目录
算法
771. 宝石与石头
给定字符串J 代表石头中宝石的类型,和字符串 S代表你拥有的石头。 S 中每个字符代表了一种你拥有的石头的类型,你想知道你拥有的石头中有多少是宝石。
J 中的字母不重复,J 和 S中的所有字符都是字母。字母区分大小写,因此"a"和"A"是不同类型的石头。
纪念第一次下手,使用的是C,用时4ms。
int numJewelsInStones(char* J, char* S) {
int jewels = 0;
char *p=S;
while(*J){
S=p;
while(*S){
if (*J == *S)jewels++;
S++;
}
J++;
}
return jewels;
}思路:
- char* J, char* S两个是指向字符串首地址的指针
- 循环条件为* J,* S,一次循环指针则往后移动一个字符的位置,直到* J,* S=0
929. 独特的电子邮件地址
每封电子邮件都由一个本地名称和一个域名组成,以 @ 符号分隔。
例如,在 alice@leetcode.com中, alice 是本地名称,而 leetcode.com 是域名。
除了小写字母,这些电子邮件还可能包含 ',' 或 '+'。
如果在电子邮件地址的本地名称部分中的某些字符之间添加句点('.'),则发往那里的邮件将会转发到本地名称中没有点的同一地址。例如,"alice.z@leetcode.com” 和 “alicez@leetcode.com” 会转发到同一电子邮件地址。 (请注意,此规则不适用于域名。)
如果在本地名称中添加加号('+'),则会忽略第一个加号后面的所有内容。这允许过滤某些电子邮件,例如 m.y+name@email.com 将转发到 my@email.com。 (同样,此规则不适用于域名。)
可以同时使用这两个规则。
给定电子邮件列表 emails,我们会向列表中的每个地址发送一封电子邮件。实际收到邮件的不同地址有多少?
示例:
输入:["test.email+alex@leetcode.com","test.e.mail+bob.cathy@leetcode.com","testemail+david@lee.tcode.com"]
输出:2
解释:实际收到邮件的是 "testemail@leetcode.com" 和 "testemail@lee.tcode.com"。java:
public static int numUniqueEmails(String[] emails) {
HashSet<Object> set = new HashSet<>();
for (String email : emails) {
String local = email.substring(0,email.indexOf("@"));
String domain = email.substring(email.indexOf("@"));
String realLocal = local.substring(0,local.indexOf("+")).replace(".", "");
set.add(realLocal + domain);
}
return set.size();
}python:
class Solution:
def numUniqueEmails(self, emails):
"""
:type emails: List[str]
:rtype: int
"""
email_set = set()
for email in emails:
name, domain = email.split('@')
email = name[:name.find('+')].replace('.', '')+domain
email_set.add(email)
return len(email_set)思路:
- 首先找到"@"位置,并截取0到"@"的字符串local
- "@"到末尾的字符串保存在domain
- 对local进行操作,截取0到"+"的字符串并把字符串中的"."替换成""
- 利用set不能存储相同的元素,来得出实际邮件地址数目
905. 按奇偶排序数组
给定一个非负整数数组 A,返回一个由 A 的所有偶数元素组成的数组,后面跟 A 的所有奇数元素。
你可以返回满足此条件的任何数组作为答案。
示例:
输入:[3,1,2,4]
输出:[2,4,3,1]
输出 [4,2,3,1],[2,4,1,3] 和 [4,2,1,3] 也会被接受。
class Solution {
public int[] sortArrayByParity(int[] A) {
int len = A.length;
int ne[] = new int[len];
int s = 0;
int e = len - 1;
for (int i = 0; i < len; i++) {
if (A[i]%2 == 0) {
ne[s++] = A[i];
}else {
ne[e--] = A[i];
}
}
return ne;
}
}思路:
- 创建新一个数组,大小等于原数组A,把每次循环得到的偶数从前往后排,奇数则从后往前排
804. 唯一摩尔斯密码词
国际摩尔斯密码定义一种标准编码方式,将每个字母对应于一个由一系列点和短线组成的字符串, 比如: "a" 对应 ".-", "b" 对应 "-...", "c" 对应 "-.-.", 等等。
为了方便,所有26个英文字母对应摩尔斯密码表如下:
[".-","-...","-.-.","-..",".","..-.","--.","....","..",".---","-.-",".-..","--","-.","---",".--.","--.-",".-.","...","-","..-","...-",".--","-..-","-.--","--.."]给定一个单词列表,每个单词可以写成每个字母对应摩尔斯密码的组合。例如,"cab" 可以写成 "-.-..--...",(即 "-.-." + "-..." + ".-"字符串的结合)。我们将这样一个连接过程称作单词翻译。
返回我们可以获得所有词不同单词翻译的数量。
例如:
输入: words = ["gin", "zen", "gig", "msg"]
输出: 2
解释:
各单词翻译如下:
"gin" -> "--...-."
"zen" -> "--...-."
"gig" -> "--...--."
"msg" -> "--...--."
共有 2 种不同翻译, "--...-." 和 "--...--.".
class Solution {
public int uniqueMorseRepresentations(String[] words) {
int len = words.length;
String[] codes = {".-","-...","-.-.","-..",".","..-.","--.","....","..",".---","-.-",".-..","--","-.","---",".--.","--.-",".-.","...","-","..-","...-",".--","-..-","-.--","--.."};
String codeswords;
HashSet<Object> set = new HashSet<>();
for (int i = 0; i < len; i++) {
codeswords = "";
char[] t = words[i].toCharArray();
for (int j = 0; j < t.length; j++) {
codeswords += codes[t[j] - 97];
}
set.add(codeswords);
}
return set.size();
}
}思路:
- 先把words的字先把words的每个字符串都转成字符数组
- 对字符数组进行-97操作,得到codes所对应的下标,再根据下标拼接字符串得到摩尔斯密码,摩尔斯密码保存在新字符串codeswords
- 将codeswords保存到set集合,利用set不能存储相同的元素,来得出实际邮件地址数目
922. 按奇偶排序数组 II
给定一个非负整数数组 A, A 中一半整数是奇数,一半整数是偶数。
对数组进行排序,以便当 A[i] 为奇数时,i 也是奇数;当 A[i] 为偶数时, i 也是偶数。
你可以返回任何满足上述条件的数组作为答案。
示例:
输入:[4,2,5,7]
输出:[4,5,2,7]
解释:[4,7,2,5],[2,5,4,7],[2,7,4,5] 也会被接受。
执行用时:5ms
class Solution {
public int[] sortArrayByParityII(int[] A) {
int j = 1;
for (int i = 0; i < A.length - 1; i = i + 2) {
if ((A[i] & 1) != 0) {
while ((A[j] & 1) != 0) {
j = j + 2;
}
int tmp = A[i];
A[i] = A[j];
A[j] = tmp;
}
}
return A;
}
}思路:
- 数组0,2,4,6 偶数,1,3,5,7奇数
- 遍历偶数下标的时候的时候每次循环i+2
- 当遇到存在偶数下标不对应偶数,则遍历奇数下标,一发现存在奇数下标不对应的奇数,马上交换
- 继续遍历偶数下标直至结束
807. 保持城市天际线
在二维数组grid中,grid[i][j]代表位于某处的建筑物的高度。 我们被允许增加任何数量(不同建筑物的数量可能不同)的建筑物的高度。 高度 0 也被认为是建筑物。
最后,从新数组的所有四个方向(即顶部,底部,左侧和右侧)观看的“天际线”必须与原始数组的天际线相同。 城市的天际线是从远处观看时,由所有建筑物形成的矩形的外部轮廓。 请看下面的例子。
建筑物高度可以增加的最大总和是多少?
