目录
1. 设备驱动概述
1.1 万物皆文件
① Linux将设备纳入文件系统的范畴进行管理,每个设备都对应一个文件名,在内核中也就对应一个索引节点。应用程序通过设备的文件名寻找具体的设备,而设备则像普通文件一样受到文件系统访问权限控制机制的保护
② 对文件操作的系统调用大都适用于设备文件,用户的操作通过一组标准化的调用执行,而这些调用独立于特定的驱动程序。将这些调用映射到作用于实际硬件设备的操作上,由驱动程序完成
③ 从应用程序的角度看,设备文件逻辑上的空间是一个线性空间(起始地址为0,每读取1个字节地址加1)。从这个逻辑空间到具体物理设备空间(e.g. 磁盘的磁道和扇区)的映射由内核提供,并被划分为文件操作和设备驱动2个层次
说明:文件操作是对设备操作的组织和抽象,而设备操作则是对文件操作的最终实现
1.2 设备分类
1.2.1 块设备
① 像磁盘那样以块或扇区为单位,成块进行输入 / 输出的设备,称为块设备
③ 文件系统通常建立在块设备上;也有很多文件系统建立在内存上,不需要驱动程序(e.g. proc & sysfs)
1.2.2 字符设备
① 像键盘那样以字符为单位,逐个字符进行输入 / 输出的设备,称为字符设备
1.2.3 网络设备
① 网络设备是一类特殊设备,在/dev目录下没有对应的设备文件节点,使用套接字socket文件。虽然也使用read / write系统调用,但是这些调用只作用于软件对象
1.3 设备驱动分层结构

1.3.1 驱动类型与驱动分层
① 对于一个具体设备而言,文件操作和设备驱动是一个事物的不同层次,从概念上可以把一个系统划分为应用层、文件系统层和设备驱动层三个层次
1.3.1 块设备驱动分层
对于像磁盘这样结构性强且内容需要进一步组织和抽象的设备来说,其文件系统就比较厚重,需要经过两层抽象
a. 将对磁盘物理空间的立体描述(e.g. 柱面、磁道、扇区)转换为设备逻辑空间中的块
即使在块设备上构建了文件系统,但是依然可以以raw data的方式访问块设备,比如使用dd命令,此时将绕过文件系统到块的映射
1.3.2 字符设备驱动分层
① 字符设备的文件系统层比较薄,文件的逻辑空间通常直接等价于设备的逻辑空间,所以在文件系统层不需要映射

系统调用是内核和应用程序之间的接口,而驱动程序是内核和硬件之间的接口,他为应用程序屏蔽了硬件的细节。这样在应用程序看来,硬件设备只是一个设备文件,应用程序可以像操作普通文件一样对硬件设备进行操作
1.4 设备标识
① 与文件用唯一的索引节点标识类似,一个物理设备也用唯一的索引节点标识
② 物理设备索引节点记录与特定设备建立连接所需的信息,包括设备类型、主设备号和次设备号
③ 设备类型和主设备号结合,唯一地确定了设备的驱动程序及其接口
1.5 设备创建
所需头文件 | #include <sys/types.h> #include <sys/stat.h> #include <fcntl.h> #include <unistd.h> |
函数原型 | int mknod(const char *pathname, mode_t mode, dev_t dev); |
函数参数 | pathname: 要创建的设备节点路径 mode: 指定要创建设备节点的类型和权限 其中节点类型可以使用以下宏之一, S_IFREG / S_IFCHR / S_IFBLK / S_IFIFO / S_IFSOCK dev: 如果创建的设备类型指定为S_IFCHR或S_IFBLK,则需要指定设备号,可以使用makedev函数生成 |
函数返回值 | 成功返回0;否则返回-1,并设置errno |
mknod 设备节点路径 设备类型 主设备号 次设备号
# mknod /dev/test c 241 02. IO空间管理
2.1 IO内存与IO端口
2.1.1 设备控制器
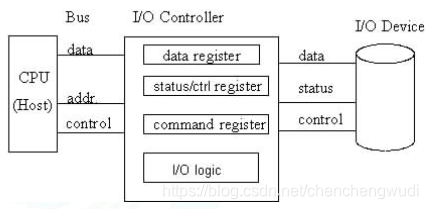
① 设备控制器是计算机中的一个实体,主要职责是控制一个或多个IO设备,以实现IO设备和CPU之间的数据交换,即作为CPU和IO设备之间的接口
② 设备控制器通过控制总线接收从CPU发来的命令,然后去控制IO设备工作
③ 设备通常会提供一组寄存器(控制寄存器 / 数据寄存器 / 状态寄存器),他们位于设备控制器中。从编址方式来说,被区分为IO内存和IO端口
2.1.2 IO内存
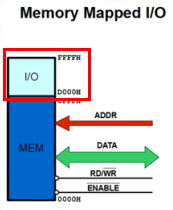
① 如果IO空间与内存一起编址,对应的内存空间被称作IO内存(e.g. ARM)
② 由于外设寄存器参与内存统一编址,可以通过访问一般内存的指令来访问寄存器
2.1.3 IO端口

