文章目录
前言
1、首先此次超清重建(SR)使用的不是插值之类的传统方法,而是使用的深度学习法。(插值法就是把像素等比例拉伸,拉伸之后中间会出现空白点,这些空白的点根据之前拉伸的店进行均匀过度)
2、其次,SR问题如果使用深度学习方法,一般有两种解决思路:
- 基于单张图片去SR,就是依靠现有低频信息去猜高频信息,中途用了很多数学知识,建立模型,最终就看高频信息能不能猜的准,猜得准这个模型就好用;但是这个过程就很麻烦,费时间。
- 另外的基于参考图像方法,顾名思义,我先搜一张和原图差不多的图像,我看看他的低频信息和高频信息是怎么联系起来的,之后我再照猫画虎去推导本图像的高频信息。
- 而我就是用的第一种方法中的EDSR模型来实现超分辨率重建
3、最后,本文主要讲解EDSR都包含哪些模块?以及每个模块的作用是什么?但是对于为什么该团队偏偏使用了这些模块,在该团队的论文中以及我能查找的文献中没有说明。再加上本人能力有限,这类问题将会先行放过。
EDSR 模型架构
简介
- EDSR模型,全称为enhanced deep super-resolution network(增强的深度学习超分辨率重建网络)
在本文中,EDSR主要具有两大特点:
- 使用了ResNet残差思想
- 移除了batchnorm(就是常说的BN层-批处理层,后面会解释)
EDSR模型包含以下层/模块:
- Conv层(卷积层)
- ReLu激活层
- Mult层(残差缩放层)
- ResBlock(残差块)
- UpSample (上采样模块)。
- Shuffle层
图像输入之后,会先进行卷积、激活、残差缩放,学习到图片的高频特征,之后再进行upsample上采样(上采样对应的是下采样池化,上采样是进行分辨力增加的步骤)进行图像的最终超清晰度重建。
EDSR模型的简单架构如图:
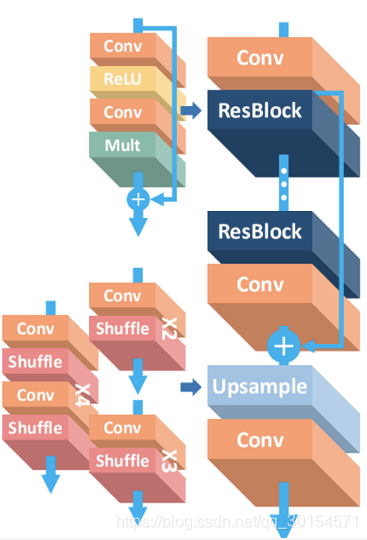
接下来就会详细讲解这些层/模块的作用。
1、Conv层(卷积层)
卷积层的作用:
- 提取图像的特征,并且卷积核的权重是可以学习的,卷积操作能突破传统滤波器的限制,根据目标函数提取出想要的特征;
- 参数共享(一个卷积核用来滤整个图像,而不是很多个卷积核),降低了网络参数,提升训练效率。
为什么卷积能够提取图像特征?
