Pytorch的猫狗识别代码——基于上一个手写汉字识别代码改写
前言
这篇关于猫狗识别的代码是基于上一篇的手写汉字识别代码改写的。
之前有尝试了PyTorch的入门教程实战这篇博文里提到的代码,就是陈云老师那个代码,然后学习了一遍,遇到的一些错误都整理在了Pytorch猫狗大战遇见的问题总结这篇博客里。但是这个代码的结果很奇怪,主要还残留了下面两个问题:
- 就是loss没有在visdom中显示出来,最终验证集验证的模型精度也没有显示,所以也不知道模型的好坏。
- 最终输出的result.csv文件中,狗的概率就没有大于0.5的,也就是预测结果都是猫,这就很迷了。
实际上作为小白的我,陈云老师的代码让我有点捉摸不透,所以就还是用我熟悉的手写汉字识别的代码框架吧,然后再结合陈云老师的代码的一些内容,来个移花接木吧!?
关于数据
数据集的分布是这样的:
我是直接将数据集test1文件夹和训练集train文件夹放在和代码文件code.py同级的目录下。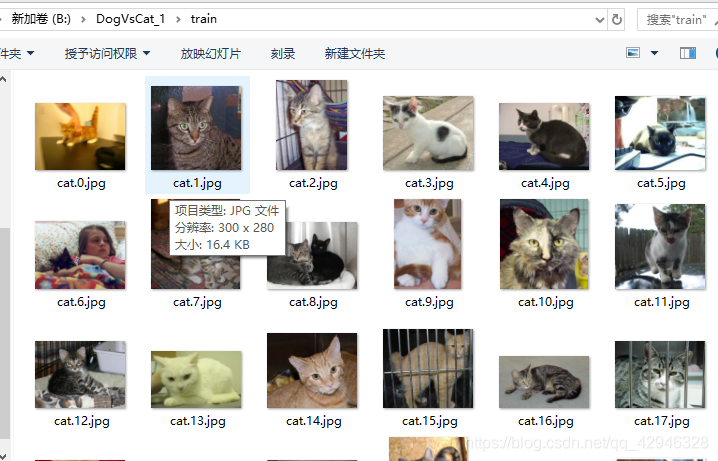
这是训练集的数据,一共有25000张图片。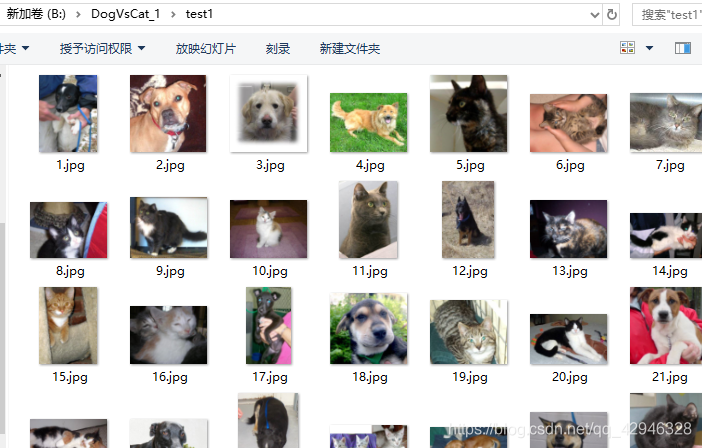
这是测试集的数据,一共有12500张图片。
1. 库的导入
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import DataLoader, Dataset
from torch.autograd import Variable
import argparse # 提取命令行参数
import os
from PIL import Image
from torch.utils import data
import numpy as np
from torchvision import transforms as T
import torchvision.transforms as transforms
from torchnet import meter
import matplotlib.pyplot as plt
from torchvision import datasets, transforms, models
import torchvision
from tqdm import tqdm
import warnings
warnings.filterwarnings("ignore")
有些库貌似并没有用上,但是我也懒得删了,反正也不会有问题的。
2. 命令行参数设置
parse = argparse.ArgumentParser(description='Params for training. ')
# 数据集根目录
parse.add_argument('--root', type=str, default='B:/DogVsCat_1', help='path to data set')
# 模式,5选1,当default为train时,就会运行下面的trian函数,就只进行模型训练
# train为训练模型,test为预测test1文件样本的结果,validation为验证模型的预测精度,inference为预测少量样本,inference_one为预测单个样本
parse.add_argument('--mode', type=str, default='train', choices=['train', 'validation', 'test', 'inference', 'inference_one'])
# checkpoint 路径,用来保存模型训练的状态
parse.add_argument('--log_path', type=str, default=os.path.abspath('.') + '/log.pth', help='dir of checkpoints')
# 第一次训练时,需要将restore设为False,等到代码运行一段时间生成log.pth文件后,停止训练,将其改为True,再继续运行即可
parse.add_argument('--restore', type=bool, default=True, help='whether to restore checkpoints')
parse.add_argument('--batch_size', type=int, default=10, help='size of mini-batch')
parse.add_argument('--image_size', type=int, default=64, help='resize image')
# 迭代次数
parse.add_argument('--epoch', type=int, default=5)
# test数据预测结果输出文件名
parse.add_argument('--file_name', type=str, default='result.csv')
args = parse.parse_args() # 解析参数
这里同样是用了argparse模块,具体不清楚的可以取看基于Pytorch的手写汉字识别中的3.2部分,这里就不再赘述。
同样需要强调的是,在第一次运行的时候,需要将restore设为False,等到代码运行一段时间生成log.pth文件后,停止训练,将其改为True,再继续运行即可。