① 如果IO空间单独编址,就位于IO空间,通常被称作IO端口(e.g. X86)
② 由于将外设寄存器看成一个独立的地址空间,对外设寄存器的访问需要专用指令(e.g. X86中的IN / OUT指令)
③ 与内存物理地址空间相比,IO地址空间通常都比较小,比如X86的IO空间只有64KB(0x0 ~ 0xffff),这是IO端口的主要缺点
2.2 IO资源管理
2.2.1 IO资源描述
Linux设计了一个通用的数据结构resourc(include/linux/ioport.h)e来描述各种IO资源,包括IO端口、IO内存、DMA和IRQ

成员 | 含义 |
start | 资源范围的开始 |
end | 资源范围的结束 |
name | 资源拥有者的名字 |
flags | 资源标志,比如资源类型等 |
parent / sibling / child | 构成资源的树状结构 |
IO设备在软件层面被抽象成一组资源的集合,将IO设备实体用简洁统一的视图来描述

Linux是以树状结构来管理每一类IO资源(e.g. IO端口、IO内存、DMA和IRQ),每一类IO资源都对应一颗资源树,树中的每一个节点都是一个resource结构,而树的根节点root则描述了该类资源的整个资源空间
Linux在kernel/resource.c中定义了全局变量ioport_resource和iomem_resource,他们分别描述整个IO端口空间和整个IO内存空间


使用resource结构中flags成员的bit [12:8]表示资源种类,其中每一个bit位表示一种资源,所以共有5种资源
2.2.2 IO资源管理函数
任何设备都可以使用下面三个函数申请、分配和释放资源,传递给他们的参数为资源树的根节点和要插入的新资源数据结构

request_resource
--> write_lock(&resource_lock) // 以写方式获取读写锁
--> __request_resource
--> write_unlock(&resource_lock) // 释放读写锁所以核心操作在__request_resource函数,下面分析一下该函数,

说明:要特别注意对__request_resource函数返回值的处理,
函数功能:在资源树中寻找一个给定大小和排列方式可用的范围,若存在,将这个范围分配给一个IO设备(主要由PCI设备驱动程序使用,可以使用任意的端口号和主板上的内存地址对其进行配置)

allocate_resource函数更进一步,可以根据max & min参数并考虑地址对齐地分配资源
这里注意find_resource函数的返回值,在查询成功的情况下返回0,否则返回负数。后续的if语句利用了短路特性,当find_resource失败时,不会调用__request_resource函数


2.2.3 管理IO区域资源
Linux将基于IO端口和IO内存的映射方式统称为IO区域(IO region),并提供如下3个操作接口

需要注意的是,当发现有冲突并且再次申请尝试时,会以conflict resource为新的parent的,也就是查找conflict resource的child链表
说明2:在处理IORESOURCE_MUXED标志时可能导致睡眠

如果要查找的resource是某个资源子资源的一部分,则切换到该子资源的child链表查找
从__request_region & __release_region的实现可知,IORESOURCE_MUXED标志表示软件多路复用,也就是不同驱动交替但互斥地使用这段资源。当标记为IORESOURCE_MUXED的资源已经被持有,则其他申请者进入睡眠

可见__check_region的实现方式就是尝试申请一次该区域
说明:管理IO区域的3个函数均以双下划线开头,所以是内部函数,一般不直接调用
2.2.4 管理IO端口资源
管理IO端口的函数通过封装管理IO区域管理函数的方式实现,对应的根资源为ioport_resource
// 请求在IO端口空间中分配指定范围的IO端口资源
#define request_region(start,n,name) \
__request_region(&ioport_resource, (start), (n), (name), 0)
// 释放IO端口空间中指定的IO端口资源
#define release_region(start,n) \
__release_region(&ioport_resource, (start), (n))
// 检查IO端口空间中的指定IO端口资源是否已被占用
static inline int __deprecated check_region(resource_size_t s,
resource_size_t n)
{
return __check_region(&ioport_resource, s, n);
}efine request_muxed_region(start,n,name) \
__request_region(&ioport_resource, (start), (n), (name), IORESOURCE_MUXED)该宏用于申请软件交替使用的IO端口资源,实际就是在申请资源时增加IORESOURCE_MUXED标志,该宏在X210内核代码中没有模块调用(确实这种用法很不常见)
说明2:由于IO空间非常小,因此即使外设总线有一个单独的IO端口空间,也不是所有的外设都将其IO端口(之寄存器)映射到IO端口空间中
比如大多数PCI卡都通过内存映射方式将其IO端口或外设内存映射到CPU的内存物理地址空间中;而老式的ISA卡通常将其IO端口映射到IO端口空间中
2.2.5 管理IO内存资源
管理IO端口的函数也通过封装管理IO区域管理函数的方式实现,对应的根资源为iomem_resource
// 请求分配指定的IO内存资源
#define request_mem_region(start,n,name) \
__request_region(&iomem_resource, (start), (n), (name), 0)
// 释放指定的IO内存资源
release_mem_region
#define release_mem_region(start,n) \
__release_region(&iomem_resource, (start), (n))
// 检查指定的IO内存资源是否已被占用
#define check_mem_region(start,n) \
__check_region(&iomem_resource, (start), (n))说明:使用cat /proc/ioports & cat /proc/iomem可以查看计算机上IO端口和IO内存的分配情况
以X210为例,状态如下图,从图中可以明显看出资源之间的层次关系
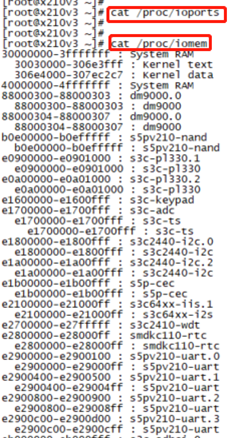
特别注意:iomen中分配的都是物理内存地址,体现在SoC的memory map中
2.3 访问IO端口空间
在驱动程序请求了IO端口空间中的端口资源后,就可以通过CPU的IO指令来读写这些IO端口。在读写IO端口时需要注意,大多数平台都区分8位 / 16位 / 32位端口

