src=cv::Mat(2, 2, CV_8UC3,Scalar(0,0,255);
Scalar括号内的是2*2矩阵中每个元素的值,显然这里4个元素都是一样的,即(0,0,255)
- Mat dst(行,列, CV_8UC3,具体像素值);
- CV_8UC3, 再如CV_32FC3,CV_32FC1
- 8:每个通道的一个像素占8位
- U:无符号
- C:通道数
- 3:3个通道,决定了Scalar()的参数数量
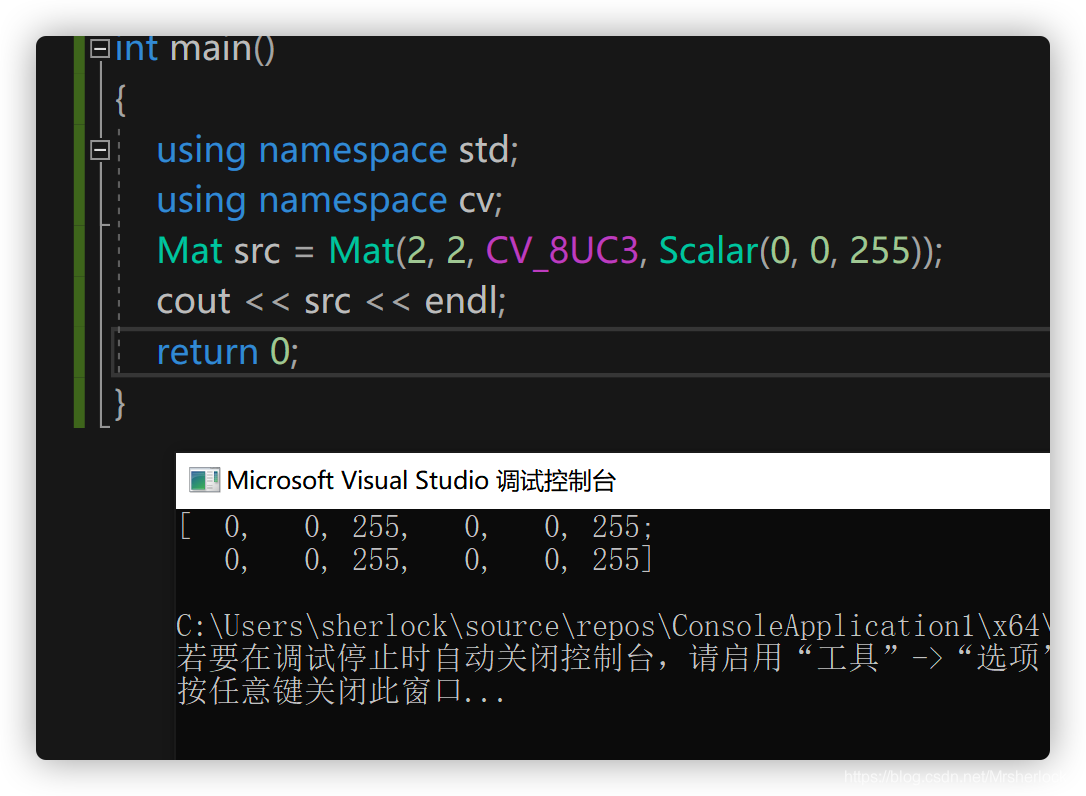

