大数据包括静态数据和动态数据(流数据),相应地,大数据计算包括批量计算和实时计算。传统的MapReduce框架采用离线处理计算的方式,主要用于对静态数据的批量计算,并不适合处理流数据。流计算即针对流数据的实时计算。Storm流计算框架具有可扩展性、高容错性、能可靠地处理消息的特点,且使用简单,可以以较低的成本来开发实时应用。
流计算概念
静态数据和流数据(动态数据)
静态数据:静态数据是指不会随时间发生变化的数据。
流数据:数据以大量、快速、时变的流形式持续到达。例如:网络监控、电信金融、生产制造等。
从概念上来,流数据(或数据流)是指在时间分布和数量上无限的一系列动态数据集合体;数据记录是流数据的最小组成单元。
流数据具有如下特征:
- 数据快速持续到达,潜在数据量也许是无穷无尽的。
- 数据来源众多,格式复杂。
- 数据量大,但是不十分关注存储,一旦流数据中的某个元素经过处理,要么被丢弃,要么被归档存储。
- 注重数据的整体价值,不过分关注个别数据。
- 数据顺序颠倒,或者不完整,系统无法控制将要处理的新到达的数据元素的顺序。
批量计算和实时计算
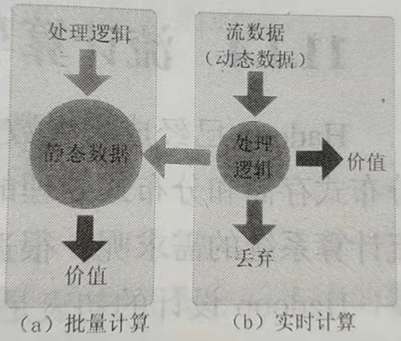
批量计算:批量计算以“静态数据”为对象,可以在很充裕的时间内对海量数据进行批量处理,计算得到有价值的信息。
实时计算:实时计算最重要的一个需求是能够得到计算结果,一般要求响应时间为秒级。
流数据不适合采用批量计算,因为流数据不适合用传统的关系模型建模,不能把源源不断的流数据保存到数据库中;流数据被处理后,一部分进入数据库成为静态数据,其他部分则直接被丢弃。
流计算的概念
流计算是针对流数据的实时计算;流计算秉承了一个基本理念,即数据的价值随着时间的流逝而降低。
对于一个流计算系统来说,它应达到如下需求:
(1)高性能。处理大数据的基本要求,如每秒处理几十万条数据。
(2)海量式。支持TB级甚至是PB级的数据规模。
(3)实时性。必须保证一个较低的时延,达到秒级,甚至是毫秒级别。
(4)分布式。支持大数据的基本架构,必须能够平滑扩展。
(5)易用性。能够快速进行开发和部署。
(6)可靠性。能可靠地处理流数据。
流计算框架
类别 | 名称 | 描述 |
第一类商业级的流计算平台 | IBM InfoSphere Streams | 商业级高级别平台,可以帮助用户开发应用程序来快速摄取、分析和关联来自数千个实时源的信息 |
IBM StreamBase | IBM开发的另一款商业流计算系统,在金融部门和政府部门使用 | |
第二类开源流计算框架 | Twitter Storm | 免费、开源的分布式实时计算系统,可简单、高效、可靠地处理大量的数据;阿里巴巴的JStorm是Storm的增强版本 |
Yahoo!S4 | 开源流计算平台,是通用的、分布式的、可扩展的、分区容错的、可插拔的流式系统 | |
第三类公司自研,未开源 | DStream | 百度开发的通用实时流数据计算系统 |
银河流数据处理平台 | 淘宝开发的通用流数据实时计算系统 | |
Super Mario | 基于Erlang语言和ZooKeeper模块开发的高性能流数据处理框架 |
流计算的处理流程
流计算处理流程包括数据实时采集、数据实时计算和实时查询服务。
概述
传统的数据处理流程需要先采集数据并存储在关系数据库等数据管理系统中,之后用户通过查询操作和数据管理系统进行交互,最终得到查询结果。
传统的数据处理存在的问题:
(1)存储的数据是旧的。
