问题描述:
MelbCV.csv是墨尔本人行道监控数据的一个子集,用探索一个新的数据集的一般策略(第三讲ppt)对其进行探索性分析,并利用统计描述或图形回答如下问题:
每个变量有多少个唯一值?什么值出现的频率最高,多久出现一次?有缺失值吗?如果有,这种情况发生的频率有多高?
数据集在附件;
如下图,简单展示数据集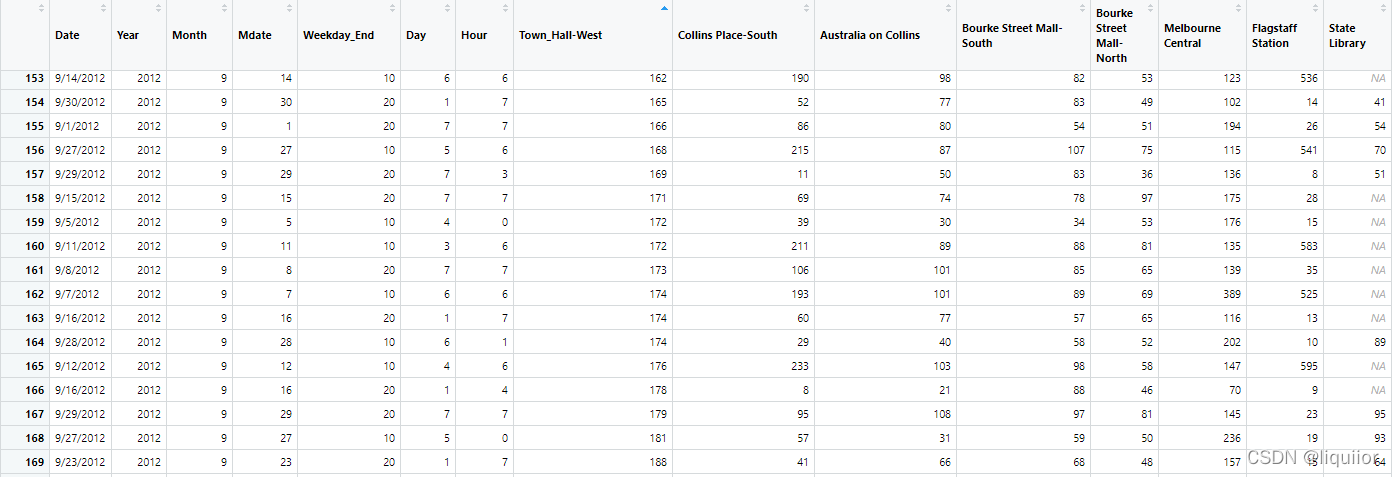
分析:
探索一个新的数据集的一般策略:
- 得到唯一值的方法:
a<-c(11,2,11,5,6,7)
table(a)

2. 获取出现频率最多的一个数,即获取众数:
getmode <- function(v) {
uniqv <- data.frame(table(v))
i<-which.max(uniqv$Freq)
as.numeric(as.vector(uniqv$v[i]))
}
- 因子形转变成向量型
as.vector()
解决方案:
library(tidyverse)
MelbCV<-as.tibble(MelbCV)
MelbCV.unique<-apply(MelbCV,2,FUN = function(x){length(unique(x))})
MelbCV.unique#每个变量有多少唯一值

getmode <- function(v) {
uniqv <- data.frame(table(v))
#print(uniqv)
i<-which.max(uniqv$Freq)#将table转为data.frame的时候表示次数的那列向量会被自动命名为Freq,打印出来如下图一
as.numeric(as.vector(uniqv$v[i]))
}
MelbCV.mode<-apply(MelbCV[,8:15],2,FUN = function(x){getmode(x)})
MelbCV.mode#结果如下图二,出现频率最高的值
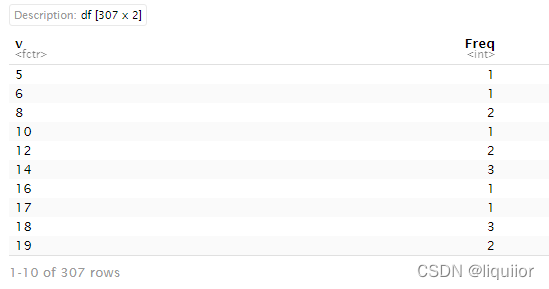

MelbCV.mode是每列出现频次最高的值即众数,其中Date,year,Month,Mdate,Hour中的各个唯一值出现频次相同如下,Day列中出现频次最高的有1和7;Hour中的出现频次最高的值每24个记录其中就会出现一次;Date,year,Month,每一条记录其都会出现其众数;发现State Library的众数是一个缺失值
MelbCV$Date%>%table
MelbCV$Year%>%table
MelbCV$Month%>%table
MelbCV$Mdate%>%table
MelbCV$Day%>%table
MelbCV$Hour%>%table
MelbCV$Weekday_End%>%table

#下面是众数出现的位置
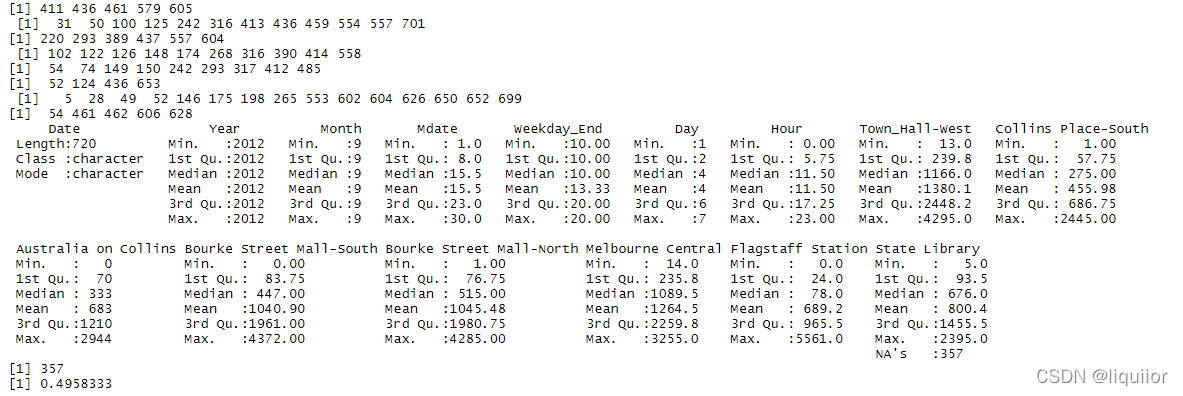
which(MelbCV$`Town_Hall-West`==MelbCV.mode[1])
which(MelbCV$`Collins Place-South`==MelbCV.mode[2])
which(MelbCV$`Bourke Street Mall-North`==MelbCV.mode[5])
which(MelbCV$`Australia on Collins`==MelbCV.mode[3])
which(MelbCV$`Bourke Street Mall-South`==MelbCV.mode[4])
which(MelbCV$`Melbourne Central`==MelbCV.mode[6])
which(MelbCV$`Flagstaff Station`==MelbCV.mode[7])
which(MelbCV$`State Library`==MelbCV.mode[8])
MelbCV%>%summary#发现存在缺失值在`State Library`列,共有357个缺失值
sum(is.na(MelbCV$`State Library`))#缺失值个数
naprop<-sum(is.na(MelbCV$`State Library`))/nrow(MelbCV)
naprop#出现缺失值的频率
版权声明:本文为liquiior原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。