hdfs集群下线DataNode要严格遵守顺序!!!
启动hdfs与yarn平台后,进入web页面发现无法上传文件和创建目录,更无法删除目录。在hadoop中发现提示为进入安全模式。
查看安全模式状态
hdfs dfsadmin -safemode get
进入安全模式
hdfs dfsadmin -safemode enter
离开安全模式
hdfs dfsadmin -safemode leave离开安全模式后可以正常使用。但是出现了一种块丢失的情况。

排查错误
根据提示信息执行 fsck
执行命令: hdfs fsck / 查看所有丢失的文件详细信息
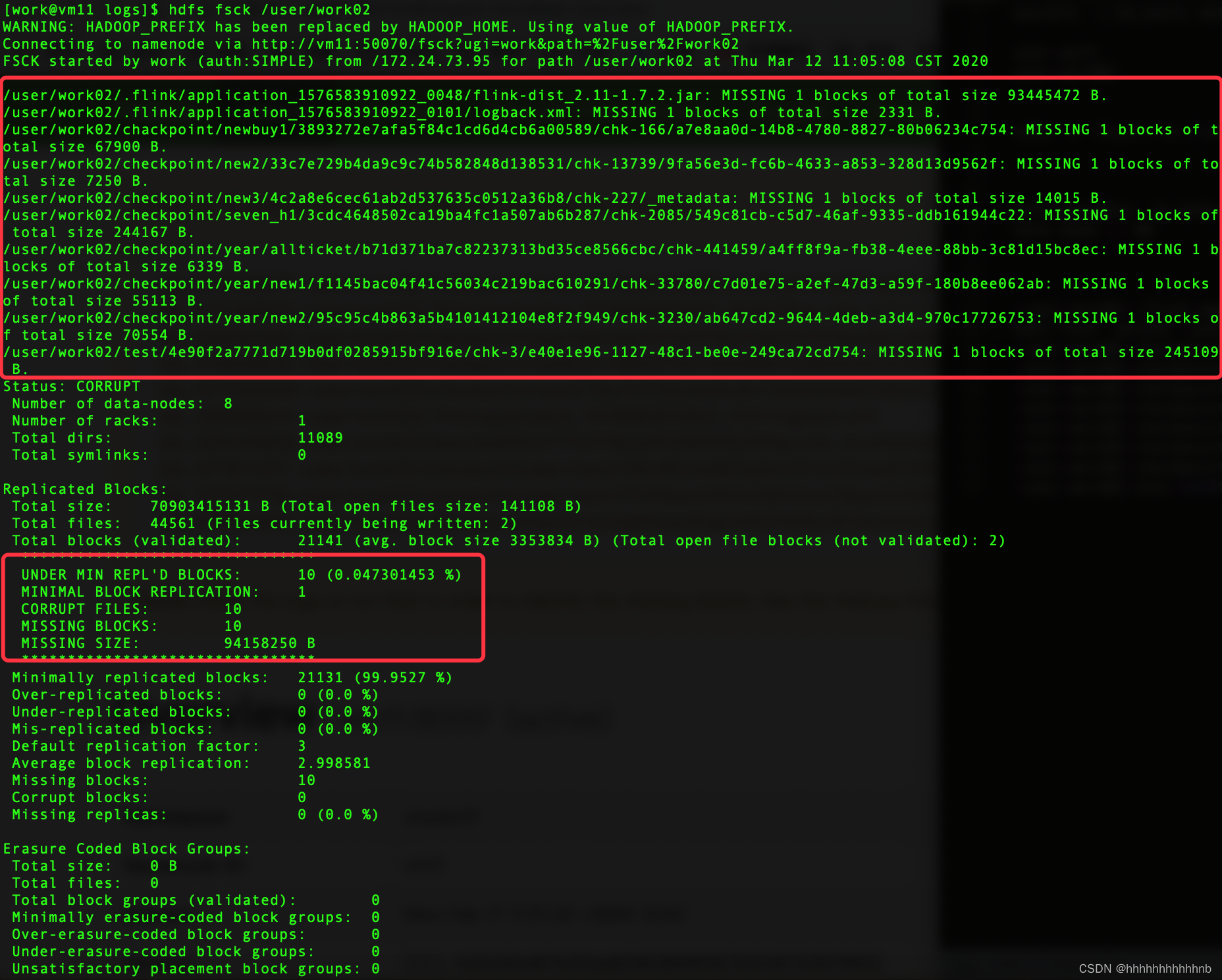
以上MISSING状态的文件和web界面的一致。
查看文件是否存在
