(原文中图有点乱,全部贴在本博客末尾)
摘要
近年来,人脸图像处理取得了很大的进展。然而,以前的方法要么对预先确定的一组面部属性进行处理,要么让用户几乎没有交互处理图像的自由。为了克服这些缺点,我们提出了一个新的框架,称为MaskGAN,实现了多样性和互动的面部处理。我们的核心思想是:语义上的面部掩膜是对灵活的面部操作以及可靠的面部细节保存的的一个中间表示。MaskGAN主要由两部分组成:1)密集映射网络(DMN)和2)编辑行为模拟训练(EBST)。具体来说,DMN学习任意形式的用户掩膜与目标图像之间的样式映射,这使得可以生成多种多样的结果。EBST对用户在原始掩膜上的编辑进行建模,使整个框架对各种操作输入更加鲁棒。具体来说,它引入了双重编辑一致性作为辅助监督信号。为了便于广泛的研究,我们构建了一个大规模的高分辨率人脸数据集,该数据集具有细粒度的掩膜注释,名为CelebAMask HQ。MaskGAN在两个具有挑战性的任务:属性转换和样式复制上进行了综合评估,显示出优于其他最先进方法的性能。代码、模型、数据集从如下链接获得:https://github.com/switchablenorms/CelebAMask-HQ。
1.介绍
人脸图像处理是计算机视觉和计算机图形学中的一项重要任务,它可以实现自动的面部表情和风格(如发型、肤色)转换等许多应用。此任务大致可分为两类:语义级处理和几何级处理。然而,这些方法要么对预先定义的属性集进行处理,要么让用户几乎没有交互处理面部图像的自由。为了克服上述缺点,我们提出了一个名为MaskGAN的新框架,旨在实现多样性和交互式的面部处理。我们的核心思想是:语义上的面部掩膜是对灵活的面部操作以及可靠的面部细节保存的的一个中间表示。MaskGAN没有直接变换像素空间中的图像,而是将面部处理过程学习为在掩膜上的转化,从而在面部组成、形状和姿势方面产生更多样的结果。 MaskGAN的另一个优点是,它为用户提供了一种直观的方式来指定形状、位置和面部组成等用于交互式编辑。
MaskGAN主要由两部分组成:1)密集映射网络和2)编辑行为模拟训练。前者学习语义掩膜和渲染图像之间的映射,后者学习建模用户处理掩膜时的行为。具体来说,密集映射网络由图像生成主干网和空间感知样式编码器组成。空间感知样式编码器以目标图像及其对应的语义标签掩模作为输入;它为图像生成主干生成空间感知样式特征。在接收到用户修改之后的掩膜后,图像生成骨干学习根据空间感知样式特征合成人脸。通过这种方式,我们的密集映射网络能够学习用户修改的掩膜和目标图像之间的细粒度样式映射。