2).Mat对象复制
部分复制:只复制Mat的头和指针部分,不复制数据部分
Mat A = imread(B);
Mat C(D);完全复制
Mat F = A.clone(); F依然随A改变
Mat G; A.copyTo(G); AG互不干涉3). 创建Mat对象的其他方法
Mat_()
Mat filter = (Mat_<double>(3,3)<<0,-1,0,-1,5,-1,0,-1,0);
//<double>表示Mat对象中每个元素的类型
/*
<uchar>
<int>
<float>
*/Mat::zeros()和create()
Mat a = imread("~/a.jpeg");
Mat zero = Mat::zeros(a.size(), a.type());
Mat zero = Mat::zeros(2,2,CV_32FC3);
Mat dst;
dst.create(Size(20, 20), CV_32UC2);
//cv::Mat1d::Mat_(int rows, int cols)
案例:
/***Mat对象的基本使用方法***/
int main(int argc, char ** argv)
{
Mat src;
src = imread("地址");
if(!src.data)
{
cout<<"no data"<<endl;
return -1;
}
namedWindow("src_imgae", WINDOW_AUTOSIZE);
imshow("src_image", src);
Mat dst; //创建一个Mat对象
dst = Mat(src.size(), src.type()); //初始化一个Mat对象,和src的大小类型都一样
dst = Scalar(123,12,132); //赋值, Scalar标量,括号就是RGB的值
namedWindow("dst_image", WINDOW_AUTOSIZE);
imshow("dst_image", dst);
Mat dst_clone =src.clone(); //克隆图像会随着源图像改变而改变
Mat dst_copy; //复制的图像不会因为源图像的变化而变化
src.copyTo(dst_copy);
Mat dst_cvt;
cvtColor(src, dst_cvt, RGB2GRAY); //改变颜色空间
cout<<"src' channels: "<<endl;
cout<<"dst_cvt's channels: "<<endl;
const uchar* dst_cvt_firstRow = dst_cvt.ptr<uchar>(0);
cout<<"dst_cvt's firstRow: "<<*dst_cvt_firstRow<<endl;
int cols = dst.cols; //宽度
int rows = dst.rows; //高度
Mat dst_mat(2,2,CV_8UC3,Scalar(12,122,1));
waitKey(0);
return 0;
}
像素级操作
基于.at()方法
1⃣️获取单通道像素值
int gray_pexls = gray_src.at<int>(row, col); //为什么int后边又是uchar呢?????? 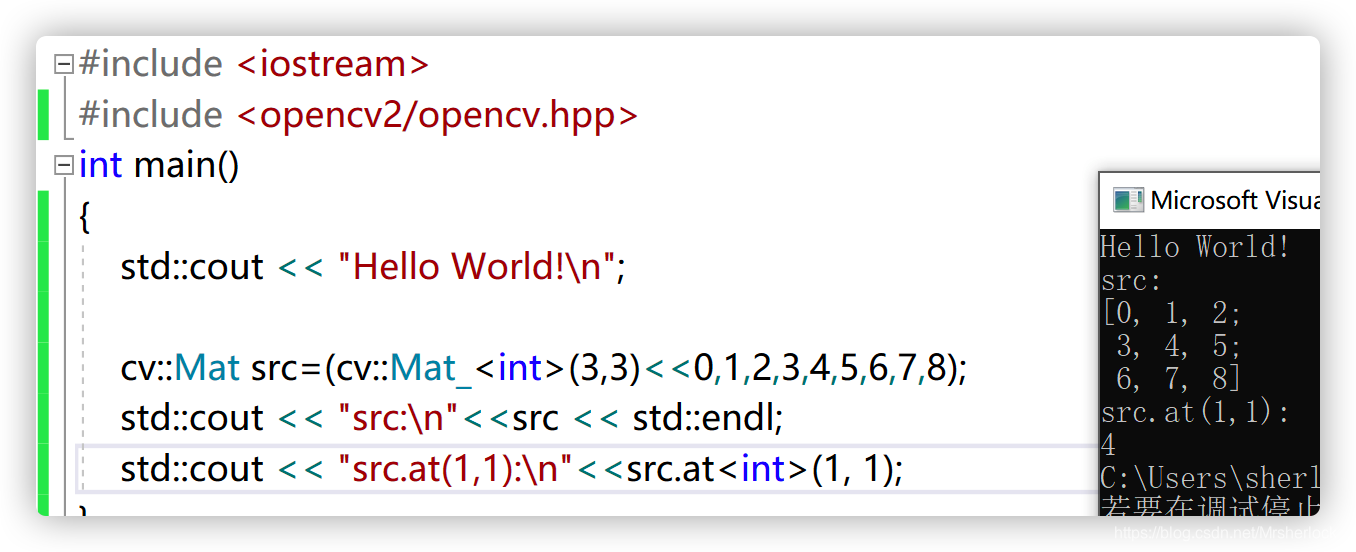
元素黑白互换:
gray_src.at(row, col) = 255 - gray_pexls; //黑白互换2⃣️获取3通道像素值
一个24位的图片,图片的每个像素都是24位,bgr排列为888, 每个8是bgr的数值
注意Vec3f, Vec3i, Vec3d, Vec2d, Vec2i等,数字表示通道数,末尾字母表示类型简写
float b = dst.at<Vec3f>(row, col)[0];
//Vec3b,vec是模板类Vec的对象,3是3通道,对应三通道是BGR的uchar类型数据
double g = src.at<Vec3d>(row, col)[1];
//Vec3d表示3通道,double
int r = src.at<Vec3i>(1,2)[2];
//Vec3i表示3通道int三通道图片反差色实现
bitwise_not(src, dst_f); //位操作,相当于255-rgb#include "pch.h"
#include <iostream>
#include <opencv2/opencv.hpp>
using namespace std;
using namespace cv;
int main(int argc, char ** argv)
{
Mat src;
src = imread("C:\\Users\\xujin\\Desktop\\test.JPG");
if (!src.data)
{
cout << "no image";
return -1;
}
/*namedWindow("src_image", WINDOW_AUTOSIZE);
imshow("src_image", src);
*/
//RGB转单通道
Mat gray_src;
cvtColor(src, gray_src, COLOR_RGB2GRAY);
namedWindow("gray_src_image", WINDOW_AUTOSIZE);
imshow("gray_src_image", gray_src);
int height = gray_src.rows;
int width = gray_src.cols;
for (int row = 0; row < height; row++)
{
for (int col = 0; col < width; col++)
{
//获取单通道像素值
int gray_pexls = gray_src.at<uchar>(row, col); //为什么int后边又是uchar呢??????
//改变单通道图片像素值
gray_src.at<uchar>(row, col) = 255 - gray_pexls; //黑白互换
}
}
namedWindow("gray_src_cvt", WINDOW_AUTOSIZE); //显示改变像素后的gray图
imshow("gray_src_cvt", gray_src);
//改变三通道图片的像素值
Mat dst;
src.copyTo(dst);
int height3 = src.rows;
int width3 = src.cols;
int nc = src.channels();
for (int row = 0; row < height3; row++)
{
for (int col = 0; col < width3; col++)
{
if (nc == 1)
{
//获取单通道像素值
int gray_pexls = gray_src.at<uchar>(row, col); //为什么int后边又是uchar呢??????
//改变单通道图片像素值
gray_src.at<uchar>(row, col) = 255 - gray_pexls; //黑白互换
//src.convertTo(dst, CV_32F); //把CV_8UC1,转换成CV_32F, 32位float数据
}
else
{
//获取3通道像素值, 显然每个像素都是[b,g,r]三维向量
int b = dst.at<Vec3b>(row, col)[0]; //Vec3b,vec是模板类Vec的对象,3是3通道,对应三通道是BGR的uchar类型数据
int g = dst.at<Vec3b>(row, col)[1]; //at是个函数,与之不同函数参数前有<>
int r = dst.at<Vec3b>(row, col)[2]; //Vec3f是同理的float类型数据
dst.at<Vec3b>(row, col)[0] = 255 - b;
dst.at<Vec3b>(row, col)[1] = 255 - g;
dst.at<Vec3b>(row, col)[2] = 255 - r;
}
}
}
namedWindow("dst_image", WINDOW_AUTOSIZE); //显示改变像素后的gray图
imshow("dst_image", dst);
namedWindow("src_image", WINDOW_AUTOSIZE);
imshow("src_image", src);
//利用函数完成上述反差效果
Mat dst_f;
dst = Mat(src.size(), src.type());
bitwise_not(src, dst_f); //位操作,相当于255-rgb
namedWindow("dst_f_image", WINDOW_AUTOSIZE);
imshow("dst_f_image",dst_f);
waitKey(0);
return 0;
}基于指针方法
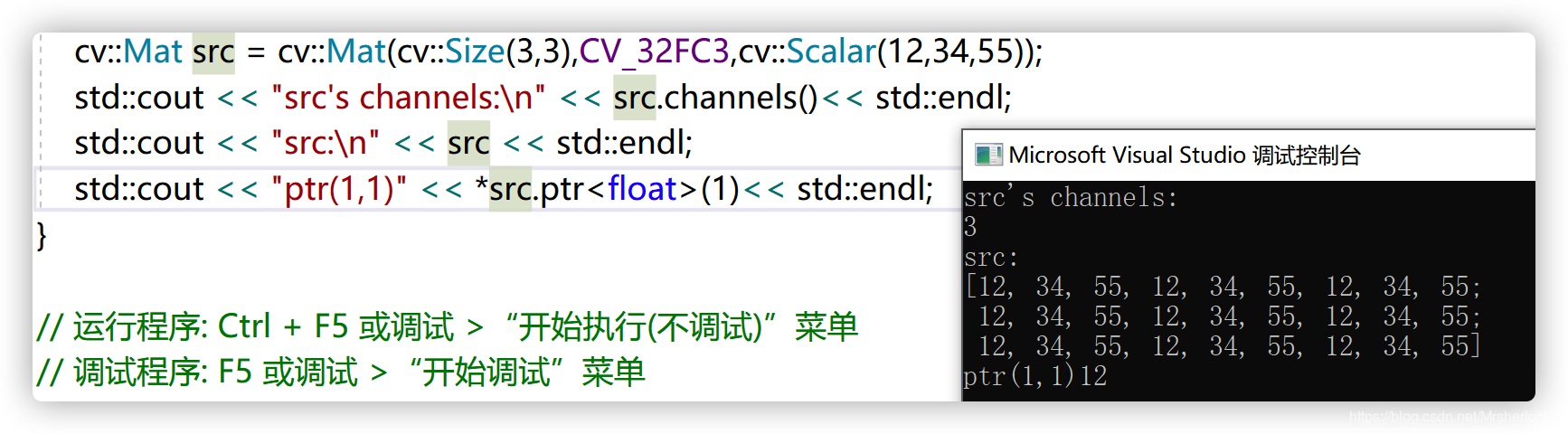
ptr()
返回类型是矩阵元素的类型,若矩阵元素是int类型,需int* cv::ptr(int row);
uchar* cv::ptr<uchar>(int row);
//uchar可以替换成其他类型该接口只能获取指定行的头元素的指针, 如下图:
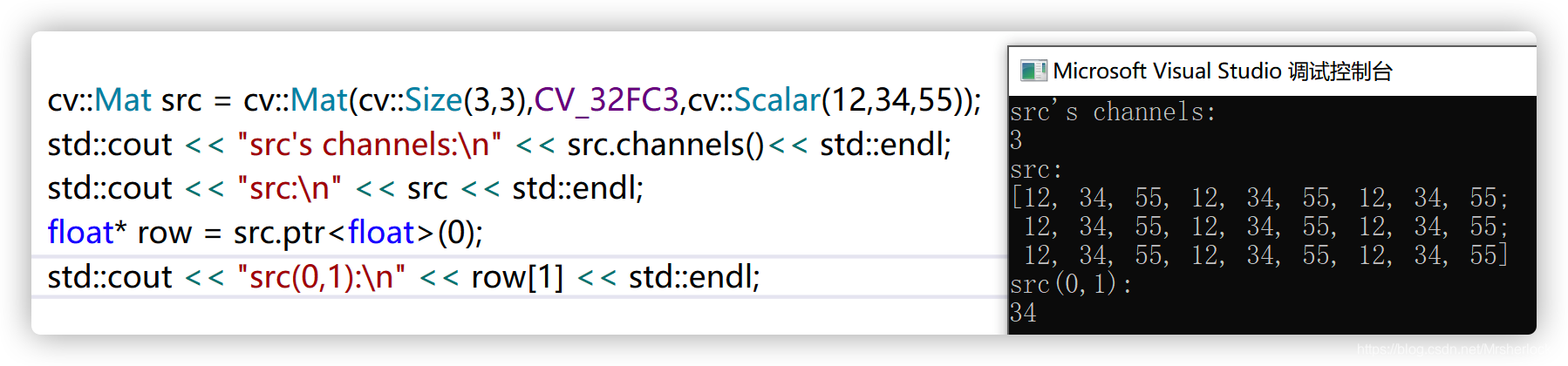
获取行列的指针,则需要再次调用该指针(这里直接将float指针row作为数组使用,详见C++笔记)
案例
Mat src = imread("~/video/a.jpg");
Mat dst = Mat(src.size(), src.type());
int channels = src.channels();
int height = src.rows;
int width = src.cols * channels;
for ( int row = 1; row<height; row++){
const uchar * current = src.ptr<uchar>(row);
const uchar * next = src.ptr<uchar>(row + 1);
const uchar * previous = src.ptr<uchar>(row - 1);
uchar * output = dst.ptr<uchar>(row);
for (int col = channels; col < channels *( src.cols -1); col++){
*output = saturate_cast("");
*output = current[col] * 3 + next[col] - previous[col];
//该层循环内部为像素级操作
output ++;
}
}
图像的线性混合
线性混合模型
α取值0-1
addWeigheted()
addWeighted(InputArray src1,
double alpha,
InputArray src2,
double beta,
double gamma,
Output dst,
int dtype=-1);src1 ,src2 即输入图片
alpha=1-beta
gamma是平衡参数
dst输出对象
#include "pch.h"
#include <iostream>
#include <opencv2/opencv.hpp>
using namespace std;
using namespace cv;
int main(int argc, char ** argv)
{
Mat src0, src1;
src0 = imread("C:\\Users\\xujin\\Desktop\\test0.JPG");
if (!src0.data)
{
cout << "no image";
return -1;
}
namedWindow("src0_image", WINDOW_AUTOSIZE);
imshow("src0_image", src0);
src1 = imread("C:\\Users\\xujin\\Desktop\\test1.JPG");
if (!src1.data)
{
cout << "no image";
return -1;
}
namedWindow("src1_image", WINDOW_AUTOSIZE);
imshow("src1_image", src1);
if (src1.rows == src0.rows && src1.cols == src0.cols && src0.type() == src1.type())
{
Mat dst;
double alpha = 0.2;
double beta = 1 - alpha;
double gamma = 0.0;
int dtype = -1;
addWeighted(src0, alpha, src1, beta, gamma, dst, dtype);
//add(src0, src1, dst, Mat()); 没有参数值会过于生硬
//multiply(src1, src0, dst); 也是一种混合
namedWindow("dst_image", WINDOW_AUTOSIZE);
imshow("dst_image", dst);
}
else
{
cout << "not equal";
return -1;
}
waitKey(0);
return 0;
}绘制形状和文字与随机线
cv::Point类
表示2D平面上的点x,y
属性x和y
Point p; p.y=9; p.x=1;cv::Scalar类
表示四个元素的向量
Scalar(b,g,r);表示bgr三个通道的值,可以表示颜色
cv::line()画直线
line(src0, p1, p2, color, 1, LINE_8, 0); //参数: 背景图,开始点,结束点, 线条颜色, thickness线条厚度, 线条类型LINE_8,LINE_AA 锯齿线
void MyLines()
{
Point p1 = Point(20, 30);
Point p2;
Scalar color = Scalar(0, 0, 255);
p2.x = 300;
p2.y = 300;
line(src0, p1, p2, color, 1, LINE_8, 0); //参数: 背景图,开始点,结束点, 线条颜色, thickness线条厚度, 线条类型LINE_8
}cv::ellipse()画椭圆
ellipse(src0, Point(src0.cols/2, src0.rows/2), Size(src0.cols/4, src0.rows/8),90, 0 ,360, color, LINE_8);
//参数: 背景图, 椭圆中心,椭圆的长短半径, 椭圆躺着的方向, 起始角度,颜色,线型
void Myellipse()
{
Scalar color = Scalar(0, 222, 31);
ellipse(src0, Point(src0.cols/2, src0.rows/2), Size(src0.cols/4, src0.rows/8),90, 0 ,360, color, LINE_8);
//参数: 背景图, 椭圆中心,椭圆的长短半径, 椭圆躺着的方向, 起始角度,颜色,线型
}画矩形cv::rectangle()
创建矩形对象
Rect rect = Rect(200, 100, 300, 300); //参数:左顶点坐标x,y和width\height
rectangle(src0, rect, color, 1, LINE_8); //参数:背景图,矩形对象, 颜色, thickness, 线型
void MyRectangle()
{
Rect rect = Rect(200, 100, 300, 300); //参数:左顶点坐标x,y和width\height
Scalar color = Scalar(233, 1, 22);
rectangle(src0, rect, color, 1, LINE_8); //参数:背景图,矩形对象, 颜色, thickness, 线型
}
画圆cv::circle()
circle(src0, center, radius, color, 1, LINE_8);
//参数: 背景图, 圆心, 半径, 颜色, thickness, 线型
void MyCircle()
{
Scalar color = Scalar(0, 222, 31);
Point center = Point(src0.cols / 2, src0.rows / 2);
int radius = 140;
circle(src0, center, radius, color, 1, LINE_8); //参数: 背景图, 圆心, 半径, 颜色, thickness, 线型
}填充cv::fillPoly()
填充文字putText()
putText(src0, "hello", Point(src0.cols / 2, src0.rows / 2), FONT_HERSHEY_COMPLEX, 2, Scalar(122, 222, 31), 1, LINE_8);
//参数:背景图, 文本内容, 光标起点, 字形,字体大小, 颜色, thickness,线型随机数
RNG类, 随机数产生
RNG 是一个类,首先要产生一个对象,rng_R, next可以取出下一个随机数.
uniform()
可以返回指定范围的均匀分布随机数,即 返回[a,b)范围内均匀分布的整数随机数。
int uniform (int a, int b)
float uniform (float a, float b)
double uniform (double a, double b)
gaussian函数返回一个高斯随机数,fill则用随机数填充矩阵。
还有一些随机数相关的函数,比如randu可以产生一个均匀分布的随机数或者矩阵,randn可以产生一个正态分布的随机数,randShuffle可以随机打乱矩阵元素。
RNG rng(种子);
rng.uniform(double a, double b); uniform类函数用来确定生成界限
void RandomDemo()
{
RNG rng(12345);
Point p1;
Point p2;
Mat bg = Mat::zeros(src0.size(), src0.type());
namedWindow("bg_image", WINDOW_AUTOSIZE);
for (int i = 0; i < 100000; i++)
{
p1.x = rng.uniform(0, src0.cols);
p2.x = rng.uniform(0, src0.cols);
p1.y = rng.uniform(0, src0.rows);
p2.y = rng.uniform(0, src0.rows);
Scalar color = Scalar(rng.uniform(0, 255), rng.uniform(0, 255), rng.uniform(0, 255));
line(bg, p1, p2, color, 1, LINE_8);
imshow("bg_image", bg);
if (waitKey(50) > 0)
{
break;
}
}
}Blur 模糊/滤波
各种滤波API,可以通过像素级别操作完成相同的算法效果,这里只是API
滤波其实是分成了中值滤波和均值滤波,
均值滤波又包含了加权均值滤波,加权均值滤波进一步演化成Gaussian加权均值滤波算法
简单说明:均值滤波就是求滑动窗口内像素平均值,中值滤波就是求中间值,高斯滤波就是按公式来求
使用filter2D()
Mat kernel = (Mat_<double>(3, 3)<<0, 1, 0, 1, 0, 1, 0, 1, 0);
filter2D(Mat src, Mat dst, src.depth(), kernel);
// 上述的filter2D()算子是用来进行滤波操作的
常用的滤波算子
Smooth/Blur是图像处理中最简单的常用操作之一
- 作用:图像预处理降低噪声
- 原理:卷积计算
卷积算子都是线性操作,故线性滤波
- 参考掩膜
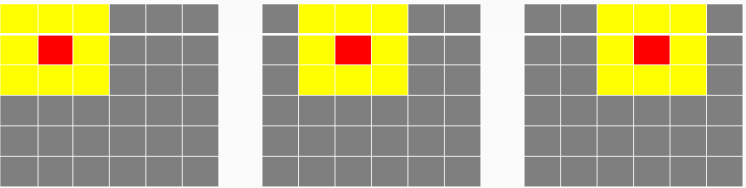
- 假设有6x6的图像像素点矩阵。
- 卷积过程:6x6上面是个3x3的窗口,从左向右,从上向下移动,黄色的每个像个像素点值之和取平均值赋给中心红色像素作为它卷积处理之后新的像素值。每次移动一个像素格
显然周边一圈的像素是得不到新值的, 如何处理呢???
外部扩张,在矩阵外部新插入一圈新像素值,那么新像素值如何取值呢???
1).均值滤波
实际上就是对kernel覆盖的像素进行求均值,然后复制给anchor对应像素
均值滤波:无法克服边缘像素信息丢失缺陷,原因是均值滤波是基于平均权重, 权重都可以看成1
blur()
blur(Mat src, Mat dst, Size(xradius, yradius), Point(-1,-1)); blur模糊
//参数:源图像,输出图像, filter的维度3*3or3*12等,point中心点一般不动2).高斯滤波
高斯滤波:无法完全避免边缘像素信息丢失缺陷,因为没有考虑像素值的不同
GaussianBlur(Mat src, Mat dst, Size(11,11), sigmax, sigmay);
//Size(x,y) x&y必须是正奇数
//参数:源图像,输出图像,filter维度,参数xy类似正态分布, 只考虑空间位置,即靠近纵轴权重越大, 但没有考虑像素本身的数值大小
GaussianBlur 像素级别操作
首先介绍Gaussian加权均值滤波算法,简单来说就是:
对滑动窗口内的每个像素加以权值,而每个滑动窗口的元素正是对应像素的权值,即通过卷积即可完成加权求和,在通过/N可得到像素加权均值,
一般的滑动窗口内的权值是我们自己设计的,这里采用的权值分布是高斯分布(参考正态分布,高斯分布就是正态分布),
一般使用标准2维正态分布,高斯滤波把周围像素对中心像素的距离分布影响考虑进去了

