1. Create two tables, there are a1 and a2.
table: a1
table a2:
2. Create a function: record_a1
CREATE OR REPLACE FUNCTION record_a1()
returns trigger as $$
declare
nCnt int;
begin
select count(0) into nCnt from a2 where column1=new.column1;
if nCnt=0 then
insert into a2(column1, column2, column3) values(new.column1, new.column2, TG_OP);
else
update a2 set column2=new.column2, column3=TG_OP where column1=new.column1;
end if;
return old;
end;
$$
language plpgsql;3. Create a trigger:
create TRIGGER a1_trigger
after insert or update on a1
for each row execute procedure record_a1();CREATE [ CONSTRAINT ] TRIGGER name
{ BEFORE | AFTER | INSTEAD OF } { event [ OR ... ]}
ON table_name
[ FROM referenced_table_name ]
{ NOT DEFERRABLE | [ DEFEREABLE ] { IINITIALLY IMMEDIATE | INITIALLY DEFERED} }
FOR [ EACH ] { ROW | STATEMENT }
[ WHEN { condition }]
EXECUTE PROCEDURE function_name ( arguments )
4. Check result
| table a1 (insert) | table a2 |
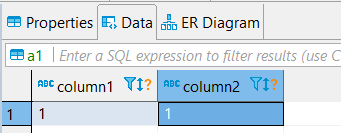 | 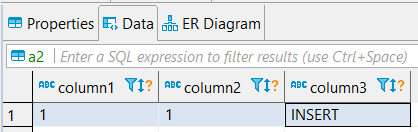 |
| table a1 (update) | table a2 |
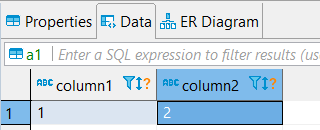 | 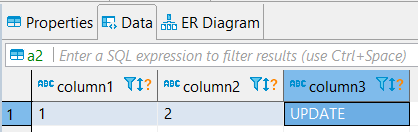 |
5. Drop trigger
drop trigger a1_trigger ON a1;DROP TRIGGER [ IF EXISTS ] NAME ON TABLE [ CASCADE | RESTRICT ];
7. Reference
触发器函数中的特殊变量
当把一个 PL/pgSQL 函数当作触发器函数调用的时候,系统会在顶层的声明段里自动创建几个特殊变量,比如在之前例子中的 “NEW”、“OLD”、“TG_OP” 变量等。可以使用的变量有如下这些。
NEW:该变量为 INSERT/UPDATE 操作触发的行级触发器中存储的新的数据行,数据类型是 RECORD。在语句级别的触发器里此变量没有分配,DELETE 操作触发的行级触发器中此变量也没有分配。
OLD:该变量为 UPDATE/DELETE 操作触发的行级触发器中存储的旧数据行,数据类型是 RECORD。在语句级别的触发器里此变量没有分配, INSERT 操作触发的行级触发器中此变量也没有分配。
TG_NAME:数据类型是 name,该变量包含实际触发的触发器名。
TG_WHEN: 内容为 BEFORE 或 AFTER 的字符串,用于指定是 BEFORE 触发器还是 AFTER 触发器。
TG_LEVEL: 内容为 ROW 或 STATEMENT 的字符串用于指定是语句级触发器还是行级触发器。
TG_OP: 内容为 INSERT、UPDATE、DELETE、TRUNCATE 之一的字符串,用于指定 DML 语句的类型。
TG_RELID: 触发器所在表的 OID。
TG_TABLE_NAME: 触发器所在表的名称。
TG_TABLE_SCHEMA: 触发器所在表的模式。
TG_NARGS: 在 CREATE TRIGGER 语句里面赋予触发器过程的参数个数。
TG_ARGV[]: 为 text 类型的一个数组;是 CREATE TRIGGER 语句里的参数。