首先我们要明确为什么要将数据归一化或者说是标准化,因为不同数据范围相差太大,不好比较,所以要消除不同量纲单位带来的影响,归一化后各数据指标处于同一数量级,适合进行综合对比评价
想要数据集或者有什么不明白的可以点赞关注后私信答主
归一化一般是把数据调整到[0,1]范围内
每一列处理公式是 (x-min)/(max-min)max min为那一列的最大和最小值
原数据如下:
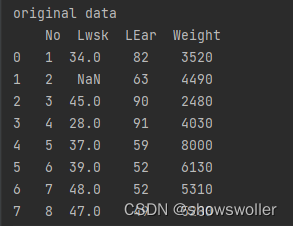
归一化后数据如下:
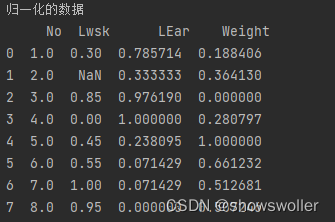
代码如下
from sklearn import preprocessing
import pandas as pd
import numpy as np
def MaxMinNormalizetion(x):
shapeX=x.shape
rows=shapeX[0]
cols=shapeX[1]
headers=list(x)
result=pd.DataFrame(columns=headers)
for i in range(0,rows,1):
dict1={}
dict1[headers[0]]=x['No'][i]
for j in range(1,cols,1):
maxcol=x[headers[j]].max()
mincol=x[headers[j]].min()
val=(x.iloc[i,j]-mincol)/(maxcol-mincol)#一般是(x-min)/(max-min)进行归一化处理
dict1[headers[j]]=val
result=result.append(dict1,ignore_index=True)
return result
data1=pd.read_csv(r'CatInfo.csv')
print('original data\n',data1)
newdata=MaxMinNormalizetion(data1)
print('归一化的数据\n',newdata)但是眼尖的同学可以发现里面是有空值的 这对我们进行后续的运算是非常不利的 我们要把他消除
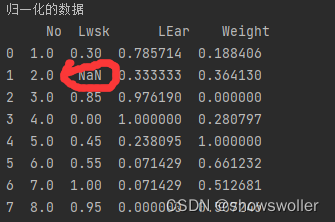
消除空值后如下
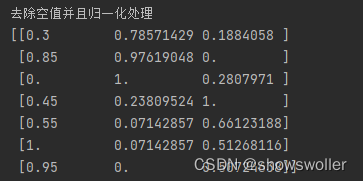
代码如下
from sklearn import preprocessing
import pandas as pd
import numpy as np
print("去除空值并且归一化处理")
y=data1.dropna(axis=0).iloc[:,1:]#去除空值
min_max_scaler=preprocessing.MinMaxScaler()
x_minmax=min_max_scaler.fit_transform(y)
print(x_minmax)想要数据集或者有什么不明白的可以点赞关注后私信答主
版权声明:本文为jiebaoshayebuhui原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。