说明:port参数指定端口地址,在大多数平台上(e.g. X86)他都是unsigned short类型,其他一些平台上则是unsigned int类型。显然,端口地址的类型是由IO端口空间的大小来决定的
2.4 访问IO内存空间
2.4.1 虚拟地址映射
使用request_mem_region函数分配到IO内存之后,需要通过ioremap进行虚拟地址映射,之后在内核中才能访问该虚拟地址
/*
* offset: IO设备上一块物理内存的起始地址
* size:要映射空间的大小
*/
void *ioremap(unsigned long offset, unsigned long size);说明1:ioremap与vmalloc函数类似,也需要建立新的内核页表,只是不需要执行内存分配(因为IO物理地址已存在)

通过不同的标志,可以建立不同属性的虚拟地址映射页表,可见ioremap默认建立的虚拟地址映射是noncache的
需要注意的是,在64位系统中,对于ioremap_noncache映射的虚拟地址,如果使用memcpy操作会发生对齐错误导致kernel panic。因此如果在64位系统中要对一个映射后的虚拟地址做memcpy操作,需要使用ioremap_wc进行映射

说明3:通过ioremap获得的虚拟地址应该被iounmap函数释放,该函数原型如下,
void iounmap(void *addr);2.4.2 虚拟地址访问
在将IO内存的物理地址映射为内核虚拟地址后,理论上就可以像读写内存那样直接读写IO内存。但是由于在某些平台上,对IO内存和系统内存有不同的访问处理,因此为了确保跨平台的兼容性,Linux实现了一系列读写IO内存的函数,这些函数在不同平台上有不同的实现
// 读IO内存
readb / readw / readl
// 写IO内存
writeb / writew / writel
// 拷贝IO内存
memset_io / memcpy_fromio / memcpy_toio说明:为了保证驱动程序跨平台的可移植性,建议开发者使用上面的函数来访问IO内存
3. 设备驱动模型
3.1 设备驱动模型的引入

① 随着Linux中驱动代码量的快速增长,为了降低设备多样性带来的Linux驱动开发的复杂度,以及实现设备热插拔处理、电源管理等,Linux内核引入了设备模型(Driver Model)的概念
②设备模型将硬件设备归纳、分类,然后抽象出一套标准的数据结构和接口,驱动的开发就简化为对内核所规定的数据结构的填充和实现
③ Linux设备驱动模型跟踪所有系统所知道的设备,以便让设备驱动模型的核心程序协调驱动与新设备之间的关系
3.2 Linux设备驱动模型引入的目的
3.2.1 电源管理与系统关机
设备之间大多数情况下有依赖和耦合关系,因此要实现电源管理就必须对系统的设备结构有清楚地理解,应知道关闭设备的先后顺序
3.2.2 与用户空间通信
sysfs虚拟文件系统的实现与设备模型密切相关,并且向外界展示了他所表述的结构。向用户空间提供的系统信息以及改变操作参数的结构,都要通过sysfs文件系统实现,即通过设备模型实现
sysfs文件系统是一个类似于proc文件系统的特殊文件系统,用于将系统中的设备组织成层次结构,并向用户程序提供详细的内核数据信息

该目录下的所有子目录代表系统中当前被发现的所有块设备。按照功能来说,放在class目录下更合适,但是由于历史遗留原因一直放在block目录
但是从Linux 2.6.22开始,这部分已经被标记为过去时,只有打开了CONFIG_SYSFS_DEPRECATED配置选项才会有这个目录存在(Ubuntu 16.04中没有定义该配置项,但是仍然有block目录),并且其中的内容从Linux 2.6.26开始已经正式移到class/block目录,旧的block目录为了向后兼容而保留
该目录下的每个子目录都是kernel支持并且已经注册的总线类型。这是内核设备按照总线类型分层放置的目录结构,/sys/devices中的所有设备都是连接到某种总线之下的
一般来说每个子目录下包含2个子目录,一个是devices,另一个是drivers。其中devices目录包含这个总线下的所有设备,这些设备都是符号链接,指向/sys/devices目录下的真正设备;而drivers目录包含所有注册在这个总线上的驱动
该目录下包含所有注册在kernel中的设备类型,这是按照设备功能划分的设备模型,每个设备类型表示具有一种功能的设备。每个设备类型子目录下是这种设备类型的具体设备的符号链接,指向/sys/devices目录下的具体设备
该目录包含注册设备号文件,其中分成字符设备 & 块设备主次设备号组成的文件名,该文件是链接文件指向/sys/devices目录下的真实设备
该目录是系统加载固件机制对用户空间的接口,关于固件有专用于固件加载的一套API
该目录包含系统中所有模块信息,不论这些模块编译进内核还是编译为动态可加载模块
该目录包含系统中的电源选项,该目录下的几个属性文件可用于控制整个机器的电源状态,如可以向其中写入控制命令让机器关机 / 重启等
3.2.3 设备热插拔
3.2.4 设备分类机制
设备模型包括了对设备分类的机制,他会在更高的功能层次上描述这些设备,并使得这些设备对用户空间可见。尤其是将命名设备的功能从内核层转移到用户层,大大提高了设备管理的灵活性
3.2.5 对象生命周期管理
设备模型实现了一系列机制以处理对象的生命周期、对象之间的关系,以及这些对象在用户空间中的表示,简化编程人员创建和管理对象的工作
3.3 Linux设备模型
3.3.1 对象概述

