chime-4 lstm
关于比赛 (About the competition)
Not so long ago, there was a challenge for speech separation and recognition called CHIME-6. CHIME competitions have been held since 2011. The main distinguishing feature of these competitions is that conversational speech recorded in everyday home environments on several devices simultaneously is used to train and evaluate participants’ solutions.
不久前,语音分离和识别面临一个挑战,称为CHIME-6 。 CHIME竞赛自2011年以来一直举行。这些竞赛的主要区别在于,在日常家庭环境中同时在几种设备上记录的对话语音用于培训和评估参与者的解决方案。
The data provided for the competition was recorded during the “home parties” of the four participants. These parties were recorded on 32 channels at the same time (six four-channel Microsoft Kinects in the room + two-channel microphones on each of the four speakers).
为比赛提供的数据是在四名参与者的“家庭聚会”期间记录的。 这些参与者同时记录在32个通道上(房间中有六个四通道Microsoft Kinects +四个扬声器中的每个都有两个通道麦克风)。
There were 20 parties, all of them lasting 2–3 hours. The organizers have chosen some of them for testing:
有20个聚会,所有聚会持续2-3小时。 组织者选择了其中一些进行测试:
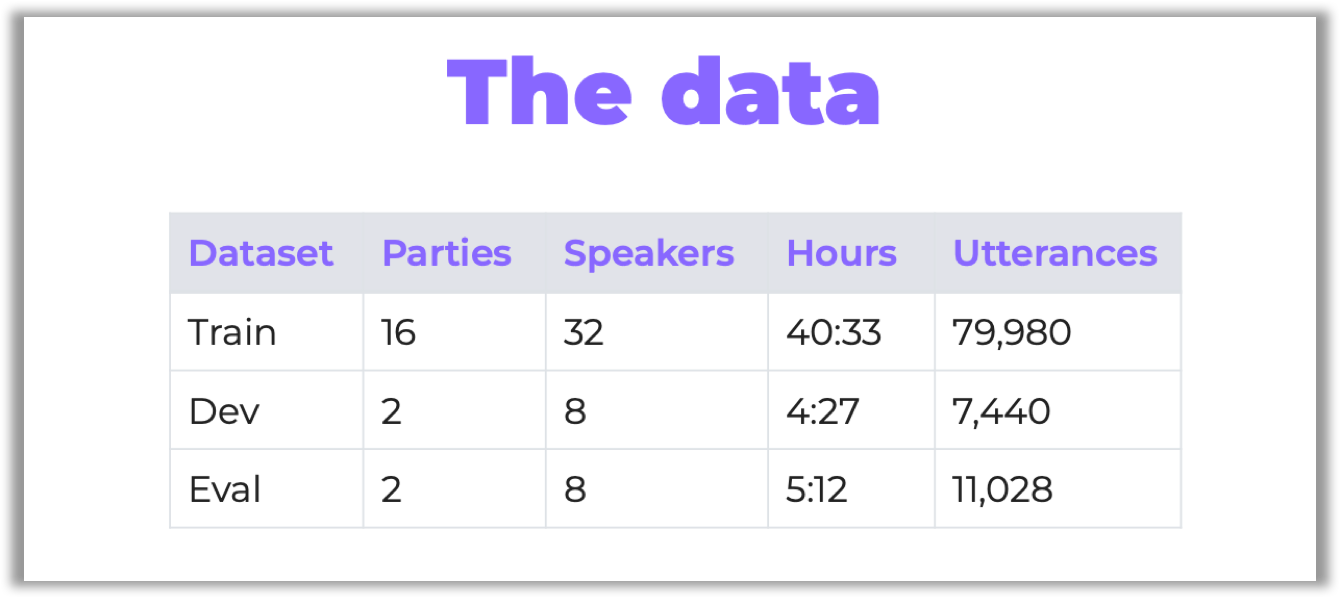
By the way, it was the same dataset that had been used in the previous CHIME-5 challenge. However, the organizers prepared several techniques to improve data quality (see the description of software baselines on GitHub, sections “Array synchronization” and “Speech enhancement”).