void getGaussianMatrix(int size, double sigma, Mat &Gauss){
Gauss.create(Size(size,size), CV_32F1);
float sum = 0.0
float center = size/2;
//要产生一个3x3的高斯滤波器模板/kernel,要以末班中心位置为原点坐标进行取样,
//center用来平衡周围像素的值
const float PI = 3.1415926;
for (int i =0;i<size;i++){
for(int j =0;j<size;j++){
Gauss.at<float>(i,j) =
(1/(2*PI*sigma*sigma))*exp(-((i-center)*(i-center)+(j-center)*(j-center))/(2*sigma*sigma))
sum += Gauss.at<float>(i,j);
}
}
# 归一化
for (int i =0;i<size;i++){
for(int j=0;j<size;j++){
Gauss.at<float>(i,j) /= sum;
}
}
}由于我们往往采用的是xy独立同分布,所以ρ=0, μ是位置参数,σ是尺度参数
下面程序采用了相同的σ,实际应该有σ_x与σ_y
3).中值滤波:统计排序滤波器
使用场景: 椒盐噪声, 就是图片上多了几个黑白点
 ,还可以参考左右两边max和min值, 中值滤波同上也是赋值给中间像素
,还可以参考左右两边max和min值, 中值滤波同上也是赋值给中间像素
mediaBlur()
medianBlur(Mat src, Mat dst, ksize);4). 双边滤波
高斯双边模糊 – 是边缘保留的滤波方法,避免了边缘信息丢失,保留了图像轮廓不变
既考虑了空间分布,有考虑了数值大小
bilateralFilter()
bilateralFilter(src, dst, d, sigmaColor,sigmaSpace);
/*
参数: 原图,输出图,计算半径(半径内的像素都会被纳入计算),
sigmaColor:值越大,颜色越宽广的像素将相互影响
sigmaSpace:值越大,越远的像素将相互影响
*/MORPGHOLOGY
回调函数
主函数调用回调函数,主函数执行完毕后, 执行回调函数
createTrackbar
createTrackbar(const String& trackbarname,
const String& winname,
int* value,
int count,TrackbarCallback onChange = 0,
void* userdata = 0);- 实例: createTrackbar("Element Size", "dst_image", &element_size, max_size,CallBack_Dem);
- 参数:滑动控件名称,显示在的窗口名称, 初始化阈值(形参指针,故传地址), 控件刻度最大值, 回调函数
- 回调函数可以理解为一个函数变量
- 回调函数原型是void (*TrackbarCallback)(int pos, void* userdata);
- (*TrackbarCallback)为函数void (int pos,void* userdata)的别名
- 回调函数是专门为滑动控件而产生的,
- 第一个形参pos,它表示的是当前滑块所在的位置,它的值是createTrackbar()传给他的,就是初始化阈值
结构元素
getStructuringElement()
- 得到一个结构元素, 如何理解???
- 可以这么理解,之前定义filter\kernel都是先用Mat声明一个对象,然后元素逐个赋值,比较麻烦,这里opencv封装了一个函数,直接指定参数就可以得到一个同样的东西, 只是封装了一下步骤,没有什么优化
- 用直接修改参数的方法得到一个kernel\filter
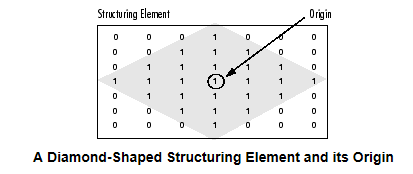
getStructruingElement(shape, ksize, anchor=None);- kernel形状: MORPH_RECT矩形, MORPH_CORSS交叉形, MORPH_ELLIPSE椭圆形等等
- kernel的维度尺寸, (n,n) ,如图的Size(7,7);
- 锚点, (-1,-1)为默认值,如图圈圈
- 上述说的什么形状其实是一个矩阵里有效值的排列显示,如图
- 还可以有其他任意形状
Mat kernel = getStructuringElement(MORPH_RECT, Size(3, 3), Point(-1, -1));
//morphologyEx(src0, dst, MORPH_OPEN, kernel);
//morphologyEx(src0, dst, MORPH_CLOSE, kernel);
//morphologyEx(src0, dst,MORPH_BLACKHAT, kernel);
morphologyEx(src0, dst, MORPH_TOPHAT, kernel);
//morphologyEx(src0, dst, MORPH_GRADIENT, kernel);形态学基础
同或
异或
| a | b | ||
| 0 | 0 | 1 | 0 |
| 0 | 1 | 0 | 1 |
| 1 | 0 | 0 | 1 |
| 1 | 1 | 1 | 0 |
腐蚀
erode(src0, dst, structureElement, Point(-1, -1);简单的说就是把物体向内部收缩了
结构A被结构B腐蚀的定义为, A⨀B=z|(B)z⊆A
结构B看成一个kernel,将B在A图中滑动,每次滑动的结果是B绿块和A红块的同或值(只有当所有的绿块和红块重合才为1)

腐蚀:腐蚀就是求局部最小值的操作。
- 原理:腐蚀可以理解为B的中心(锚点)沿着A的内边界走了一圈。腐蚀也是对高亮部分而言,A区域之外的部分 < A的高亮像素,所里里面被外面取代。A中能完全包含B的像素被留下来了。
- 腐蚀可以简单理解为消除物体A所有边界点的过程。
- 二值时黑底白图时, 可以很容易消除细小的噪点


膨胀
简单的说就是物体外部扩张
结构A被结构B膨胀的定义为, A⨁B=z|(B^)z⋂A≠∅
同样把B看成一个kernel,B在A图中滑动,每次滑动的结果是锚点位置的值,该值是由B的绿块和A的红块求异或(绿块有一个和红块重合就为1)

膨胀: 求局部最大值的操作
- 原理:膨胀或者腐蚀操作就是将图像(或图像的一部分区域,我们称之为A)与核(我们称之为B)进行卷积
- kernel可以是任何形状,它有一个单独定义的参考点, anchor锚点,kernel可以理解成filter掩膜等
- 膨胀就是求局部最大值的操作,核B与图形卷积,即计算核B覆盖的区域的像素点的最大值,并把这个最大值赋值anchor.随着卷积核扫描这个图像, 会使图像中的高亮区域逐渐增长
- 膨胀可以简单理解为将B与A接触的所有背景点合并到A中的过程。

dilate()
dilate(Mat src, Mat output, Mat structElement,Point(-1,-1));

open开操作
- 原理: 先腐蚀后膨胀就称为开操作, 具体运用依然要看前景后景颜色
- 可以去除孤立的小点, 不在图像区域内的小点或者连接桥
- 作用:“去毛刺”
- 理解:最后一步是膨胀,膨胀->扩展->开
morphologyEx(src0, dst, MORPH_OPEN, kernel);
close闭操作
- 原理:先膨胀后腐蚀
- 填充图像内部的断裂点和盆地点
- 作用:“填孔隙”
- 理解:最后一步是腐蚀,腐蚀->收缩->闭
morphologyEx(src0, dst, MORPH_CLOSE, kernel);
顶帽
- top hat 是原图像-开图像
- 作用:“找回毛刺”
morphologyEx(src0, dst, MORPH_TOPHAT, kernel);
黑帽blackhat
- 是闭图像-源图像
- 作用:“找回空隙”
morphologyEx(src0, dst, MORPH_BLACKHAT, kernel);
#include "pch.h"
#include <iostream>
#include <opencv2/opencv.hpp>
#include <string>
using namespace std;
using namespace cv;
Mat src0, src1, dst;
int element_size = 3;
int max_size = 21;
void CallBack_Dem(int, void*);
int main(int argc, char ** argv)
{
src0 = imread("C:\\Users\\xujin\\Desktop\\test0.JPG");
if (!src0.data)
{
cout << "no image";
return -1;
}
namedWindow("src0_image", WINDOW_AUTOSIZE);
imshow("src0_image", src0);
namedWindow("dst_image", WINDOW_AUTOSIZE);
createTrackbar("Element Size", "dst_image", &element_size, max_size,CallBack_Dem);
//CallBack_Dem(0, 0);
Mat kernel = getStructuringElement(MORPH_RECT, Size(3, 3), Point(-1, -1));
//morphologyEx(src0, dst, MORPH_OPEN, kernel);
//morphologyEx(src0, dst, MORPH_CLOSE, kernel);
//morphologyEx(src0, dst,MORPH_BLACKHAT, kernel);
morphologyEx(src0, dst, MORPH_TOPHAT, kernel);
//morphologyEx(src0, dst, MORPH_GRADIENT, kernel);
imshow("dst_image", dst);
waitKey(0);
return 0;
}
void CallBack_Dem(int, void*)
{
int s = element_size * 2 + 1;
Mat structureElement = getStructuringElement(MORPH_RECT, Size(s, s), Point(-1, -1));
dilate(src0, dst, structureElement, Point(-1, -1));
//erode(src0, dst, structureElement, Point(-1, -1);
imshow("dst_image", dst);
return;
}形态学操作应用
先看完阈值操作
保留水平线
用一个列col=1的kernel进行滤波
adaptiveThreshold(~gray, bin, 255, ADAPTIVE_THRESH_MEAN_C, THRESH_BINARY, 3,-2);
Mat hline = getStructuringElement(MORPH_RECT, Size(src0.cols / 15, 1), Point(-1, -1));
保留垂直线
用一个行row=1的kernel进行滤波
adaptiveThreshold(~gray, bin, 255, ADAPTIVE_THRESH_MEAN_C, THRESH_BINARY, 3,-2);
Mat vline = getStructuringElement(MORPH_RECT, Size(1, src0.rows/15), Point(-1, -1));
保留字母
adaptiveThreshold(~gray, bin, 255, ADAPTIVE_THRESH_MEAN_C, THRESH_BINARY, 13,-2);
Mat kernel = getStructuringElement(MORPH_RECT, Size(4,4), Point(-1, -1));
#include "pch.h"
#include <iostream>
#include <opencv2/opencv.hpp>
#include <string>
using namespace std;
using namespace cv;
Mat src0, gray, bin, dst;
int main(int argc, char ** argv)
{
src0 = imread("C:\\Users\\xujin\\Desktop\\ABCD.PNG");
if (!src0.data)
{
cout << "no image";
return -1;
}
namedWindow("src0_image", WINDOW_AUTOSIZE);
imshow("src0_image", src0);
cvtColor(src0, gray, COLOR_BGR2GRAY);
namedWindow("gray_image", WINDOW_AUTOSIZE);
namedWindow("bin_image", WINDOW_AUTOSIZE);
imshow("gray_image", gray);
//二值化
adaptiveThreshold(~gray, bin, 255, ADAPTIVE_THRESH_MEAN_C, THRESH_BINARY, 13,-2);
//注意gray要取反,这里要参考我们的背景颜色, 我用的是白色背景,所以要取反这样二值图片就是黑色背景
imshow("bin_image", bin);
//保留水平线
Mat hline = getStructuringElement(MORPH_RECT, Size(src0.cols / 15, 1), Point(-1, -1));
//保留垂直线
Mat vline = getStructuringElement(MORPH_RECT, Size(1, src0.rows/15), Point(-1, -1));
//保留字母
Mat kernel = getStructuringElement(MORPH_RECT, Size(3,3), Point(-1, -1));
//这里主要是靠kernel的size来抹除细小噪声, 因为噪点比字母要小很多,所以可以靠小的kernel进行抹除
Mat temp;
erode(bin, temp, kernel, Point(-1, -1));
dilate(temp, dst, kernel, Point(-1, -1));
//实际上就是取开操作,以保留水平线为例
//用水平rect,先腐蚀,把不需要的“垂直”像素点腐蚀掉
//随后膨胀,还原被腐蚀的”水平“元素
//erode(bin, temp, vline, Point(-1, -1));
//dilate(temp, dst, vline, Point(-1, -1));
namedWindow("dst_image", WINDOW_AUTOSIZE);
imshow("dst_image", dst);
waitKey(0);
return 0;
}
图像金字塔-上采样和降采样
图像金字塔
调整图像大小,最常见的就是放大(zoom in)和缩小(zoom out)
图像的金字塔是一系列以金字塔形状排列的分辨率逐步降低的图像集合。金字塔的底部是待处理图像的高分辨率表示,而顶部是低分辨率的近似

上采样和下采样
采样的点越多图像越清晰
上采样是扩大分辨率(金字塔向下走)
pyrUp(src0, dst, Size(src0.cols*2, src0.rows*2));下采样是降低分辨率(金字塔向上走)
pyrDown(src0, bin, Size(src0.cols / 2, src0.rows / 2));图像金字塔分类:
1). Gaussian pyramid
主要是下采样,即爬金字塔,注意是gray图
步骤:
- 对当前层进行GaussianBlur高斯模糊,即Gaussian内核卷积
- 删除当前层的偶数行列
2). Laplacian pyramid
主要是上采样,即下金字塔
3) . Difference of Gaussian DOG
注意是gray图
把同一张图的不同GaussianBlur参数所得到的两张图相减,得到输出图像为DOG
差分金字塔,DOG(Difference of Gaussian)金字塔是在高斯金字塔的基础上构建起来的,生成高斯金字塔的目的就是为了构建DOG金字塔。
同组尺寸相同,模糊系数不同; 同层尺寸不同,模糊系数相同;
DOG金字塔的第1组第1层是由高斯金字塔的第1组第2层减第1组第1层得到的。以此类推,逐组逐层生成每一个差分图像,所有差分图像构成差分金字塔。概括为DOG金字塔的第0组第l层图像是由高斯金字塔的第0组第i+1层减第0组第i层得到的。

算法实现
#include "pch.h"
#include <iostream>
#include <opencv2/opencv.hpp>
#include <string>
using namespace std;
using namespace cv;
Mat src0, gray, bin, dst;
int main(int argc, char ** argv)
{
src0 = imread("C:\\Users\\xujin\\Desktop\\test1.JPG");
if (!src0.data)
{
cout << "no image";
return -1;
}
namedWindow("src0_image", WINDOW_AUTOSIZE);
imshow("src0_image", src0);
//上采样
pyrUp(src0, dst, Size(src0.cols*2, src0.rows*2));
namedWindow("dst_image", WINDOW_AUTOSIZE);
imshow("dst_image", dst);
//降采样
pyrDown(src0, bin, Size(src0.cols / 2, src0.rows / 2));
namedWindow("bin_image", WINDOW_AUTOSIZE);
imshow("bin_image", dst);
//DOG 高斯不同
Mat gray_src, g1, g2, dogImg;
cvtColor(src0, gray_src, CV_BGR2GRAY);
GaussianBlur(gray_src, g1, Size(3, 3), 0, 0);
GaussianBlur(g1, g2, Size(5, 5), 0, 0);
subtract(g1, g2, dogImg);
namedWindow("dog_image", WINDOW_AUTOSIZE);
//归一化显示
//normalize(dogImg, dogImg, 255, NORM_MINMAX);
imshow("dog_image", dogImg);
waitKey(0);
return 0;
}
基本阈值操作
图像阈值Threshold
设定一个值, 将图片像素高于或者低于这个值的像素点,进行某种操作,即阈值化操作
threshold(src, dst, value, value_max, type);
//原图,输出图,初始化阈值,阈值最值,阈值类型type就是Treshold类型
Otsu算法:自动决定最优阈值
在对于明暗差异较大时,效果很优秀
threshold(src, dst, TRESH_OTSU, value_max, type);
//另一种方式
threshold(gray, dst, 0, 255, THRESH_OTSU | value);指定了0-255的阈值范围
原理:遍历所有可能阈值, 计算每个阈值结果产生两类像素(高于阈值和低于阈值的像素值)的方差,Otsu算法将使得下式有最小值
阈值类型
TRESHOLD_BINARY阈值二值化