当查询数据的时候,存储的静态数据已经是过去某一时刻的快照,这些数据在查询时可能已不具备时效性了。
(2)需要用户主动发出查询。
流计算的数据处理流程,一般包含3个阶段:数据实时采集、数据实时计算、实时查询服务。

数据实时采集
数据实时采集阶段需要采集多个数据源的海量数据,需要保证实时性、低延迟和稳定可靠。
数据采集系统的基本架构一般有3个部分:
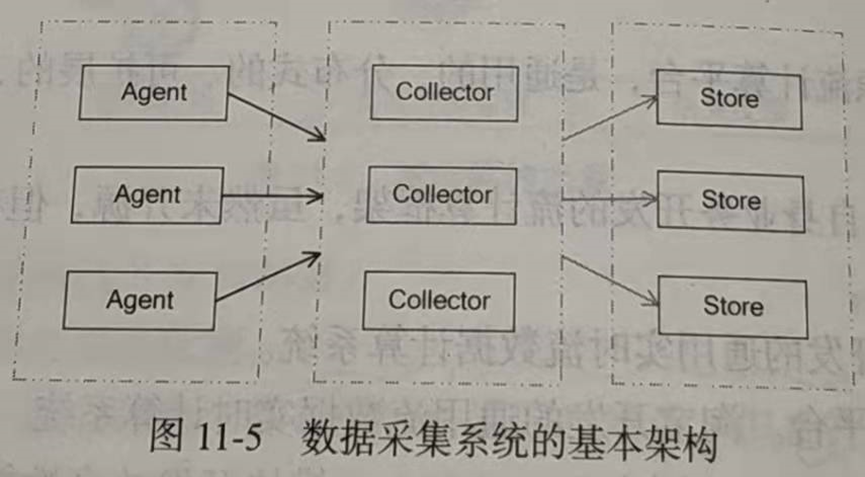
(1)Agent:主动采集数据,并把数据推送到Collector部分。
(2)Collector:接收多个Agent的数据,并实现有序、可靠、高性能的转发。
(3)Store:存储Collector转发过来的数据。
对于流计算,一般在Store部分不进行数据的存储,而是将采集的数据直接发送给流计算平台进行实时计算。
数据实时计算
数据实时计算阶段对采集的数据进行实时的分析和计算。流处理系统接收数据采集系统不断的发来的实时数据,实时地进行分析计算,并反馈实时结果。经流处理系统处理后的数据,可视情况进行存储,以便之后进行分析计算。在时效性要求较高的场景中,处理之后的数据也可以直接丢弃。
实时查询服务
在流处理流程中,实时查询服务可以不断更新结果,并将用户所需的结果实时推送给用户。
流处理系统与传统的数据处理系统有如下不同之处:
(1)流处理系统处理的是实时数据,而传统的数据处理系统处理的是预先存储好的静态数据。
(2)用户通过流处理系统获取的实时结果,而通过传统的数据处理系统获取的是过去某一时刻的结果。并且,流处理系统无须用户主动发出查询,实时查询服务可以主动将实时结果推送给用户。
开源流计算框架Storm
2010年Yahoo!开发的分布式流式处理系统S4开源,2011年Twitter开发的流计算框架Storm开源;
批处理系统一般重视数据处理的总吞吐量,流处理系统更加关注数据处理的延时,即注入的数据得到越快处理越好。
Storm简介
Storm是一个免费、开源的分布式实时计算系统
Storm可以简单、高效、可靠地处理流式数据,并支持多种编程语言
Storm可以方便地与数据库系统进行整合,从而开发出强大的实时计算系统
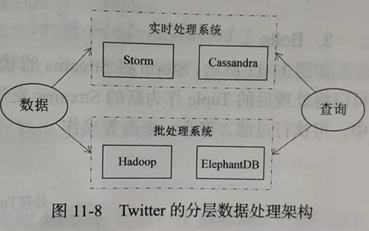
Storm采用了由实时处理系统和批处理系统组成的分层数据处理架构,一方面,由Hadoop和ElephantDB(专门用于从Hadoop中导出key/value数据的数据库)组成批处理系统,另一方面,由Storm和Cassandra(非关系数据库)组成实时系统。在计算查询时,该系统会同时查询批处理视图和实时视图,并把它们合并志来以得到最终的结果。实时系统处理的结果最终会由批处理系统来修正,这种设计方式使得Twitter的数据处理系统显得与众不同。
Storm的特点
1、整合性:Storm可方便地与队列系统和数据库系统进行整合
2、简易的API:Storm的API在使用上即简单又方便
3、可扩展性:Storm的并行特性使其可以运行在分布式集群中
4、容错性:Storm可以自动进行故障节点重启,以及节点故障时任务重新分配
5、可靠的消息处理:Storm保证每个消息都能完整处理
6、支持各种编程语言:Storm支持使用各种编程语言来定义任务
7、快速部署:Storm仅需要少量的安装和配置就可以快速进行部署和使用
8、免费、开源:Storm是一款开源框架,可以免费使用
Storm的设计思想
1、Streams