顺便说一句,它与之前的CHIME-5挑战赛中使用的数据集相同。 但是,组织者准备了几种提高数据质量的技术(请参阅GitHub上软件基线的描述,“数组同步”和“语音增强”部分)。
To find out more about the competition and data preparation here, visit its GitHub page or read the overview on Arxiv.org.
要在此处找到有关竞赛和数据准备的更多信息,请访问其GitHub页面或在Arxiv.org上阅读概述 。
This year there were two tracks:
今年有两条路:
Track 1 — multiple-array speech recognition;Track 2 — multiple-array diarization and recognition.
音轨1-多阵列语音识别; 专题2 –多阵列分析和识别。
And for each track, there were two separate ranking categories:
对于每个曲目,都有两个单独的排名类别:
Ranking A— systems based on conventional acoustic modeling and official language modeling;
排名A-基于常规声学建模和官方语言建模的系统;
Ranking B — all other systems, including systems based on the end-to-end ASR baseline or systems whose lexicon and/or language model have been modified.
等级B-所有其他系统,包括基于端到端ASR基线的系统或已修改其词典和/或语言模型的系统。
The organizers provided a baseline for participation, which includes a pipeline based on the Kaldi speech recognition toolkit.
组织者提供了参与的基线,其中包括基于Kaldi语音识别工具包的管道。
The main criterion for evaluating participants was the speech recognition metric — word error rate (WER). For the second track, two additional metrics were used — diarization error rate (DER) and Jaccard error rate (JER), which allow to evaluate the quality of the diarization task:
评估参与者的主要标准是语音识别指标-单词错误率(WER)。 对于第二条轨道,使用了两个额外的度量标准-区分错误率(DER)和Jaccard错误率(JER),它们可以评估区分任务的质量:
In the tables below, you can see the competition results:
在下表中,您可以看到比赛结果:
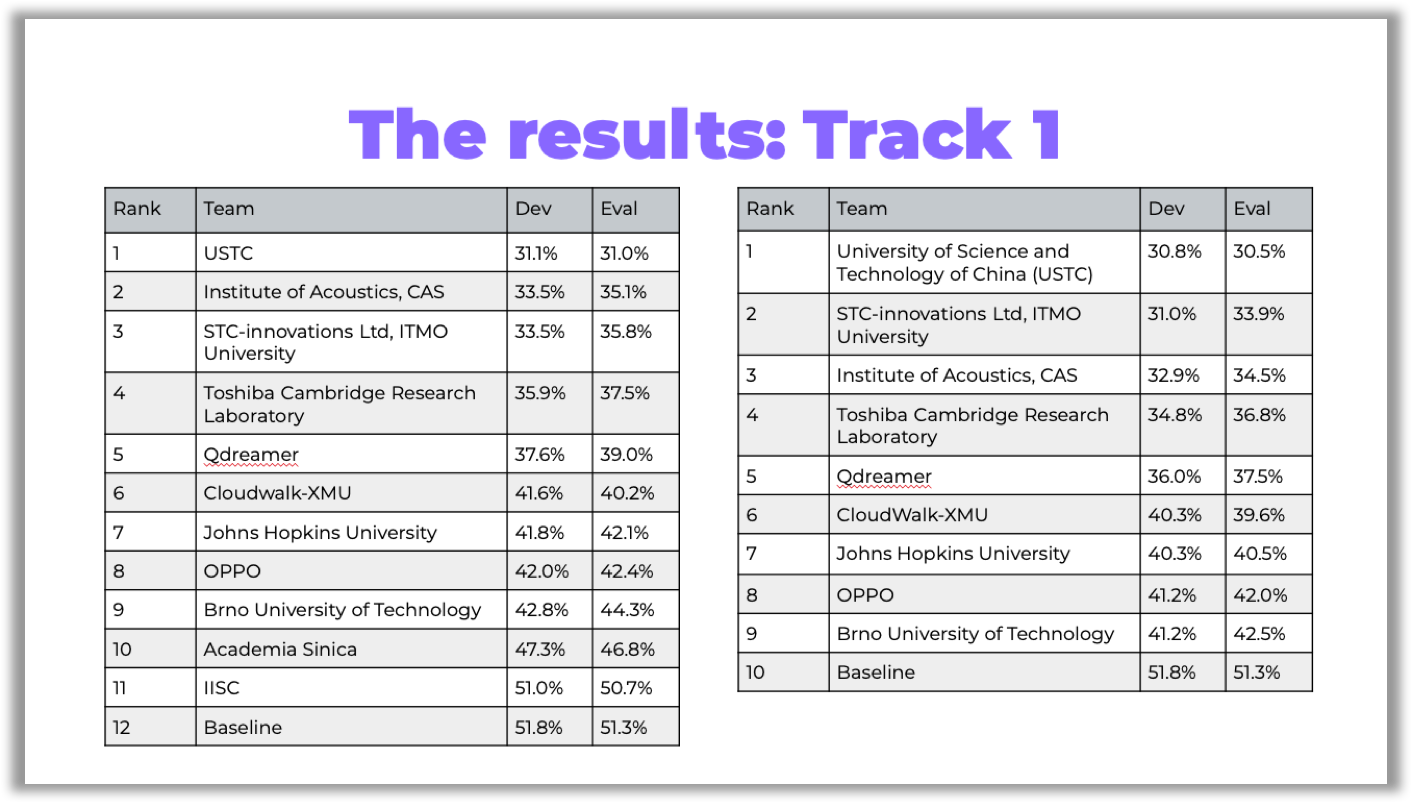
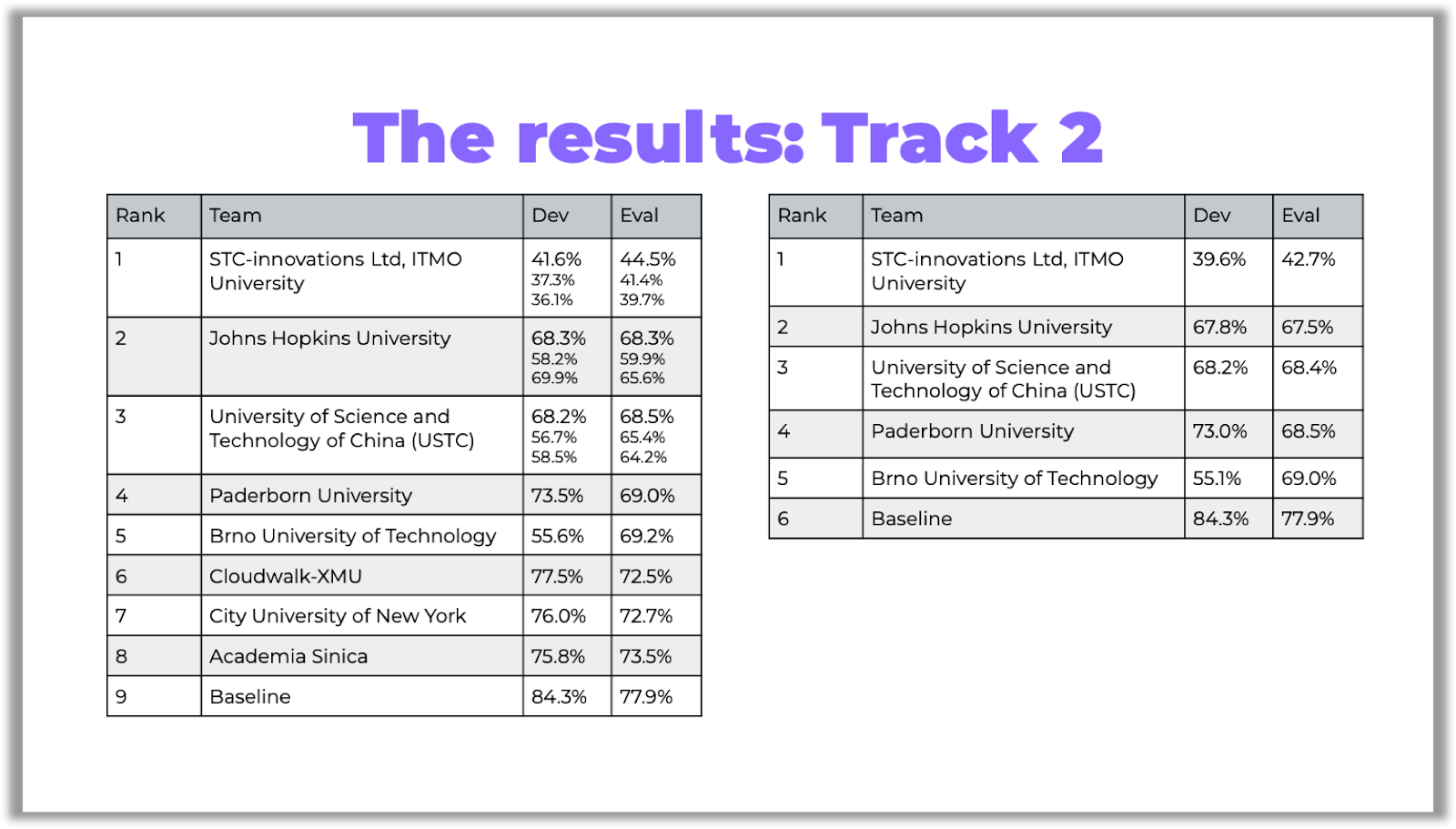
You can access the links to the papers on GitHub.