Linux设备驱动模型使用一系列抽象(面向对象设计中的类)提供统一的设备管理视图,这些抽象包括:总线、类、设备和设备驱动
总线是CPU和一个或多个设备之间信息交互的通道,为了方便设备模型的抽象,所有设备都应连接到总线上

类主要是集合具有相似功能或属性的设备,这样就可以抽象出一套可以在多个设备之间共用的数据结构和接口函数。从属于相同class的设备驱动程序就不再需要重复定义这些公共资源,直接从class中继承即可

抽象系统中的所有硬件设备,描述他们的名字、属性、从属的Bus和从属的class等信息

包含设备初始化、电源管理相关的接口实现。Linux内核中的驱动开发,基本围绕该抽象进行(实现所规定的接口函数)

3.3.2 kobject对象

① kobject结构体是设备驱动模型底层的一个结构体,是设备驱动模型中所有对象的一个基本单元,是对所有对象共有部分的抽象
② kobject结构体提供了一些公共服务,如对象引用计数、维护对象链表、对象上锁、对用户空间的表示等
③ 设备驱动模型中的各种对象内部都会包含一个kobj结构,他相当于面向对象中的总基类
3.3.3 对象集合体kset
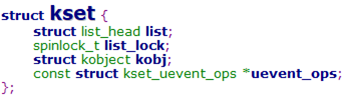
① uevent_ops指向一个用于处理集合中kobject对象的热插拔操作的结构体
② kset是相同类型的kobjct的集合,比如"全部的块设备"就是一个kset
③ kset结构关心的是对象的集合,他与kobject的关系如下图所示,

3.3.4 共同特性的ktype

成员 | 含义 |
release | 析构函数 |
sysfs_ops | 对属性进行操作的读写函数(show和store函数) |
default_attrs | 描述给定对象的特征 |
kobject是一个抽象而基本的对象,对于一组具有共同特性的kobject,使用ktype来描述
3.3.5 实例:kobject & kset实验
从/sys目录的构成可知整个sysfs文件系统盘根错节,此处补充一个向系统添加kobject & kset对象的实验,帮助理解该过程(但不会过分深入细节)
① 向内核添加一个kobject对象后,底层代码会自动在/sys目录中生成一个子目录(父目录可以在代码中指定)
② kobject可以附加一些属性,并绑定操着这些属性的方法。当向内核成功添加一个kobjec对象后,其附加的属性会被底层的代码自动实现为对象对应目录下的文件,用户访问这些文件最终转换为调用操作属性的方法来访问其属性
③ 通过sysfs的API接口,可以将两个kobject对象关联起来,形成软连接(在sysfs文件系统中软连接大量存在)
④ 除了kobject,还有kset类,他是多个kobject对象的集合,即多个kobject对象可以通过一个kset集合在一起
kset自身内嵌了一个kobject,可以作为集合中kobject对象的父对象,从而在kobject之间形成父子关系,这种父子关系在/sys目录中体现为父目录和子目录的关系。而属于同一集合的kobject对象形成兄弟关系,在/sys目录中体现为同级目录
#include <linux/module.h>
#include <linux/kernel.h>
#include <linux/init.h>
#include <linux/slab.h>
#include <linux/kobject.h>
static struct kset *kset;
static struct kobject *kobj1;
static struct kobject *kobj2;
static int val;
static ssize_t val_show(struct kobject *kobj,
struct kobj_attribute *attr, char *buf)
{
return snprintf(buf, PAGE_SIZE, "%d\n", val);
}
static ssize_t val_store(struct kobject *kobj, struct kobj_attribute *attr,
const char *buf, size_t count)
{
char *endp = NULL;
printk("size = %d\n", count);
val = simple_strtol(buf, &endp, 10);
return count;
}
// kobj_attribute继承了attribute结构
// 在Linux 4.x代码中属性权限为0644可以,改为0666编译会不通过,更加安全
static struct kobj_attribute kobj1_val_attr = __ATTR(val, 0644,
val_show, val_store);
static struct attribute *kobj1_attrs[] = {
&kobj1_val_attr.attr,
NULL,
};
static struct attribute_group kobj1_attr_group = {
.attrs = kobj1_attrs,
};
static int __init kobject_test_init(void)
{
int ret = 0;
// 在/sys目录下添加kset对象,会新增/sys/kset目录
kset = kset_create_and_add("kset", NULL, NULL);
// 在kset对象下新增kobj1 & kobj2对象
// 会新增/sys/kset/kobj1 & /sys/kset/kobj2目录
kobj1 = kobject_create_and_add("kobj1", &kset->kobj);
kobj2 = kobject_create_and_add("kobj2", &kset->kobj);
// 给kobj1创建属性文件
// 会增加/sys/kset/kobj1/val文件
ret = sysfs_create_group(kobj1, &kobj1_attr_group);
// 在/sys/kobj2目录下建立kobj1的软链接
ret = sysfs_create_link(kobj2, kobj1, "kobj1");
return 0;
}
static void __exit kobject_test_exit(void)
{
sysfs_remove_link(kobj2, "kobj1");
sysfs_remove_group(kobj1, &kobj1_attr_group);
kobject_del(kobj2);
kobject_del(kobj1);
kset_unregister(kset);
}说明:代码中使用的函数原型如下,从中可以体会其面向对象的设计思想
/*
* name: kset的名字,设置到kset内嵌kobject的name字段
* uevent_ops: kset uvent操作集
* parent_kobj: 父对象指针,设置到kset内嵌kobject的parent字段
* 设置为NULL时,在/sys目录下建立对象
*/
struct kset *kset_create_and_add(const char *name,
const struct kset_uevent_ops *uevent_ops,
struct kobject *parent_kobj);
/*
* name: kobject的名字
* parent: 父对象指针
*/
struct kobject *kobject_create_and_add(const char *name,
struct kobject *parent);
/*
* kobj: 要创建属性的kobject对象指针
* grp: 属性数组结构
*/
int sysfs_create_group(struct kobject *kobj,
const struct attribute_group *grp);
② 在Ubuntu 16.04中,切换到root用户可以实现对属性文件的写操作(使用sudo都不行)
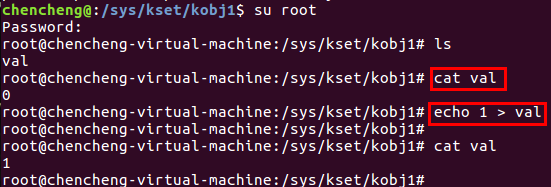
4. platform平台总线驱动模型
4.1 概述

① 为了解决驱动代码和设备的信息耦合问题,Linux提出了platform bus(平台总线)的概念,即使用虚拟总线将设备信息和驱动程序分离
② platform平台总线是一条虚拟总线,其中platform_device为相应的设备,platform_driver为相应的驱动,平台总线会维护两条链表,分别管理设备和驱动
其实这个是bus / device / device_driver框架就提供的功能,在bus中分别维护device和device_driver
③ 平台总线负责将设备信息和驱动代码匹配。当一个设备被注册到总线时,总线会根据其名字搜索对应的驱动,如果找到就将设备信息导入驱动程序并执行驱动
④ 平台总线驱动模型基于bus / device / device_driver机制实现,与其相比,platform由内核进行统一管理,在驱动中使用资源,提高了代码的安全性和可移植性
说明:将驱动代码和设备信息解耦之后,驱动代码就实现了跨平台特性
4.2 platform_bus结构

platfomr总线是bus_type的一个实例,其中最重要的就是platform_match函数,该函数用于实现platform_driver和platform_device的匹配
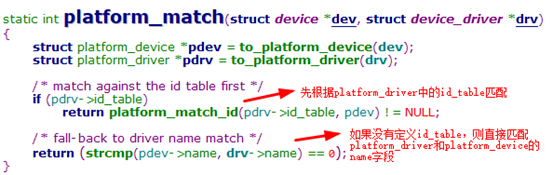
说明1:platform_bus_type中并没有定义bus级别的probe函数,这点在下文分析probe过程时会用到
说明2:platform_bus_type总线由系统定义,后续使用中,只要在驱动中定义并注册platform_driver结构;在BSP或dts中定义platform_device结构即可
4.3 platform_driver结构
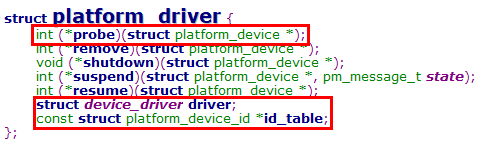
① platform_driver结构继承了device_driver结构
② id_table定义了platform_driver支持的设备名称,供platform_match函数实现匹配

③ probe函数是驱动match成功后运行的第一个函数,一般在该函数中实现驱动的初始化操作
说明:platform_driver_register函数分析

如果platform_driver中定义了probe等函数,会将其设置到device_driver的hook点,因为最终的match & probe是在bus / device / device_driver机制中完成的
注意:此处设置到driver中的probe函数为platform_drv_probe,并不是platform_driver中定义的probe函数,因为这2个probe函数的类型是不同的
设置的platform_drv_probe函数是调用platform_driver中probe函数的跳板
4.4 platform_device结构

① platform_device结构继承了device结构
② num_resources & resource字段描述了设备持有的资源
以X210 SPI master为例,说明platform_device的定义方式,

说明:目前Linux内核代码已使用设备树描述设备信息,但设备树的引入并未改变总线设备驱动模型,只是更换了描述方式
4.5 平台总线match流程
注意:match机制是bus / device / device_driver框架提供的
match流程的核心函数为driver_match_device,如果bus中定义了match函数,将在此处被调用

之所以注册设备 & 注册驱动均能触发match函数的调用,就要看该函数的调用关系了
platform_device_add
--> device_add // 可见实际提供功能的是bus / device / device_driver框架
--> bus_probe_device
--> device_attach
--> __device_attach
--> driver_match_device // match流程
--> driver_probe_device // probe流程说明:device_attach函数会搜索bus的klist_drivers链表,在逐个驱动上调用match函数
platform_driver_register
--> driver_register // 可见实际提供功能的是bus / device / device_driver框架
--> bus_add_driver
--> driver_attach
--> __driver_attach
--> driver_match_device // match流程
--> driver_probe_device // probe流程说明:driver_attach函数会搜索bus的klist_devices链表,在逐个设备上调用match函数
4.6 平台总线probe流程
注意:probe机制也是bus / device / device_driver框架提供的
如上文所述,在__device_attach & __driver_attach函数中,一旦mach成功,就会调用driver_probe_device函数进行probe
driver_probe_device
--> really_probe
可见probe函数的调用顺序,优先调用bus的probe函数,之后才是device_driver的probe函数
在平台设备中,bus层面没有设置probe函数,所以只能调用device_driver中设置的probe函数,也就是platform_drv_probe函数

可见该函数最终完成了对platform_driver函数中probe函数的调用,也就是驱动程序自己定义的probe函数
4.7 各级设备的展开
4.7.1 SoC总线层级视图

内核启动时,会逐层展开地去寻找设备,SoC的总线层级视图结构如下,
① SoC内部包含CPU和各种控制器,比如A、B、I2C和SPI,内核通过platform虚拟总线连接各个控制器
② IP外设有具体的总线,如I2C总线、SPI总线,对应的I2C设备和SPI设备就挂载在各自的总线上
4.7.2 展开platform设备
通过调用platform_add_devices函数注册一组已定义的platform_device结构体


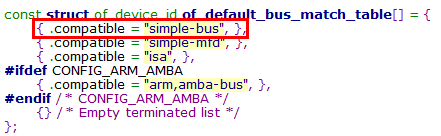
各个controller的设备信息,被组织在"simple-bus"总线上

在Linux启动过程中,会调用of_platform_default_populate函数,遍历simple-bus下的所有节点,并创建platform_device(drivers/of/platform.c)

of_platform_default_populate
--> of_platform_populate
--> of_platform_bus_create
--> of_platform_device_create_pdata // 分配并注册platform_device结构4.7.3 展开各controller设备
各级controller设备的展开,都是在controller driver的probe函数中,通过调用相关总线core层提供的函数实现的,这就体现了逐层展开的含义
定义i2c_board_info结构,之后调用i2c_register_board_info函数将其注册为i2c_devinfo结构,并加入__i2c_board_list链表(drivers/i2c/i2c-boardinfo.c)



在I2C controller的设备信息中,增加子节点描述I2C设备信息,表示定义的I2C设备由该I2C controller控制
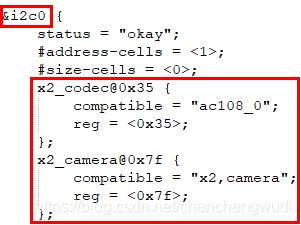
最终由i2c_scan_static_board_info函数遍历__i2c_board_list链表,并注册I2C设备

// I2C controller driver probe函数调用
i2c_add_adapter / i2c_add_numbered_adapter
--> i2c_register_adapter
--> i2c_scan_static_board_info // 遍历__i2c_board_list
--> i2c_new_device // 分配并注册i2c_client设备i2c_add_adapter
--> i2c_register_adapter
--> of_i2c_register_devices // 遍历i2c设备节点信息
--> of_i2c_register_device // 分配并注册i2c_client设备定义spi_board_info结构,之后调用spi_register_board_info函数将其注册为board_info结构,并加入board_list链表(drivers/spi/spi.c)

![]()
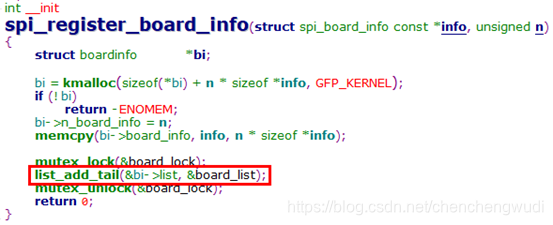
I2C按channel定义info数组;SPI只定义一个数组,在info中指定channel
在SPI controller的设备信息中,增加子节点描述I2C设备信息,表示定义的I2C设备由该I2C controller控制