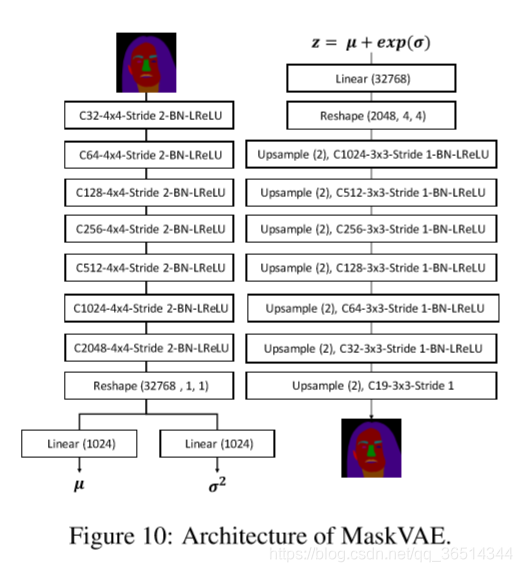
编辑行为模拟训练是一种建模用户在原掩码上编辑行为的训练策略。它引入了双重编辑一致性作为辅助监督信号。其训练流程由存在的密集映射网络、预训练的MASKVAE和alpha混合子网络组成。核心思想是将两个局部扰动的输入掩膜(由MASKVAE学习)混合在一起的生成结果应该保留主观的外观和身份信息。具体来说,具有编码解码架构的MaskVAE负责建模几何结构先验的流形。alpha混合子网络学习执行alpha混合作为图像合成,这有助于保持处理的一致性。经过编辑行为模拟训练后,密集映射网络对推理过程中用户输入掩码的各种变化具有更强的鲁棒性。
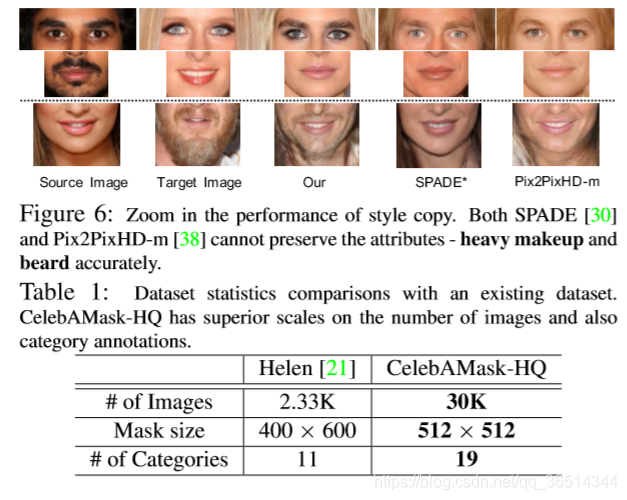
MaskGAN在属性转换和风格复制两个具有挑战性的任务上进行了综合评估,与其他最先进的方法相比,显示出优越的性能。为了便于大规模的研究,我们构建了一个大规模的高分辨率人脸数据集,该数据集带有细粒度的掩膜标签,名为CelebAMask HQ。具体来说,CelebAMask HQ由超过30000张512×512分辨率的人脸图像组成,每张图像都用19个面部组成类别的语义掩膜进行注释,例如眼睛区域、鼻子区域、嘴巴区域。
总之,我们的贡献有三方面:
1) 我们提出的MaskGAN实现了多样的和互动的面部处理。在MaskGAN框架下,进一步提出了密集映射网络,为用户提供了一种使用其语义标签掩膜进行人脸操作的交互方式。2) 提出了一种新的训练策略,称为编辑行为模拟训练,增强了密集映射网络对推理过程中用户输入掩膜形状变化的鲁棒性。3) 我们贡献了CelebA Mask HQ,一个大规模的高分辨率人脸数据集,带有掩膜注释。我们相信这个面向几何学的数据集将为人脸编辑和处理方向开辟新的研究方向。
2.相关工作
生成对抗网络。GAN通常由相互竞争的生成器和鉴别器组成。由于GAN可以生成逼真的图像,因此它在图像到图像的转换、图像修复和虚拟试穿等任务中具有广泛的应用。
语义层面的人脸操作。深层语义层面的人脸编辑已经研究了几年。包括[2,25,31,20,23,22]在内的许多著作都取得了令人印象深刻的成果。IcGAN引入了一个编码器来学习条件GAN的逆映射。DIAT利用对抗损失转迁移属性,并且学习混合预测脸和原始脸。Fader Network利用对抗性训练从潜在空间中分离出与属性相关的特征。StarGAN提出了一种基于目标域标签的单网络多域图像翻译方法。然而,这些方法不能通过示例生成图像。