例子:
输入: grid = [[3,0,8,4],[2,4,5,7],[9,2,6,3],[0,3,1,0]]
输出: 35
解释:
The grid is:
[ [3, 0, 8, 4],
[2, 4, 5, 7],
[9, 2, 6, 3],
[0, 3, 1, 0] ]
从数组竖直方向(即顶部,底部)看“天际线”是:[9, 4, 8, 7]
从水平水平方向(即左侧,右侧)看“天际线”是:[8, 7, 9, 3]
在不影响天际线的情况下对建筑物进行增高后,新数组如下:
gridNew = [ [8, 4, 8, 7],
[7, 4, 7, 7],
[9, 4, 8, 7],
[3, 3, 3, 3] ]
执行用时:12ms
class Solution {
public int maxIncreaseKeepingSkyline(int[][] grid) {
int len = grid.length;
int[] vArray = new int[len];//垂直
int[] lArray = new int[len];//水平
// int[][] newgrid = new int[len][len];
int n = 0;
for (int i = 0; i < len; i++) {
for (int j = 0; j < len; j++) {
if (vArray[i] < grid[j][i]) {
vArray[i] = grid[j][i];
}
if (lArray[i] < grid[i][j]) {
lArray[i] = grid[i][j];
}
}
}
for (int i = 0; i < len; i++) {
for (int j = 0; j < len; j++) {
if (vArray[j] < lArray[i]) {
n = n + vArray[j] - grid[i][j];
// newgrid[i][j] = vArray[j];
}else {
n = n + lArray[i] - grid[i][j];
// newgrid[i][j] = lArray[i];
}
}
}
// for (int i = 0; i < len; i++) {
// System.out.println(vArray[i]+"-"+lArray[i]);
// }
// for (int i = 0; i < newgrid.length; i++) {
// for (int j = 0; j < newgrid.length; j++) {
// System.out.print(newgrid[i][j]);
// }
// }
return n;
}
}思路:
- 找出每行,每列的最大值
- 与之前的grid相减得出增加量
给定二叉搜索树的根结点 root,返回 L 和 R(含)之间的所有结点的值的和。
二叉搜索树保证具有唯一的值。
938. 二叉搜索树的范围和
示例 1:
输入:root = [10,5,15,3,7,null,18], L = 7, R = 15
输出:32
示例 2:
输入:root = [10,5,15,3,7,13,18,1,null,6], L = 6, R = 10
输出:23
复习一下什么是二叉搜索树:
二叉搜索树的性质
1,任意节点x,其左子树中的key不大于x.key,其右子树中的key不小于x.key。
2,不同的二叉搜索树可以代表同一组值的集合。
3,二叉搜索树的基本操作和树的高度成正比,所以如果是一棵完全二叉树的话最坏运行时间为Θ(lgn),但是若是一个n个节点连接成的线性树,那么最坏运行时间是Θ(n)。
4,根节点是唯一一个parent指针指向NIL节点的节点。
5,每一个节点至少包括key、left、right与parent四个属性,构建二叉搜索树时,必须存在针对key的比较算法。
下面给出一张wiki百科上的二叉搜索树的图示:
实例1的二叉搜索树:

/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public int rangeSumBST(TreeNode root, int L, int R) {
if (root == null) {
return 0;
}
if (root.val > R) {
return rangeSumBST(root.left, L, R);
}else if (root.val < L){
return rangeSumBST(root.right, L, R);
}else {
return root.val + rangeSumBST(root.left, L, R) + rangeSumBST(root.right, L, R);
}
}
}思路:
- 利用递归
- root.val > R时遍历左子节点,root.val < L时遍历右子节点,否则累加直至root=null返回0回到上一级递归
114. 二叉树展开为链表
给定一个二叉树,原地将它展开为链表。
例如,给定二叉树
1
/ \
2 5
/ \ \
3 4 6将其展开为:
1
\
2
\
3
\
4
\
5
\
6执行用时 : 2 ms
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public void flatten(TreeNode root) {
if(root==null) return;
flatten(root.left);
flatten(root.right);
//左右子树皆已转换成链表
TreeNode temp = root.right;
root.right = root.left;
root.left = null;
while(root.right!=null){
root = root.right;
}
root.right = temp;
}
}思路:
- 先执行flatten(root.left);不断遍历到最左子节点
- 然后flatten(root.right);遍历右子节点
- 左子节点替换右子节点,并将左子节点置空
- TreeNode temp = root.right;
- root.right = root.left;
- root.left = null;
1029. 可被 5 整除的二进制前缀
给定由若干 0 和 1 组成的数组 A。我们定义 N_i:从 A[0] 到 A[i] 的第 i 个子数组被解释为一个二进制数(从最高有效位到最低有效位)。
返回布尔值列表 answer,只有当 N_i 可以被 5 整除时,答案 answer[i] 为 true,否则为 false。
示例 1:
输入:[0,1,1]
输出:[true,false,false]
解释:
输入数字为 0, 01, 011;也就是十进制中的 0, 1, 3 。只有第一个数可以被 5 整除,因此 answer[0] 为真。
示例 2:
输入:[1,1,1]
输出:[false,false,false]
示例 3:
输入:[0,1,1,1,1,1]
输出:[true,false,false,false,true,false]
示例 4:
输入:[1,1,1,0,1]
输出:[false,false,false,false,false]
提示:
1 <= A.length <= 30000A[i]为0或1
执行用时:8 ms
class Solution {
public List<Boolean> prefixesDivBy5(int[] A) {
List<Boolean> b = new ArrayList<Boolean>();
int temp = 0;
int len = A.length;
for (int i = 0; i < len; i++) {
if (A[i]==1) {
temp = (temp*2+1)%5;
}else {
temp = (temp*2)%5;
}
if (temp%5==0) {
b.add(true);
}else {
b.add(false);
}
}
return b;
}
}思路:
- 这题是简单题,但要考虑的地方比较细
- 若一开始未想到整型精度问题则会在纠结在int、double、String之间的类型转换
- 经测试,当数据足够多时,双精度double对5取余也会出错
- 最终我放弃大数取余再转型,而是直接在二进制转十进制时就对每位二进制数的十进制数取余
- (temp*2+1)%5
- (temp*2)%5
- 这样最终得到的temp是一个小于5的余数,不用再考虑复杂的精度问题
350. 两个数组的交集 II
给定两个数组,编写一个函数来计算它们的交集。
示例 1:
输入: nums1 = [1,2,2,1], nums2 = [2,2]
输出: [2,2]
示例 2:
输入: nums1 = [4,9,5], nums2 = [9,4,9,8,4]
输出: [4,9]说明:
- 输出结果中每个元素出现的次数,应与元素在两个数组中出现的次数一致。
- 我们可以不考虑输出结果的顺序。
执行用时 : 88 ms
class Solution:
def intersect(self, nums1: List[int], nums2: List[int]) -> List[int]:
inter = set(nums1) & set(nums2) # set类型{},与dict相似,但不存储value且key不重复,&按位与运算符得出相同部分
l = []
for i in inter:
l += [i] * min(nums1.count(i), nums2.count(i)) # 重复数字出现的最小次数
return l- 用set不能存储重复
- 判断两个列表是否存在相同元素可以使用位运算符&
1029. 两地调度
公司计划面试 2N 人。第 i 人飞往 A 市的费用为 costs[i][0],飞往 B 市的费用为 costs[i][1]。
返回将每个人都飞到某座城市的最低费用,要求每个城市都有 N 人抵达。
示例:
输入:[[10,20],[30,200],[400,50],[30,20]]
输出:110
解释:
第一个人去 A 市,费用为 10。
第二个人去 A 市,费用为 30。
第三个人去 B 市,费用为 50。
第四个人去 B 市,费用为 20。
最低总费用为 10 + 30 + 50 + 20 = 110,每个城市都有一半的人在面试。
提示:
1 <= costs.length <= 100costs.length为偶数1 <= costs[i][0], costs[i][1] <= 1000
执行用时:92 ms
class Solution(object):
def twoCitySchedCost(self, costs):
"""
:type costs: List[List[int]]
:rtype: int
"""
diff = list(map(lambda x: x[1] - x[0], costs)) # 对每个costs[n]进行costs[n][1]-costs[n][0],返回一个list,去A地的钱减去去B地的钱的差价
ans = sum(map(lambda x: x[0], costs)) # 求和costs[n]的costs[n][0],都去A地总共花的钱
diff.sort() # 对差价排序,排越前的去B地更加划算
n = len(diff) // 2 # 取一半人去B地