3. 自定义数据集
# 自定义数据集
class MyDataset(data.Dataset):
def __init__(self, root, transforms=None, train=True, test=False):
"""
主要目标: 获取所有图片的地址,并根据训练,验证,测试划分数据
"""
self.test = test
imgs = [os.path.join(root, img) for img in os.listdir(root)] # 目录下每张图片的路径列表
# test1: data/test1/8973.jpg
# train: data/train/cat.10004.jpg
# 将imgs列表按照图片名的序号排序
if self.test:
imgs = sorted(imgs, key=lambda x: int(x.split('.')[-2].split('\\')[-1]))
else:
imgs = sorted(imgs, key=lambda x: int(x.split('.')[-2]))
imgs_num = len(imgs) # 获取数据集大小
# shuffle imgs
np.random.seed(100)
imgs = np.random.permutation(imgs) # 随机排列序列
# 划分训练集和验证集,比例为7:3
if self.test:
self.imgs = imgs # 测试集就不做处理
elif train:
self.imgs = imgs[:int(0.7 * imgs_num)] # 70%的训练集做训练集
else:
self.imgs = imgs[int(0.7 * imgs_num):] # 30%的训练集做验证集
# 数据转换操作
if transforms is None:
normalize = T.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
self.transforms = T.Compose([
T.Scale(256),
T.RandomSizedCrop(224), # 即先随机采集,然后对裁剪得到的图像缩放为同一大小,该操作的含义:即使只是该物体的一部分,我们也认为这是该l类物体
T.RandomHorizontalFlip(), # 以给定的概率随机水平旋转给定的PIL的图像
T.ToTensor(), # 转换为tensor类型
normalize # 归一化
])
def __getitem__(self, index):
"""
返回一张图片的数据
:param index: 图片索引
返回图片数据data和相应的标签label
"""
img_path = self.imgs[index]
if self.test:
label = int(self.imgs[index].split('.')[-2].split('\\')[-1]) # 对于测试集没有label,则返回id,如1000.jpg返回1000
else:
label = 1 if 'dog' in img_path.split('/')[-1] else 0 # 对于训练集和验证集,dog的标签是1,cat的标签是0
data = Image.open(img_path) # 存储图片数据的列表
data = self.transforms(data) # 对图片数据进行转换
return data, label # 返回图片数据和相应的标签
def __len__(self):
return len(self.imgs) # 返回数据大小
这一部分的代码是修改自陈云老师的代码,并且做了一些改动。
这里需要注意的是,如果电脑的win10在代码的以下两处就不做改动,但如果是Linux就改成 ‘/’。(陈云老师代码里是’/’,但是在我电脑上报错了,改成现在的代码就没有问题了)

4. 进行神经网络搭建(ResNet)
# 进行神经网络搭建
class ResidualBlock(nn.Module):
"""
实现子module: Residual Block(残差网络)
"""
def __init__(self, inchannel, outchannel, stride=1, shortcut=None):
super(ResidualBlock, self).__init__()
self.left = nn.Sequential(
nn.Conv2d(inchannel, outchannel, 3, stride, 1, bias=False),
nn.BatchNorm2d(outchannel),
nn.ReLU(inplace=True),
nn.Conv2d(outchannel, outchannel, 3, 1, 1, bias=False),
nn.BatchNorm2d(outchannel))
self.right = shortcut
def forward(self, x):
out = self.left(x)
residual = x if self.right is None else self.right(x)
out += residual
return F.relu(out)
class ResNet34(nn.Module):
"""
实现主module:ResNet34