直接查看文件,显示该文件是存在的:hdfs dfs -ls /path/to/file

查看文件内容
检查文件内容是否可查看:hdfs dfs -tail /path/to/file
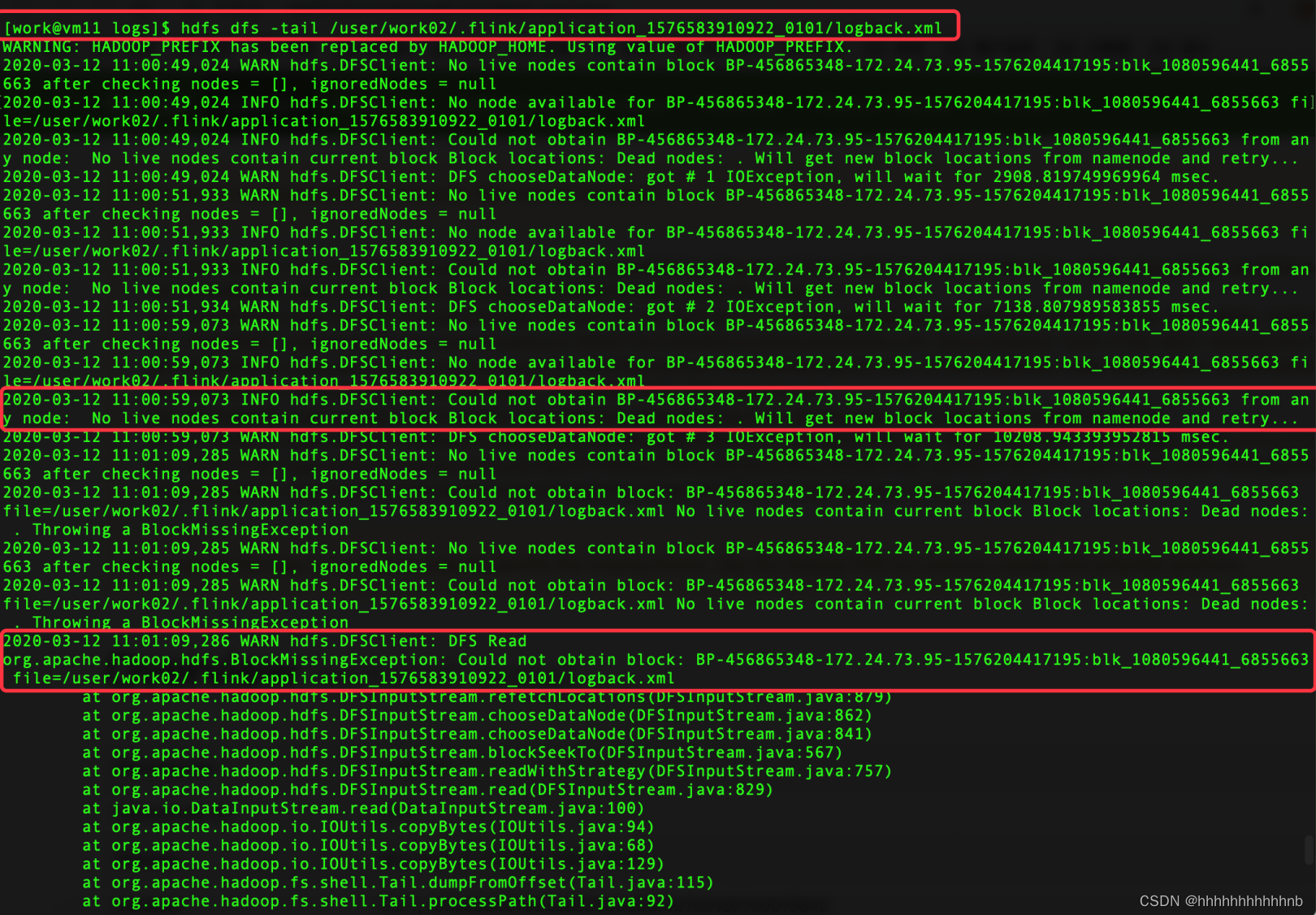
即,当前存活的node中没有该block,该block存在于Dead nodes。
追溯处理
- 经查资料判断:这种状态下的block是没办法再恢复的了。
- 原因:之前进行过缩容,文件位于被缩容的datanode节点,已丢失。
- 修复:处理该
warning错误信息的办法就是在namenode直接删除已丢失的block即可
$ hdfs fsck -delete /user/work02/.flink/application_1576583910922_0101/logback.xml