for i in range(n):
ans += diff[i]
print(diff[i])
return ans思路:
- diff = list(map(lambda x: x[1] - x[0], costs)) # 对每个costs[n]进行costs[n][1]-costs[n][0],返回一个list,去A地的钱减去去B地的钱的差价
- ans = sum(map(lambda x: x[0], costs)) # 求和costs[n]的costs[n][0],都去A地总共花的钱
- diff.sort() # 对差价排序,排越前的去B地更加划算
- n = len(diff) // 2 # 取一半人去B地
122. 买卖股票的最佳时机 II
给定一个数组,它的第 i 个元素是一支给定股票第 i 天的价格。
设计一个算法来计算你所能获取的最大利润。你可以尽可能地完成更多的交易(多次买卖一支股票)。
注意:你不能同时参与多笔交易(你必须在再次购买前出售掉之前的股票)。
示例 1:
输入: [7,1,5,3,6,4]
输出: 7
解释: 在第 2 天(股票价格 = 1)的时候买入,在第 3 天(股票价格 = 5)的时候卖出, 这笔交易所能获得利润 = 5-1 = 4 。
随后,在第 4 天(股票价格 = 3)的时候买入,在第 5 天(股票价格 = 6)的时候卖出, 这笔交易所能获得利润 = 6-3 = 3 。
执行用时 :44 ms, 在所有Python3提交中击败了99.11%的用户
内存消耗 :13.9 MB, 在所有Python3提交中击败了70.74%的用户
class Solution:
def maxProfit(self, prices: List[int]) -> int:
profit = 0
for i in range(1,len(prices)):
if prices[i] > prices[i-1]:
profit += (prices[i] - prices[i-1])
return profit思路:
- 交易不能交叉进行
- [a,b,c,d],假设a<=b<=c<=d,则最大收益为d-a,但巧妙的是d-a=(d-c)+(c-b)+(b-a),这样又像是第一天买入,第二天卖出再买入...直到第四天卖出,其实收益相等
- 在保证局部最优的情况下也保证全局最优
53. 最大子序和
给定一个整数数组 nums ,找到一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。
示例:
输入: [-2,1,-3,4,-1,2,1,-5,4],
输出: 6
解释: 连续子数组 [4,-1,2,1] 的和最大,为 6。执行用时 :48 ms, 在所有Python3提交中击败了99.35%的用户
内存消耗 :13.5 MB, 在所有Python3提交中击败了88.85%的用户
class Solution:
def maxSubArray(self, nums: List[int]) -> int:
if nums is None or len(nums) == 0:
return 0
preSum = nums[0]
maxSum = preSum
for i in range(1, len(nums)):
preSum = preSum + nums[i] if preSum > 0 else nums[i]
maxSum = max(preSum, maxSum)
return maxSum
思路
- 暴力法,从头遍历,只有当preSum>0时,才考虑与后面元素相加再进行比较
- 否则,直接与后面元素比较,因为举例[-2,1],-2<1,而且-2+1<1,这样直接取1作为max即可,不需要考虑比较-2与1相加的结果
121. 买卖股票的最佳时机
给定一个数组,它的第 i 个元素是一支给定股票第 i 天的价格。
如果你最多只允许完成一笔交易(即买入和卖出一支股票),设计一个算法来计算你所能获取的最大利润。
注意你不能在买入股票前卖出股票。
示例 1:
输入: [7,1,5,3,6,4]
输出: 5
解释: 在第 2 天(股票价格 = 1)的时候买入,在第 5 天(股票价格 = 6)的时候卖出,最大利润 = 6-1 = 5 。
注意利润不能是 7-1 = 6, 因为卖出价格需要大于买入价格。执行用时 :56 ms, 在所有Python3提交中击败了94.79%的用户
内存消耗 :13.8 MB, 在所有Python3提交中击败了93.25%的用户
class Solution:
def maxProfit(self, prices: List[int]) -> int:
if prices is None or len(prices) == 0:
return 0
minPrice = prices[0]
maxPofi = 0
for i in range(len(prices)):
if minPrice > prices[i]:
minPrice = prices[i]
else:
# 比较maxPofi和prices[i] - min
maxPofi = max(maxPofi, prices[i] - minPrice)
return maxPofi思路:
- 按题意只能进行一次交易,因此只需要找出股票价格最小值minPrice买入,收益最大值maxPofi卖出即可
69. x 的平方根
实现 int sqrt(int x) 函数。
计算并返回 x 的平方根,其中 x 是非负整数。
由于返回类型是整数,结果只保留整数的部分,小数部分将被舍去。
示例 1:
输入: 4
输出: 2示例 2:
输入: 8
输出: 2
说明: 8 的平方根是 2.82842...,
由于返回类型是整数,小数部分将被舍去。执行用时 :6 ms, 在所有Java提交中击败了87.68%的用户
内存消耗 :33.8 MB, 在所有Java提交中击败了75.02%的用户
class Solution {
public int mySqrt(int x) {
if (x <= 1) {
return x;
}
int l = 1, h = x;
while (l <= h) {
int mid = l + (h - l) / 2;
int sqrt = x / mid;
if (sqrt == mid) {
return mid;
} else if (sqrt < mid) {
h = mid - 1;
} else {
l = mid + 1;
}
}
return h;
}
}思路:
- 采用二分法
- mid = l + (h - l) / 2为二分法中值位置
- 不断更新l,h,逐渐逼近sqrt,最后h<l,取h值
744. 寻找比目标字母大的最小字母
给定一个只包含小写字母的有序数组letters 和一个目标字母 target,寻找有序数组里面比目标字母大的最小字母。
数组里字母的顺序是循环的。举个例子,如果目标字母target = 'z' 并且有序数组为 letters = ['a', 'b'],则答案返回 'a'。
示例:
输入:
letters = ["c", "f", "j"]
target = "a"
输出: "c"
输入:
letters = ["c", "f", "j"]
target = "c"
输出: "f"执行用时 :1 ms, 在所有Java提交中击败了99.38%的用户
内存消耗 :42.7 MB, 在所有Java提交中击败了75.99%的用户
class Solution {
public char nextGreatestLetter(char[] letters, char target) {
int n = letters.length;
int l = 0, h = n - 1;
while (l <= h) {
int t = l + (h - l) / 2;
if (letters[t] > target) {
h = t - 1;
} else {
l = t + 1;
}
}
return l < n ? letters[l] : letters[0];
}
}思路:
- 采用二分法
- 循环条件为l<=h,不能为l<h,否则当target大于或等于数组最后一个字母时,l=h=n-1,则在return代码那一行无法判断第n-1个字母是否为target
- 当中间值大于target,h取中间值前一个
- 当中间值小于或等于target,l取中间值后一个,若中间值为target,则l=中间值+1就是最终结果
540. 有序数组中的单一元素
给定一个只包含整数的有序数组,每个元素都会出现两次,唯有一个数只会出现一次,找出这个数。
示例 1:
输入: [1,1,2,3,3,4,4,8,8]
输出: 2
示例 2:
输入: [3,3,7,7,10,11,11]
输出: 10执行用时 :0 ms, 在所有Java提交中击败了100.00%的用户
内存消耗 :40.4 MB, 在所有Java提交中击败了5.34%的用户
class Solution {
public int singleNonDuplicate(int[] nums) {
int n = nums.length;
if (n <= 0) {
return -1;
}
int l = 0, h = n - 1;
while (l < h) {
int m = l + (h - l) / 2;
if (m % 2 == 1) {
m--;
}
if (nums[m] == nums[m + 1]) {
l=m+2;
}else {
h=m;
}
}
return nums[h];
}
}思路:
- 采用二分法,假设所找元素位置为index(index位置一定是奇数)
- 令中间值m始终为偶数,则存在m+1<index时,nums[m] == nums[m + 1];m+1>=index时,nums[m] != nums[m + 1]
- 那么也就是说可以由已知的判断条件推出index,若nums[m] == nums[m + 1],则index范围变为[m + 2,h],因此令l=m+2
- 若nums[m] != nums[m + 1],则index范围变为[l,m],因此令h=m
- 最终在l=h时退出循环
278. 第一个错误的版本
你是产品经理,目前正在带领一个团队开发新的产品。不幸的是,你的产品的最新版本没有通过质量检测。由于每个版本都是基于之前的版本开发的,所以错误的版本之后的所有版本都是错的。
假设你有 n 个版本 [1, 2, ..., n],你想找出导致之后所有版本出错的第一个错误的版本。
你可以通过调用 bool isBadVersion(version) 接口来判断版本号 version 是否在单元测试中出错。实现一个函数来查找第一个错误的版本。你应该尽量减少对调用 API 的次数。
示例:
给定 n = 5,并且 version = 4 是第一个错误的版本。
调用 isBadVersion(3) -> false
调用 isBadVersion(5) -> true
调用 isBadVersion(4) -> true
所以,4 是第一个错误的版本。 执行用时 :15 ms, 在所有Java提交中击败了99.75%的用户
内存消耗 :31.8 MB, 在所有Java提交中击败了99.69%的用户
/* The isBadVersion API is defined in the parent class VersionControl.