TRESHOLD_BINARY_INV阈值反二值化

TRESHOLD_TRUNC阈值截断

TRESHOLD_TOZERO阈值取零

TRESHOLD_TOZERO_INV阈值反取零

#include "pch.h"
#include <iostream>
#include <opencv2/opencv.hpp>
#include <string>
using namespace std;
using namespace cv;
int threshold_value = 127;
int threshold_max = 255;
void Threshold_demo(int, void*);
int value = 1;
int value_max = 5;
Mat src0, gray, bin, dst;
int main(int argc, char ** argv)
{
src0 = imread("C:\\Users\\xujin\\Desktop\\test1.JPG");
if (!src0.data)
{
cout << "no image";
return -1;
}
namedWindow("src0_image", WINDOW_AUTOSIZE);
imshow("src0_image", src0);
namedWindow("dst_image", WINDOW_AUTOSIZE);
createTrackbar("threshold_value", "dst_image", &threshold_value, threshold_max, Threshold_demo);
createTrackbar("value_choice", "dst_image", &value, value_max, Threshold_demo);
waitKey(0);
return 0;
}
void Threshold_demo(int, void*)
{
cvtColor(src0, gray, CV_RGB2GRAY);
//threshold(gray, dst, threshold_value, threshold_max, value);
//自动调节阈值
threshold(gray, dst, 0, 255, THRESH_OTSU | value);
imshow("dst_image", dst);
}adaptiveThreshold
自适应阈值化操作,这里只用二值化
这个adaptiveTreshold()只能处理单通道8位的图
void adaptiveThreshold(InputArray src,
OutputArray dst,
double maxValue,
int adaptiveMethod,
int thresholdType,
int blockSize,
double C);
/*
参数详解
第一个参数,InputArray src,原图,即输入图像,是一个8位单通道的图像;
第二个参数,OutputArray dst,目标图像,与原图像具有同样的尺寸与类型;
第三个参数,double maxValue,分配给满足条件的像素的非零值;
第四个参数,int adaptiveMethod,自适应阈值的方法,通常有以下几种方法;
ADAPTIVE_THRESH_MEAN_C,阈值T(x,y)是(x,y)减去C的Blocksize×Blocksize邻域的平均值。
ADAPTIVE_THRESH_GAUSSIAN_C ,阈值T(x,y)是(x,y)减去C的Blocksize×Blocksize邻域的加权和(与高斯相关),
默认sigma(标准差)用于指定的Blocksize;具体的情况可以参getGaussianKernel函数;
第五个参数,int thresholdType,阈值的类型必须是以下两种类型,
THRESH_BINARY,正向二值化
THRESH_BINARY_INV ,反向二值化
第六个参数,int blockSize,像素邻域的大小,用来计算像素的阈值,blockSize必须为奇数,例如,3,5,7等等;
第七个参数,double C,从平均数或加权平均数减去常量。通常,它是正的,但也可能是零或负数。
*/
adaptiveThreshold(~gray, bin, 255,
ADAPTIVE_THRESH_MEAN_C,
THRESH_BINARY,
15,-2);
//参数:原图,输出图,二值化算法,阈值类型(不必纠结), 操作块大小(adaptiveThreshold的计算单位是像素的邻域块,邻域块取多大,就由这个值作决定),偏移值调整量(±和0都可以)
//15是邻域块大小,发现自适应二值化得到的不理想时可调整它和偏移量-2
//必要时:gray要取反,这里要参考我们的背景颜色, 我用的是白色背景,所以要取反这样二值图片就是黑色背景卷积
卷积算子
是一个数学概念, 在图像处理中是一个操作, 是kernel(filter,卷积核,算子)在图像的每个像素的操作
kernel本质是个固定大小的小型矩阵, 中心点是anchor锚点, 相当于在图片的海洋中下锚---->操作,即anchor point
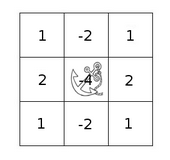
卷积的工作方式
kernel放在像素数组上, 求锚点周围覆盖像素的乘积,然后加起来,替换锚点覆盖下的像素值,即卷积处理

Sum = 8x1+6x1+6x1+2x1+8x1+6x1+2x1+2x1+8x1
New pixel = sum / (m*n)
卷积操作两个核心,一个是kernel的设计, 一个是算子遍历像素的方式
对于kernel的设计,一般的算子有一些经典的,也可以自定义算子
经典卷积算子:
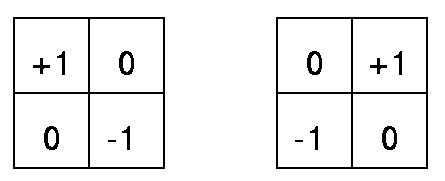
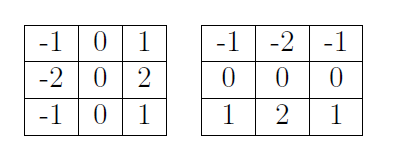
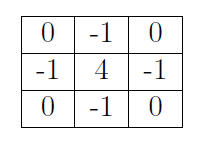
自定义算子;
就是创建一个小型矩阵, 之前学过可以用Mat来创建
Mat kernel = (Mat_(3,3)<<-1,0,-1,-2,0,2,-1,0,1);卷积操作方法filter2D()
filter2D(src, dst, depth, kernel, anchor, delta);
//参数(原图片, 输出图片, 图片深度, 算子, 锚点, delta);案例:
int main(int argc, char ** argv)
{
Mat src, gray, bin, dst;
src = imread("C:\\Users\\xujin\\Desktop\\test1.JPG");
if (!src.data)
{
cout << "no image";
return -1;
}
namedWindow("src_image", WINDOW_AUTOSIZE);
imshow("src_image", src);
Mat dst_x, dst_y;
Mat dstSobel_x, dstSobel_y, dstLap;
src.copyTo(dst_x);
src.copyTo(dst_y);
src.copyTo(dstSobel_x);
src.copyTo(dstSobel_y);
src.copyTo(dstLap);
Mat kernel_x = (Mat_<int>(2, 2) << 1, 0, 0, -1);
Mat kernel_y = (Mat_<int>(2, 2) << 0,-1,-1,0);
Mat kernelSobel_x = (Mat_<int>(3, 3) << -1, 0, -1, -2, 0, -2, -1, 0, -1);
Mat kernelSobel_y = (Mat_<int>(3, 3) << -1,-2,-1, 0, 0, 0, 1, 2, 1);
Mat kernelLap = (Mat_<int>(2, 2) << 0, -1, 0, -1, -4, -1, 0, -1, 0);
filter2D(src, dst_x,-1, kernel_x, Point(-1, -1));
filter2D(src, dst_y, -1, kernel_x, Point(-1, -1)); //filter2D()是进行2D卷积操作的函数, 卷积核是一个小型矩阵,卷积核是设计核心
filter2D(src, dst_y, -1, kernelSobel_x, Point(-1, -1));
filter2D(src, dst_y, -1, kernelSobel_y, Point(-1, -1));
filter2D(src, dst_y, -1, kernelLap, Point(-1, -1));
namedWindow("dst_x_image", WINDOW_AUTOSIZE);
imshow("dst_x_image", dst_x);
namedWindow("dst_y_image", WINDOW_AUTOSIZE);
imshow("dst_y_image", dst_y);
namedWindow("dstSobel_x_image", WINDOW_AUTOSIZE);
imshow("dstSobel_x_image", dstSobel_x);
namedWindow("dstSobel_y_image", WINDOW_AUTOSIZE);
imshow("dstSobel_y_image", dstSobel_y);
namedWindow("dstLap_image", WINDOW_AUTOSIZE);
imshow("dstLap_image", dstLap);
waitKey(0);
return 0;
}
卷积的边缘处理
很容易发现一个问题: 卷积操作时总是对外围的一圈像素无法处理
图像卷积的时候边界像素,不能被卷积操作,原因在于边界像素没有完全跟kernel重叠,所以当3x3滤波时候有1个像素的边缘没有被处理,5x5滤波的时候有2个像素的边缘没有被处理。
处理边缘
在卷积操作前,增加边缘像素并填充像素值
copyMakeBorder(src, dst, top,bottom, left, right, borderType, value);
// 参数:原图片,输出图片,边缘长度,一般上下左右top\bottom\left\right取相同值,边缘类型(即上所属三个),颜色值参数borderType:
- BORDER_CONSTANT – 填充边缘用指定像素值
- BORDER_REPLICATE – 填充边缘像素用已知的边缘像素值。
- BORDER_WRAP – 用另外一边的像素来补偿填充
其实在blur时可以发现,GaussianBlur和一些函数都是有borderType这个参数的
GaussianBlur(src, dst, Size(3, 3), 0, 0, BORDER_CONSTANT);
#include "pch.h"
#include <iostream>
#include <opencv2/opencv.hpp>
#include <string>
using namespace std;
using namespace cv;
int main(int argc, char ** argv)
{
Mat src, gray, bin, dst;
src = imread("C:\\Users\\xujin\\Desktop\\test1.JPG");
if (!src.data)
{
cout << "no image";
return -1;
}
namedWindow("src_image", WINDOW_AUTOSIZE);
namedWindow("dst_image", WINDOW_AUTOSIZE);
imshow("src_image", src);
int top = (int)(0.05*src.rows);
int bottom = (int)(0.05*src.rows);
int left = (int)(0.05*src.cols);
int right = (int)(0.05*src.cols);
RNG rng = (12345);
int borderType = BORDER_CONSTANT;
Scalar color = Scalar(rng.uniform(0, 255), rng.uniform(0, 255), rng.uniform(0, 255));
copyMakeBorder(src, dst, top, bottom, left, right, borderType, color);
GaussianBlur(src, dst, Size(3, 3), 0, 0, BORDER_CONSTANT);
imshow("dst_image", dst);
waitKey(0);
return 0;
}
边缘检测
对于边缘提取算法,我们一般采用Sobel算子检测方法和Canny算法,
Sobel算子对灰度渐变,多噪声图片处理效果很好,但对边缘定位精度较差,即定位不准确(大多数边缘不止一个像素);
Canny算法不容易受到噪声干扰,利用强弱边缘,即弱边缘和强边缘相连时,才将弱边缘考虑,从而容易检测到真正的边缘,即定位精度比较高.
Laplance算子,由于对噪声比较敏感,常不用在边缘检测上
精度要求不高可以考虑Sobel边缘提取方法, 反之考虑Canny边缘提取方法,
Sobel\Laplance算子
卷积应用-图像边缘提取
边缘:是像素值发生跃迁的地方
如何捕捉边缘:对图像像素求一阶导数,显然这里有f(x,y), 对x求偏导,偏导数越大,像素在X轴方向的变化越大,边缘可能性越强
Sobel算子:
Sobel(src, dst, depth, dx,dy,kernelSize,scale, delta,borderType);
//参数:源图像,输出图像,深度,x导数阶数,y导数阶数,
// Sobel算子维度,1,3,5,7, scale, delta, 边缘处理类型Sobel对精度要求不高,同样需要gray图
sobel算子是离散微分算子, 用来计算图像灰度的近似梯度,是一阶微分算子
Sobel算子功能集合高斯平滑和微分求导, 有Sobel算子,我就不用再用高数的方法求导数了
计算方法:
A为原始图, Gx&Gy代表了像素各为X和Y两个方向的像素导数的图片, 计算方法就是两图对应像素相乘再求和
得到Gx和Gy后,需要把Gx和Gy混合成一张图Gxy,
理论:
实践:
convertScaleAbs(A,B),计算绝对值 计算A的元素绝对值,输出给B
sobel算子的理解:
Sobel算子分成横向检测了纵向检测,
边缘的概念,边缘理论上是像素值得突变处,导数正好是变化率的意义,
因此在x轴方向导数最大,则是一个垂直边缘,相反在y轴方向变化最大,则是一个水平边缘,
通过计算像素的差值,得到的图像,越明亮的地方越是边缘
(这也表示,并不是存在差值就是边缘点,而是比较明亮的才是,实现手段就是利用阈值进行过滤),
将xy方向的sobel输出图进行线性混合,则得到了整个图像的边缘信息
实现方法:
高斯模糊-转灰度-Sobel算子求导-XY合成
- GaussianBlur是为了去掉小的噪点, 所以GaussianBlur的filter\kernel不用太大, 3*3就行
- 转灰度是因为Sobel是针对灰度值的
具体而言:
- 理论使用G=sqrt(Gx^2 + Gy^2),实际考虑效率使用|G| = |Gx| + |Gy|,即计算各方向边缘图的绝对值,然后进行线性混合
- 其次计算y方向的边缘信息,得到Gy
- 首先计算x方向的边缘信息,得到Gx
- 灰度处理
- 得到图片后,先对图片进行增强,利用GaussianBlur过滤噪点
- 最后,根据阈值T,若G(row,col)大于T,则认为是边缘点,过滤后得到最后的G,即图片边缘信息图(这里是单阈值)
Mat src = imread(“path”);
Mat gray;
Mat output_x;
Mat output_y;
Mat output_absx;
Mat output_absy;
Mat sobel_image;
Mat output_laplance;
cvtColor(src, gray, COLOR_BGR2GRAY);
//Sobel(Mat src, Mat output, int depth,
// int dx, int dy,int ksize,double scale,
// double delta,int borderType);
//Sobel边缘检测算法实现基于cv::Sobel
Sobel(src,output_x,src.depth(),1,0,3); # 一般只用到前几个参数,dx和dy选择哪个方向就置1
convertScaleAbs(output_x,output_absx);
Sobel(src,output_y,src.depth(),0,1,3);
convertScaleAbs(output_y,output_absy);
addWeighted(output_absx,0.5,output_absy,0.5,sobel_image);
Mat k_sobel_x = (Mat_<double>(3,3)<< -1, 0, 1,
-2, 0, 2,
-1, 0, 1);
Mat k_sobel_y = (Mat_<double>(3,3)<< -1, -2, -1,
0, 0, 0,
1, 2, 1);
//x和y的滑动结果需要分别取绝对再相加,就得到了xy两方向的像素导数值,及时调用
//绝对值api
convertScaleAbs(
Mat k_laplance =(Mat_<double>(3,3)<< 0, -1, 0,
-1, 4, -1,
0 , -1, 0);
filter2D(Mat src, Mat output,src.depth(),Mat kernel); 案例:
#include "pch.h"
#include <iostream>
#include <opencv2/opencv.hpp>
#include <string>
using namespace std;
using namespace cv;
int main(int argc, char ** argv)
{
Mat src, gray, bin, dst;
src = imread("C:\\Users\\xujin\\Desktop\\test1.JPG");
if (!src.data)
{
cout << "no image";
return -1;
}
namedWindow("src_image", WINDOW_AUTOSIZE);
namedWindow("dst_image", WINDOW_AUTOSIZE);
imshow("src_image", src);
GaussianBlur(src, dst, Size(3, 3), 0, 0);
Mat dst_gray;
cvtColor(dst, dst_gray, CV_BGR2GRAY);
imshow("dst__gray_image", dst_gray);
Mat xgrad, ygrad;
//同样可使用Scharr算子,即Sobel算子的升级版
Scharr(dst_gray, xgrad, CV_16S, 1, 0, 3);
Scharr(dst_gray, ygrad, CV_16S, 0, 1, 3);
//Sobel(dst_gray, xgrad, CV_16S, 1, 0, 3);
//Sobel(dst_gray, ygrad, CV_16S, 0, 1, 3);
convertScaleAbs(xgrad, xgrad);
convertScaleAbs(ygrad, ygrad); //Abs绝对值
imshow("xgrad", xgrad);
imshow("ygrad", ygrad);
imshow("dst_image", dst);
Mat dst_xygrad;
//XY梯度混合
//addWeighted(xgrad, 0.5, ygrad, 0.5, 0, dst_xygrad);
//不适用API来实现
dst_xygrad = Mat(xgrad.size(), xgrad.type());
int width = dst_xygrad.cols;
int height = dst_xygrad.rows;
for (int row = 0; row < height; row++)
{
for (int col = 0; col < width; col++)
{
int xg = xgrad.at<uchar>(row, col);
int yg = ygrad.at<uchar>(row, col);
int xy = xg + yg;
dst_xygrad.at<uchar>(row, col) = saturate_cast<uchar>(xy);
}
}
imshow("dst_XYimage", dst_xygrad);
waitKey(0);
return 0;
}
Laplance算子
Laplacian(src, dst, depth, ksize, scale, delta,borderType);
//参数: 源图像, 目标图像, 图像深度,核大小, 比例因子,delta,边界类型原理:
针对二阶导数, 一阶导数峰值点对应二阶导数为0,根据二阶导数为0,提取边缘像素位置
Laplacian()函数通过加上Sobel算子得到的x和y方向上的导数,来得到Laplace变换的结果, 所以不需要分别求导再相加
实现方法:
高斯模糊-Laplacian()直接输出
#include "pch.h"
#include <iostream>
#include <opencv2/opencv.hpp>
#include <string>
using namespace std;
using namespace cv;
int main(int argc, char ** argv)
{
Mat src, gray, bin, dst;
src = imread("C:\\Users\\xujin\\Desktop\\test1.JPG");
if (!src.data)
{
cout << "no image";
return -1;
}
namedWindow("src_image", WINDOW_AUTOSIZE);
namedWindow("dst_image", WINDOW_AUTOSIZE);
imshow("src_image", src);
GaussianBlur(src, dst, Size(3, 3), 0, 0);
imshow("dst_image", dst);
Mat dst_gray;
cvtColor(dst, dst_gray, CV_BGR2GRAY);
namedWindow("dstGray_image", WINDOW_AUTOSIZE);
imshow("dstGray_image", dst_gray);
Mat dstGray, edgImage;
GaussianBlur(src, dst, Size(3, 3), 0, 0);
cvtColor(dst, dstGray, COLOR_BGR2GRAY);
Laplacian(dstGray, edgImage, CV_16S, 3);
convertScaleAbs(edgImage, edgImage);
namedWindow("Lap_image", WINDOW_AUTOSIZE);
imshow("Lap_image", edgImage);
waitKey(0);
return 0;
}
Canny边缘检测算法
Canny算法是边缘检测算法, 是一个很好的边缘检测器
注意:Canny()得到的是二值图像
Canny(src, edges, threshold1, threshold2, Size, L2gradient);
//参数:原图片, 仅有边缘的图片, 低阈值, 高阈值, Sobel算子(计算梯度的算子)大小,
// L2gradient若为true,则用L2来归一化, false则L1归一化Canny算法五步骤:
- GaussianBlur去噪点
- 灰度转换cvtColor
- 计算像素梯度Sobel/Scharr
- 非最大值抑制(x\y方向上不是最大值的去掉)
- 高低阈值输出二值图像
其中高低阈值输出时:
T1,T2为阈值, T2:T1 = 3:1 or 2:1, T2为高阈值, T1为低阈值
若像素>T2的像素,保留
若像素>T1且和>T2的像素相互连接, 则保留该像素
Canny算法实现
流程如下
GaussianBlur去噪点
灰度处理
计算Sobel梯度信息
NMS(非最大值抑制)得到疑似边缘点
简单说明,就是寻找像素点局部最大值,将非极大值点对应的灰度值设置为背景像素点而非边缘像素点, 像素点邻域内满足梯度值最大的点则判为边缘像素点,
上述操作完成了对非极大值点的抑制,提出了大部分非边缘点
此时得到的像素点是疑似边缘点
双阈值Double-Treshold来检测且定位真正的边缘和潜在的边缘,即强弱边缘
疑似边缘点高于高阈值,则保留
疑似边缘点低于低阈值,则排除
疑似边缘点在高低阈值中间时,则判断该像素是否连接到一个保留像素点, 连接则保留,反之排除
//cv::Canny()
Mat src =imread(“path”);
Mat src_gray;
Mat output;
GaussianBlur(src,src,Size(3,3),0,0,BORDER_DEFAULT);
cvtColor(src, src_gray, COLOR_BGR2GRAY);
int T1 = 40;
int T2 =190;
Canny(src_gray,output,T1,T2,3,true);
//Canny(Mat src, Mat output, double threshold1, thrshold2,int kernelSize, bool L2gradient=false)
//L2gradient=false时则用L1归一化,ture则用L2
案例:
#include "pch.h"
#include <iostream>
#include <opencv2/opencv.hpp>
#include <string>
using namespace std;
using namespace cv;
int t1 = 50;
int t2 = t1 * 2;
int max_value = 255;
void cannyCallback(int, void*);
Mat src, gray, bin, dst, canny;
int main(int argc, char ** argv)
{
src = imread("C:\\Users\\xujin\\Desktop\\test1.JPG");
if (!src.data)
{
cout << "no image";
return -1;
}
namedWindow("src_image", WINDOW_AUTOSIZE);
namedWindow("dst_image", WINDOW_AUTOSIZE);
namedWindow("dstGray_image", WINDOW_AUTOSIZE);
namedWindow("canny_image", WINDOW_AUTOSIZE);
imshow("src_image", src);
cvtColor(src, gray, COLOR_BGR2GRAY);
imshow("dstGray_image", gray);
createTrackbar("cannyT1T2", "canny_image", &t1, max_value, cannyCallback);
cannyCallback(0, 0);
waitKey(0);
return 0;
}
void cannyCallback(int, void*)
{
blur(gray, bin, Size(3, 3), Point(-1, -1), BORDER_DEFAULT);
Canny(bin, canny, t1,t2, 3, false);
imshow("canny_image", canny);
}霍夫变换
主要用来寻找直线
霍夫直线变换原理
直线的方程表示可以由斜率和截距表示
用参数空间(k,b)也是可以表示一条直线的
但是存在k-->∞的情况,因此提出霍夫变换