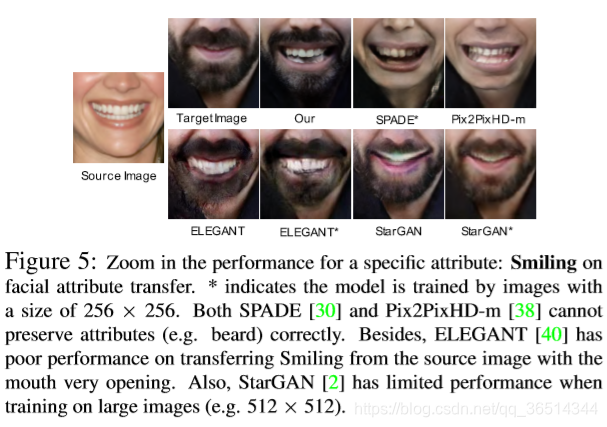
几何层面的人脸操作。最近的一些研究开始讨论从实例层面转移面部特征的可能性。例如,ELEGANT提出通过交换两个人脸的潜在码来交换两个人脸之间的属性。然而,ELEGANT无法准确地从示例中传递属性(例如“微笑”)。对于基于3D的人脸操作,尽管基于3D的方法在正常姿势下取得了令人满意的结果,但是它们通常在计算上是昂贵的,并且在大的和极端的姿势下它们的性能可能会降低。
3.我们的方法
总体框架。我们的目标是使用MaskGAN实现结构化适用的人脸操作,给定一张目标图像,目标图像的语义掩膜
和原图像的语义掩膜
(用户修正之后的掩膜)。当用户操作
的结构时,我们的模型能够合成一个处理后的脸
,其中C是语义标签的类别数。
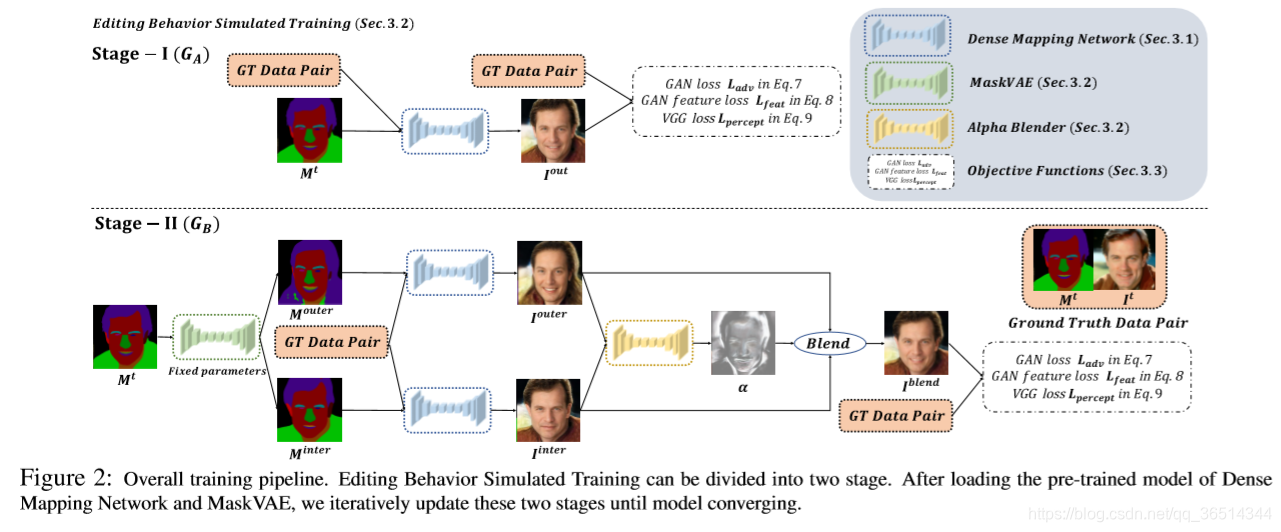
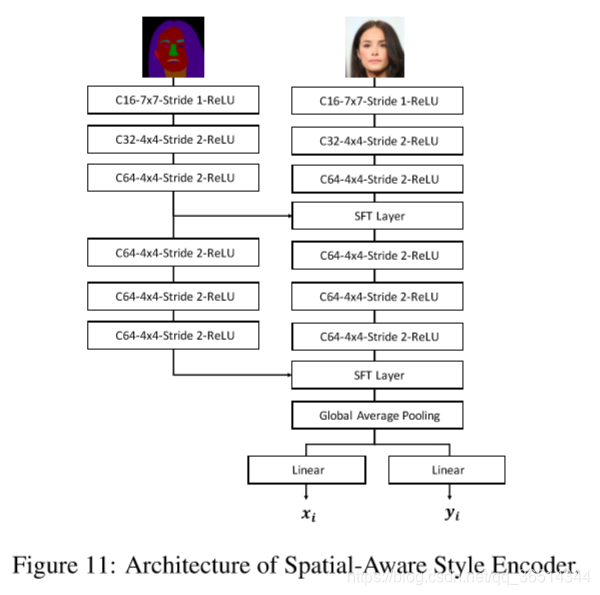
训练流程。如图11所示,MaskGAN由三个关键元素组成:密集映射网络(DMN)、MaskVAE和Alpha混合器,Alpha混合器通过编辑行为模拟训练(EBST)进行训练。DMN(见第3.1节)为用户提供了一个面向语义标签掩膜的人脸操作界面,该界面可以学习人脸与
之间的样式映射。MaskVAE负责对结构先验的流形进行建模(见3.2节)。Alpha混合器负责保持操作的一致性(见3.2节)。为了使DMN在推理的时候对用户定义的掩膜
的变化更为鲁棒,我们提出了一种新的训练策略EBST(见第2节3.2)它可以模拟用户在
上的编辑行为。这种训练方法需要一个训练有素的DMN、一个重构误差很小的MaskVAE和一个从头开始训练的Alpha混合器。训练流程可分为两个阶段。在训练阶段,我们用
来代替
作为输入。在第一阶段,我们首先用
和
更新DMN。在第二阶段中,我们使用MaskVAE生成了两个与
有微小差异的
和
,并生成了两个人脸
和
。然后Alpha混合器把这两张脸混合成
来保持操作一致性。经过EBST后,DMN对
在推理阶段的变化具有更强的鲁棒性。目标函数的详细信息见3.3节。
推理过程。在测试中我们只需要DMN。在图12中,与训练阶段不同的是,我们简单地将图像生成骨干网的输入替换为,其中
可以由用户定义。
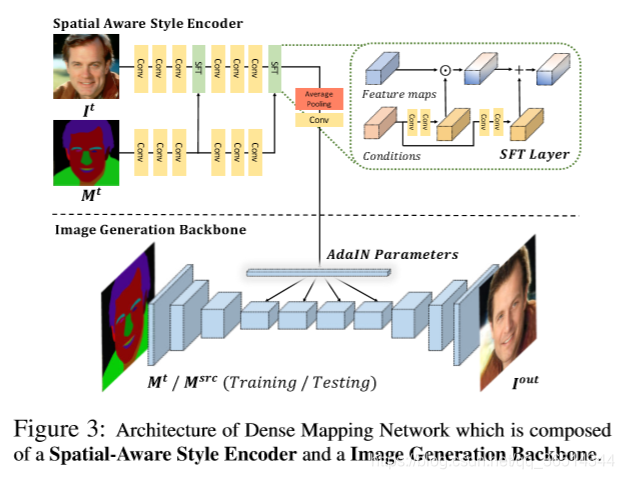
3.1.密集映射网络
密集映射网络采用Pix2PixHD为骨干的体系结构,我们采用一个外部编码器对其进行扩展,