您可以访问GitHub上的论文链接。
Here are a few curious things I’d like to discuss about the challenge: don’t want you to miss anything!
关于挑战,我想讨论一些奇怪的事情:不想让您错过任何事情!
挑战亮点 (Challenge highlights)
以研究为导向的参与 (Research-oriented participation)
In the previous CHiME-5 challenge, the Paderborn University team, who ranked 4th in Track 2, focused on a speech enhancement technique called Guided Source Separation (GSS). The results of the CHiME-5 competition have demonstrated that the technique improves other solutions.
在上一届CHiME-5挑战赛中,帕德博恩大学团队在第二分赛中排名第四,其研究重点是语音增强技术,即引导源分离 (GSS)。 CHiME-5竞赛的结果表明该技术改进了其他解决方案。
This year, the organizers officially referred to GSS in the sound improvement section and included this technique in the baseline of the first track.
今年,组织者在声音改善部分正式提及了GSS,并将此技术纳入了第一首曲目的基线。
That is why many participants, including all the front runners, used GSS or a similar modification inspired by this idea.
这就是为什么包括所有领先者在内的许多参与者都使用GSS或受此想法启发的类似修改的原因。
Here is how it works: you need to construct a Spatial Mixture Model (SMM), which allows to determine time-frequency masks for speakers (i.e., on what frequencies and at what time a given speaker was speaking). Training is performed using the EM algorithm with temporary annotations of speakers as initialization.
它是这样工作的:您需要构建一个空间混合模型(SMM),该模型可以确定扬声器的时频掩码(即,给定扬声器在什么频率和什么时间说话)。 训练是使用EM算法进行的,将说话者的临时注释作为初始化。
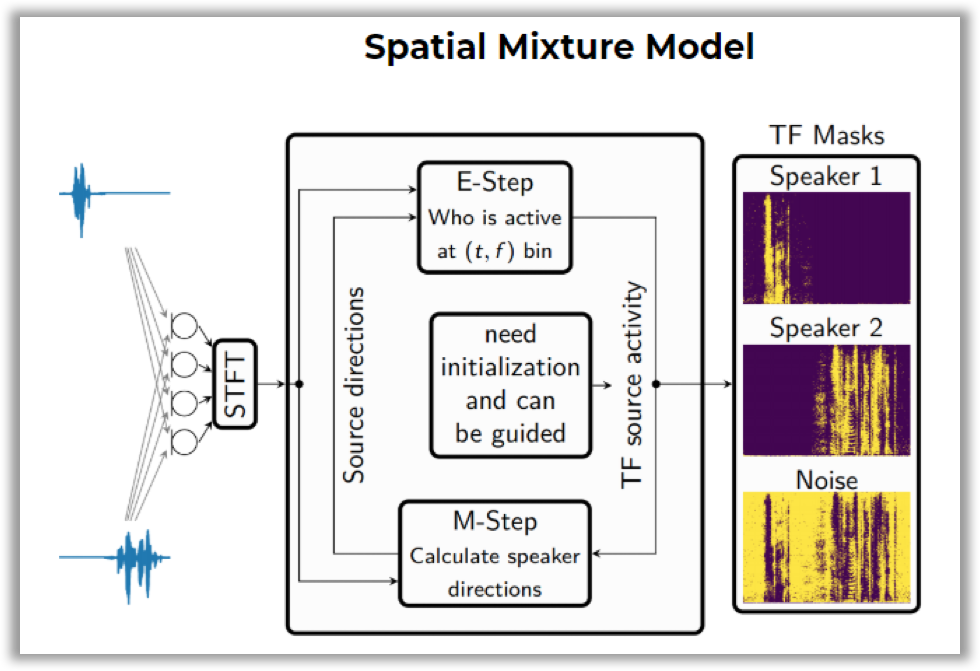
Then, this block is integrated into the general speech enhancement pipeline. This pipeline includes the dereverberation technique (i.e., removing the echo effect from a signal, which occurs when sound is reflected from the walls) and beamforming (i.e., generating a single signal from several audio tracks).