在Storm对流数据Streams的抽象描述中,流数据是一个无限的Tuple序列(Tuple即元组,是元素的有序列表,每一个Tuple就是一个值列表,列表中的每个值都有一个名称,并且该值可以是基本类型、字符顾炎武 、字节数组等,也可以是其他可序列化的类型)。这些Tuple序列会以分布式并行地创建和处理。

2、Spouts[spauts 窗口的嘴]
Storm认为每个Streams都有一个源头,并把这个源头抽象为Spouts。Spouts会从外部读取流数据并持续发出Tuple。

3、Bolts[bəults 插销,螺栓]
Strom将Streams的状态转换过程抽象为Bolts。Bolts即可以处理Tuple,也可以将处理后的Tuple作为新的Streams发送给其他Bolts。对Tuple的处理逻辑都被封装在Bolts中,可执行过滤、聚合、查询等操作。
4、Topology[tə’pɔlədʒi 拓扑结构]
Storm将Spouts和Bolts组成的网络抽象成Topology。Topology是Storm中最高层次的抽象概念,它可以被提交到Storm集群执行。一个Topology就是一个流转换图,图中节点是一个Spout或Bolt,图中的边则表示Bolt订阅了哪个Stream。当Spout或者Bolt发送元组时,它会把元组发送到每个订阅了该Stream的Bolt上进行处理。
在Topology的具体实现上,Storm中的Topology定义仅是一些Thrift[θrift 节约]结构体(Thrift是基于二进制的高性能的通信中间件),而Thrift支持各种编程语言进行定义,这样一来可以使用各种编程语言来创建、提交Topology。
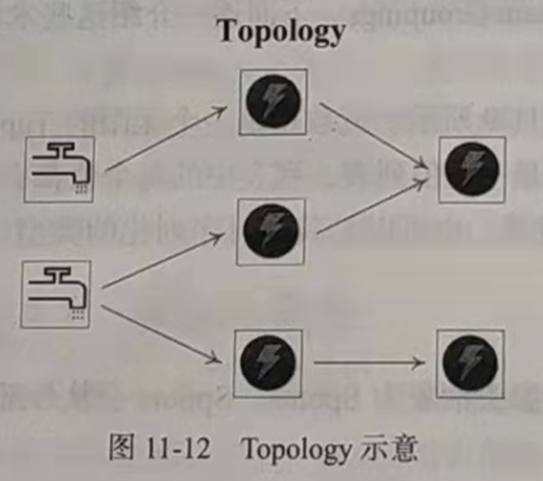
5、Stream Groupings
Strom中的Stream Groupings用于告知Topology如何在两个组件间(如Spout和Bolt之间,或者不同的Bolt之间)进行Tuple的传送。一个Topology中Tuple的流向如图,其中箭头表示Tuple的流向,圆圈表示任务,每一个Spout和Bolt都可以有多个分布式任务,一个任务在什么时候、以什么方式发送Tuple就是由Stream Groupings来决定。
目前,Strom中的Stream Groupings有以下6种方式:
(1)ShuffleGrouping:随机分组,随机分发Stream中的Tuple,保证每个Bolt的Task接收Tuple数量大致一致
(2)FieldsGrouping:按照字段分组,保证相同字段的Tuple分配到同一个Task中
(3)AllGrouping:广播发送,每一个Task都会收到所有的Tuple
(4)GlobalGrouping:全局分组,所有的Tuple都发送到同一个Task中
(5)NonGrouping:不分组,和ShuffleGrouping类似,当前Task的执行会和它的被订阅者在同一个线程中执行
(6)DirectGrouping:直接分组,直接指定由某个Task来执行Tuple的处理
Storm的框架设计
Storm运行在分布式集群中,不同于Hadoop,在Hadoop上运行的是MapReduce作业,在Storm上运行的是Topology。两者的主要不同点是MapReduce作业最终会完成计算并结束运行,而Topology将持续处理消息(直到人为终止)。
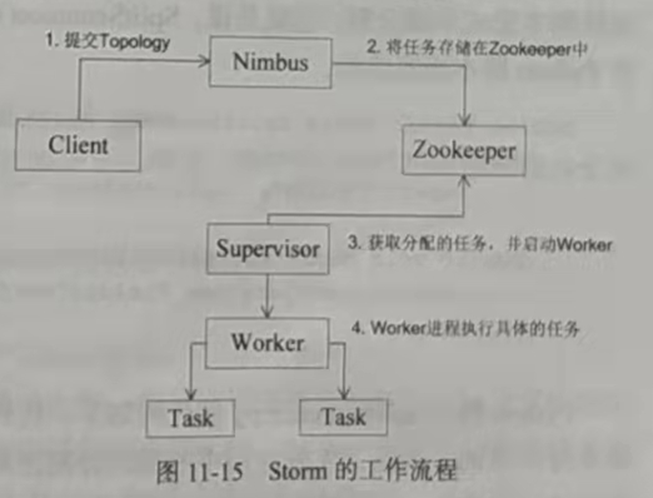