假设现在有一张图片,我们需要识别老鼠屁股上的这一片区域。
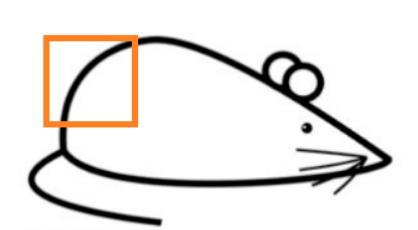
绿框内的图像值可能是这样的(当然,这并不是真正的灰度值)

而卷积核,本质上其实就是一个滤波器,可以看作是一个滤波器模板。在上图中,老鼠尾巴,就是我们要提取的特征,为了提取它,我们可以设置卷积核为下图:
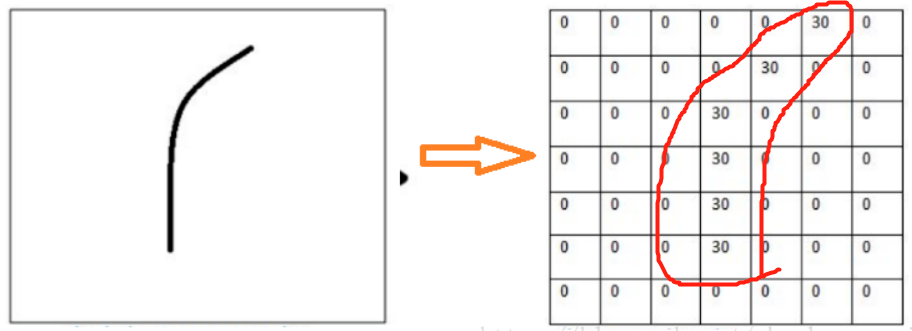
【注意】真正的卷积核的参数不是手动设置的,它是会自动学习更新的,在这里是为了演示方便所以写死了卷积核的内容。
我们将卷积核作用于图片,直接进行卷积运算,我们发现对于识别的特征计算出来的值非常大;
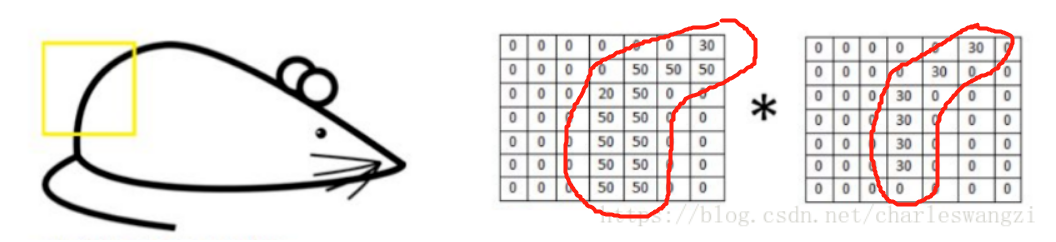
对于上面的卷积(注意,卷积的结果是一个数):(50 * 30)+(50 * 30)+(50 * 30)+(20 * 30)+(50 * 30)=6600;
而对于不能识别的特征,计算的值非常小,曲线的卷积核与其卷积得到的值为0,如下:
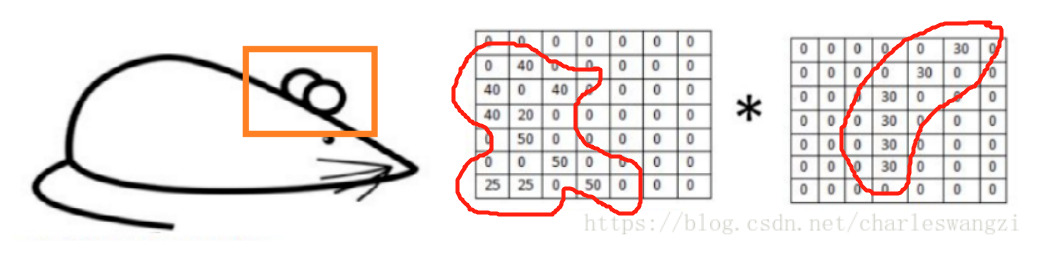
所以,如果某个图像块与此卷积核卷积出的值大,则认为此图像块十分接近于此卷积核(就是长得像)。
如果我们设计了6个卷积核,可以理解:我们认为这个图像上有6种底层纹理模式,也就是我们用6种卷积核就能描绘出目标物体的完整特征。
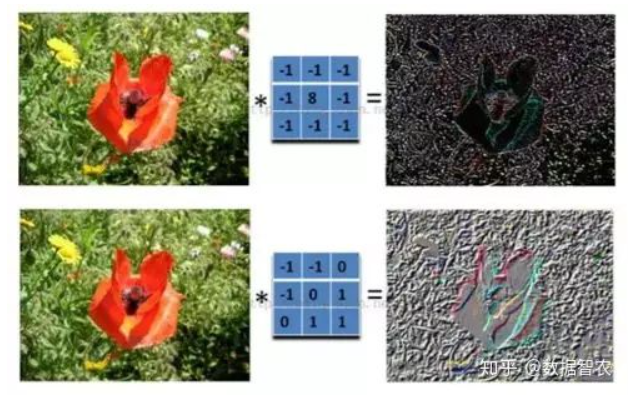
补充,什么是模板?