然后,将该块集成到通用语音增强管道中。 该管道包括去混响技术(即从声音中去除声音时从信号中消除回声效应)和波束成形(即从多个音轨中生成单个信号)。
Since there were no speaker annotations for the second track, speech recognition alignments (time stamps of spoken phrases) were used to initialize the EM algorithm for training SMM.
由于第二音轨没有说话者注释,因此使用语音识别对齐方式(口语短语的时间戳)来初始化用于训练SMM的EM算法。
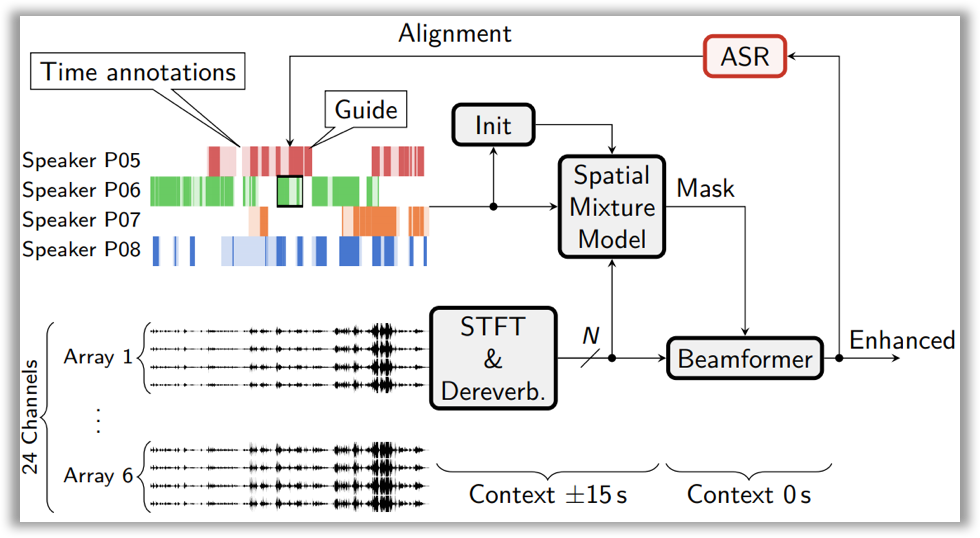
You can read more about the technique and its implementation results in the Hitachi and Paderborn University team’s paper on Arxiv or take a look at their slides.
您可以在Hitachi和Paderborn University团队关于Arxiv的论文中阅读有关该技术及其实现结果的更多信息,或查看其幻灯片 。
自己的解决方案 (Solution for themselves)
The USTC team, who ranked 1st in Track 1 and 3rd in Track 2, improved the solution they presented at the CHIME-5 challenge. This is the same team that won the CHIME-5 contest. However, other participants did not use the techniques described in their solution.
USTC团队在Track 1中排名第一,在Track 2中排名第三,改进了他们在CHIME-5挑战赛上提出的解决方案。 这是赢得CHIME-5比赛的同一支球队。 但是,其他参与者未使用其解决方案中描述的技术。
Inspired by the idea of GSS, USTC implemented its modification of the speech enhancement algorithm — IBF-SS.