boolean isBadVersion(int version); */
public class Solution extends VersionControl {
public int firstBadVersion(int n) {
int l = 1, h = n;
while (l < h) {
int t = l + (h - l) / 2;
if (isBadVersion(t)) {
h = t;
} else {
l = t + 1;
}
}
return l;
}
}思路:
- 采用二分法
- 若发现版本出错去缩小范围为[l,t],未出错则缩小范围为[t+1,h]
- h=t的原因是结果我们需要取得出错的第一个版本,若h=t-1则可能会把第一个错的版本给排出去,不利于后面的判断
- 而l=t+1不会有排除所需要的值
153. 寻找旋转排序数组中的最小值
假设按照升序排序的数组在预先未知的某个点上进行了旋转。
( 例如,数组 [0,1,2,4,5,6,7] 可能变为 [4,5,6,7,0,1,2] )。
请找出其中最小的元素。
你可以假设数组中不存在重复元素。
示例 1:
输入: [3,4,5,1,2]
输出: 1示例 2:
输入: [4,5,6,7,0,1,2]
输出: 0执行用时 :1 ms, 在所有Java提交中击败了97.99%的用户
内存消耗 :35.5 MB, 在所有Java提交中击败了41.97%的用户
class Solution {
public int findMin(int[] nums) {
int n = nums.length;
int l = 0, h = n - 1;
while(l<h) {
int m = l+(h-l)/2;
if (nums[h]<nums[m]) {
l=m+1;
}else {
h=m;
}
}
return nums[h];
}
}思路:
- 采用二分法
- 循环条件nums[h]<nums[m]不能换为nums[l]<nums[m],如0,1,2,3时l会一直加到最后而取不到0
- 最终h=l退出循环
34. 在排序数组中查找元素的第一个和最后一个位置
给定一个按照升序排列的整数数组 nums,和一个目标值 target。找出给定目标值在数组中的开始位置和结束位置。
你的算法时间复杂度必须是 O(log n) 级别。
如果数组中不存在目标值,返回 [-1, -1]。
示例 1:
输入: nums = [5,7,7,8,8,10], target = 8
输出: [3,4]示例 2:
输入: nums = [5,7,7,8,8,10], target = 6
输出: [-1,-1]执行用时 :6 ms, 在所有Java提交中击败了22.55%的用户
内存消耗 :40.8 MB, 在所有Java提交中击败了87.69%的用户
class Solution {
public static int[] searchRange(int[] nums, int target) {
int first = binarySearch(nums, target);
int last = binarySearch(nums, target + 1) - 1;
System.out.println(first);
System.out.println(last);
if (first == nums.length || nums[first] != target) {
return new int[] { -1, -1 };
} else {
return new int[] { first, first < last ? last : first };
}
}
public static int binarySearch(int[] nums, int target) {
int l = 0, h = nums.length;
while (l < h) {
int m = l + (h - l) / 2;
if (nums[m] < target) {
l = m + 1;
} else {
h = m;
}
}
return l;
}
}思路:
- 采用二分法
- 二分法函数的h初始值是nums.length
- first代表所找元素的第一个位置
- last为所找元素的最后一个位置(通过找到“目标元素+1”元素的第一个位置-1得到)
- 当target不存在,而target+1存在时,last<first,所以需要比较first和last
241. 为运算表达式设计优先级
给定一个含有数字和运算符的字符串,为表达式添加括号,改变其运算优先级以求出不同的结果。你需要给出所有可能的组合的结果。有效的运算符号包含 +, - 以及 * 。
示例 1:
输入:"2-1-1"输出:[0, 2]解释: ((2-1)-1) = 0 (2-(1-1)) = 2
执行用时 :9 ms, 在所有 Java 提交中击败了50.00%的用户
内存消耗 :36.4 MB, 在所有 Java 提交中击败了57.25%的用户
class Solution {
public List<Integer> diffWaysToCompute(String input) {
// 分治法,碰到运算符号,递归求解前一半的值和后一半的值,然后根据运算符号,计算两者构成的值
List<Integer> ways = new ArrayList<>();
for (int i = 0; i < input.length(); i++) {
char c = input.charAt(i);
if (c == '+' || c == '-' || c == '*') {// 出现运算符号,递归求解前半段和后半段
List<Integer> left = diffWaysToCompute(input.substring(0, i));
List<Integer> right = diffWaysToCompute(input.substring(i + 1));
for (int l : left) {
for (int r : right) {
switch (c) {
case '+':
ways.add(l + r);
break;
case '-':
ways.add(l - r);
break;
case '*':
ways.add(l * r);
break;
}
}
}
}
}
if (ways.size() == 0) {//纯数字,input中没符号
ways.add(Integer.valueOf(input));
}
return ways;
}
}思路:
- 递归回溯。可以产生所有的组合方式。
- 每个小组合方式相当于一个子集,不断的将计算结果返回给上一层
- 举例:
a + (b - (c * d))会不断的变成a + (b - (left* right))->a + (left- right)->left+ right - 似乎计算结果不需要
for循环?其实有这种情况,a + (b - (c * d))和a + (b - c) * d)),这里a + right,right就可能有多种情况
- 举例:
279. 完全平方数
给定正整数 n,找到若干个完全平方数(比如 1, 4, 9, 16, ...)使得它们的和等于 n。你需要让组成和的完全平方数的个数最少。
示例 1:
输入: n =12输出: 3 解释:12 = 4 + 4 + 4.
示例 2:
输入: n =13输出: 2 解释:13 = 4 + 9.