ResNet34包含多个layer,每个layer又包含多个Residual block
用子module来实现Residual block,用_make_layer函数来实现layer
"""
def __init__(self, num_classes=2):
super(ResNet34, self).__init__()
self.model_name = 'resnet34'
# 前几层: 图像转换
self.pre = nn.Sequential(
nn.Conv2d(3, 64, 7, 2, 3, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.MaxPool2d(3, 2, 1))
# 重复的layer,分别有3,4,6,3个residual block
self.layer1 = self._make_layer(64, 128, 3)
self.layer2 = self._make_layer(128, 256, 4, stride=2)
self.layer3 = self._make_layer(256, 512, 6, stride=2)
self.layer4 = self._make_layer(512, 512, 3, stride=2)
# 分类用的全连接
self.fc = nn.Linear(512, num_classes)
def _make_layer(self, inchannel, outchannel, block_num, stride=1):
"""
构建layer,包含多个residual block
"""
shortcut = nn.Sequential(
nn.Conv2d(inchannel, outchannel, 1, stride, bias=False),
nn.BatchNorm2d(outchannel))
layers = []
layers.append(ResidualBlock(inchannel, outchannel, stride, shortcut))
for i in range(1, block_num):
layers.append(ResidualBlock(outchannel, outchannel))
return nn.Sequential(*layers)
def forward(self, x):
x = self.pre(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = F.avg_pool2d(x, 7)
x = x.view(x.size(0), -1)
return self.fc(x)
这里用的网络是有名的ResNet(残差网络),这是以VGG为基础引入快捷结构加深层,以两个卷积层为间隔,将输入x连接至输出。至于VGG网络,指的是有卷积层和池化层构成的基础的CNN,将有权重的层(卷积层或全连接层)叠加至16层(或19层)。
这部分的代码我还没有细看,这关系到网络的搭建问题,等有空再仔细琢磨网络搭建的问题。
5. 训练模型
# 训练模型
def train():
train_set = MyDataset(args.root + '/train', train=True) # 训练数据对象
train_loader = DataLoader(train_set, batch_size=args.batch_size, shuffle=True, num_workers=1) # 将数据按batch size封装成Tensor
# 选择使用的设备
# device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
device = torch.device('cpu') # 我是后来用cuda训练但是后来一直说内存不够,一气之下就将device直接改成cpu来训练了
# 如果你没有我出现的内存不够的问题,还是直接用上上行的代码吧
print(device)
# 选择模型
model = ResNet34()
model.to(device)
# 训练模式
model.train()
criterion = nn.CrossEntropyLoss() # 损失函数为交叉熵损失函数
optimizer = optim.Adam(model.parameters(), lr=0.001) # 参数优化方法为Adam
# 由命令行参数决定是否从之前的checkpoint开始训练
if args.restore:
checkpoint = torch.load(args.log_path)
model.load_state_dict(checkpoint['model_state_dict'])
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
loss = checkpoint['loss']
epoch = checkpoint['epoch']
else:
loss = 0.0
epoch = 0
while epoch < args.epoch:
running_loss = 0.0
for i, data in tqdm(enumerate(train_loader), total=len(train_set)):