受GSS想法的启发,USTC实施了对语音增强算法IBF-SS的修改。
You can find out more in their paper.
您可以在他们的论文中找到更多信息。
基线改善 (Baseline improvement)
There were several evident weaknesses in the baseline that the organizers did not bother to hide: for example, using only one audio channel to build diarization or the lack of rescoring by the language model for ranking B. In baseline scripts, you can also find tips for improvement (for example, to add augmentation with noise from the CHIME-6 data to build x-vectors).
基线存在一些明显的弱点,组织者不会费心掩盖:例如,仅使用一个音频通道进行二值化,或者缺乏语言模型的评分来排名B。在基线脚本中,您还可以找到提示进行改进(例如,添加来自CHIME-6数据的噪声增强以构建x矢量)。
The JHU team solution completely eliminates all these weaknesses: there no brand new super efficient techniques, but the participants went over all the problem areas of the baseline. In Track 2, they ranked 2nd.
JHU团队的解决方案完全消除了所有这些弱点:没有全新的超高效技术,但是参与者研究了基线的所有问题区域。 在Track 2中,他们排名第二。
They explored multi-array processing techniques at each stage of the pipeline, such as multi-array GSS for enhancement, posterior fusion for speech activity detection, PLDA score fusion for diarization, and lattice combination for ASR. The GSS technique was described above. A good enough fusion technique, according to the JHU research, is simple max function.
他们探索了管线各个阶段的多阵列处理技术,例如用于增强的多阵列GSS,用于语音活动检测的后融合,用于二值化的PLDA分数融合以及用于ASR的晶格组合。 上面描述了GSS技术。 根据JHU的研究,足够好的融合技术是简单的max函数。
Besides, they integrated techniques such as online multi-channel WPE dereverberation and VB-HMM based overlap assignment to deal with challenges like background noise and overlapping speakers, respectively.
此外,他们还集成了在线多通道WPE去混响和基于VB-HMM的重叠分配等技术,分别应对背景噪声和扬声器重叠等挑战。
More detailed description of the JHU solution can be found in their paper.
有关JHU解决方案的更多详细说明,请参见他们的论文 。
追踪2名获胜者:有趣的把戏 (Track 2 winners: interesting tricks)
I‘d like to highlight a few tricks that were used by the winners of the second track of the competition, the ITMO (STC) team:
我想强调一下第二道比赛的冠军ITMO(STC)团队使用的一些技巧:
WRN x向量 (WRN x-vectors)
X-Vector is a speaker embedding, i.e a vector that contains speaker information. Such vectors are used in speaker recognition tasks. WRN x-vectors is an improvement of x-vectors through using the ResNet architecture and some other tricks. It has reduced DER so much that this technique alone would have been enough for the team to win the competition.
X-Vector是说话者嵌入,即包含说话者信息的向量。 这样的向量被用于说话者识别任务。 WRN x-vector是通过使用ResNet体系结构和其他技巧来对x-vector的改进。 它降低了DER,以至于仅凭这项技术就足以使团队赢得比赛。
You can read more about WRN x-vectors in the paper by the ITMO team.
您可以在ITMO团队的论文中阅读有关WRN x矢量的更多信息。
余弦相似度和频谱聚类,并自动选择二值化阈值 (Cosine similarities and spectral clustering with automatic selection of the binarization threshold)
By default, the Kaldi diarization pipeline includes extracting x-vectors from audio, calculating PLDA scores and clustering audio using agglomerative hierarchical clustering (AHC).
默认情况下,Kaldi diarization流水线包括从音频中提取x矢量,计算PLDA分数并使用聚集层次聚类(AHC)对音频进行聚类。
Now look at the PLDA component that used to build distances between speaker vectors. PLDA has a mathematical justification in calculating distances for I-Vectors. Put simply, it relies on the fact that I-Vectors contain information about the speaker and the channel, and when clustering, the only important thing for us is the speaker information. It also works nicely for X-Vectors.
现在看一下PLDA组件,该组件用于建立说话人矢量之间的距离。 PLDA在计算I向量的距离时具有数学上的依据。 简而言之,它依赖于一个事实,即I-Vector包含有关扬声器和声道的信息,并且在聚类时,对我们来说唯一重要的事情就是扬声器信息。 它也适用于X-Vectors。
However, using cosine similarity instead of PLDA scores and spectral clustering with automatic selection of a threshold instead of AHC allowed the ITMO team to make another significant improvement in diarization.
但是,使用余弦相似度代替PLDA分数,并通过自动选择阈值而不是AHC进行光谱聚类,这使ITMO团队在数字化方面有了另一个显着改进。
To find out more about spectral clustering with automatic selection of the binarization threshold, read this paper on Arxiv.org.
要了解更多关于二值化阈值自动选择谱聚类,请阅读本文件上Arxiv.org。
TS-VAD (TS-VAD)
The authors focus specifically on this technique in their work. TS-VAD is a novel approach that predicts an activity of each speaker on each time frame. The TS-VAD model uses acoustic features (e.g., MFCC) along with i-vectors for each speaker as inputs. Two versions of TS-VAD are provided: single-channel and multi-channel. The architecture of this model is presented below.
作者在工作中特别关注此技术。 TS-VAD是一种新颖的方法,可以预测每个时间段每个发言人的活动。 TS-VAD模型使用声学功能(例如MFCC)以及每个扬声器的i矢量作为输入。 提供了TS-VAD的两个版本:单通道和多通道。 该模型的体系结构如下所示。
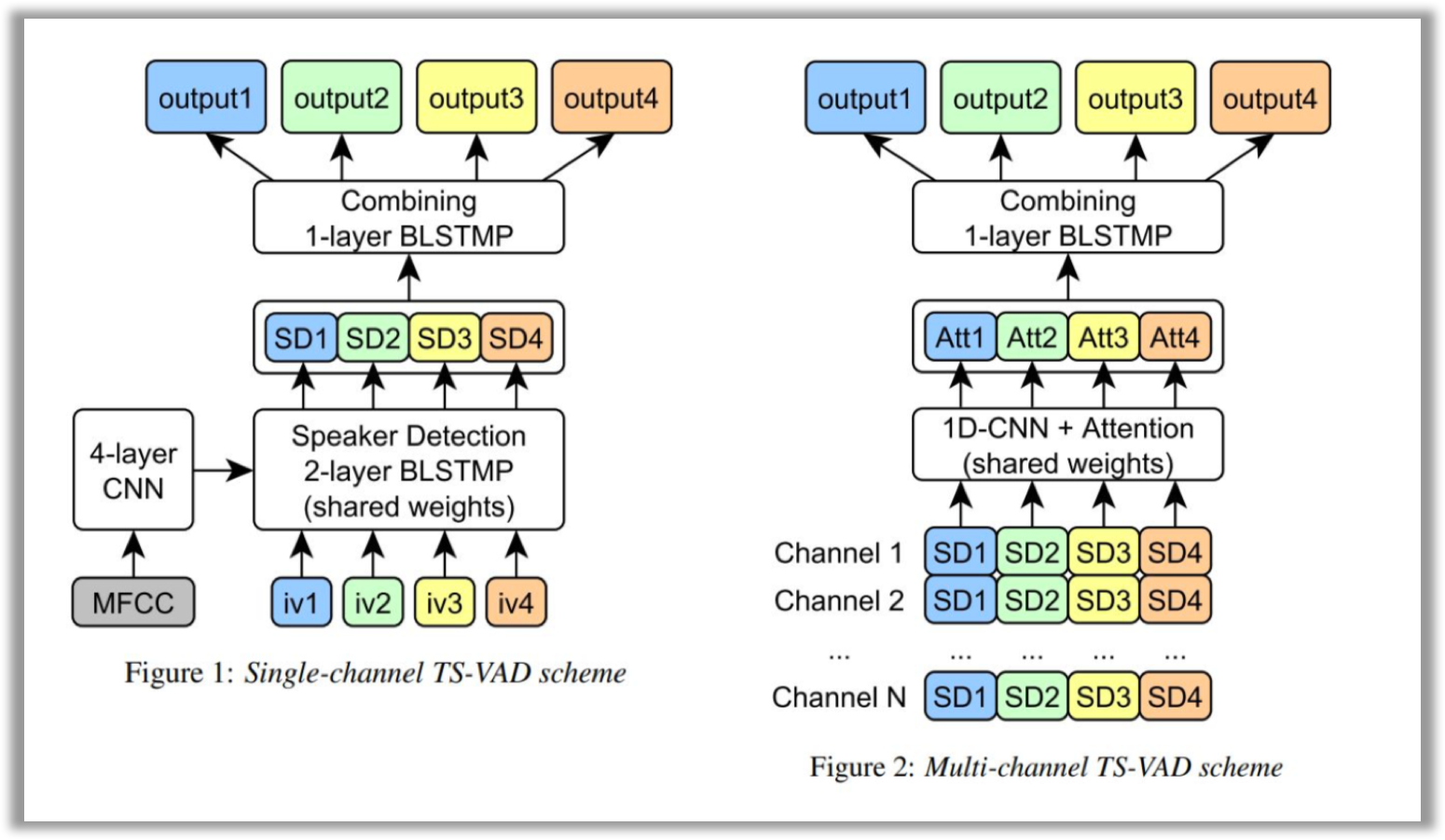
Note that this network is tailored for dialogs of four participants, which is actually stipulated by the requirements of this challenge.
请注意,此网络是为四个参与者的对话量身定制的,这实际上是此挑战的要求所规定的。
The single-channel TS-VAD model was designed to predict speech probabilities for all speakers simultaneously. This model with four output layers was trained using a sum of binary cross-entropies as a loss function. Authors also found that it is essential to process each speaker by the same Speaker Detection (SD) 2-layer BLSTMP, and then combine SD outputs for all speakers by one more BLSTMP layer.
单通道TS-VAD模型旨在同时预测所有说话者的语音概率。 使用二进制交叉熵之和作为损失函数训练了具有四个输出层的模型。 作者还发现,必须通过同一扬声器检测(SD)2层BLSTMP处理每个扬声器,然后再通过一个BLSTMP层将所有扬声器的SD输出组合在一起。
The single-channel version of TS-VAD processes each channel separately. To process separate Kinect channels jointly, authors investigated the multi-channel TS-VAD model, which uses a combination of SD blocks outputs of the single TS-VAD model as an input. All the SD vectors for each speaker are passed through a 1-d convolutional layer and then combined by means of a simple attention mechanism. Combined outputs of attention for all speakers are passed through a single BLSTM layer and converted into a set of perframe probabilities of each speaker’s presence/absence.
TS-VAD的单通道版本分别处理每个通道。 为了共同处理单独的Kinect通道,作者研究了多通道TS-VAD模型,该模型使用单个TS-VAD模型的SD块输出的组合作为输入。 每个说话者的所有SD向量都经过一维卷积层,然后借助简单的关注机制进行组合。 所有发言者的注意力集中输出通过单个BLSTM层传递,并转换为每个发言者存在/不存在的一组perframe概率。
Finally, to improve overall diarization performance, the ITMO team fused several single-channel and multi-channel TS-VAD models by computing a weighted average of their probability streams.
最后,为了提高总体数字化性能,ITMO团队通过计算概率流的加权平均值,融合了几种单通道和多通道TS-VAD模型。
You can learn more about the TS-VAD model on Arxiv.org.
您可以在Arxiv.org上了解有关TS-VAD模型的更多信息。
结论 (Conclusion)
I hope this review has helped you get a better understanding of the CHiME-6 challenge. Maybe you’ll find the tips and tricks I mentioned useful if you decide to take part in the upcoming contests. Feel free to reach out in case I missed something!
我希望这篇评论能帮助您更好地了解CHiME-6挑战。 如果您决定参加即将举行的比赛,也许您会发现我提到的提示和技巧很有用。 如有任何遗漏,请随时与我们联系!
翻译自: https://towardsdatascience.com/the-chime-6-challenge-review-15f3cbf0062d
chime-4 lstm