√ Accepted
√ 588/588 cases passed (60 ms)
√ Your runtime beats 36.96 % of java submissions
√ Your memory usage beats 17.28 % of java submissions (46.9 MB)class Solution {
public int numSquares(int n) {
List<Integer> squares = generateSquares(n);
Queue<Integer> queue = new LinkedList<>();
boolean[] marked = new boolean[n + 1];
queue.add(n);
marked[n] = true;
int level = 0;
while (!queue.isEmpty()) {
int size = queue.size();
level++;
while (size-- > 0) {
int cur = queue.poll();
for (int s : squares) {
int next = cur - s;
if (next < 0) {
break;
}
if (next == 0) {
return level;
}
if (marked[next]) {
continue;
}
marked[next] = true;
queue.add(next);
}
}
}
return n;
}
//生成小于n的平方数序列
private List<Integer> generateSquares(int n) {
List<Integer> squares = new ArrayList<>();
int square = 1;
int diff = 3;
while (square <= n) {
squares.add(square);
square += diff;
diff += 2;
}
return squares;
}
}思路:
- 将整数与其生成小于n的平方数序列相减直至找出相减为0时,此时level为最少个数
- 否则平方数全为1
127. 单词接龙
给定两个单词(beginWord 和 endWord)和一个字典,找到从 beginWord 到 endWord 的最短转换序列的长度。转换需遵循如下规则:
- 每次转换只能改变一个字母。
- 转换过程中的中间单词必须是字典中的单词。
说明:
- 如果不存在这样的转换序列,返回 0。
- 所有单词具有相同的长度。
- 所有单词只由小写字母组成。
- 字典中不存在重复的单词。
- 你可以假设 beginWord 和 endWord 是非空的,且二者不相同。
示例 1:
输入:
beginWord = "hit",
endWord = "cog",
wordList = ["hot","dot","dog","lot","log","cog"]
输出: 5
解释: 一个最短转换序列是 "hit" -> "hot" -> "dot" -> "dog" -> "cog",
返回它的长度 5。
示例 2:
输入:
beginWord = "hit"
endWord = "cog"
wordList = ["hot","dot","dog","lot","log"]
输出: 0
解释: endWord "cog" 不在字典中,所以无法进行转换。√ Accepted
√ 40/40 cases passed (190 ms)
√ Your runtime beats 57.67 % of java submissions
√ Your memory usage beats 36.67 % of java submissions (54.3 MB)class Solution {
public int ladderLength(String beginWord, String endWord, List<String> wordList) {
// 所有单词长度相等
int L = beginWord.length();
// 字典中的词可以通过改变一个字母得以延续
HashMap<String, ArrayList<String>> allComboDict = new HashMap<String, ArrayList<String>>();
wordList.forEach(word -> {
for (int i = 0; i < L; i++) {
// 键是通用状态,值是所有具有通用状态的单词
String newWord = word.substring(0, i) + '*' + word.substring(i + 1, L);
ArrayList<String> transformations = allComboDict.getOrDefault(newWord, new ArrayList<String>());
transformations.add(word);
allComboDict.put(newWord, transformations);
}
});
// Queue for 广度优先搜索
Queue<Pair<String, Integer>> Q = new LinkedList<Pair<String, Integer>>();
Q.add(new Pair(beginWord, 1));
// 标记已访问过的词
HashMap<String, Boolean> visited = new HashMap<String, Boolean>();
visited.put(beginWord, true);
while (!Q.isEmpty()) {
Pair<String, Integer> node = Q.remove();
String word = node.getKey();
int level = node.getValue();
for (int i = 0; i < L; i++) {
// 找到 current_word 的所有通用状态
String newWord = word.substring(0, i) + '*' + word.substring(i + 1, L);
// 检查这些通用状态是否存在其它单词的映射
for (String adjacentWord : allComboDict.getOrDefault(newWord, new ArrayList<String>())) {
// adjacentWord等于endWord时返回
if (adjacentWord.equals(endWord)) {
return level + 1;
}
// 否则把它添加到BFS Queue. 并标记已访问
if (!visited.containsKey(adjacentWord)) {
visited.put(adjacentWord, true);
Q.add(new Pair(adjacentWord, level + 1));
}
}
}
}
return 0;
}
}思路:
拥有一个 beginWord 和一个 endWord,分别表示图上的 start node 和 end node。我们希望利用一些中间节点(单词)从 start node 到 end node,中间节点是 wordList给定的单词。我们对这个单词接龙每个步骤的唯一条件是相邻单词只可以改变一个字母。
我们将问题抽象在一个无向无权图中,每个单词作为节点,差距只有一个字母的两个单词之间连一条边。问题变成找到从起点到终点的最短路径,如果存在的话。因此可以使用广度优先搜索方法。
算法中最重要的步骤是找出相邻的节点,也就是只差一个字母的两个单词。为了快速的找到这些相邻节点,我们对给定的 wordList 做一个预处理,将单词中的某个字母用 * 代替。
这个预处理帮我们构造了一个单词变换的通用状态。例如:Dog ----> D*g <---- Dig,Dog和 Dig 都指向了一个通用状态 D*g。
这步预处理找出了单词表中所有单词改变某个字母后的通用状态,并帮助我们更方便也更快的找到相邻节点。否则,对于每个单词我们需要遍历整个字母表查看是否存在一个单词与它相差一个字母,这将花费很多时间。预处理操作在广度优先搜索之前高效的建立了邻接表。
例如,在广搜时我们需要访问 Dug 的所有邻接点,我们可以先生成 Dug 的所有通用状态:
Dug => *ugDug => D*gDug => Du*
第二个变换 D*g 可以同时映射到 Dog 或者 Dig,因为他们都有相同的通用状态。拥有相同的通用状态意味着两个单词只相差一个字母,他们的节点是相连的。
利用广度优先搜索搜索从 beginWord 到 endWord 的路径。
算法
对给定的
wordList做预处理,找出所有的通用状态。将通用状态记录在字典中,键是通用状态,值是所有具有通用状态的单词。将包含
beginWord和1的元组放入队列中,1代表节点的层次。我们需要返回endWord的层次也就是从beginWord出发的最短距离。为了防止出现环,使用访问数组记录。
当队列中有元素的时候,取出第一个元素,记为
current_word。找到
current_word的所有通用状态,并检查这些通用状态是否存在其它单词的映射,这一步通过检查all_combo_dict来实现。从
all_combo_dict获得的所有单词,都和current_word共有一个通用状态,所以都和current_word相连,因此将他们加入到队列中。对于新获得的所有单词,向队列中加入元素
(word, level + 1)其中level是current_word的层次。最终当你到达期望的单词,对应的层次就是最短变换序列的长度。
标准广度优先搜索的终止条件就是找到结束单词。
695. 岛屿的最大面积
给定一个包含了一些 0 和 1的非空二维数组 grid , 一个 岛屿 是由四个方向 (水平或垂直) 的 1 (代表土地) 构成的组合。你可以假设二维矩阵的四个边缘都被水包围着。
找到给定的二维数组中最大的岛屿面积。(如果没有岛屿,则返回面积为0。)
示例 1:
[[0,0,1,0,0,0,0,1,0,0,0,0,0],
[0,0,0,0,0,0,0,1,1,1,0,0,0],
[0,1,1,0,1,0,0,0,0,0,0,0,0],
[0,1,0,0,1,1,0,0,1,0,1,0,0],
[0,1,0,0,1,1,0,0,1,1,1,0,0],
[0,0,0,0,0,0,0,0,0,0,1,0,0],