用参数(r,θ)霍夫空间,可以直接表示直线
在霍夫空间中, 每一个点(r,θ)表示一条直线
笛卡尔坐标系中, 以一定点(x0,y0)做的所有的线,在极坐标系中显示为一正弦曲线, 显然改变定点,即移动该曲线,
极坐标中正弦曲线有m个交点, 那么笛卡尔坐标系中就有m个共线的点,即该线为直线

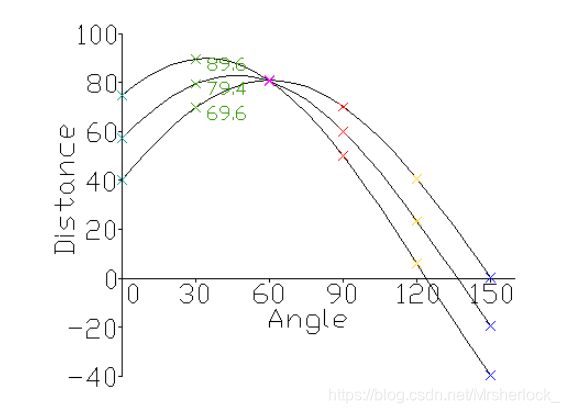
霍夫直线变换的功能
直线检测实现
把笛卡尔坐标系中所有的像素点, 利用hough变换, 转换到极坐标系中;在笛卡尔坐标系中共线的点,反映在极坐标中就是曲线的焦点, 如果是m条直线,那么反映在极坐标系中,则会产生m个颜色很深的点(或很亮的点), 提取这几个点,反变换到笛卡尔坐标系, 即找到直线
标准霍夫变换
HoughLines() 从平面坐标转换到霍夫空间,返回极坐标系中的点(θ, r),
该接口一般是有经验的开发者使用,需要自己反变换到平面空间, 不作介绍.
HoughLinesP()
霍夫变换直线HoughLinesP,返回直线的两个点(x0,y0, x1,y1);
返回值用vector<Vec4f> result; Vec4f表示一个只包含4个float值的vector
HoughLinesP(
InputArray src, // 输入图像,必须8-bit的灰度图像
OutputArray lines, // 输出的四个坐标,x0,y0,x1,y1也就是两个Point
double rho, // 生成极坐标时候的像素扫描步长,一般为1
double theta, //生成极坐标时候的角度步长,一般取值CV_PI/180
int threshold, // 阈值,只有获得足够交点的极坐标点才被看成是直线
double minLineLength=0;// 最小直线长度
double maxLineGap=0;// 最大间隔
)实现步骤:
先边缘检测
再hough检测
#include "pch.h"
#include <iostream>
#include <opencv2/opencv.hpp>
#include <string>
using namespace std;
using namespace cv;
int main(int argc, char ** argv)
{
Mat src, dst;
src = imread("C:\\Users\\xujin\\Desktop\\test1.JPG");
if (!src.data)
{
cout << "no image";
return -1;
}
namedWindow("src_imgae", WINDOW_AUTOSIZE);
namedWindow("src_gray_imgae", WINDOW_AUTOSIZE);
namedWindow("dst_imgae", WINDOW_AUTOSIZE);
imshow("src_image", src);
Mat src_gray;
Canny(src, src_gray, 100, 200);
imshow("src_gray_image", src_gray);
cvtColor(src_gray, dst, CV_GRAY2BGR);
vector<Vec4f>plines;
HoughLinesP(src_gray, plines, 1, CV_PI / 180.0, 10, 0, 5);
Scalar color = Scalar(0, 0, 255);
for (size_t i = 0; i < plines.size(); i++)
{
Vec4f hline = plines[i];
line(dst, Point(hline[0], hline[1]), Point(hline[2], hline[3]), color, 1, LINE_AA);
}
imshow("dst_image", dst);
waitKey(0);
return 0;
}轮廓检测
轮廓检测流程:
- 灰度处理
- 二值化,需要CV_8UC1类型的图片
- 检测轮廓
- 绘制轮廓
findContours()
参数output_contours类型是vector>类型,意思是:
实际上检测了m个轮廓,即vector, 每个轮廓是一系列的点集合,即vector, 想访问某个轮廓可以for循环vector,得到的是vector
返回的是 vector< vector< Point> > output; 轮廓的二维点集. 每一行表示一个轮廓的点的集合
Mat src = (“path”);
Mat output_contours;
cv::findContours(Mat src, vector<vector<Point>>output_contours,
int mode,int method, Point offset = Point());
/*
mode:轮廓检索类型
RETR_EXTRENAL,外面的轮廓,
RETR_LIST,所有轮廓,并保存到列表中,
RETR_CCOMP,所有轮廓,并组成两层,一个外轮廓一个内轮廓,
RETR_TREE,检测所有轮廓,并按层次分成树结构,这个比较常用
method:轮廓逼近方法
CHAIN_APPROX_NONE,直接画出轮廓,
CHAIN_APPROX_SIMPLE,只保留关键点,比如长方形是四个顶点
*/

