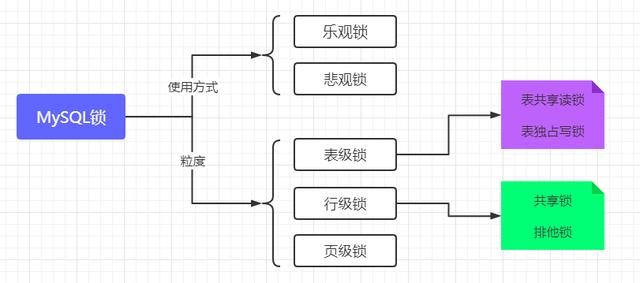
先上一张图,MySQL锁分类:
MySQL锁
学习数据库锁的目的
在我们平时的开发中也很少考虑锁的问题,这是因为数据库隐式帮我们添加了锁:
- 对于UPDATE、DELETE、INSERT语句,InnoDB会自动将涉及的数据集添加排他锁(X锁)
- 事务拿到某一行记录的共享锁(S锁),才可以读取这一行,并阻止其他事务对其添加排他锁
- 事务拿到某一行记录的排他锁(X锁),才可以修改或者删除这一行
共享锁的目的是为了提高读读并发;排他锁的目的是为了保证数据的一致性。
我们在某些特定的场景下才需要手动进行加锁,学习数据库锁知识就是为了:
- 能更好地控制程序代码
- 能让我们在特定场景派上用场
- 构建自己的数据库知识体系
表锁详解
首先,从锁的粒度进行划分,数据库锁可分为两大类:
- 表锁
① 开销小,加锁快
② 不会出现死锁
③ 锁粒度大,发生冲突的概率高,并发度低
- 行锁
① 开销大,加锁慢
② 会出现死锁
③ 锁粒度小,发生冲突的概率低,并发度高
【注】:不同的存储引擎支持的所粒度是不一样的:InnoDB存储引擎表锁和行锁都支持;MyISAM只支持表锁。InnoDB存储引擎只有通过索引条件检索数据才使用行级锁,否则,InnoDB将使用表级锁;也就是说,InnoDB的行锁是基于索引的。
表锁又分为:表读锁 & 表写锁。在表读锁和表写锁的情况下:读读不阻塞,读写阻塞,写写阻塞!
- 读读不阻塞:一个事务读取数据,其他事务也在读数据,不会加锁
- 读写阻塞:一个事务在读数据,其他事务不能修改正在读取的数据,会加锁
- 写写阻塞:一个事务在修改数据,其他事务不能修改正在修改的数据,会加锁
行锁详解
我们使用MySQL一般使用的都是InnoDB存储引擎,InnoDB存储引擎和MyISAM存储引擎有两个本质的区别:
- InnoDB存储引擎支持行锁
- InnoDB存储引擎支持事务
InnoDB存储引擎实现了以下两种类型的行锁:
- 共享锁(S锁):也称为读锁,多个客户可以同时读取同一个资源,但不允许其他客户修改;
- 排他锁(X锁):也称为写锁,会阻塞其他的写锁和读锁;
乐观锁和悲观锁
- 悲观锁:在数据处理过程,使数据处于锁定状态,通过数据库锁机制实现;数据库层面加锁,都会阻塞去等待锁。
select ... for update 是MySQL提供的实现悲观锁的方式。- 乐观锁:认为数据一般情况下不会发生冲突,所以在数据进行提交更新时,才对数据的冲突与否进行检测。
数据库中实现乐观锁的方式是MVCC。通过版本号version机制实现:一般通过为数据库表增加一个version字段,当读取数据时,将version字段的值一同读出,数据每更新一次,对version值+1,当我们提交更新时,判断数据库表对应记录的当前版本信息与第一次取出来的version值进行比较,如果数据库表当前版本号与第一次取出的version相等,更新操作。也可以通过时间戳进行实现。
间隙锁(Gap Lock)
当范围检索数据时,InnoDB会给符合范围条件的已有数据记录的索引项进行加锁;对于键值在条件范围内但并不存在的记录,称之为“间隙”。InnoDB也会对间隙进行加锁,这种锁机制称之为“间隙锁”。
【注】:间隙锁只会在REPEATABLE READ隔离级别下使用。
举个例子:假设员工表emp_table中有100条记录,其中emp_id=1,2,...,100
SELECT * FROM emp_table WHERE emp_id >= 100 for update;这是一个范围查询,InnoDB不仅会对符合条件的emp_id值为100的记录进行加锁,也会对emp_id大于等于101的间隙加锁。
InnoDB存储引擎使用间隙锁的目的:
- 为了防止幻读
- 满足恢复和复制的需要
MySQL的恢复机制要求:在一个事务尚未提交前,其他事务不能插入满足其锁定条件的记录,也就是不允许出现幻读。