[0,0,0,0,0,0,0,1,1,1,0,0,0],
[0,0,0,0,0,0,0,1,1,0,0,0,0]]
对于上面这个给定矩阵应返回 6。注意答案不应该是11,因为岛屿只能包含水平或垂直的四个方向的‘1’。
示例 2:
[[0,0,0,0,0,0,0,0]]对于上面这个给定的矩阵, 返回 0。
注意: 给定的矩阵grid 的长度和宽度都不超过 50。
√ Accepted
√ 726/726 cases passed (9 ms)
√ Your runtime beats 45.1 % of java submissions
√ Your memory usage beats 69.15 % of java submissions (46.6 MB)class Solution {
private int m, n;
private int[][] direction = { { 0, 1 }, { 0, -1 }, { 1, 0 }, { -1, 0 } };
public int maxAreaOfIsland(int[][] grid) {
if (grid == null || grid.length == 0) {
return 0;
}
m = grid.length;
n = grid[0].length;
int maxArea = 0;
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
maxArea = Math.max(maxArea, dfs(grid, i, j));// 找出最大面积
}
}
return maxArea;
}
private int dfs(int[][] grid, int r, int c) {
if (r < 0 || r >= m || c < 0 || c >= n || grid[r][c] == 0) {
return 0;
}
grid[r][c] = 0;// 已访问的标记为0
int area = 1;
for (int[] d : direction) {
area += dfs(grid, r + d[0], c + d[1]);// 遍历direction上下左右访问
}
return area;
}
}思路:
- 使用DFS,以direction为遍历方向不断访问上下左右的点
- 已访问标记为0
- 使用递归得出岛屿面积,找出最大的面积
200. 岛屿数量
给定一个由 '1'(陆地)和 '0'(水)组成的的二维网格,计算岛屿的数量。一个岛被水包围,并且它是通过水平方向或垂直方向上相邻的陆地连接而成的。你可以假设网格的四个边均被水包围。
示例 1:
输入:
11110
11010
11000
00000
输出: 1√ Accepted
√ 47/47 cases passed (4 ms)
√ Your runtime beats 65.96 % of java submissions
√ Your memory usage beats 47.05 % of java submissions (42.8 MB)class Solution {
private int m, n;
private int[][] direction = {{0, 1}, {0, -1}, {1, 0}, {-1, 0}};
public int numIslands(char[][] grid) {
if (grid == null || grid.length == 0) {
return 0;
}
m = grid.length;
n = grid[0].length;
int islandsNum = 0;
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
if (grid[i][j] != '0') {
dfs(grid, i, j);
islandsNum++;//岛屿+1
}
}
}
return islandsNum;
}
private void dfs(char[][] grid, int i, int j) {
if (i < 0 || i >= m || j < 0 || j >= n || grid[i][j] == '0') {
return;
}
grid[i][j] = '0';// 已访问的标记为0
for (int[] d : direction) {
dfs(grid, i + d[0], j + d[1]);// 遍历direction上下左右访问
}
}
}思路:
- 使用DFS,以direction为遍历方向不断访问上下左右的点
- 使用递归得出每一个岛屿覆盖范围且把已访问标记为0
547. 朋友圈
班上有 N 名学生。其中有些人是朋友,有些则不是。他们的友谊具有是传递性。如果已知 A 是 B 的朋友,B 是 C 的朋友,那么我们可以认为 A 也是 C 的朋友。所谓的朋友圈,是指所有朋友的集合。
给定一个 N * N 的矩阵 M,表示班级中学生之间的朋友关系。如果M[i][j] = 1,表示已知第 i 个和 j 个学生互为朋友关系,否则为不知道。你必须输出所有学生中的已知的朋友圈总数。
示例 1:
输入:
[[1,1,0],
[1,1,0],
[0,0,1]]
输出: 2
说明:已知学生0和学生1互为朋友,他们在一个朋友圈。
第2个学生自己在一个朋友圈。所以返回2。√ Accepted
√ 113/113 cases passed (3 ms)
√ Your runtime beats 91.39 % of java submissions
√ Your memory usage beats 46.28 % of java submissions (51.2 MB)class Solution {
private int n;
public int findCircleNum(int[][] M) {
n = M.length;
int circleNum = 0;
boolean[] hasVisited = new boolean[n];// 初始化已访问
for (int i = 0; i < n; i++) {// 遍历每一个学生的朋友圈
if (!hasVisited[i]) {// 若未访问过该学生
dfs(M, i, hasVisited);
circleNum++;
}
}
return circleNum;
}
private void dfs(int[][] M, int i, boolean[] hasVisited) {
hasVisited[i] = true;// 标记学生已访问
for (int k = 0; k < n; k++) {
if (M[i][k] == 1 && !hasVisited[k]) {// 若该学生的朋友未访问,继续访问该朋友
dfs(M, k, hasVisited);
}
}
}
}思路:
- 使用DFS,遍历每一个学生的朋友圈,直到朋友圈里的学生都被访问过
130. 被围绕的区域
给定一个二维的矩阵,包含 'X' 和 'O'(字母 O)。
找到所有被 'X' 围绕的区域,并将这些区域里所有的 'O' 用 'X' 填充。
示例:
X X X X
X O O X
X X O X
X O X X
运行你的函数后,矩阵变为:
X X X X
X X X X
X X X X
X O X X
解释:
被围绕的区间不会存在于边界上,换句话说,任何边界上的 'O' 都不会被填充为 'X'。 任何不在边界上,或不与边界上的 'O' 相连的 'O' 最终都会被填充为 'X'。如果两个元素在水平或垂直方向相邻,则称它们是“相连”的。
√ Accepted
√ 59/59 cases passed (4 ms)
√ Your runtime beats 76.43 % of java submissions
√ Your memory usage beats 45.88 % of java submissions (49.4 MB)class Solution {
private int[][] direction = { { 0, 1 }, { 0, -1 }, { 1, 0 }, { -1, 0 } };
private int m, n;
public void solve(char[][] board) {
if (board == null || board.length == 0) {
return;
}
m = board.length;
n = board[0].length;
// 先填充最外侧,剩下的就是里侧了
for (int i = 0; i < m; i++) {
dfs(board, i, 0);// 第一列
dfs(board, i, n - 1);// 最后一列
}
for (int i = 0; i < n; i++) {
dfs(board, 0, i);// 第一行
dfs(board, m - 1, i);// 最后一行
}
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
if (board[i][j] == 'T') {
board[i][j] = 'O';
} else if (board[i][j] == 'O') {
board[i][j] = 'X';
}
}
}
}
private void dfs(char[][] board, int r, int c) {
if (r < 0 || r >= m || c < 0 || c >= n || board[r][c] != 'O') {
return;
}
board[r][c] = 'T';// 从外侧填充到内侧
for (int[] d : direction) {
dfs(board, r + d[0], c + d[1]);
}
}
}思路:
- 测试值:
[
["X","X","X","X"],
["X","O","O","X"],
["X","X","O","X"],
["X","O","X","X"]] - 把边界上的O或与边界上的O相连的O换成T
两次for循环后:
[
["X","X","X","X"],
["X","O","O","X"],
["X","X","O","X"],
["X","T","X","X"]]
再把T换成O,O换成X,即可得出结果
417. 太平洋大西洋水流问题
给定一个 m x n 的非负整数矩阵来表示一片大陆上各个单元格的高度。“太平洋”处于大陆的左边界和上边界,而“大西洋”处于大陆的右边界和下边界。