findContours()和drawContours()
雷区: 输入图片是三色道才能显示彩色线, findContours()输入的是CV_8*C1类型的图片,想要绘制彩图时,务必对drawContours输入CV_8*C3的图片
特殊寻找算法下可以使用其他深度的CV_****图片
void cv::drawContours( InputOutputArray image,
InputArrayOfArrays contours,
int contourIdx,
const Scalar & color,
int thickness = 1,
int lineType = LINE_8,
InputArray hierarchy = noArray(),
int maxLevel = INT_MAX,
Point offset = Point()
) ;
#include "opencv2/imgproc.hpp"
#include "opencv2/highgui.hpp"
using namespace cv;
using namespace std;
int main( int argc, char** argv )
{
Mat src;
// the first command-line parameter must be a filename of the binary
// (black-n-white) image
if( argc != 2 || !(src=imread(argv[1], 0)).data)
return -1;
Mat dst = Mat::zeros(src.rows, src.cols, CV_8UC3);
src = src > 1;
namedWindow( "Source", 1 );
imshow( "Source", src );
vector<vector<Point> > contours;
vector<Vec4i> hierarchy;
findContours( src, contours, hierarchy,
RETR_CCOMP, CHAIN_APPROX_SIMPLE );
// iterate through all the top-level contours,
// draw each connected component with its own random color
int idx = 0;
for( ; idx >= 0; idx = hierarchy[idx][0] )
{
Scalar color( rand()&255, rand()&255, rand()&255 );
drawContours( dst, contours, idx, color, FILLED, 8, hierarchy );
}
namedWindow( "Components", 1 );
imshow( "Components", dst );
waitKey(0);
}案例:
LearnOpencvDIPAndQt::LearnOpencvDIPAndQt(QWidget *parent)
: QMainWindow(parent)
{
ui.setupUi(this);
using namespace cv;
using namespace std;
QFileDialog file;
QString path = file.getOpenFileName(nullptr, "SELECT", QDir::currentPath(), "all(*.*)");
ConvertMatQImage cvt;
string stdPath = path.toStdString();
Mat m = imread(stdPath);
Mat gray;
Mat gaussianM;
GaussianBlur(m, gaussianM, Size(3, 3), 1);
cvtColor(gaussianM, gray, COLOR_BGR2GRAY);
Mat threshImg;
threshold(gray, threshImg, 0, 255, THRESH_OTSU);
Mat result = Mat::zeros(m.rows, m.cols, CV_8UC3);
vector<vector<Point>> contour;
findContours(threshImg, contour, RETR_LIST, CHAIN_APPROX_NONE);
for (int idx = 0; idx < contour.size(); idx++)
{
drawContours(result, contour, idx,Scalar(255,0,0));
}
namedWindow("output", WINDOW_AUTOSIZE);
imshow("output", result);
QImage resultImg = cvt.matToQImage(&result);
ui.label->setPixmap(QPixmap::fromImage(resultImg));
}视频
视频的读取
VideoCapture cap ("~/video/a.mp4");
VideoCapture cap(0);
VideoCapture cap;
cap.open("~/video/a.mp4")
if(cap.isOpened()){}
Mat frame;
cap>>frame;
cap.read(frame);
if(cap.read(frame)){}
if(frame.empty()){}
cap.release();上述是从视频或视频流中读取图片,判断读取内容,接下来需要解析图片参数
VideoCapture cap("~/video/a.mp4");
Mat frame;
cap>>frame;
//cap.read(frame);
int width = cap.get(CV_CAP_PROP_FRAME_WIDTH);
int height = cap.get(CV_CAP_PROP_FRAME_HEIGHT);
int frameRate = cap.get(CV_CAP_PROP_FPS);
int totalFrames = cap.get(CV_CAP_PROP_FRAME_COUNT);总帧数模板匹配
总结:
模版匹配就是那一个小图去匹配一个大图, 输入的图片是8位or32位,不限制通道,
输出结果是一张通过算法计算得到的数值图,非图像图,根据算法不同,定位出数值图的最大值或最小值,即为匹配点
匹配点是Point对象, 想要在原图中绘制图矩形框,还需要模板的长宽
matcTemplate()
cv::matchTemplate(Mat src, Mat template,Mat result,int method,Mat mask);
如果你的图片size是WxH,模板size是wxh,那么你会得到一个(W-w+1)*(H-h+1)的图片,
mask不是必须参数
result就是得到值,也是个Mat对象:
意味着:
这里的元素都是相关的匹配方法的计算结果数值,
可以通过minMaxLoc()来定位出最小值(我们这里用方差匹配),和最小值所在的位置,这个位置就是图片中位置,
也就是说,得到的result通过minMaxLoc()可以得到:方法匹配数值结果和模板在图片中左上角的像素点坐标,
下一步你可以根据这个信息,来画个框,框出你的匹配结果

左边是模板,右边是图片,模板在图像上滑动,从而寻找模板在图片中的位置
然后两图片逐像素比较,有点暴力匹配了,就是比较像素差异,一般的算法是相减然后平方,得到的数越小,像素点之间的相似程度越高,
这里有很多不同的方法template match modes
TM_SQDIFF 方差匹配
TM_SQDIFF_NORMED 归一化方差匹配
TM_CCORR 相关性匹配
TM_CCORR_NORMED 归一化相关性匹配
TM_CCOEFF 相关系数匹配
TM_CCOEFF_NORMED 归一化相关系数匹配方差匹配法用最小值来表示最佳匹配,而相关性和相关系数两个方法用最大值表示最佳匹配
归一化是用来把匹配结果数据进行归一化,使其显示在0-1,可以理解为0-255,这样你可以直观看到结果图片的亮度,
int main() {
Mat tmp = imread("C:/Users/sherlock/Pictures/template.jpg");
Mat src = imread("C:/Users/sherlock/Pictures/test.jpg");
Mat result;
Mat dst;
src.copyTo(dst);
Point minLoc;
double minVal;
matchTemplate(src, tmp, result, TM_SQDIFF_NORMED);
cout << result.size() << endl;
minMaxLoc(result, &minVal, 0, &minLoc, 0);
Point result_rect = minLoc;
Size result_size = tmp.size();
rectangle(dst, Rect(minLoc, tmp.size()), Scalar(0, 100, 255), 1, 8, 0);
cout << minLoc << endl;
cout << minVal << endl;
imshow("tmp", tmp);
imshow("src", src);
imshow("result", result);
imshow("drawResult", dst);
waitKey(0);
return 0;
}
最大值最小值定位函数
cv::minMalLoc();
cv::minMaxLoc(Mat src, double* minVal, double* maxVal,
Point* minLoc, Point* maxLoc);
必须是8bit channels=1
Mat src = (Mat_<uchar>(2,2)<<28,21,12,3);
src.convertTo(src,CV_8UC1);
Point minLoc,maxLoc;
double minVal,maxVal;
minMaxLoc(src,&minVal,&maxVal,&minLoc,&maxLoc);
cout<<src<<endl;
cout<<minLoc<<endl;
cout<<minVal<<endl;
目标追踪
追踪器
tracking是基于视觉的目标跟踪扩展库,在opencv_contrib模块中
在tracking模块中,包含了很多目标跟踪的class,例如:
cv::Detector
cv::MultiTracker
cv::Tracker
cv::TrackerKCF //显然这是cv::Tracker的子类,继承了Tracker的cen
cv::TrackerMIL
首先要包含tracker头文件
#include <opencv2/tracking/tracker.hpp>创建追踪器(由于创建的是个指针类,所以采用->符号来访问类函数(方法))
Ptr<TrackerMIL> tracker= TrackerMIL::create();
Ptr<TrackerTLD> tracker= TrackerTLD::create();
Ptr<TrackerKCF> tracker = TrackerKCF::create();
Ptr<TrackerMedianFlow> tracker = TrackerMedianFlow::create();
Ptr<TrackerBoosting> tracker= TrackerBoosting::create();
tracker->init(frame,bbox);
tracker->update(frame,bbox);多目标追踪器
MultiTracker multi_trackers;
multi_trackers.add();
multi_trakcers.getObjects();
multi_trackers.getObjects().size();
bool cv::MultiTracker::add(Ptr<Tracker> newTracker,InputArray image,const Rect2d &boundingBox);
//.add()方法返回一个bool变量,表示成功与否,这里是添加一个追踪器和感兴趣box
bool cv::MultiTracker::add(vectro<Ptr<Tracker>> newTrackers, InputArray image, vector<Rect2d> boundingBoxes);
//.add()方法的重载是添加一组追踪器和对应感兴趣boxes
const vector<Rect2d> & cv::MultiTracker::getObjects() const;
//.getObjects()方法是返回MultiTracker类对象的objects成员,
//这个成员就是存储了全部的bboxes,是vector<Rect2d>类型,就是返回了个vector对象
//所以可以通过.size()方法来进行.getObjects().size()获得bboxes总个数,即vector总长度
//也可以通过[]访问某个bbox,即.getObjects9()[k]访问第k个bbox,得到的是个Rect类对象
bool::cv::MultiTracker::update(InputArray image)
//更新跟踪器状态,更新结果保存在MUltiTracker对象内部的跟踪器成员中
bool::cv::MultiTracker::update(InputArray image,std::vector<Rect2d> &boundingBoxes)
//更新一组跟踪器状态,这是必须要进行的操作,否则跟踪器会不知道当前目标的位置选择ROI区域,并获得包围框
void selectROIs(String &windowName,
InputArray image,
DetectionBasedTracker::TrackedObject::PositionsVector &boundindBoxes,
bool showCrosshair = true, bool fromCenter = false);
//这是获得多个roi框,你需要vector<Rect2d> bboxes;⚠️没有返回值
Rect selectROI(String &windowName, InputArray image, bool showCrosshair = true, bool fromCenter = false);
//获得一个roi框,你需要一个Rect bbox;⚠️返回的是该Rect框
时间函数
// 利用getTickCount()
// 利用getTickFrequency()
// 时间计算逻辑是:
// 获得操作系统启动到当前的计时周期数, 获得CPU频率,单位是 重复次数/秒
// 根据周期数差值/CPU频率,可以得到秒数
int start_time = getTickCount();
for (int i=0;i<100;i++){
cout<<“nothing”<<endl;
}
int end_time = (getTickCount()-start_time)/getTickFrequency();
cout<<end_time<<“s”<<endl;第二部分 DIP算法相关
前言
该笔记主要是基于DIP理论➕openCV实现,学习该笔记首先要确保通读DIP理论,并由自己的话描述相关知识,并且掌握openCV中的相关算子
这里主要是基于VS2017/2019来实现openCV3.4.10版本的操作
图像处理分为传统图像处理和基于深度学习的图像处理,当某章某节涉及到深度学习时,我会在标题后追加(深度学习)以示区分.
第一章特征提取
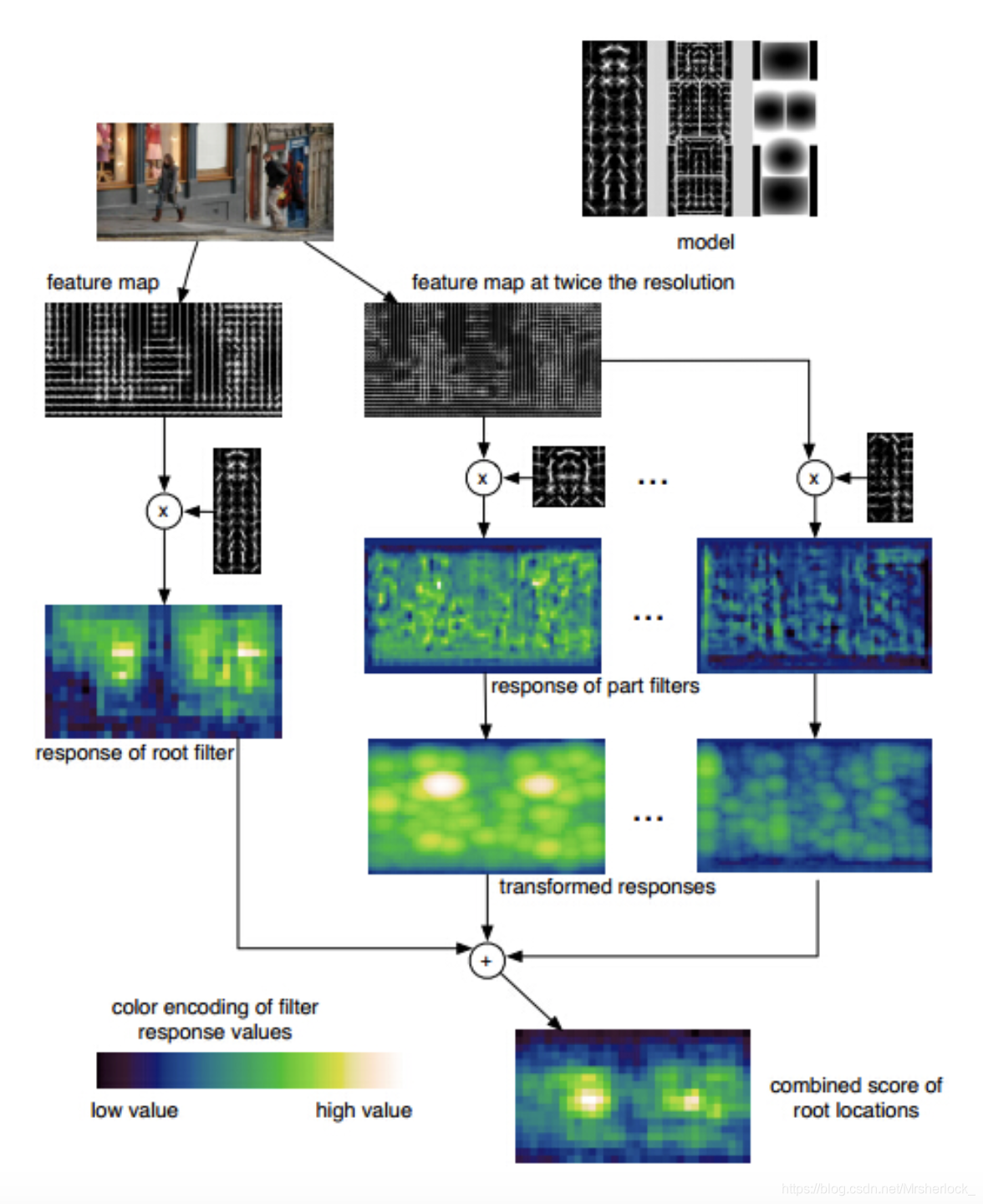
在特征提取上,传统的图像处理都是自行设计提取固定特征的算子,在深度学习上主要是利用CNN网络来广泛的提取图像的特征.在本章中主要介绍的是传统图像处理的经典的特征描述和提取方法,例如Haar、LBP、SIFT、HOG和DPM特征,其中的DPM特征是传统DIP在特征提取领域的天花板.
图像的浅层特征主要是颜色、纹理和形状
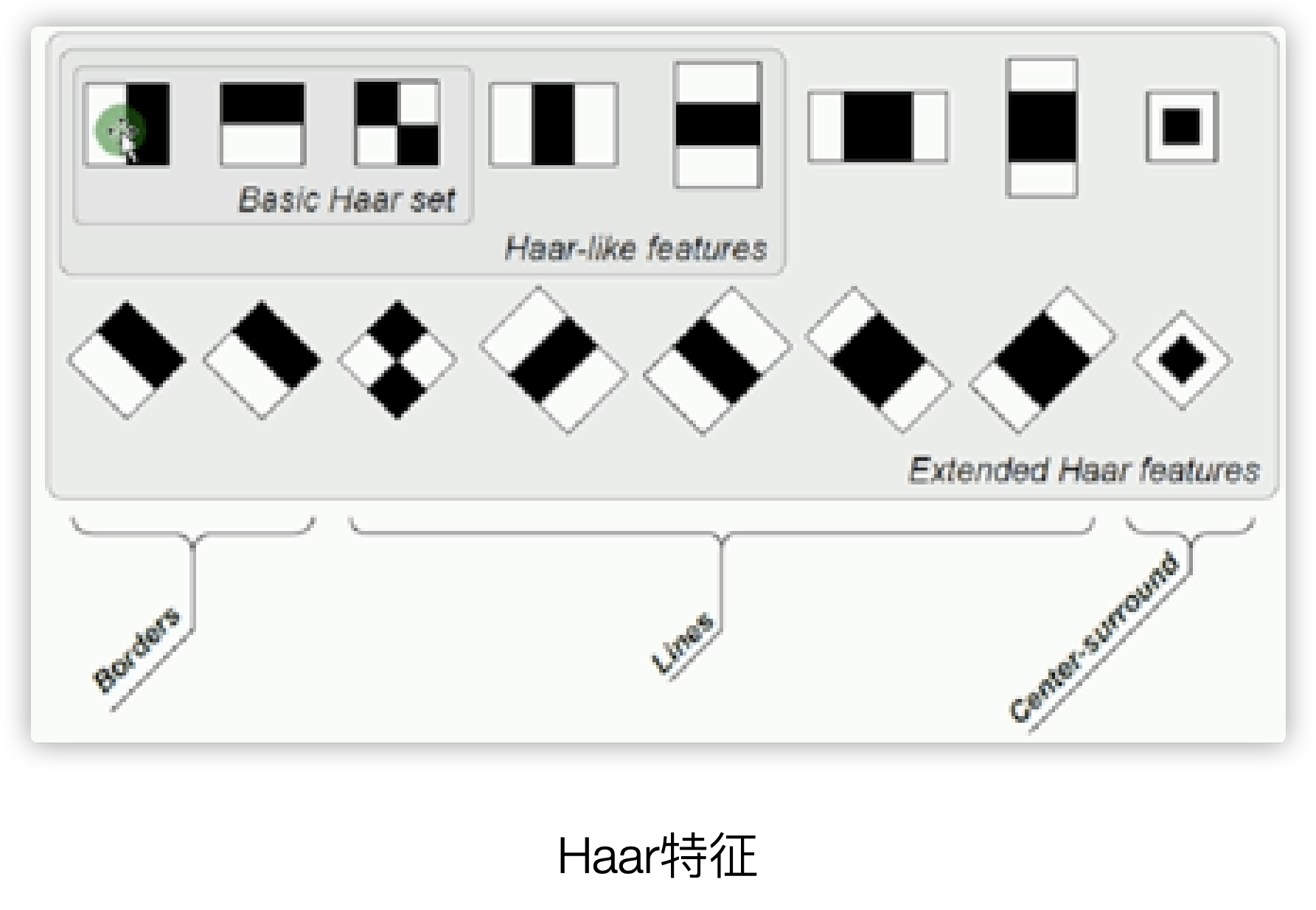
第一节 Haar特征(黑白色块)
Haar特征是按照黑白像素区域,每一个黑色或白色区域都是一个包含了多个像素的像素块,像素块之间的差值决定了哪些块之间存在哪种类型的边缘,比如下图的第一个是描述的垂直边缘,第二个则表示水平边缘.
一个矩形Haar特征定义了矩形中几个区域像素和的差值,可以是任意尺寸和任意位置,这个差值表明了图像的特定区域的某些特征
Haar特征往往应用在人脸识别的场景
第二节LBP特征(局部二值模式)
LBP是Local Binary Pattern局部二值模式的缩写,LBP特征描述的是图像的局部特征,LBP特征的特点是旋转不变性和灰度不变性
常用在人脸识别和目标检测上
LBP的旋转不变性和灰度不变性,往往可以对光照,旋转等具有较强的鲁棒性
2.1原始LBP特征
在一张图片或一个感兴趣区域中,其LBP特征有如下描述步骤:
- 在灰度图片中,在3x3的像素邻域内,以中心像素作为阈值T,将中心点的8邻域像素的8个数值,分别和T进行比较,若大于T则置1,小于则0
- 把第一步的8个比较结果,依次排成一行,形成一个8位二进制序列,并转换成十进制数值
- 十进制结果即该中心像素的LBP特征值
显然,一个像素点,可以生成2^8=256种LBP特征值
原始LBP由于采用固定邻域像素点作为比较对象,所以面对尺寸变换时往往失去鲁棒性,更不要谈旋转不变性了