Storm集群采用Master-Worker的节点方式,其中Master节点运行名为Nimbus的后台程序(类似Hadoop中的JobTracker),负责在集群范围内分发代码、为Worker分配任务和监测故障。而每个Worker节点运行名为Supervisor的后台程序,负责监听分配给它所在机器 的工作,即根据Nimbus分配的任务来决定启动或停止Worker进程。
Storm集群框架采用了Zookeeper来作为分布式协调组件,负责Nimbus和多个Supervisor之间的所有协调工作(一个完整的拓扑可能被分为多个子拓扑,并由多个Supervisor完成)。
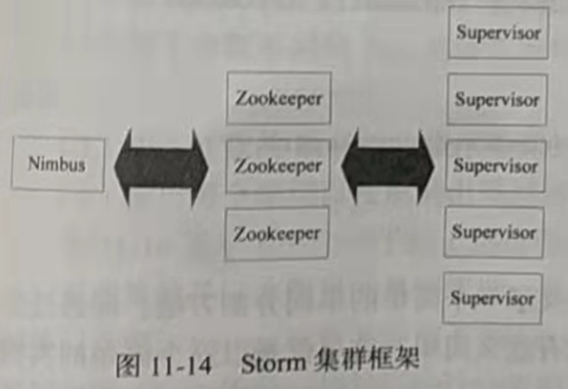
此外,Nimbus后台进程和Supervisor后台进程都是快速失败(Fail-fast)和无状态(Stateless)的,Master节点并没有直接和Worker节点通信,而是借助ZooKeeper将状态信息存放在ZooKeeper中或本地磁盘中,以便节点故障时进行快速恢复。这意味着,若Nimbus进程或Supervisor进程终止,一旦进程重启,它们将恢复到之前的状态并继续工作。这种设计使Storm极其稳定。
Spark Streaming
Spark Streaming是构建在Spark上的实时计算框架,它扩展了Spark处理大规模流式数据的能力。Spark Streaming可结合批处理和交互查询,适合一些需要对历史数据和实时数据进行结合分析的场景。
Spark Streaming 设计
Spark Streaming可整合多种输入数据源,经处理后的数据可存储至文件系统、数据库或显示在仪表盘里。
Spark Streaming的基本原理是将实时输入数据流以时间片(秒级)为单位进行拆分,然后经过Spark引擎以批处理的方式处理每个时间片数据,执行流程如下图:
Spark Streaming最主要的抽象是离散化的数据流(Discretized Stream,DStream)表示连续不断的数据流。在内部实现上,Spark Streaming的输入数据按照时间片(如1s)分成一段段的DStream,每一段数据转换为Spark中的RDD,并且对DStream的操作都最终转变为对相应的RDD的操作。例如下图展示了进行单词统计时,每个时间片的数据(存储句子的RDD)经flatMap操作,生成了存储单词的RDD。整个流式计算可根据业务的需求对这些中间结果 进行进一步的处理,或者存储到外部设备中。
Spark Streaming与Storm的对比
Spark Streaming和Storm最大的区别:
Spark Streaming无法实现毫秒级的流计算,而Storm可以实现毫秒级响应。
Spark Streaming无法实现实时性要求非常高的场景,而Storm处理的单位为Tupe,只需要极小的延迟。
Spark Streaming无法实现毫秒级的流计算主要原因是Spark Streaming将流数据按批处理窗口大小(通常在0.5~2秒之间)分解为一系列批处理作业,在这个过程中会产生多个Spark作业,且每一段数据的处理都会经过Spark DAG分解、任务调度过程,因此无法实现毫秒级响应。
Spark Stream构建在Spark上,一方面是因为Spark的低延迟执行引擎(100毫秒左右)可以用于实时计算,另一方面,相比于Storm,RDD数据集更容易做高效的容错处理。
Spark Streaming采用的小批量处理方式使得它可以同时兼顾批量和实时数据处理的逻辑和算法。