输入为
和
。详细的架构如图12所示。
空间感知样式编码器。我们提出了一种空间感知的样式编码网络,它同时接收样式信息
和相应的空间信息
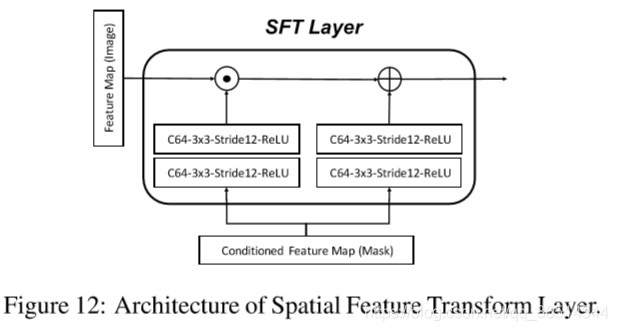
。为了融合这两个域,我们用了SFT-GAN[39]中的空间特征变换(SFT)。SFT层学习一个映射函数
,其中仿射变换参数
由先验条件
获得,如式
。在获取了
之后,SFT层对特征图F同时进行特征层面和空间层面的调制,如式:
,其中F的维度和
相同,
代表元素层面的结果。我们从
的特征获得先验条件
,并且从
获得特征图F。因此,我们以风格信息
作为空间信息
的条件,并且用以下方式生成
。
![]()
其中是包含空间感知样式信息的仿射参数。为了将空间感知样式信息传输到目标掩膜输入中,我们在DMN中的残差块
中使用AdaIN。AdaIN时风格迁移上最好的最好的方法,其定义为:
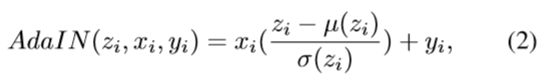
其与实例归一化类似,但是用条件样式信息代替IN的仿射参数。
DMN是一个生成器,定义为,其中
。通过空间感知样式编码器,DMN根据
提供的空间信息学习
和
之间的样式映射。因此,
的样式(例如发型和皮肤样式)会转换到
上的相应位置,以便DMN可以合成最终的处理过的脸部
。
3.2编辑行为模拟训练
编辑行为模拟训练可以在训练期间模拟用户在上的编辑行为。这种训练方法需要一个训练有素的密集映射网络
,一个训练到低重构误差的MaskVAE,和一个从零开始训练的Alpha混合器。MaskVAE由
和
组成,负责结构先验流行的建模。Alpha混合器B负责保持操作的一致性。我们把
定义为另一个生成器,把MaskVAE、DMN和Alpha 混合器当作
,其中
。整个训练流程如图11,详细算法在算法一中展示。训练流程能分为两阶段。首先我们需要加载预训练模型
,
,
。在第一阶段,我们更新
一次。在第二阶段,给定
,我们通过微小的结构上的内插和外插得到两个新的掩膜
和
,内插和外插是在掩模的潜在空间上加上两个方向相反的平行矢量实现。那些向量通过
计算得到,其中
是任意选择的掩膜
的潜在表示。
设为2.5,用于合适的混合。在用DMN生成两个人脸之后,Alpha混合器学习将两个图像混合到目标图像中,目标图像保持与原始图像的一致性。然后,我们迭代更新
和
。(图11中的1,2阶段)直到模型收敛。在EBST之后,DMN会在推理过程中对用户修改的掩模上的变化具有更强的鲁棒性。