规定水流只能按照上、下、左、右四个方向流动,且只能从高到低或者在同等高度上流动。
请找出那些水流既可以流动到“太平洋”,又能流动到“大西洋”的陆地单元的坐标。
提示:
- 输出坐标的顺序不重要
- m 和 n 都小于150
示例:
给定下面的 5x5 矩阵:
太平洋 ~ ~ ~ ~ ~
~ 1 2 2 3 (5) *
~ 3 2 3 (4) (4) *
~ 2 4 (5) 3 1 *
~ (6) (7) 1 4 5 *
~ (5) 1 1 2 4 *
* * * * * 大西洋
返回:
[[0, 4], [1, 3], [1, 4], [2, 2], [3, 0], [3, 1], [4, 0]] (上图中带括号的单元).√ Accepted
√ 113/113 cases passed (14 ms)
√ Your runtime beats 24.09 % of java submissions
√ Your memory usage beats 56.9 % of java submissions (51.7 MB)class Solution {
private int m, n;
private int[][] matrix;
private int[][] direction = { { 0, 1 }, { 0, -1 }, { 1, 0 }, { -1, 0 } };
public List<List<Integer>> pacificAtlantic(int[][] matrix) {
// 找单元大于其这一列且其这一行上、下、左、右任意一个方向的点
List<List<Integer>> ret = new ArrayList<>();
if (matrix == null || matrix.length == 0) {
return ret;
}
m = matrix.length;
n = matrix[0].length;
this.matrix = matrix;// 赋值到全局matrix
boolean[][] canReachP = new boolean[m][n];
boolean[][] canReachA = new boolean[m][n];
// 先遍历最外侧
for (int i = 0; i < m; i++) {
dfs(i, 0, canReachP);
dfs(i, n - 1, canReachA);
}
for (int i = 0; i < n; i++) {
dfs(0, i, canReachP);
dfs(m - 1, i, canReachA);
}
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
if (canReachP[i][j] && canReachA[i][j]) {
ret.add(new ArrayList<>(Arrays.asList(i, j)));
}
}
}
return ret;
}
private void dfs(int r, int c, boolean[][] canReach) {
if (canReach[r][c]) {
return;
}
canReach[r][c] = true;
for (int[] d : direction) {// 从边缘部分往里面找大值
int nextR = d[0] + r;
int nextC = d[1] + c;
if (nextR < 0 || nextR >= m || nextC < 0 || nextC >= n || matrix[r][c] > matrix[nextR][nextC]) {
continue;
}
dfs(nextR, nextC, canReach);
}
}
}思路:
左边和上边是太平洋,右边和下边是大西洋,内部的数字代表海拔,海拔高的地方的水能够流到低的地方,求解水能够流到太平洋和大西洋的所有位置
从边缘网内部遍历,找出大值,最后判断canReachP[i][j] && canReachA[i][j]为true的为既可以流动到“太平洋”,又能流动到“大西洋”的陆地单元的坐标
17. 电话号码的字母组合
给定一个仅包含数字 2-9 的字符串,返回所有它能表示的字母组合。
给出数字到字母的映射如下(与电话按键相同)。注意 1 不对应任何字母。
示例:
输入:"23"
输出:["ad", "ae", "af", "bd", "be", "bf", "cd", "ce", "cf"].√ Accepted
√ 25/25 cases passed (2 ms)
√ Your runtime beats 71.9 % of java submissions
√ Your memory usage beats 73.14 % of java submissions (36.1 MB)class Solution {
private static final String[] KEYS = { "", "", "abc", "def", "ghi", "jkl", "mno", "pqrs", "tuv", "wxyz" };
public List<String> letterCombinations(String digits) {
List<String> combinations = new ArrayList<>();
if (digits == null || digits.length() == 0) {
return combinations;
}
doCombination(new StringBuilder(), combinations, digits);
return combinations;
}
private void doCombination(StringBuilder prefix, List<String> combinations, final String digits) {
if (prefix.length() == digits.length()) {
combinations.add(prefix.toString());
return;
}
int curDigits = digits.charAt(prefix.length()) - '0';//找出是第几个按键
String letters = KEYS[curDigits];
for (char c : letters.toCharArray()) {//遍历每个按键里的字母
prefix.append(c); // 添加
doCombination(prefix, combinations, digits);
prefix.deleteCharAt(prefix.length() - 1); // 删除
}
}
}
思路:
使用Backtracking(回溯)思路,不是立即返回,而是继续求解
首先判断出输入的按键
然后按照按键中的字母求解排列组合问题
93. 复原IP地址
给定一个只包含数字的字符串,复原它并返回所有可能的 IP 地址格式。
示例:
输入: "25525511135"
输出: ["255.255.11.135", "255.255.111.35"]√ Accepted
√ 147/147 cases passed (6 ms)
√ Your runtime beats 69.49 % of java submissions
√ Your memory usage beats 40.79 % of java submissions (37 MB)class Solution {
public List<String> restoreIpAddresses(String s) {
List<String> addresses = new ArrayList<>();
StringBuilder tempAddress = new StringBuilder();
doRestore(0, tempAddress, addresses, s);
return addresses;
}
private void doRestore(int k, StringBuilder tempAddress, List<String> addresses, String s) {
// k表示第几段ip 1.2.3.4
// 第四段||s为空
if (k == 4 || s.length() == 0) {
// 第四段&&s为空
if (k == 4 && s.length() == 0) {
// 添加到最终答案List上
addresses.add(tempAddress.toString());
}
return;
}
// 当s.length()已经小于2时,以i < s.length()为条件
for (int i = 0; i < s.length() && i <= 2; i++) {
// i
if (i != 0 && s.charAt(0) == '0') {
break;
}
String part = s.substring(0, i + 1);
// 一段part<=255
if (Integer.valueOf(part) <= 255) {
// 若已存在part,则拼接
if (tempAddress.length() != 0) {
part = "." + part;
}
tempAddress.append(part);
// 递归下一段
doRestore(k + 1, tempAddress, addresses, s.substring(i + 1));
// 回溯,移除最后一个点
tempAddress.delete(tempAddress.length() - part.length(), tempAddress.length());
}
}
}
}思路:
回溯(DFS)

79. 单词搜索
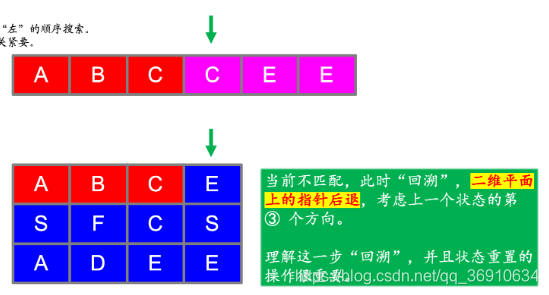
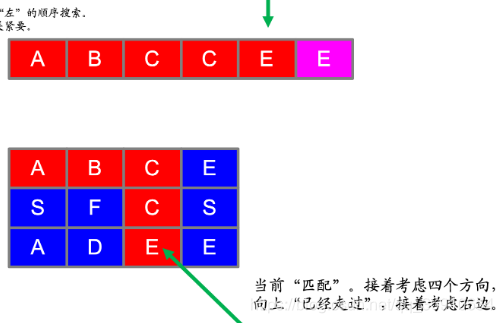
给定一个二维网格和一个单词,找出该单词是否存在于网格中。
单词必须按照字母顺序,通过相邻的单元格内的字母构成,其中“相邻”单元格是那些水平相邻或垂直相邻的单元格。同一个单元格内的字母不允许被重复使用。
示例:
board =
[
['A','B','C','E'],
['S','F','C','S'],
['A','D','E','E']
]
给定 word = "ABCCED", 返回 true.
给定 word = "SEE", 返回 true.