# tqdm是可以将for循环的过程用进度条表示出来
# enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标
# 这里取出的数据就是 __getitem__() 返回的数据
inputs, labels = data[0].to(device), data[1].to(device) # 放入数据和标签
# 根据pytorch中backward()函数的计算,当网络参量进行反馈时,梯度是累积计算而不是被替换
# 处理每一个batch时并不需要与其他batch的梯度混合起来累积计算,因此需要对每个batch调用一遍zero_grad()将参数梯度置0.
optimizer.zero_grad() # 将模型参数梯度初始化为0
outs = model(inputs) # 前向传播计算预测值
loss = criterion(outs, labels) # 计算当前损失
loss.backward() # 反向传播计算梯度
optimizer.step() # 更新所有参数(用Adam)
running_loss += loss.item() # 累加每个batch里每个样本的loss
if i % 200 == 199: # 每训练200个样本就打印epoch,loss,并且保存checkpoint
print('epoch %5d: batch: %5d, loss: %f' % (epoch + 1, i + 1, running_loss / 200)) # 打印该loss平均值
running_loss = 0.0
# 保存 checkpoint
print('Save checkpoint...')
torch.save({'epoch': epoch,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'loss': loss},
args.log_path)
epoch += 1
print('Finish training')
在这一部分,有一点要提的就是关于device。一开始用cuda训练的很正常,但是后来突然报错,说内存不够,然后将batch_size调成1也不行,我就直接将device改成cpu了,但其实速度也还行,就至少我的batch_size可以改高一点也没问题。
要运行这一部分时,就在命令行参数设置部分,将其中的default设置成如下:
parse.add_argument('--mode', type=str, default='train', choices=['train', 'validation', 'test', 'inference', 'inference_one'])
运行ing:
等到训练了200个样本之后,就会打印epoch,loss以及“Save checkpoints…"(我忘记截图这一部分了)
坚持!它会很慢,反正至少要坚持训练200个样本,这样才会保存checkpoint,下次训练就可以直接在上一轮的基础上训练了。其实如果你嫌200太多了,可以在下面的循环部分将200,199调成你想要的值,比如2。
if i % 200 == 199: # 每训练200个样本就打印epoch,loss,并且保存checkpoint
print('epoch %5d: batch: %5d, loss: %f' % (epoch + 1, i + 1, running_loss / 200)) # 打印该loss平均值
running_loss = 0.0
# 保存 checkpoint
print('Save checkpoint...')
torch.save({'epoch': epoch,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'loss': loss},
args.log_path)
注意此时有三个地方需要修改:
此时的运行界面:
6.验证模型,计算预测精度
# 验证模型,计算预测精度
def validation():
# 测试数据集导入
val_data = MyDataset(args.root + '/train', train=False) # 验证集数据
val_dataloader = DataLoader(val_data, batch_size=args.batch_size, shuffle=False, num_workers=4)
# 获取模型
model = ResNet34()
checkpoint = torch.load(args.log_path)
model.load_state_dict(checkpoint['model_state_dict'])
model.eval() # 数据切换到测试模式
with torch.no_grad(): # 停止gradient计算,从而节省了GPU算力和显存
confusion_matrix = meter.ConfusionMeter(2)
for ii, data in enumerate(val_dataloader):
input, label = data # 放入数据和标签
score = model(input)
_, pred = torch.max(score.data, 1)
confusion_matrix.add(score.data, label.data)
cm_value = confusion_matrix.value() # 混淆矩阵
accuracy = 100. * (cm_value[0][0] + cm_value[1][1]) / (cm_value.sum()) # 验证后模型准确率
print('利用验证集得到模型准确率为: %.2f%%' % accuracy)
这部分就是用从训练集中划分的测试集来判断模型的精度。
要运行这部分代码,需要在命令行参数设置部分,将其中的default设置成如下:
parse.add_argument('--mode', type=str, default='validation', choices=['train', 'validation', 'test', 'inference', 'inference_one'])
运行结果如下:
额,这精度结果还行吧。。。其实如果觉得精度不够,可以继续训练,不过就是要防止过拟合。
7. 预测test1文件的所有样本并输出
# 预测test1文件的所有样本并输出
def write_csv(results, file_name):
# 将results输出成文件名为file_name的csv文件
import csv
with open(file_name, 'w') as f:
writer = csv.writer(f)
writer.writerow(['id', 'label'])
writer.writerows(results)
def test():
"""
测试,并将结果保存成csv文件
"""
print('Start testing...')
# 获得训练过的模型
model = ResNet34()
model.eval() # 数据切换到测试模式
checkpoint = torch.load(args.log_path)
model.load_state_dict(checkpoint['model_state_dict'])
# 数据
train_data = MyDataset(args.root + '/test1', test=True) # 测试数据集
test_dataloader = DataLoader(train_data, batch_size=args.batch_size, shuffle=False, num_workers=1)
results = []
for data in test_dataloader:
input, path = data
inputs = Variable(input)
y_pred = model(inputs)
_, pred = torch.max(y_pred.data, 1) # 获得结果最大的分类标签
batch_results = [(path_, pred_) for path_, pred_ in zip(path, pred)]
results += batch_results
write_csv(results, args.file_name)
return results
这一部分是将test1文件夹的所有图片进行预测,并且输出为csv文件,对于文件名的设置,则在
命令行参数设置部分设置。
要运行这部分代码,需要在命令行参数设置部分,将其中的default设置成如下:
parse.add_argument('--mode', type=str, default='test', choices=['train', 'validation', 'test', 'inference', 'inference_one'])
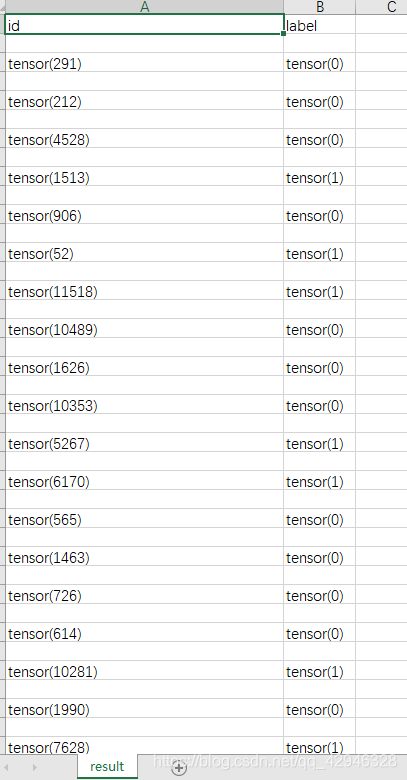
如图所示是我截取的csv文件中的部分结果,其中左边一列是图片在test文件的文件名,右边一列就是改图片被划分的类别,0为cat,1为dog。
8. 预测少量样本
对于一次性预测像上面test文件中那么多图片,看预测效果的话还要再1万多张图片中找相应的图片,有点麻烦。实际上需要预测的图片并没有那么多,所以就补充了一个代码,用来预测少量样本的,输出结果也会更加直观。
这里另外加一个文件夹val,将图片存在里面,如果文件夹的名字不同,记得在下面的代码进行修改

我只放了这四张图
下面是代码:
# 预测少量样本
def inference():
print('Start inference...')
model = ResNet34()
model.eval() # 数据切换到测试模式
checkpoint = torch.load(args.log_path)
model.load_state_dict(checkpoint['model_state_dict'])
# 数据
train_data = MyDataset(args.root + '/val', test=True) # 测试数据集
test_dataloader = DataLoader(train_data, batch_size=1, shuffle=False, num_workers=1)
results = []
results_str = []
classes = ['cat', 'dog'] # 标签的字符串形式,用于将后面的预测结果0,1替换成'cat'和'dog’
for data in test_dataloader:
input, path = data
inputs = Variable(input)
path = Variable(path)
y_pred = model(inputs)
_, pred = torch.max(y_pred.data, 1)
batch_results = [path.item(), pred.item()] # .item()表示将tensor类转换成int类
results.append(batch_results)
prelabel_str = classes[pred.item()]
batch_results_str = [path.item(), prelabel_str]
results_str.append(batch_results_str)
print('Pred Label:' + str(results))
print("Pred Label(str):", str(results_str))
要运行这部分代码,需要在命令行参数设置部分,将其中的default设置成如下:
parse.add_argument('--mode', type=str, default='inference', choices=['train', 'validation', 'test', 'inference', 'inference_one'])
预测结果:
和图片对比一下,发现有些预测正确了,有些预测错了,并没有太准哈,那就后续再训练训练模型吧。?
9. 预测一个样本
有时候只需要预测一张图片,可以在val文件夹里就只放一张图片也行,我这里的情况是直接将图片放在和代码同级的地方
记得针对自己的图片名字,在下面的代码中修改img_path
# 预测一个样本
def inference_one():
print('Start inference...')
model = ResNet34()
model.eval() # 数据切换到测试模式
checkpoint = torch.load(args.log_path)
model.load_state_dict(checkpoint['model_state_dict'])
# 数据
normalize = T.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
transforms = T.Compose([
T.Scale(256),
T.RandomSizedCrop(224), # 即先随机采集,然后对裁剪得到的图像缩放为同一大小,该操作的含义:即使只是该物体的一部分,我们也认为这是该l类物体
T.RandomHorizontalFlip(), # 以给定的概率随机水平旋转给定的PIL的图像
T.ToTensor(),
normalize
])
img_path = '5410.jpg'
data = Image.open(img_path) # 存储图片数据的列表
data = transforms(data) # 对图片数据进行转换
data = data.unsqueeze(0)
path = int(img_path.split('.')[-2].split('\\')[-1]) # 路径标签
classes = ['cat', 'dog']
inputs = Variable(data)
y_pred = model(inputs)
_, pred = torch.max(y_pred.data, 1)
batch_results = [path, pred.item()]
prelabel_str = classes[pred.item()]
batch_results_str = [path, prelabel_str]
print('预测结果:' + str(batch_results))
print("Pred Label:", str(batch_results_str))
要运行这部分代码,需要在命令行参数设置部分,将其中的default设置成如下:
parse.add_argument('--mode', type=str, default='inference_one', choices=['train', 'validation', 'test', 'inference', 'inference_one'])
结果: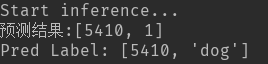
和图片对比结果是预测正确的。
10. main函数
不要忘记在代码最后加上这一部分哦
if __name__ == '__main__':
if args.mode == 'train':
train()
elif args.mode == 'validation':
validation()
elif args.mode == 'inference':
inference()
elif args.mode == 'test':
test()
elif args.mode == 'inference_one':
inference_one()
后记
其实之前训练后,test预测结果全部都是猫,后面少量样本预测,单张图片预测也全是猫,然后验证集验证的精度为100%,就很迷。
于是我也不知道该怎么做,就又给模型训练了200个样本,后面也查看了一下验证集验证的结果并打印出来,发现是又预测是1(狗)的,于是我又尝试了预测少量样本,惊奇地发现预测结果有狗啦!撒花!并且预测效果很不错!