1 DATAX简述
DataX是阿里巴巴集团内被广泛使用的离线数据同步工具/平台,实现包括 MySQL、Oracle、SqlServer、Postgre、HDFS、Hive、ADS、HBase、TableStore(OTS)、MaxCompute(ODPS)、DRDS 等各种异构数据源之间高效的数据同步功能。
DataX本身作为数据同步框架,将不同数据源的同步抽象为从源头数据源读取数据的Reader插件,以及向目标端写入数据的Writer插件,理论上DataX框架可以支持任意数据源类型的数据同步工作。同时DataX插件体系作为一套生态系统, 每接入一套新数据源该新加入的数据源即可实现和现有的数据源互通。
github地址:https://github.com/alibaba/DataX
quickstart:https://github.com/alibaba/DataX/blob/master/userGuid.md
1.1 DATAX支持的数据源
DataX目前已经有了比较全面的插件体系,主流的RDBMS数据库、NOSQL、大数据计算系统都已经接入,目前支持数据如下:
1.2 DATAX的特点
DataX的主要特点:
是一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle等)、HDFS、Hive、MaxCompute(原ODPS)、HBase、FTP等各种异构数据源之间稳定高效的数据同步功能。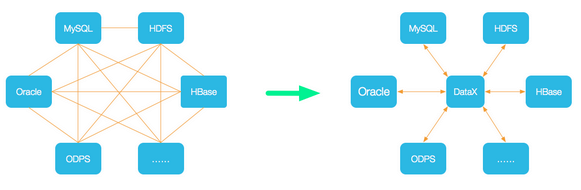
2 DATAX部署
2.1 中间件版本选取
| 中间件名称 | 版本号 |
|---|---|
| CentOS | CentOS 6.8 |
| python | 2.6.6 |
| jdk | 1.8.0_121 |
| DataX | DATAX-OPENSOURCE-3.0 |
2.2 环境准备
本次技术实践安装DataX集群,单独安装在hadoop102主机上
2.2.1 CentOS6.8
CentOS6.8安过程省略。预先创建用户/用户组zhouchen
预先安装jdk1.8.0_92 +
预先安装python2
2.2.2 关闭防火墙-root
针对CentOS7以下
1.查看防火墙状态
service iptables status
2.停止防火墙
service iptables stop
3.启动防火墙
service iptables start
2.3 集群安装
1.下载DataX
http://datax-opensource.oss-cn-hangzhou.aliyuncs.com/datax.tar.gz
2.解压
[zhouchen@hadoop102 software]$ tar -zxvf datax.tar.gz -C /opt/module/
3.修改Python执行同步
[zhouchen@hadoop102 software]$ cd /opt/module/datax/bin
[zhouchen@hadoop102 bin]$ python2 datax.py ../job/job.json
DataX (DATAX-OPENSOURCE-3.0), From Alibaba !
Copyright (C) 2010-2017, Alibaba Group. All Rights Reserved.
...
2020-07-28 10:44:48.021 [job-0] INFO JobContainer - PerfTrace not enable!