给定 word = "ABCB", 返回 false.执行用时 :13 ms, 在所有 Java 提交中击败了52.06%的用户
内存消耗 :50.9 MB, 在所有 Java 提交中击败了20.66%的用户
class Solution {
private final static int[][] direction = {{1, 0}, {-1, 0}, {0, 1}, {0, -1}};
private int m;
private int n;
public boolean exist(char[][] board, String word) {
if (word == null || word.length() == 0) {
return true;
}
if (board == null || board.length == 0 || board[0].length == 0) {
return false;
}
m = board.length;
n = board[0].length;
boolean[][] hasVisited = new boolean[m][n];
for (int r = 0; r < m; r++) {
for (int c = 0; c < n; c++) {
if (backtracking(0, r, c, hasVisited, board, word)) {
return true;
}
}
}
return false;
}
private boolean backtracking(int curLen, int r, int c, boolean[][] visited, final char[][] board, final String word) {
if (curLen == word.length()) {
return true;
}
if (r < 0 || r >= m || c < 0 || c >= n
|| board[r][c] != word.charAt(curLen) || visited[r][c]) {
return false;
}
visited[r][c] = true;
for (int[] d : direction) {
if (backtracking(curLen + 1, r + d[0], c + d[1], visited, board, word)) {
return true;
}
}
visited[r][c] = false;
return false;
}
}思路:


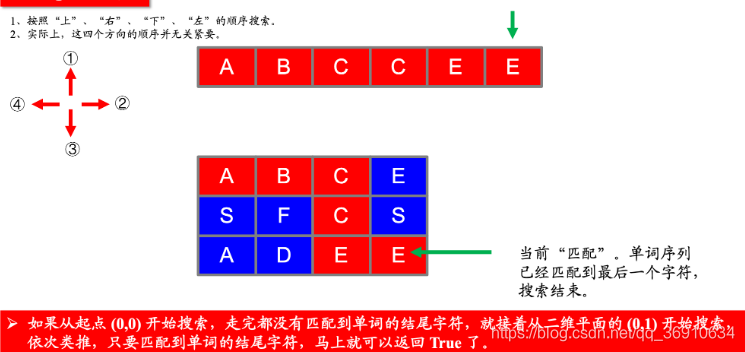
257. 二叉树的所有路径
给定一个二叉树,返回所有从根节点到叶子节点的路径。
说明: 叶子节点是指没有子节点的节点。
示例:
输入:
1
/ \
2 3
\
5
输出: ["1->2->5", "1->3"]
解释: 所有根节点到叶子节点的路径为: 1->2->5, 1->3执行用时 :4 ms, 在所有 Java 提交中击败了50.14%的用户
内存消耗 :36 MB, 在所有 Java 提交中击败了97.92%的用户
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public List<String> binaryTreePaths(TreeNode root) {
List<String> paths = new ArrayList<>();
if (root == null) {
return paths;
}
List<Integer> values = new ArrayList<>();
backtracking(root, values, paths);
return paths;
}
private void backtracking(TreeNode node, List<Integer> values, List<String> paths) {
if (node == null) {
return;
}
values.add(node.val);
if (isLeaf(node)) {
paths.add(buildPath(values));
} else {
backtracking(node.left, values, paths);
backtracking(node.right, values, paths);
}
values.remove(values.size() - 1);
}
//判断是否叶子节点
private boolean isLeaf(TreeNode node) {
return node.left == null && node.right == null;
}
private String buildPath(List<Integer> values) {
StringBuilder str = new StringBuilder();
for (int i = 0; i < values.size(); i++) {
str.append(values.get(i));
if (i != values.size() - 1) {
str.append("->");
}
}
return str.toString();
}
}思路:
- 回溯(DFS)
- values存储val,[1,2,5],[1,3],遍历左右节点直到叶子节点
- buildPath建立路径
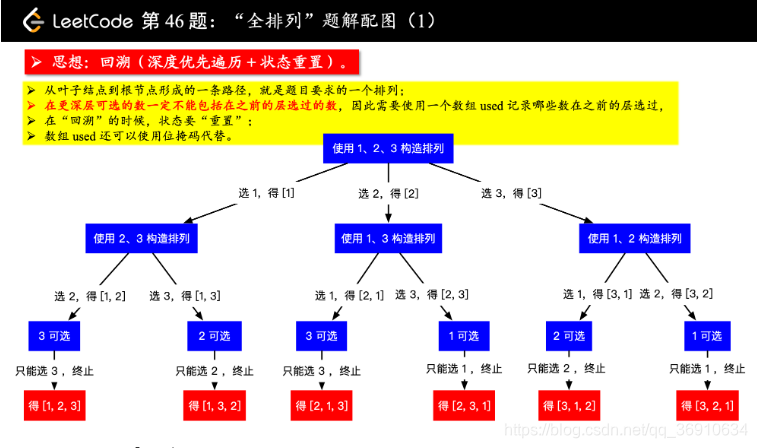
46. 全排列
给定一个没有重复数字的序列,返回其所有可能的全排列。
示例:
输入: [1,2,3]
输出:
[
[1,2,3],
[1,3,2],
[2,1,3],
[2,3,1],
[3,1,2],
[3,2,1]
]√ Accepted
√ 25/25 cases passed (4 ms)
√ Your runtime beats 70.58 % of java submissions
√ Your memory usage beats 64.64 % of java submissions (38.6 MB)class Solution {
public List<List<Integer>> permute(int[] nums) {
List<List<Integer>> permutes = new ArrayList<>();
List<Integer> permuteList = new ArrayList<>();
boolean[] hasVisited = new boolean[nums.length];//默认false
backtracking(permuteList, permutes, hasVisited, nums);
return permutes;
}
private void backtracking(List<Integer> permuteList, List<List<Integer>> permutes, boolean[] visited, final int[] nums) {
if (permuteList.size() == nums.length) {
permutes.add(new ArrayList<>(permuteList)); // 重新构造一个 List
return;
}
for (int i = 0; i < visited.length; i++) {
if (visited[i]) {
continue;
}
visited[i] = true;
permuteList.add(nums[i]);
//递归遍历num所有元素
backtracking(permuteList, permutes, visited, nums);
//去除最后一个
permuteList.remove(permuteList.size() - 1);
visited[i] = false;
}
}
}思路:
- 回溯(DFS)
- 递归遍历num中元素

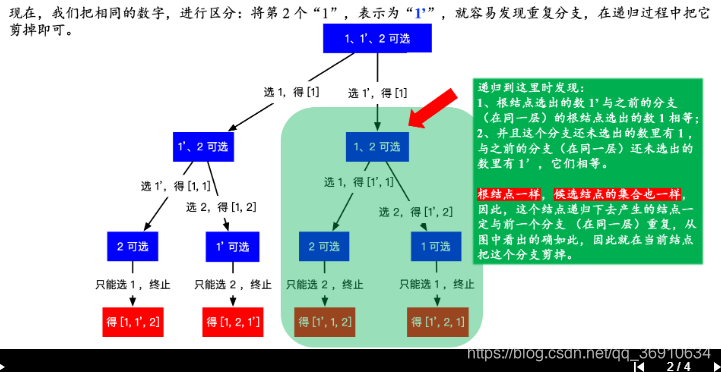
47. 全排列 II
给定一个可包含重复数字的序列,返回所有不重复的全排列。
示例:
输入: [1,1,2]
输出:
[
[1,1,2],
[1,2,1],
[2,1,1]
]执行用时:6 ms
class Solution {
public List<List<Integer>> permuteUnique(int[] nums) {
List<List<Integer>> permutes = new ArrayList<>();
List<Integer> permuteList = new ArrayList<>();
Arrays.sort(nums); // 排序
boolean[] hasVisited = new boolean[nums.length];
backtracking(permuteList, permutes, hasVisited, nums);
return permutes;
}
private void backtracking(List<Integer> permuteList, List<List<Integer>> permutes, boolean[] visited, final int[] nums) {
if (permuteList.size() == nums.length) {
permutes.add(new ArrayList<>(permuteList));
return;
}
for (int i = 0; i < visited.length; i++) {
if (i != 0 && nums[i] == nums[i - 1] && !visited[i - 1]) {
continue; // 防止重复
}
if (visited[i]){
continue;
}
visited[i] = true;
permuteList.add(nums[i]);
backtracking(permuteList, permutes, visited, nums);
permuteList.remove(permuteList.size() - 1);
visited[i] = false;
}
}
}思路: