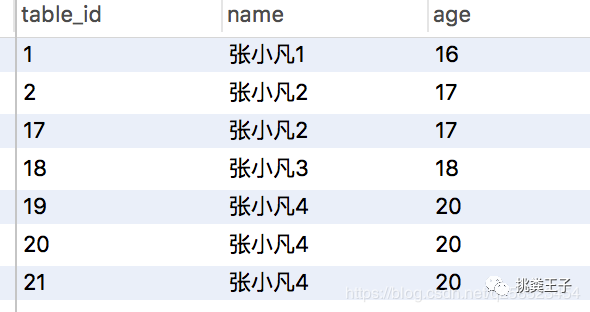
问:假如有一个student(table_id,name,age)的表,有重复name和age数据, 怎么写出delete重复数据的sql?
假如:我们只保留重复数据中, table_id最小的记录
一步一步分析:
首先我们要知道哪些数据是重复的, group by 聚集函数可以帮我找到:
SELECT name , count(*)FROM studentGROUP BY `name`HAVING count(*) > 0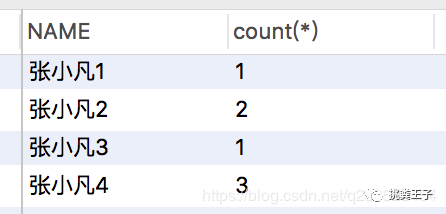
然后我们想要删除重复数据,只保留id最小的, 这里我先要知道所有准备删除的数据,即重复数据。
根据上面已知的name,我们可以用sql获得重复数据
SELECT *FROM studentWHERE NAME IN( SELECT * FROM ( SELECT NAME FROM student GROUP BY `name` HAVING count(*) > 1 ) t1 )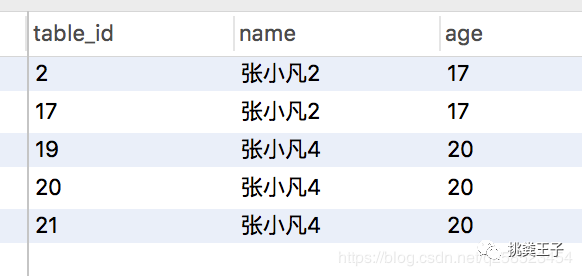
最后我们要删除这些重复数据,只保留最小的table_id,还是需要用到group by,获得最小的table_id
完整的sql:
注意:把下面 {SELECT *} 改成 { DELETE } 就可以删除重复数据了
SELECT *FROM studentWHERE NAME IN( SELECT * FROM ( SELECT NAME FROM student GROUP BY `name` HAVING count(*) > 1 ) t1 )AND table_id NOT IN( SELECT * FROM ( SELECT MIN(table_id) FROM student GROUP BY NAME HAVING count(*) > 1 ) t2)查询出待删除的数据:
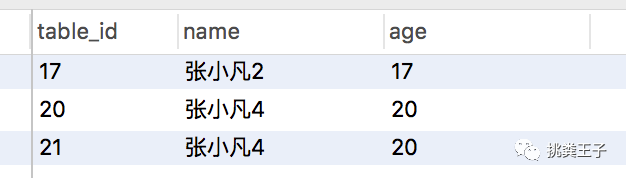
上面的sql是不是要把屏幕拉长了看,而且效率不高?
下面是另外一种写法,高效很多
SELECT * FROM studentINNER JOIN ( SELECT min(table_id) AS minId, age FROM student GROUP BY name HAVING count(*) > 1) t2 ON t2.age = student.age WHERE student.table_id > t2.minId;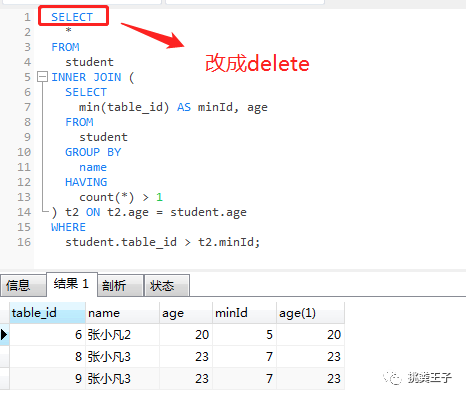
版权声明:本文为weixin_39708737原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。