2020-07-28 10:44:48.021 [job-0] INFO StandAloneJobContainerCommunicator - Total 100000 records, 2600000 bytes | Speed 253.91KB/s, 10000 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 0.024s | All Task WaitReaderTime 0.034s | Percentage 100.00%
2020-07-28 10:44:48.022 [job-0] INFO JobContainer -
任务启动时刻 : 2020-07-28 10:44:37
任务结束时刻 : 2020-07-28 10:44:48
任务总计耗时 : 10s
任务平均流量 : 253.91KB/s
记录写入速度 : 10000rec/s
读出记录总数 : 100000
读写失败总数 : 0
3 DATAX基本操作
Datax的核心就是配置格式模板,不清楚怎么配置的可以用以下方法获取配置模板:
[zhouchen@hadoop102 bin]$ python2 datax.py -r mysqlreader -w hdfswriter


3.1 DATAX同步MYSQL->MYSQL
1.创建mysql源数据表并导入数据
mysql> CREATE DATABASE /*!32312 IF NOT EXISTS*/`userdb` /*!40100 DEFAULT CHARACTER SET utf8 */;
mysql> USE `userdb`;
msql> CREATE TABLE `emp` (
`id` int(11) DEFAULT NULL,
`name` varchar(100) DEFAULT NULL,
`deg` varchar(100) DEFAULT NULL,
`salary` int(11) DEFAULT NULL,
`dept` varchar(10) DEFAULT NULL,
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,
`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
`is_delete` bigint(20) DEFAULT '1'
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
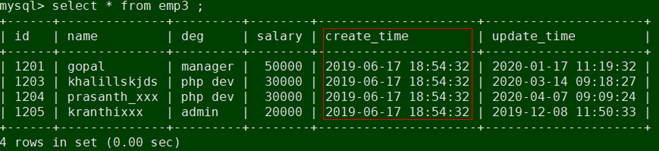
mysql> insert into `emp`(`id`,`name`,`deg`,`salary`,`dept`,`create_time`,`update_time`,`is_delete`) values (1201,'gopal','manager',50000,'TP','2019-06-17 18:54:32','2020-01-17 11:19:32',1),(1202,'manishahello','Proof reader',50000,'TPP','2019-06-15 18:54:32','2019-06-17 18:54:32',0),(1203,'khalillskjds','php dev',30000,'AC','2019-06-17 18:54:32','2020-03-14 09:18:27',1),(1204,'prasanth_xxx','php dev',30000,'AC','2019-06-17 18:54:32','2020-04-07 09:09:24',1),(1205,'kranthixxx','admin',20000,'TP','2019-06-17 18:54:32','2019-12-08 11:50:33',0),(1206,'garry','manager',50000,'TPC','2019-12-10 21:41:09','2019-12-10 21:41:09',1),(1207,'oliver','php dev',2000,'AC','2019-12-15 13:49:13','2019-12-15 13:49:13',1),(1208,'hello','phpDev',200,'TP','2019-12-16 09:41:48','2019-12-16 09:41:48',1),(1209,'ABC','HELLO',300,NULL,'2019-12-16 09:42:04','2019-12-16 09:42:24',1),(1210,'HELLO','HELLO',5800,'TP','2020-01-24 09:02:43','2020-01-24 09:02:43',1),(1211,'WORLD','TEST',8800,'AC','2020-01-24 09:03:15','2020-01-24 09:03:15',1),(1212,'sdfs','sdfsdf',8500,'AC','2020-03-13 22:01:38','2020-03-13 22:01:38',1),(1213,NULL,'sdfsdf',9800,'sdfsdf','2020-03-14 09:08:31','2020-03-14 09:08:54',1),(1214,'xxx','sdfsdf',9500,NULL,'2020-03-14 09:13:32','2020-03-14 09:13:44',0),(1215,'sdfsf','sdfsdfsdf',9870,'TP','2020-04-07 09:10:39','2020-04-07 09:11:18',0),(1216,'hello','HELLO',5600,'AC','2020-04-07 09:37:05','2020-04-07 09:37:05',1),(1217,'HELLO2','hello2',7800,'TP','2020-04-07 09:37:40','2020-04-07 09:38:17',1);

2.创建mysql目标数据表
mysql> USE userdb;
mysql> CREATE TABLE `emp3` (
`id` INT(11) DEFAULT NULL,
`name` VARCHAR(100) DEFAULT NULL,
`deg` VARCHAR(100) DEFAULT NULL,
`salary` INT(11) DEFAULT NULL,
`create_time` timestamp default CURRENT_TIMESTAMP,
`update_time` timestamp default CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
) ENGINE=INNODB DEFAULT CHARSET=latin1;
3.配置增量导入配置文件
[zhouchen@hadoop102 bin]$ cd /opt/module/datax/job
[zhouchen@hadoop102 job]$ vim mysqlAppendMysql.json
{
"job": {
"setting": {
"speed": {
"channel":1
}
},
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "zhou59420",
"connection": [
{
"querySql": [
"select id,name,deg,salary,create_time,update_time from emp where create_time > '${start_time}' and create_time < '${end_time}';"
],
"jdbcUrl": [
"jdbc:mysql://hadoop102:3306/userdb"
]
}
]
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"writeMode": "insert",
"username": "root",
"password": "zhou59420",
"column": [
"id","name","deg","salary","create_time","update_time"
],
"session": [
"set session sql_mode='ANSI'"
],
"preSql": [
"delete from emp3"
],
"connection": [
{
"jdbcUrl": "jdbc:mysql://hadoop102:3306/userdb?useUnicode=true&characterEncoding=utf-8",
"table": [
"emp3"
]
}
]
}
}
}
]
}
}
配置全量导入配置文件
只需将上面配置文件中的querySql 改为: select id,name,deg,salary,create_time,update_time from emp 即可
4.执行同步任务
[zhouchen@hadoop102 job]$ python ../bin/datax.py ./mysqlAppendMysql.json -p "-Dstart_time='2019-06-17 00:00:00' -Dend_time='2019-06-18 23:59:59'"
...
...
2020-07-28 11:48:43.579 [job-0] INFO JobContainer - PerfTrace not enable!
2020-07-28 11:48:43.579 [job-0] INFO StandAloneJobContainerCommunicator - Total 4 records, 165 bytes | Speed 16B/s, 0 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 0.000s | All Task WaitReaderTime 0.000s | Percentage 100.00%
2020-07-28 11:48:43.600 [job-0] INFO JobContainer -
任务启动时刻 : 2020-07-28 11:48:33
任务结束时刻 : 2020-07-28 11:48:43
任务总计耗时 : 10s
任务平均流量 : 16B/s
记录写入速度 : 0rec/s
读出记录总数 : 4
读写失败总数 : 0
3.2 DATAX同步MYSQL->HIVE
1.创建hive目标数据表
[zhouchen@hadoop102 ~]$ /opt/module/hive/bin/beeline
Beeline version 1.2.1 by Apache Hive
beeline> !connect jdbc:hive2://hadoop102:10000
Connecting to jdbc:hive2://hadoop102:10000
Enter username for jdbc:hive2://hadoop102:10000: zhouchen
Enter password for jdbc:hive2://hadoop102:10000: *********
Connected to: Apache Hive (version 1.2.1)
Driver: Hive JDBC (version 1.2.1)
Transaction isolation: TRANSACTION_REPEATABLE_READ
1: jdbc:hive2://hadoop102:10000> use default;
No rows affected (0.037 seconds)
1: jdbc:hive2://hadoop102:10000> CREATE external table emp (
1: jdbc:hive2://hadoop102:10000> id int,
1: jdbc:hive2://hadoop102:10000> name string,
1: jdbc:hive2://hadoop102:10000> deg string,
1: jdbc:hive2://hadoop102:10000> salary double,
1: jdbc:hive2://hadoop102:10000> dept string,
1: jdbc:hive2://hadoop102:10000> create_time timestamp,
1: jdbc:hive2://hadoop102:10000> update_time timestamp,
1: jdbc:hive2://hadoop102:10000> isdeleted string
1: jdbc:hive2://hadoop102:10000> )
1: jdbc:hive2://hadoop102:10000> row format deltmited fields terminated by '\001';
2.创建增量导入配置文件
[zhouchen@hadoop102 bin]$ cd /opt/module/datax/job
[zhouchen@hadoop102 job]$ vim mysqlAppendHive.json
{
"job": {
"setting": {
"speed": {
"channel": "1"
}
},
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": [
],
"connection": [
{
"querySql":[
"select * from emp where create_time > '${start_time}' and create_time < '${end_time}'"],
"jdbcUrl": [
"jdbc:mysql://hadoop102:3306/userdb"]
}
],
"password": "zhou59420",
"username": "root"
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [
{
"name": "id",
"type": "INT"
},
{
"name": "name",
"type": "STRING"
},
{
"name": "deg",
"type": "STRING"
},
{
"name": "salary",
"type": "DOUBLE"
},
{
"name": "dept",
"type": "STRING"
},
{
"name": "create_time",
"type": "TIMESTAMP"
},
{
"name": "update_time",
"type": "TIMESTAMP"
},
{
"name": "isdeleted",
"type": "STRING"
}
],
"defaultFS": "hdfs://hadoop102:9000",
"fieldDelimiter": "\u0001",
"fileName": "emp",
"fileType": "Text",
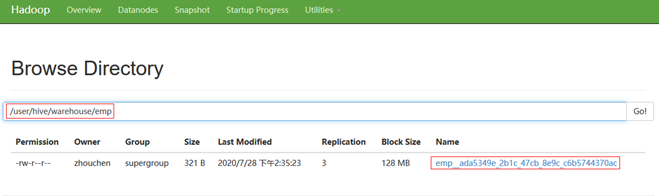
"path": "/user/hive/warehouse/emp",
"writeMode": "append"
}
}
}
]
}
}
注意:writeMode 仅支持append, nonConflict两种模式
3.执行同步任务
[zhouchen@hadoop102 job]$ python2 ../bin/datax.py ./mysqlAppendHive.json -p "-Dstart_time='2019-06-17 00:00:00' -Dend_time='2019-06-18 23:59:59'"
...
...
2020-07-28 14:29:31.577 [job-0] INFO JobContainer - PerfTrace not enable!
2020-07-28 14:29:31.577 [job-0] INFO StandAloneJobContainerCommunicator - Total 4 records, 177 bytes | Speed 17B/s, 0 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 0.000s | All Task WaitReaderTime 0.000s | Percentage 100.00%
2020-07-28 14:29:31.579 [job-0] INFO JobContainer -
任务启动时刻 : 2020-07-28 14:29:19
任务结束时刻 : 2020-07-28 14:29:31
任务总计耗时 : 11s
任务平均流量 : 17B/s
记录写入速度 : 0rec/s
读出记录总数 : 4
读写失败总数 : 0

4 基于DATAX的数据同步可视化平台
参考:https://segmentfault.com/a/1190000020939295?utm_source=tag-newest
https://github.com/WeiYe-Jing/datax-web/blob/master/doc/datax-web/datax-web-deploy.md
安装方式1:下载https://github.com/WeiYe-Jing/datax-web自己编译
安装方式2:下载官方编译好的tar包安装https://pan.baidu.com/s/13yoqhGpD00I82K4lOYtQhg 提取码:cpsk
这里推荐第二种部署方式。
4.1 DATAX-WEB部署
1.解压
[zhouchen@hadoop102 software]$ tar -zxvf datax-web-2.1.2.tar.gz -C /opt/module/datax
2.执行安装 –forece表示交互模式下安装
[zhouchen@hadoop102 datax]$ cd datax-web-2.1.2
[zhouchen@hadoop102 datax-web-2.1.2]$ ./bin/install.sh --force
2020-07-28 16:57:39.371 [INFO] (8996) ####### Start To Uncompress Packages ######
2020-07-28 16:57:39.374 [INFO] (8996) Uncompressing....
2020-07-28 16:57:39.379 [INFO] (8996) Uncompress package: [datax-admin_2.1.2_1.tar.gz] to modules directory
2020-07-28 16:57:40.745 [INFO] (8996) Uncompress package: [datax-executor_2.1.2_1.tar.gz] to modules directory
2020-07-28 16:57:40.965 [INFO] (8996) ####### Finish To Umcompress Packages ######
Scan modules directory: [/opt/module/datax/datax-web-2.1.2/bin/../modules] to find server under dataxweb
2020-07-28 16:57:40.968 [INFO] (8996) ####### Start To Install Modules ######
2020-07-28 16:57:40.970 [INFO] (8996) Module servers could be installed:
[datax-admin] [datax-executor]
2020-07-28 16:57:40.973 [INFO] (8996) Install module server: [datax-admin]
Start to make directory
2020-07-28 16:57:40.984 [INFO] (9032) Start to build directory
2020-07-28 16:57:40.987 [INFO] (9032) Directory or file: [/opt/module/datax/datax-web-2.1.2/modules/datax-admin/bin/../logs] has been exist
2020-07-28 16:57:40.988 [INFO] (9032) Directory or file: [/opt/module/datax/datax-web-2.1.2/modules/datax-admin/bin/../conf] has been exist
2020-07-28 16:57:40.990 [INFO] (9032) Directory or file: [/opt/module/datax/datax-web-2.1.2/modules/datax-admin/bin/../data] has been exist
end to make directory
Start to initalize database
2020-07-28 16:57:40.993 [INFO] (9032) Scan out mysql command, so begin to initalize the database
Do you want to initalize database with sql: [/opt/module/datax/datax-web-2.1.2/bin/db/datax_web.sql]? (Y/N)Y
Please input the db host(default: 127.0.0.1): hadoop102
Please input the db port(default: 3306): 3306
Please input the db username(default: root): root
Please input the db password(default: ): zhou59420
Please input the db name(default: dataxweb)dataweb
Warning: Using a password on the command line interface can be insecure.
2020-07-28 16:58:07.644 [INFO] (8996) Install module server: [datax-executor]
2020-07-28 16:58:07.658 [INFO] (9068) Start to build directory
2020-07-28 16:58:07.659 [INFO] (9068) Directory or file: [/opt/module/datax/datax-web-2.1.2/modules/datax-executor/bin/../logs] has been exist
2020-07-28 16:58:07.662 [INFO] (9068) Directory or file: [/opt/module/datax/datax-web-2.1.2/modules/datax-executor/bin/../conf] has been exist
2020-07-28 16:58:07.663 [INFO] (9068) Directory or file: [/opt/module/datax/datax-web-2.1.2/modules/datax-executor/bin/../data] has been exist
2020-07-28 16:58:07.665 [INFO] (9068) Directory or file: [/opt/module/datax/datax-web-2.1.2/modules/datax-executor/bin/../json] has been exist
2020-07-28 16:58:07.667 [INFO] (8996) ####### Finish To Install Modules ######
install完成之后的配置文件在/opt/module/datax/datax-web-2.1.2/modules/datax-admin/conf/bootstrap.properties。如果没有—forece模式的话,直接修改此配置即可。
3.配置
邮件配置(可选)
[zhouchen@hadoop102 datax-web-2.1.2]$ vim /opt/module/datax/datax-web-2.1.2/modules/datax-admin/bin/env.properties
MAIL_USERNAME=""
MAIL_PASSWORD=""
Python路径.这个很重要,必须选择datax的python启动脚本
[zhouchen@hadoop102 datax-web-2.1.2]$ vim modules/datax-executor/bin/env.properties
PYTHON_PATH=/opt/module/datax/bin/datax.py
web-port
[zhouchen@hadoop102 datax-web-2.1.2]$ vim modules/datax-admin/bin/env.properties
SERVER_PORT=9527
注意:datax-executor/bin/env.properties 中的DATAX_ADMIN_PORT需要跟admin下的SERVER_PORT保持一致
4.2 DATAX-WEB启动
一键启动
[zhouchen@hadoop102 datax-web-2.1.2]$ ./bin/start-all.sh
一键停止
[zhouchen@hadoop102 datax-web-2.1.2]$ ./bin/stop-all.sh
可视化界面
http://hadoop102:9527/index.html
默认的用户/密码:admin/123456
4.3 DATAX-WEB可视化构建
1.创建项目
2.创建模板
3.配置数据源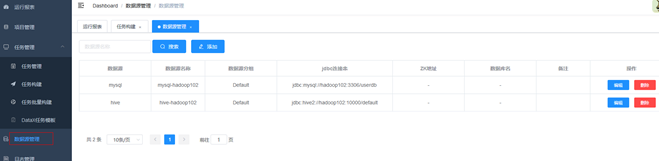
4.创建任务
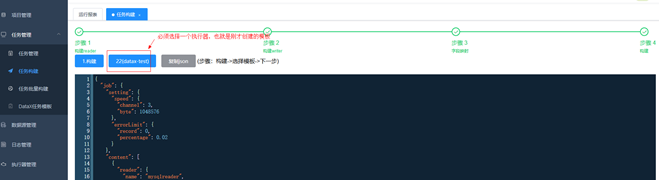
5.启动任务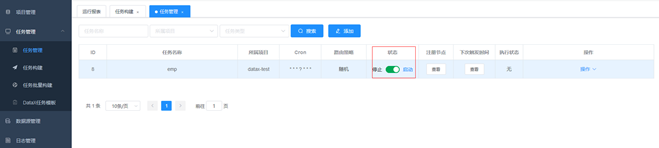
5 DATAX在有赞大数据平台的实践
参考链接:https://tech.youzan.com/datax-in-action/
这篇案例主要讲的是有赞大数据DataX的实践,主要讲的是Datax分布式部署、通过源码改造直接支持hive读写、还有结果汇报等内容。
5.1 DATAX分布式部署和运行问题
使用 DataX 最重要的是解决分布式部署和运行问题,DataX 本身是单进程的客户端运行模式,需要考虑如何触发运行 DataX。
我们决定复用已有的离线任务调度系统,任务触发由调度系统负责,DataX 只负责数据同步。这样就复用了系统能力,避免重复开发。
在每个数据平台的 worker 服务器,都会部署一个 DataX 客户端,运行时可同时启动多个进程,这些都由调度系统控制。
5.2 源码改造-支持HIVE读写
DataX 并没有自带 Hive 的 reader 和 writer,而只有 HDFS 的 reader 和writer。我们选择在 DataX 之外封装,把 Hive 读写操作的配置文件,转换为 HDFS 读写的配置文件,另外辅助上 Hive DDL 操作。具体的,我们做了如下改造
5.2.1 Hive 读操作
• 根据表名,拼接出 HDFS 路径。有赞的数据仓库规范里有一条,禁止使用外部表,这使得 HDFS 路径拼接变得容易。若是外部表,就需要从元数据系统获取相应的路径
• Hive 的表结构获取,需要依赖元数据系统。还需对 Hive 表结构做校验,后面会详细说明
5.2.2 Hive 写操作
• 写 Hive 的配置里不会指定 Hive 的文件格式、分隔符,需要读取元数据,获取这些信息填入 HDFS 的写配置文件
• 支持新建不存在的 Hive 表或分区,能构建出符合数据仓库规范的建表语句
5.3 与大数据体系交互
DataX 自带了运行结果的统计数据,我们希望把这些统计数据上报到元数据系统,作为 ETL 的过程元数据存储下来。
基于我们的开发策略,不要把有赞元数据系统的 api 嵌入 DataX 源码,而是在 DataX 之外获取 stdout,截取出打印的统计信息再上报。
6 DATAX常见问题分析
6.1 运行样例同步作业失败
报错:
[zhouchen@hadoop102 bin]$ python datax.py ../job/job.json
File "datax.py", line 114
print readerRef
^
SyntaxError: Missing parentheses in call to 'print'. Did you mean print(readerRef)?
分析:
环境上的Python版本是Python3,python2的print在python3中变为了print()函数。这里datax.py必须要用Python2执行。
安装python2,然后执行datax.py脚本
[zhouchen@hadoop102 bin]$ python2 datax.py ../job/job.json
DataX (DATAX-OPENSOURCE-3.0), From Alibaba !
Copyright (C) 2010-2017, Alibaba Group. All Rights Reserved.
...
...
2020-07-28 10:44:48.021 [job-0] INFO JobContainer - PerfTrace not enable!
2020-07-28 10:44:48.021 [job-0] INFO StandAloneJobContainerCommunicator - Total 100000 records, 2600000 bytes | Speed 253.91KB/s, 10000 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 0.024s | All Task WaitReaderTime 0.034s | Percentage 100.00%
2020-07-28 10:44:48.022 [job-0] INFO JobContainer -
任务启动时刻 : 2020-07-28 10:44:37
任务结束时刻 : 2020-07-28 10:44:48
任务总计耗时 : 10s
任务平均流量 : 253.91KB/s
记录写入速度 : 10000rec/s
读出记录总数 : 100000
读写失败总数 : 0
6.2 JSON格式错误
报错:
2020-07-28 14:12:33.303 [main] ERROR Engine -
经DataX智能分析,该任务最可能的错误原因是:
com.alibaba.datax.common.exception.DataXException: Code:[Common-00], Describe:[您提供的配置文件存在错误信息,请检查您的作业配置 .] - 配置信息错误. 您提供的配置信息不是合法的JSON格式: syntax error, pos 272 . 请按照标准json格式提供配置信息.
at com.alibaba.datax.common.exception.DataXException.asDataXException(DataXException.java:26)
at com.alibaba.datax.common.util.Configuration.<init>(Configuration.java:1066)
at com.alibaba.datax.common.util.Configuration.from(Configuration.java:79)
at com.alibaba.datax.core.util.ConfigParser.parseJobConfig(ConfigParser.java:75)
at com.alibaba.datax.core.util.ConfigParser.parse(ConfigParser.java:26)
at com.alibaba.datax.core.Engine.entry(Engine.java:137)
at com.alibaba.datax.core.Engine.main(Engine.java:204)
手写的json多少可能会出错,符号啊,中英文啊什么的,建议先校验一下:
https://www.sojson.com/