...复制
删除之后到web查看:此时missing blocks变为9。
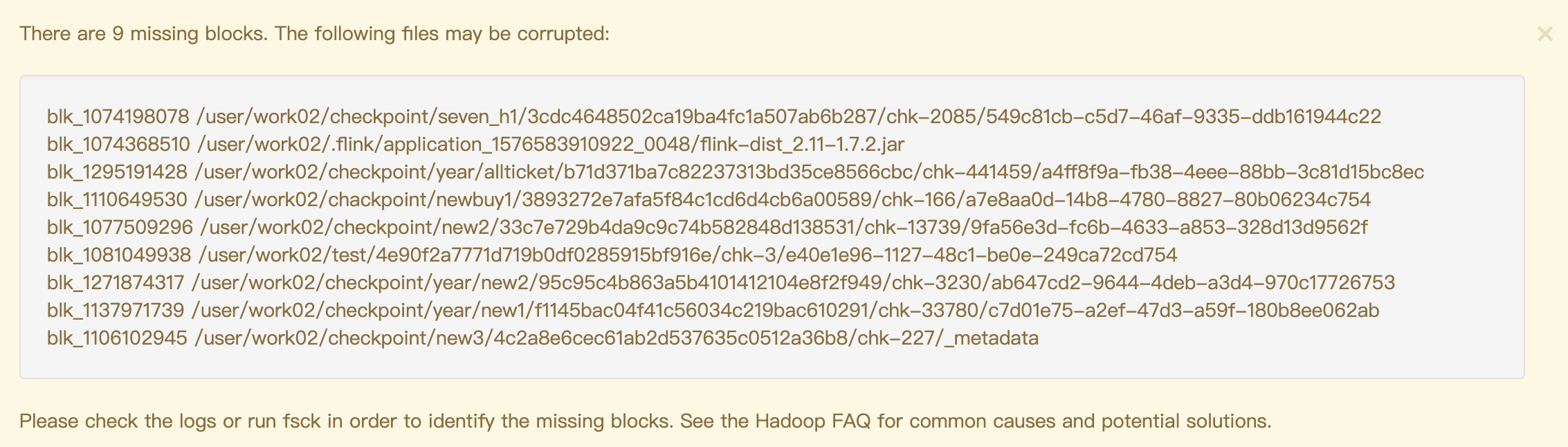
依次删除其他的block,清理完后结果如下:
思考:hdfs集群DataNode下线
- 在NameNode所在的机器(master)上的配置文件hdfs-site.xml中增加"黑名单"配置: <property> <!-- 黑名单信息--> <name>dfs.hosts.exclude</name> <value>/path/to/hadoop/etc/hadoop/dfs.exclude</value> </property>
- 在master机器上执行下面的命令: # 创建黑名单文件 $ touch /home/hadoop-twq/bigdata/hadoop-2.7.5/etc/hadoop/dfs.exclude
- 在
/path/to/hadoop/etc/hadoop/dfs.exclude文件中增加要下线的机器清单: node11 - 在
/path/to/hadoop/etc/hadoop/slaves文件中删除要下线的机器node11行 - 然后在NameNode所在的机器上执行如下的命令: # 更新节点信息 $ hdfs dfsadmin -refreshNodes
- 然后我们刷新HDFS的Web UI的DataNode信息,如下图:、
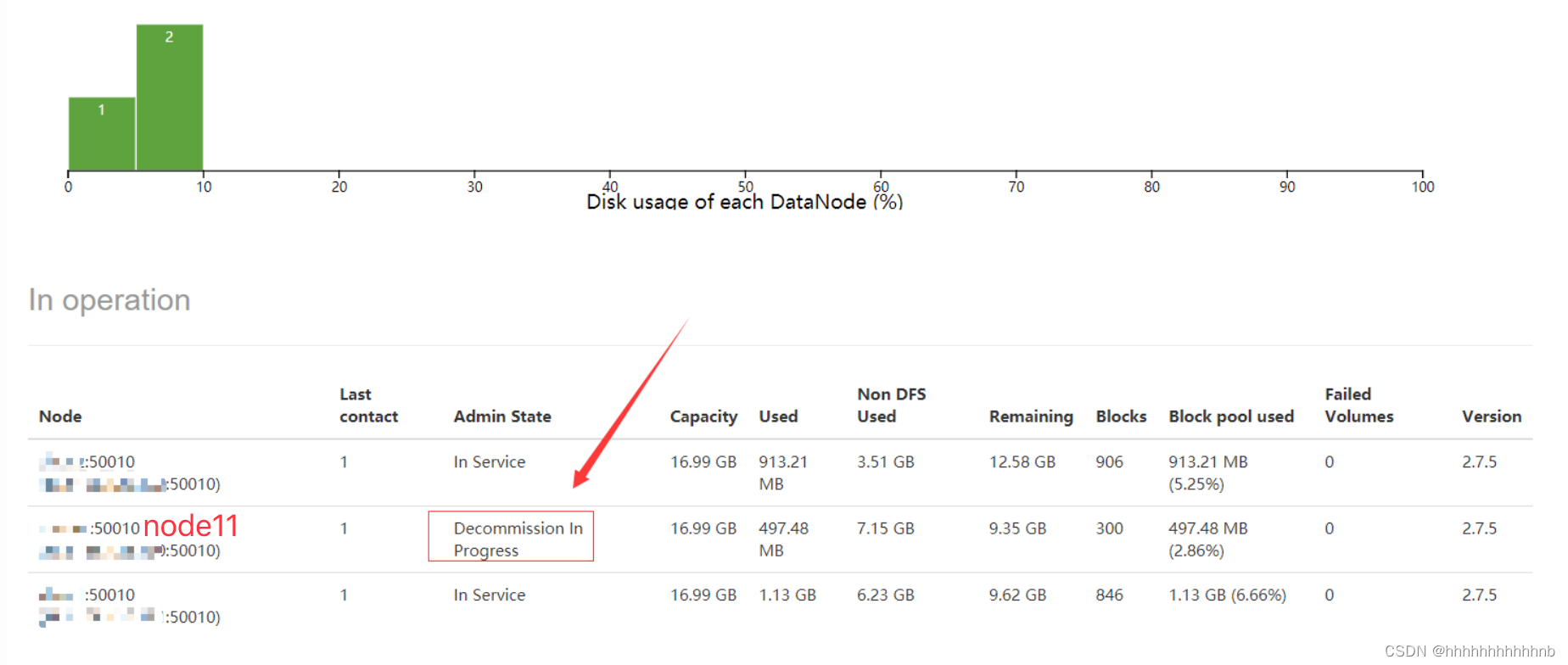
这个时候,master上的DataNode的状态变为Decommission In Progress。这个时候,在master上的DataNode的数据都在复制转移到其他的DataNode上,当数据转移完后,我们再刷新HDFS Web UI后,可以看到DataNode的状态变为Decommissioned,表示这个DataNode已经下线,如下图:
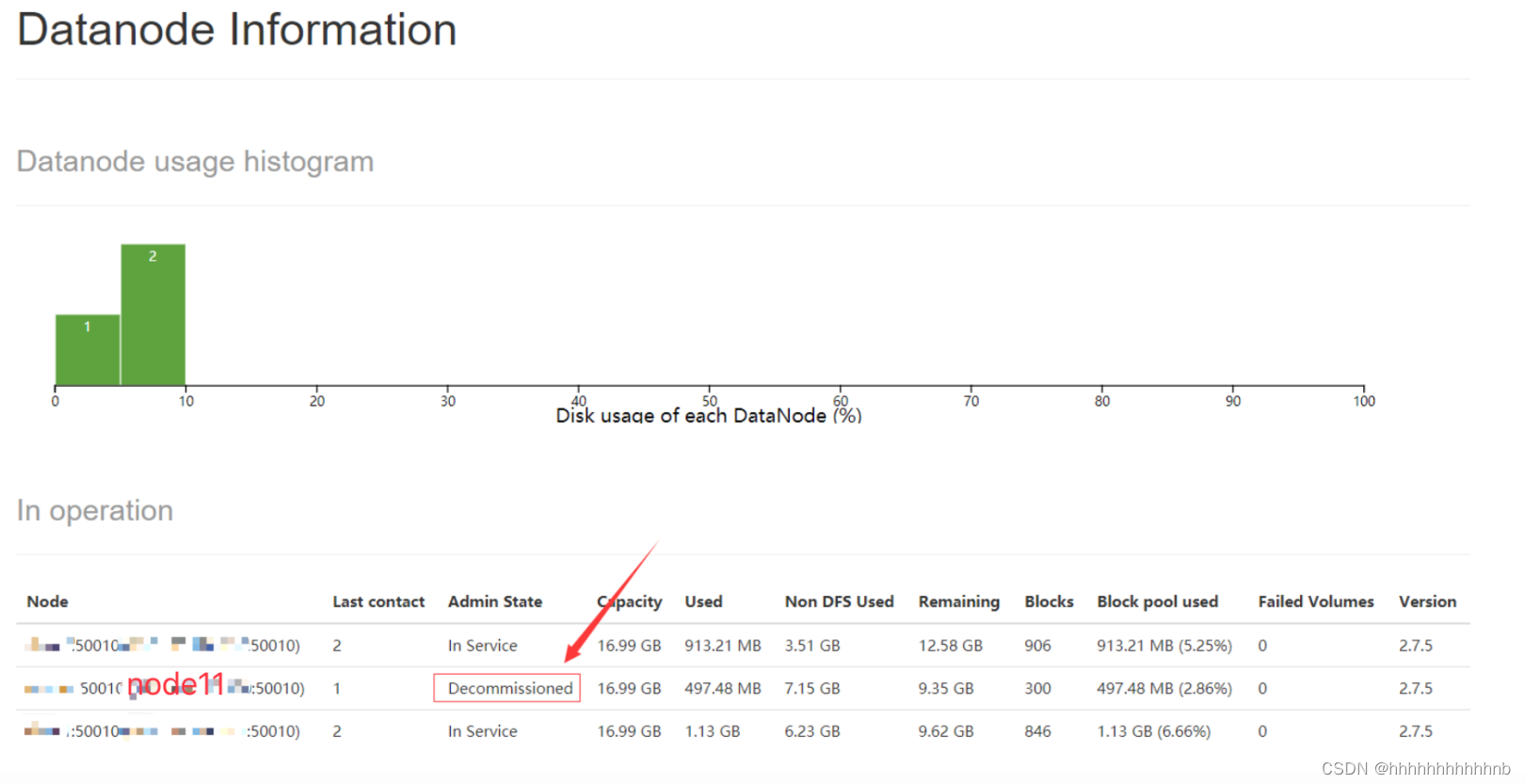
- 在node11上停止DataNode服务: $ hadoop-daemon.sh stop datanode
- 刷新DataNode: $ hdfs dfsadmin -refreshNodes
版权声明:本文为hhhhhhhhhhhnb原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。