MaskVAE提供的结构先验。类似于变分自编码器,学习MaskVAE的目标函数包括两部分:(i),它控制了像素级语义标签差异, (ii)
,它控制着潜在空间的平滑度。总体目标是最小化以下损失函数:
![]()
式中,设为1e-5,通过交叉验证获得。编码网络
输出潜在向量的均值
和协方差
。我们使用KL散度损失来最小化先验P(z)和学习分布之间的差距,即:
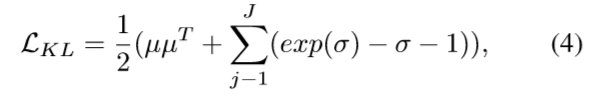
其中表示向量第j个元素的(原文就是这样的,感觉少了什么内容)。然后在训练阶段我们采样潜在向量:
,其中
~
,是一个随机变量,
代表元素级的乘法。
解码器网络输出重构语义标签,并且计算像素级的交叉熵损失:
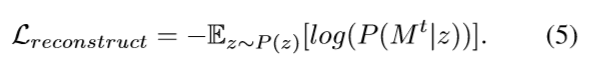
图13示出了两个掩模之间的线性插值的样本。MaskVAE可以在掩膜上执行平滑转换,EBST依赖于平滑的潜在空间来操作。
通过Alpha混合器操作一致性。为了保持和
之间的操作一致性。我们通过基于alpha混合器B的深度神经网络实现了用于图像合成的Alpha混合,它用两张输入图像
和
学习了alpha混合输入权重
。
。在学习了合适的
之后,alpha混合器混合了
和
:
。正如图11的第二阶段展示的那样,Alpha混合器与两个共享加权密集映射网络联合优化。模型组定义为
。
3.3多目标许学习
学习和
的目标函数由三部分组成:(i)
,这是条件对抗性损失,使得生成的图像更加真实,并根据条件掩模
修正生成结构,(ii)
,它鼓励生成器在多个尺度上生成自然统计,(iii)
,它用ImageNet训练的Vgg19从低频到高频细节产生在感知上提神内容生成。为了提高高分辨率图像的合成质量,我们利用多尺度鉴别器来增加接收场并减少生成图像中出现的重复模式。我们使用两个相同网络结构的
鉴别器在两个不同的尺度下工作。总体目标是最小化以下损失函数:
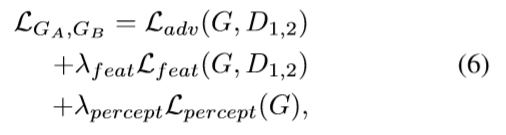
其中和
设置为10,通过交叉验证获得。
是条件判别损失,定义为:
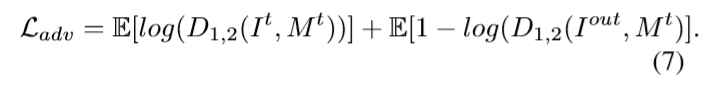
是特征匹配损失,它用来自判别器的中间层特征计算真实图像与生成图像之间的L1损失:
![]()
是感知损失它用来Vgg19的中间层特征计算真实图像与生成图像之间的L1损失。
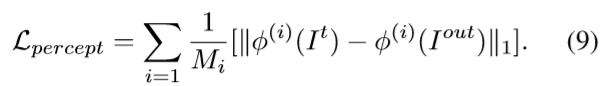
4.数据集
5.实验
不翻译了