- 简单来说,就是一个3x3的滤波器,就是数字图像处理第一次第二次实验中中出现的那个概念,用作图像处理,如下图:
2、ReLU层
ReLU层其实就是激活函数层,将上一步卷积出来的特征矩阵进行激活,形成新矩阵。只不过该层具体使用的是ReLU激活函数而已。
ReLu图像:
激活函数的作用:
- 在神经网络中,对于图像主要采用了卷积的方式来处理,卷积层图像卷积卷积核本质上是矩阵运算,这个操作显然就是线性的。
- 激活函数是用来为模型加入非线性因素的,因为线性模型的表达力不够 (类似于AI课上那个螺旋点分类)。
为什么非要使用ReLU?
- 如果采用sigmoid比较传统的函数,算激活函数时(指数运算),计算量大。而使用Relu,整个计算节省了很多。
- 对于深层网络,sigmoid函数反向传播时,很容易出现梯度消失的情况,(sigmoid接近饱和区的时候,变化太缓慢,导数趋于0)从而无法完成深层网络的训练。
- Relu会使一部分神经元的输出为0,这样就造成了网络的稀疏性,并且减少了参数之间互相依存的关系,缓解了过拟合的发生。
换句话说,为什么不能用sigmoid函数?
- sigmoid函数,这个函数有个特点,就是能将负无穷到正无穷的数映射到0和1之间,并且对这个函数求导的结果是f′(x)=f(x)(1−f(x))。因此两个0到1之间的数相乘,得到的结果就会变得很小了。
- 神经网络的反向传播是逐层对函数偏导相乘,因此当神经网络层数非常深的时候,最后一层就因为乘了很多的小于1的数而越来越小,最终就会变为0,导致层数比较浅的权重没有更新,这就是梯度消失。
3、Mult层(残差缩放层)
- 太多的残差块会导致训练不稳定(至于为什么会这样,又是一个专业知识,在此我先不求甚解了…),因此采取了【残差缩放】的方法,即残差块在相加前,经过卷积处理的数据乘以一个小数(比如作者用了0.1),使网络更稳定。
- 有关于残差缩放的具体细节,又是好几篇论文,我先放过…
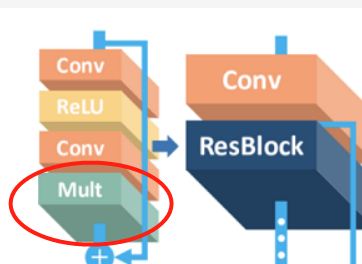
4、ResBlock(残差块)
- 残差块由之前的Conv、Relu和Mult层组合而成,除了以上三层本身并没有新加什么功能。
什么是残差思想?
- 去掉与主体内容相同的部分,从而突出微小的变化。只学习扰动。
- 这样可以用来训练特别深的网络。这样在反向求梯度拟合的过程就更容易算。
残差网络结构的思想特别适合用来解决超分辨率问题,因为:
- 低分辨率图像和输出的高分辨率图像在很大程度上是相似的,也就是指低分辨率图像携带的低频信息与高分辨率图像的低频信息相近,训练时带上这部分会多花费大量的时间,实际上我们只需要学习高分辨率图像和低分辨率图像之间的高频部分残差即可。所以残差网络结构的思想特别适合用来解决超分辨率问题。
5、为何去掉BN层(批处理规范化层)?