最终由scan_boardinfo函数遍历board_list链表,并注册SPI设备,此处也是只注册当前channel的SPI设备

spi_register_master // SPI controller driver probe函数调用
--> scan_boardinfo // 遍历board_list链表
--> spi_new_device // 分配并注册spi_device结构spi_register_master
--> of_register_spi_devices // 遍历spi设备节点信息
--> of_register_spi_device // 分配并注册spi_device结构5. 字符设备驱动程序
5.1 字符设备的描述

成员 | 含义 |
kobj | 内嵌的内核对象 |
owner | 该字符设备所在的内核模块指针,一般设置为THIS_MODULE |
ops | 字符设备文件操作集 |
list | 注册字符设备时加入相应链表 |
dev | 设备号(由主次设备号构成) |
count | 属于同一主设备号的次设备号个数 |
说明:cdev结构与file_operations结构的关系

5.2 字符设备驱动框架

③ 通过file_operations类型的文件操作集,定义字符设备提供给VFS的接口函数
5.3 字符设备驱动编写步骤

5.3.1 alloc_chrdev_region
alloc_chrdev_region函数用于动态申请设备号,这也是申请设备号的推荐方式,可避免设备号冲突

5.3.2 cdev_init
cdev_init函数初始化cdev成员,并建立cdev和file_operations之间的关联

5.3.3 cdev_add

6. 块设备驱动程序简介
6.1 概述
块设备驱动程序提供了面向块的设备的访问,这种设备以随机访问的方式传输数据,并且数据总是具有固定大小的块
② 数据经过块设备相比操作字符设备需要多经过一个数据缓冲层(buffer cache)机制

6.2 块设备驱动模型
6.2.1 块设备使用方式

6.2.2 块设备驱动分层

① VFS是对各种具体文件系统的一种封装,是用户程序访问文件的统一接口
② 在VFS层之上的文件操作系统调用(e.g. open / close / read / write),会在VFS层被指引到相应设备设置的文件操作函数
当用户发起文件访问请求时,首先会到磁盘缓存中查找文件是否被缓存了,如果在缓存,则直接从缓存中读取;如果数据不在缓存中,就必须要到具体的文件系统中读取数据
② 映射层确定要访问文件所在文件系统的块的大小(block size),并根据文件块的大小计算所请求数据的长度。本质上,文件被拆分成很多块,因此内核需要确定请求数据所在的块
③ 映射层调用一个具体的文件系统的函数来访问文件的inode结构,然后根据逻辑块号确定所请求数据在磁盘上的位置
① 内核利用通用块层启动IO操作,传达所请求的数据。通常一个IO操作只针对磁盘上一组连续的块
② 内核将块设备看作是由若干个扇区组成的数据空间,上层的读写请求在通用块层被构造成一个或多个bio结构
① IO调度层根据预先定义的策略将待处理的IO进行重排和合并,目的是提高磁盘操作效率
② IO调度的总体目标是希望让磁头能够总是向一个方向移动,移动到底了再往反方向走,这恰好是现实生活中的电梯模型,所以IO调度也被叫做电梯(elevator)调度,而相应的算法就被叫做电梯算法
③ IO调度支持如下算法,Linux内核默认使用CFQ IO调度算法


/sys/block/DEVICE_NAME/queue/scheduler节点

② 向磁盘控制器硬件接口(也就是控制器寄存器)发送适当的指令,进行实际的数据操作
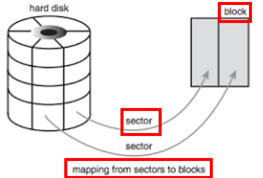
文件系统的读写单位是块(block),一个块的大小是2的n次方个扇区,比如1KB / 2KB / 4KB / 4MB等,如ext4文件系统的默认块大小为4KB

扇区(sector)是磁盘上的最小操作单位,一般一个扇区为512B。如果实际的设备扇区不是512B(比如SSD的扇区为4KB),那么只需将多个内核扇区对应一个设备扇区即可
6.3 块设备驱动核心数据结构
6.3.1 核心数据结构概述


block_device数据结构用来抽象和描述一个块设备,将VFS和块设备子系统关联起来

gendisk是磁盘类设备的一个抽象,可以表示一个已分区或未分区的磁盘
说明3:block_device_operations数据结构

block_device_operations是块设备的操作方法集,可见比字符设备操作集少很多函数。其中没有read / write接口,这是因为块设备已经使用请求队列来完成读写操作
① request_queue数据结构用来抽象和描述请求队列
② 当文件系统这样的高层代码有新的请求,就会加入到请求队列中。只要请求队列不为空,队列中对应的处理函数就会从请求队列中获取request,然后送到对应的块设备驱动中
6.3.2 核心数据结构关系

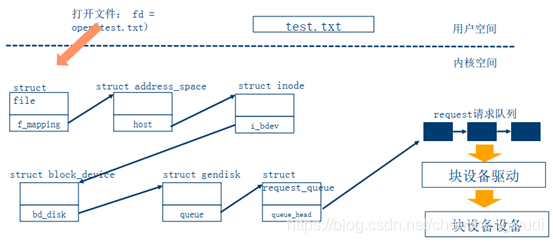
7. 实例:实现一个简单的块设备驱动
7.1 分配内存模拟磁盘
static int diskmb = 256;
static int disk_size;
static int __init my_init(void)
{
// ramdisk大小为256MB
disk_size = diskmb * 1024 * 1024;
// 为ramdisk分配内存空间
ramdisk = vmalloc(disk_size);
if (!ramdisk)
return -ENOMEM;
}7.2 注册请求队列
static spinlock_t lock;
static struct request_queue *my_request_queue;
static unsigned short sector_size = 512; // 扇区大小
// 处理请求队列中的请求
static void my_request(struct request_queue *q)
{
struct request *rq;
int size, res = 0;
char *ptr;
unsigned nr_sectors, sector;
pr_info("start handle request\n");
// 从请求队列中获取一个请求
rq = blk_fetch_request(q);
while (rq) {
// 获取该请求需要的sector个数
nr_sectors = blk_rq_cur_sectors(rq);
// 获取该请求相对于块设备的offset
sector = blk_rq_pos(rq);
// 计算出请求的内存地址与大小
ptr = ramdisk + sector * sector_size;
size = nr_sectors * sector_size;
// 判断请求的合法性
if ((ptr + size) > (ramdisk + disk_size)) {
pr_err("end of device\n");
goto done;
}
// 请求分为读写2个方向(direction)
// 处理写请求
if (rq_data_dir(rq)) {
pr_info("writing at sector %d, %u sectors\n",
sector, nr_sectors);
memcpy(ptr, bio_data(rq->bio), size);
// 处理读请求
} else {
pr_info("reading at sector %d, %u sectors\n",
sector, nr_sectors);
memcpy(bio_data(rq->bio), ptr, size);
}
done:
if (!__blk_end_request_cur(rq, res))
rq = blk_fetch_request(q);
}
pr_info("handle request done\n");
}
static int __init my_init(void)
{
// 为ramdisk创建请求队列
spin_lock_init(&lock);
my_request_queue = blk_init_queue(my_request, &lock);
if (!my_request_queue) {
vfree(ramdisk);
return -ENOMEM;
}
// 设置request_queue的逻辑块(logic block)大小,此处设置为1个扇区
blk_queue_logical_block_size(my_request_queue, sector_size);
}struct request_queue
{
// 其他成员
request_fn_proc *request_fn; // 请求处理函数
spinlock_t *queue_lock; // 保护请求队列的自旋锁
};这2个成员均在调用blk_init_queue函数时传递,用于初始化struct request_queue结构
7.3 注册块设备
#define MY_DEVICE_NAME "myramdisk"
static int mybdrv_ma_no; // 块设备主设备号
static int __init my_init(voud)
{
// 注册块设备
// 第1个参数为0,即由系统分配主设备号
mybdrv_ma_no = register_blkdev(0, MY_DEVICE_NAME);
if (mybdrv_ma_no < 0) {
pr_err("Failed registering mybdrv, returned %d\n",
mybdrv_ma_no);
vfree(ramdisk);
return mybdrv_ma_no;
}
}7.4 注册gendisk结构
static struct gendisk *my_gd;
static int __init my_init(void)
{
// 分配generic disk描述符
// 此处16指定的是与该磁盘关联的次设备号范围
my_gd = alloc_disk(16);
if (!my_gd) {
unregister_blkdev(mybdrv_ma_no, MY_DEVICE_NAME);
vfree(ramdisk);
return -ENOMEM;
}
my_gd->major = mybdrv_ma_no; // 设置主设备号,也就关联了block_device结构
my_gd->first_minor = 0; // 设置首个次设备号
my_gd->fops = &mybdrv_fops; // 设置操作集
strcpy(my_gd->disk_name, MY_DEVICE_NAME);
my_gd->queue = my_request_queue; // 关联请求队列
// 设置磁盘容量,以扇区为单位
set_capacity(my_gd, disk_size / sector_size);
add_disk(my_gd); // add partitioning information to kernel list
}7.5 块设备操作集
static int my_ioctl(struct block_device *bdev, fmode_t mode,
unsigned int cmd, unsigned long arg)
{
long size;
struct hd_geometry geo;
pr_info("cmd=%d\n", cmd);
switch (cmd) {
// 获取块设备参数
case HDIO_GETGEO:
pr_info("HIT HDIO_GETGEO\n");
/*
* get geometry: we have to fake one...
*/
size = disk_size;
size &= ~0x3f;
geo.cylinders = size>>6;
geo.heads = 2;
geo.sectors = 16;
geo.start = 4;
if (copy_to_user((void __user *)arg, &geo, sizeof(geo)))
return -EFAULT;
return 0;
}
pr_warn("return -ENOTTY\n");
return -ENOTTY;
}
static const struct block_device_operations mybdrv_fops = {
.owner = THIS_MODULE,
.ioctl = my_ioctl,
};7.6 测试结果

在加载驱动后,生成块设备/dev/myramdisk,自动分配的主设备号为252。可见在初始化过程中就有读写请求



小结:根据块设备驱动分层,我们要实现的块设备驱动就是最底层的数据结构,VFS / 映射层 / 通用块层 / IO调度层均已由Linux内核实现
所以在实现中仅涉及block_device / gendisk / request_queue / block_device_operations这4个结构的实现,而gendisk结构将这些数据结构串联起来