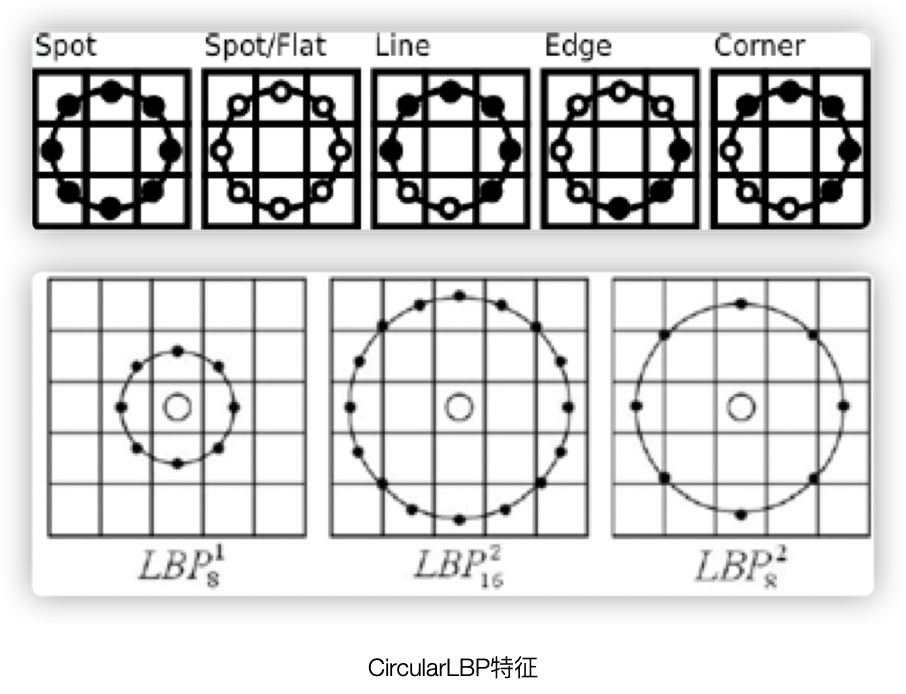
2.2 CircularLBP特征
原始LBP没有旋转不变性和尺度不变性,因此给予改进.
在CircularLBP特征中,保留了LBP的基本思想,具有如下描述步骤:
- 在灰度图片中,以某个像素点作为中心点,以R为半径画圆,圆的周长覆盖到的像素点,就是待和中心点比较的像素点
- 若圆周长覆盖的像素点不在图像内,就要采用差值算法,一般是双线性差值
- 对于CircularLBP所述的圆圈覆盖的邻域像素,按照一定步长进行角度旋转,得到一系列的序列(下图白点为1黑点为0),转换成LBP值,则每个像素点会有多个LBP值
- 取上述LBP值中最小的值作为该中心像素点的CircularLBP特征值

第三节SIFT特征(尺度旋转不变)
SIFT是尺度旋转不变的缩写,主要用于局部特征的描述提取,SIFT描述子对特征在图片中受到旋转、尺度变化、放缩和亮度等因素变化时具有较强的鲁棒性
2.3.1 SIFT特征提取方法
首先直接给出SIFT特征提取的流程图,然后对其逐个分析

建立尺度空间主要分成两步,第一步是对图片进行Gaussion金字塔操作,正常的pyramid每做一次下采样就是1层,但这里叫做一组,对每一组的图片,按照模糊尺度进行分层,第二步就是把每一组中上下层图像进行像素差分操作,得到高斯差分金字塔DOG金字塔