BN层是通常是残差架构中的模块,其在另一种SR模型——SRResNet模型中有所使用。
- Batch Norm可谓深度学习中非常重要的技术,不仅可以使训练更深的网络变容易,加速收敛,可以防止模型过拟合。在很多基于CNN的分类任务中,被大量使用(BN层很适合分类任务!)。
BN层在SR中的缺点:
- 在图像超分辨率和图像生成方面,Batch Norm表现不好,BN使得训练速度缓慢,不稳定,甚至最后使模型发散(具体的说是使损失函数发散)。
- 以图像超分辨率来说,网络输出的图像在色彩、对比度、亮度上要求和输入一致,改变的仅仅是分辨率和一些细节,而Batch Norm,对图像来说类似于一种对比度的拉伸,任何图像经过Batch Norm后,其色彩的分布都会被归一化,也就是说,它破坏了图像原本的对比度信息(比如狗不再像一个狗),所以Batch Norm的加入反而影响了网络输出的质量。
- 基于这种想法,也可以从另外一种角度解释Batch Norm为何在图像分类任务上如此有效。图像分类不需要保留图像的对比度信息,利用图像的结构信息就可以完成分类,所以,将图像都通过Batch Norm进行归一化,反而降低了训练难度,甚至一些不明显的结构,在Batch Norm后也会被凸显出来(对比度被拉开了)。
去掉BN层的意义:
- 在去掉BN后,相同的计算资源下,EDSR就可以堆叠更多的层、使每层提取更多的特征,从而得到更好的性能表现。
- EDSR在训练时先训练低倍数的上采样模型,接着用训练低倍数上采样模型得到的参数来初始化高倍数的上采样模型,这样能减少高倍数上采样模型的训练时间,同时训练结果也更好。
6、UpSample(上采样,用于扩大图像像素):
- 此模块是真正令图像扩大分辨率的模块,其功能是将输入图片按到一定规则rescale到一个想要的尺寸。
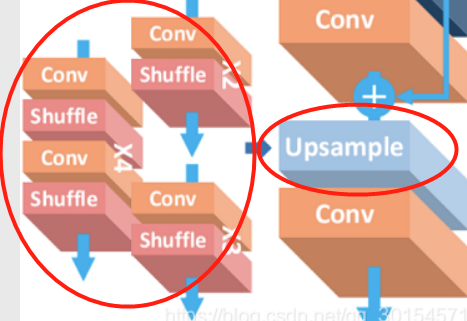
- UpSample模块由conv层和shuffle组成;
- 这里的shuffle,个人认为指的是PixelShuffle,是一种具体的上采样方法。
- UpSample的实现过程不是直接通过插值等方式产生这个高分辨率图像,而是通过卷积先得到 r2个通道的特征图,也就是说——通过卷积将通道数扩大一倍;然后再用PixelShuffle,将两个通道的特征图相互插入使得尺寸扩大一倍,来使得图像最终的超像素重建。
令附上一张原理图: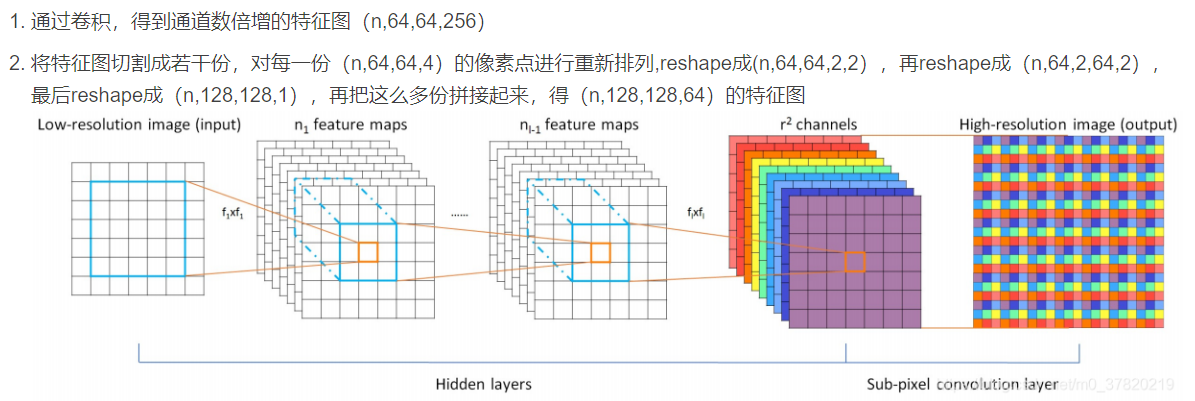
参考资料
https://www.pianshen.com/article/2449328261/
https://zhuanlan.zhihu.com/p/34818964
conv层为什么能够提取特征见:
https://blog.csdn.net/charleswangzi/article/details/82733016
BN层:https://arxiv.org/abs/1707.02921
shuffle是什么:https://blog.csdn.net/g11d111/article/details/82855946