在流程图中,第二个大步骤就是寻找极值点,在每一个octave中,寻找每个像素的3x3x3邻域的26个邻域像素点,找出其max或min,该极值点暂定关键点
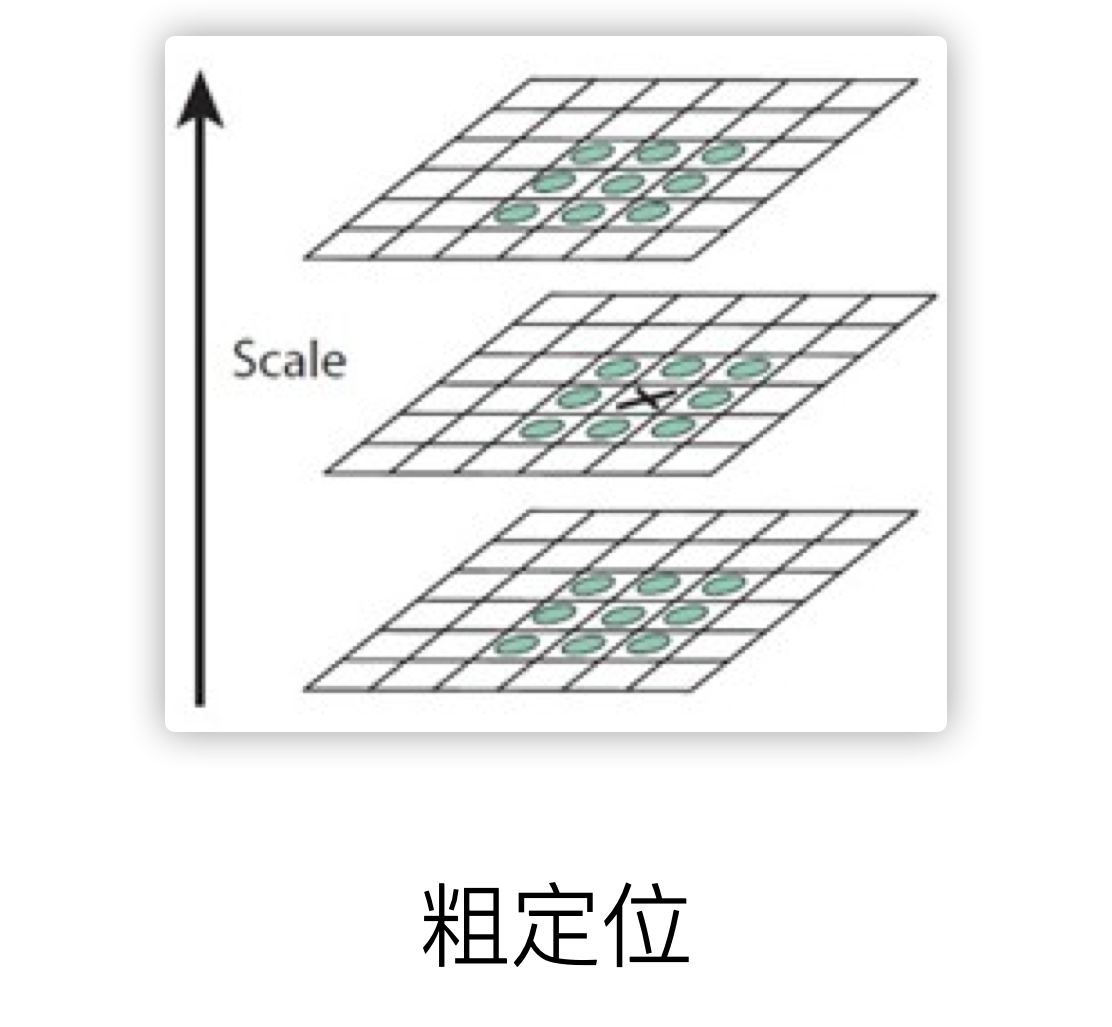
第三个大步骤就是对上述的粗定位进行精确定位,这里主要是采用的亚像素级别的差值处理,获得精确的关键点位置信息
第四步则是对关键点进行方向的初步分配,这正是旋转不变性的基础,首先把每个关键点以3.05σ为半径画圆,圆形面积覆盖的全部像素点,计算对应的梯度大小得到梯度方向,统计该区域的0-360°的梯度方向直方图,并把360°划分成36个bins每个bin代表10°,直方图峰值所在方向即该关键点主方向,保留峰值80%所在角度为该关键点辅助方向.
最后一步就是最重要的,即对关键点进行精准方向校准,此时已经获得了精准位置信息+尺度信息+粗方向信息,因此需要对方向进行精准修正,方法步骤如下:
- 增强旋转不变性,以关键点为中心,把邻域像素内坐标轴旋转该关键点主方向角度,获得新坐标
- 在新坐标中,以关键点为中心,获取16x16像素的窗口
- 在窗口中以4x4个像素为1个cell,均分成4x4个cell
- 统计每个cell中的16个像素的梯度直方图,360°按45°分成8个bins,即每个cell可得到8个特征信息
- 该关键点,16x16像素邻域范围内,共得到16x8=128个梯度特征信息,即每个关键点会产生128维的SIFT特征向量
2.3.2 SIFT特征在openCV中的实现方法
在openCV中依然采用简单算子api来实现
cv::xfeatures2d::SIFT::create(int nfeatures = 0, 关键点总个数
int nOctaveLayers =3, octave层数
double contrastThreshold = 0.04, 对比度阈值
double edgeThreshold= 10, 边缘阈值
double sigma=1.6)高斯模糊因子σ第四节HOG特征(梯度直方图)
HOG是Histograms of Oriented Gradients梯度方向直方图的缩写
HOG在SVM中的应用在传统图像处理中的行人检测领域取得了极大的成功,可以说是传统行人检测的基石.
一般情况, 在行人检测中由于每个人的内在特征存在明显的差异,因此需要一个能够全面描述人体特征的描述子进行描述,而HOG正是基于这个基本思想设计的.
HOG算子认为局部目标的表象和形状,能够被gradient或者边缘的方向密度分布很好的描述(当然gradient是梯度,而梯度往往存在于边缘处)
HOG特征提取的过程就是绘制图像的梯度分布直方图,然后利用算法,把梯度直方图归一化处理,正是这种归一化算法,将会很有效的检测出哪里是边缘,经过标准化,梯度直方图会被压缩成一个特征向量,就是HOG特征描述子,该描述子保存了大量的边缘信息,最终作为SVM分类器的输入
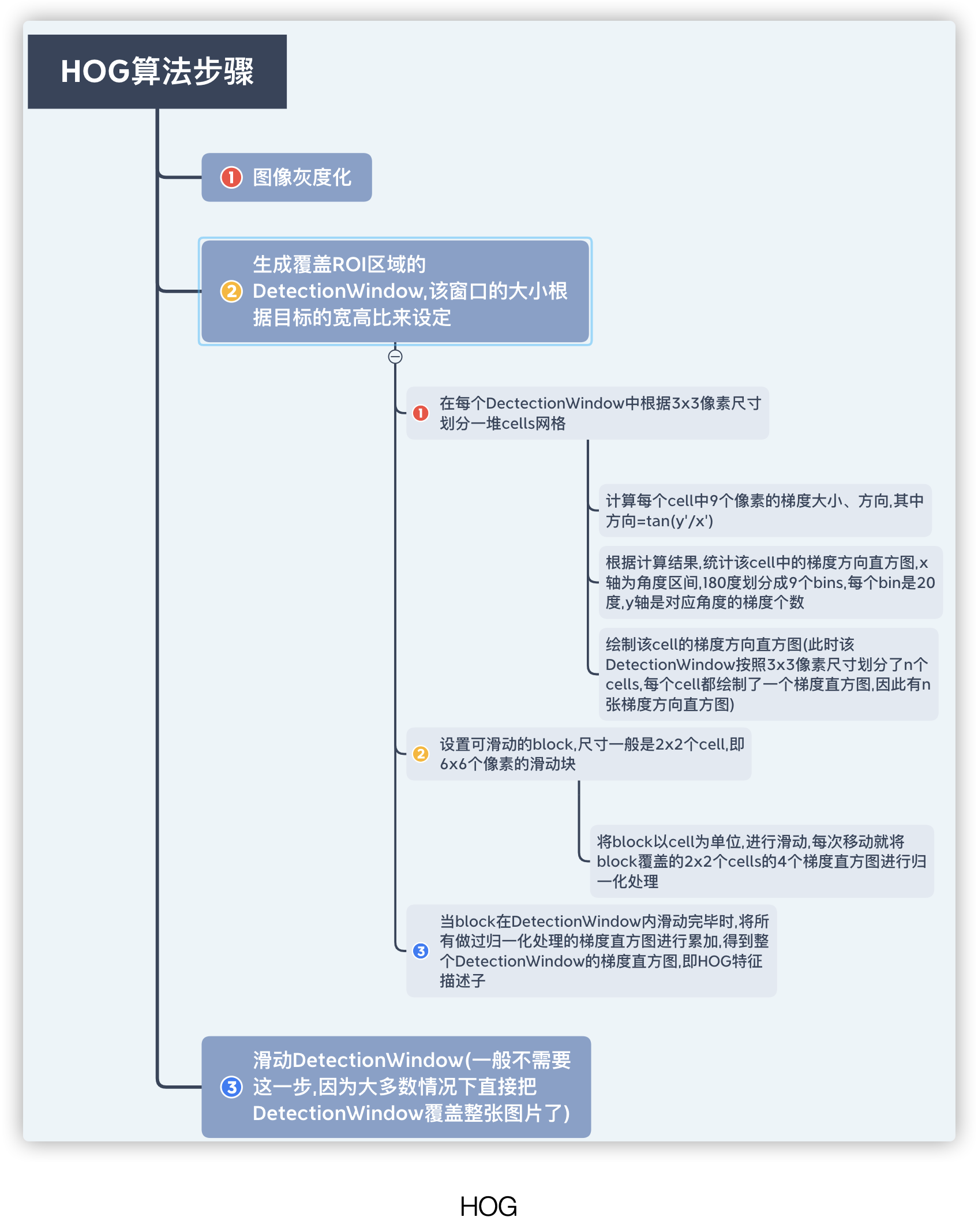
为了更好的理解HOG,用下图来描述HOG描述子的处理过程

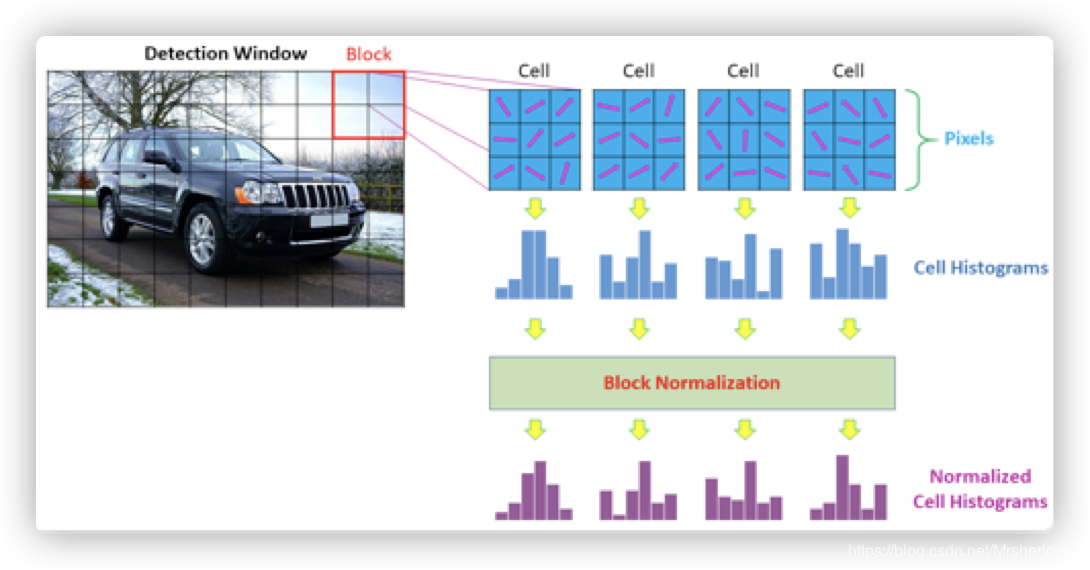
根据上图显示,一个HOG描述子的长度=block个数 ✖️ 一个block覆盖cell个数 ✖️ 每个cell的直方图中bins个数.
如果一幅图片中包含了多个DetectionWindow,那么一张图片中的HOG描述子的长度=窗口个数✖️一个HOG描述子长度
在openCV中,提供了关于HOG描述子的案例,比如下面的行人检测案例.在下面的案例中,HOGDescriptor作为HOG描述子的类,hog是类对象,该类的构造函数为默认构造函数.HOGDescriptor类存在一个svmDetector公共属性,他是用来配置HOG描述子输入给的SVM分类器的系数值的.
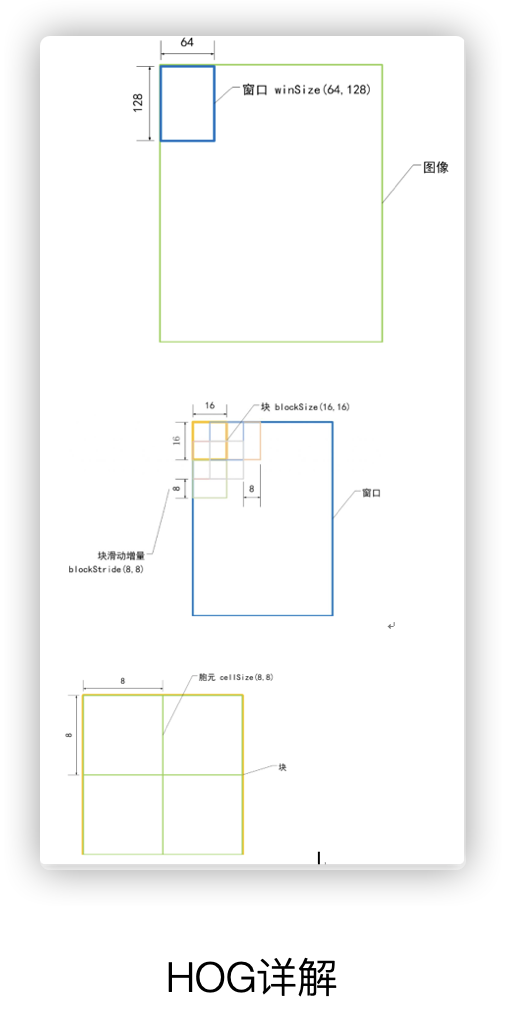
在上述的hog类对象中,默认构造一个64*128,的DetectionWindow,16*16的block,8*8的cell,且每个cell的HOG中含9个bins
更多关于HOGDescriptor类的描述详见:https://docs.opencv.org/3.4.10/d5/d33/structcv_1_1HOGDescriptor.html#ac0544de0ddd3d644531d2164695364d9
案例详解:
Mat gray;
Mat dst;
resize(src, dst, Size(64,128));
cvtColor(dst, gray, COLOR_BGR2GRAY);
HOGDescriptor detector(Size(64,128), Size(16,16), Size(8,8), Size(8,8), 9);
vector<float> descriptors;
vector<Point> locations;
detector.compute(gray, descriptors, Size(0,0),Size(0,0),locations);
cout<<“result number of HOG = “<<descriptors.size()<<endl;API介绍:
// HOG描述子
cv2.HOGDescriptor( win_size = (64, 128), //前5个最常用
block_size = (16, 16),
block_stride = (8, 8), //这个是块之间的x距离和y距离
cell_size = (8, 8),
nbins = 9,
win_sigma = DEFAULT_WIN_SIGMA,
threshold_L2hys = 0.2,
gamma_correction = true,
nlevels = DEFAULT_NLEVELS)
// 计算描述子数值类方法
HOGDescriptor::compute(image) //输入图像
virtual void cv::HOGDescriptor::compute
(
InputArray img,
std::vector< float > &descriptors,//输出HOG描述子
Size winStride = Size(), //窗口与窗口之间的距离
Size padding = Size(), //窗口的步长
const std::vector< Point > &locations = std::vector< Point >()d
)const
第五节DPM特征(可形变部件模型)
DPM特征是Deformable Parts Model可形变部件模型,DPM是传统目标检测算法的天花板,是HOG特征检测算法的扩展与改进,由于HOG往往带来高纬度的特征向量,这些特征向量作为SVM分类器的输入,往往产生很大的计算量,HOG一般采用PCA主成分分析法降维,但DPM作为HOG算法的改进,采用了一种逼近PCA的降维方法.
首先规定前提,DPM把梯度方向根据180度和360度分成了有符号和无符号两类,其中有符号表示有正负符号,其0-360角度范围的梯度看成有方向的,分成18个bins,0-180的成为无方向的分成9个bins, 显然无路方向有无,每个bin的角度都是20度.

在对该流程的理解过程中或许有偏差,但是最终的结果是一样的,另一个理解角度是:
- 采用HOG的cell思想,每8✖️8个像素为一个cell,均分图片成多个cell,计算全部像素的梯度大小和方向,统计每个cell中所有像素的梯度直方图
- 对每个cell的4邻域的4个cell,即对角线上4个cell,如图1234(上图绿色为一个cell内部情况,黄色块为一个cell简笔画), 把该cell和4邻域的4个cell对应做归一化处理见下一步
- 中心cell和4邻域4个cell分别归一化处理步骤:
- 对于有符号梯度: 计算中心cell和第i个cell(i=1,2,3,4)的梯度方向直方图,在有符号的梯度方向直方图为18个bins,4个cell直方图累加得到18个bins即18个特征
- 对于无符号梯度:如图右侧,把上图橘色块即36个特征看成一个矩阵,进行行求和、列求和,共得到4+9=13个特征**
- 归一化后合计得到18+13=31个特征,即每个8✖️8像素的cell会产生一个31维的特征向量

DPM检测
DPM作为目标检测算法的天花板,有着自己的独特的检测流程,如下图所示: