文章目录
STL的容器可分为序列容器和关联容器两大类。
- 序列容器:有数组(array)、向量(vector)、双端队列(deuqe)、双向链表(list)、单向链表(forward_list)等;
- 关联容器:集合(set)、可重复集合(multiset)等;
 | 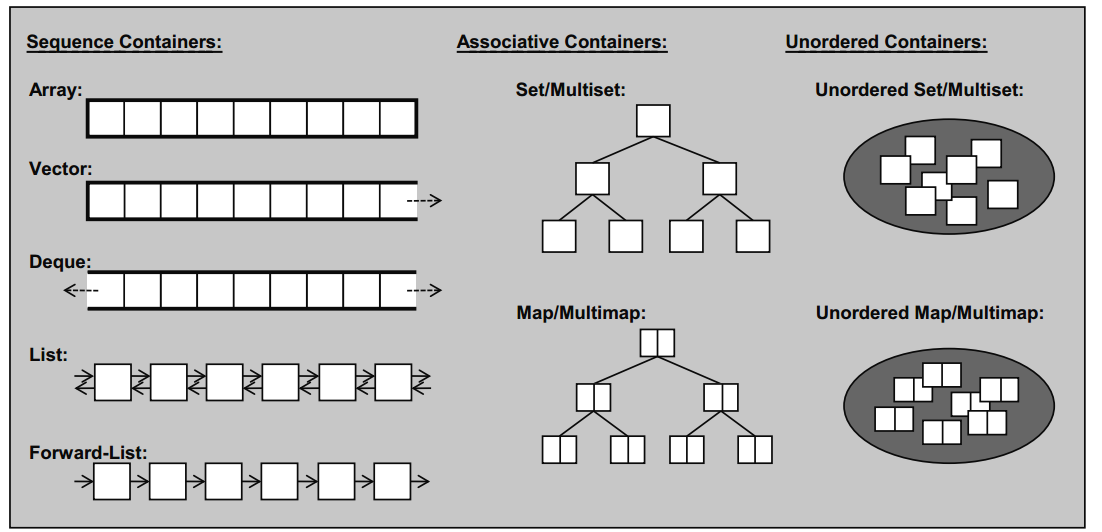 |
其中关联容器中又包括不定序容器(unordered_containers) / 无序关联容器(unordered associative container),上图中列出了四种unordered_set、unordered_multiset、unordered_map、unordered_multimap。不定序容器是指元素在容器中的位置是不确定的,也就是减少了关联容器的排序的过程,对于不需要排序的数据来讲,效率会更高一些。其是通过hashfunction()之后的哈希表和链表的复合数据结构,若是哈希桶的链表的长度超出一定值,会进行哈希重排,增加哈希桶的个数,以保持链表长度较短。
1. 容器的结构与分类

其中关于sizeof()结果的问题,结合源码和C++类空间大小可以解答
2. 序列容器(Sequence Containers)
2.1 list 容器
- list容器成员及函数 ,更多list成员函数源码见 list源码1(参考STL源码–侯捷):list节点、迭代器、数据结构 系列
list相比vector要复杂许多,list是一个双向链表,所以插入删除元素的操作代价较小,但是索引(find)比较耗时。下面是___list_node节点的源码实现:
//list节点__list_node的模板实现
template <class T>
struct __list_node{
typedef void* void_pointer;
void_pointer prev;
//类型为void*,
//其实也可以设置为__list_node<T>*,在更新版本中已经更改为_list_node_base*类型
void_pointer next;
T data;
};
list迭代器必须有能力指向list的节点,并有能力进行正确的递增、递减、取值、成员存取等操作,同时list是双向链表,迭代器必须具备前移、后移的能力,所以list提供的是Bidirectional Iterators。
list有一个重要性质:插入(insert)操作和接合(splice)操作都不会造成原有的list迭代器失效,甚至list的元素删除(erase)操作也只有“指向被删除元素”的那个迭代器失效,其它迭代器失效不受任何影响。list迭代器的部分源码如下:
template<class T,class Ref,class Ptr>
struct __list_iterator{
typedef __list_iterator<T,T&,T*> iterator;
typedef __list_iterator<T,Ref,Ptr> self;
typedef bidirectional_iterator_tag iterator_category; //(1)
typedef T value_type; //(2)
typedef Ptr pointer; //(3)
typedef Ref reference; //(4)
typedef __list_node<T>* link_type;
typedef size_t size_type;
typedef ptrdiff_t difference_type; //(5)
link_type node; //迭代器内部需要一个普通指针,指向list的节点
//ctor
__list_iterator(link_type x):node(x){}
__list_iterator(){}
__list_iterator(const iterator& x):node(x.node){}
//以下对迭代器取值,取的是节点的数据值
reference operator*() const {return (*node).data;}
pointer operator->() const {return &(operator*());}
//对迭代器累加
self& operator++(){ node=(link_type)((*node).next); return *this; }
//后置++具体的调用过程见下图,其间调用前置++
self operator++(int){ self tmp=*this; ++*this; return tmp; }
...
};

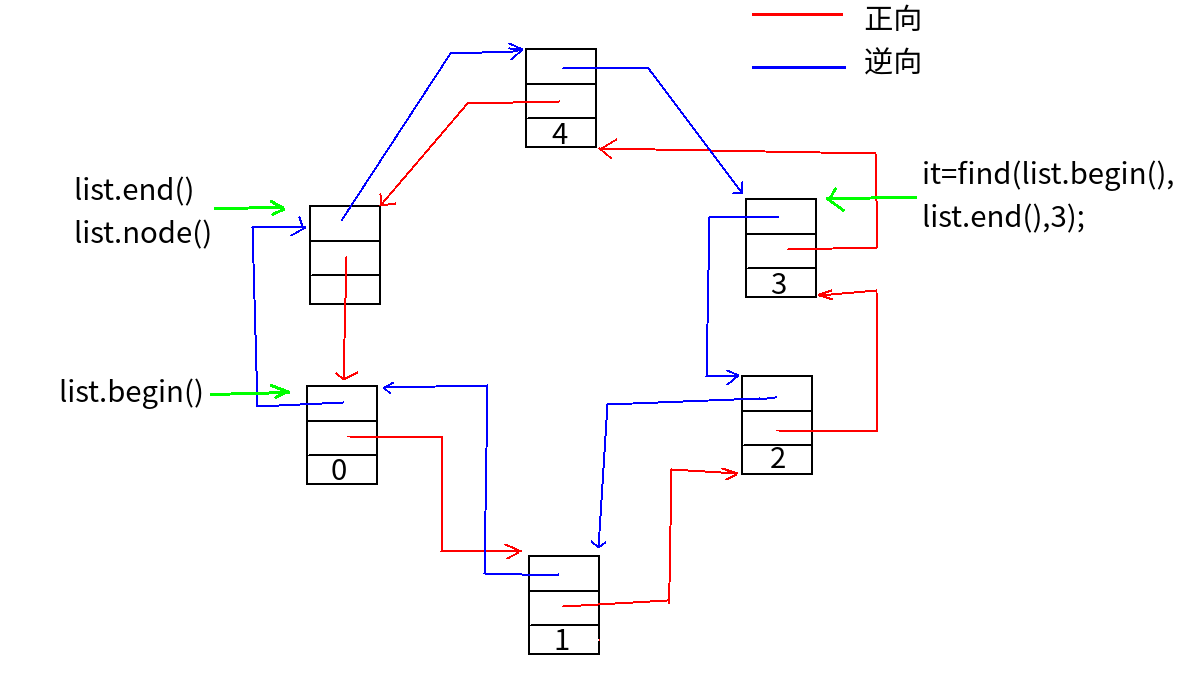
list不仅是一个双向链表,而且还是一个环状双向链表,所以它只需要一个__list_node指针便可以完整表现整个链表:
template <class T,class Alloc=alloc> //缺省使用alloc为适配器
class list{
protected:
typedef __list_node<T> list_node;
public:
typedef list_node* link_type;
protected:
link_type node; //只要一个指针,node指针指向end(),可表示整个环装双向链表
......
};
如果让node(如上)指向刻意置于尾端的一个空间节点(类似于做算法题中的dummy节点,简化情形),node便能符合STL对于“前闭后开”区间的要求,成为last迭代器,如下图,这样以来,以下几个函数可以很好完成:
//以下函数都是list定义中的成员函数
iterator begin(){return (link_type)((*node).next);}
iterator end(){return node;}
bool empty() const{return node->next==node;}
size_type size() const{
size_type result=0;
distance(begin(),end(),result);
return result;
}
//取头结点的内容
reference front(){return *begin();}
//取尾节点的内容
reference back(){return *(--end());}
//其insert函数并不像之后提到的几个容器的insert函数一样,调用了insert_aux()全局函数
//首先其是重载函数,以下只是最简单的实现,思想为构造一新节点,并在插入位置进行适当的指针操作,
//将新节点插入到链表当中去
iterator insert(iterator position,const T& x){
link_type temp=create_node(x);//产生一个节点
//调整双向指针,使temp插入进去
temp->next=position.node;
temp->prev=position.node->prev;
(link_type(position.node->prev))->next=temp;
position.node->prev=temp;
return temp;
}
2.2 vector 容器
 |  vector函数 vector函数 |
//GNU 2.9版本
template <class T, class Alloc = alloc>
class vector {
public:
typedef T value_type;
typedef value_type* iterator;
//只要是连续空间,其迭代器可以用指针来表现
typedef value_type& reference;
typedef size_t size_type;
...
protected:
iterator start;
iterator finish;
iterator end_of_storage;
void insert_aux(iterator position, const T& x);
...
public:
iterator begin() { return start; }
iterator end() { return finish; }
size_type size() const { return size_type(end() - begin()); } //GP考虑,函数调用屏蔽掉指针解引用
size_type capacity() const { return size_type(end_of_storage - begin()); }
bool empty() const { return begin() == end(); }
reference operator[](size_type n) { return *(begin() + n); }
reference front() { return *begin(); }
reference back() { return *(end() - 1); }
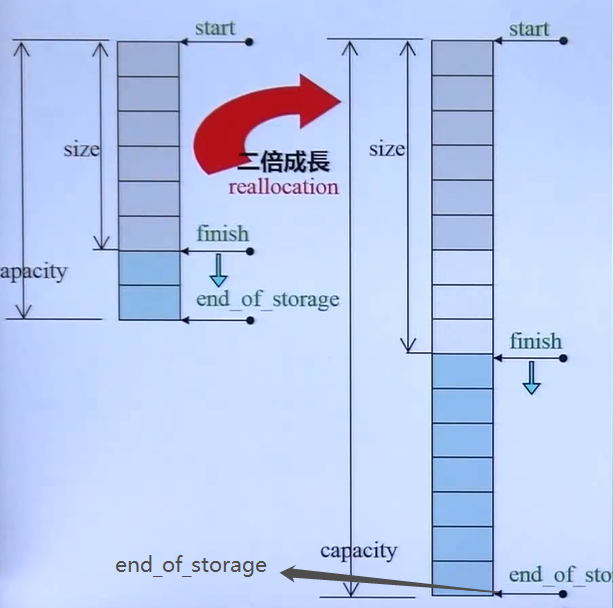
void push_back(const T& x) {
if (finish != end_of_storage) { //capacity未满
construct(finish, x); //全局函数
++finish; //调整末尾索引值
} else { //capacity填满
insert_aux(end(), x); //进行插入的辅助函数,aux:auxiliary
//该函数是一模板函数,所以进入之后会再次判断是否越界,
//然后进行新空间大小计算,开辟新的新空间大小的内存,并进行copy操作
//const size_type len = old_size != 0 ? old_size * 2 : 1;
//新的vector的len是原vector的二倍,若是长度为0,补位1
//再将原空间进行dellocate/dctr
}
}
...
};
vector空间虽可以成长,但只能向尾端成长,而且其成长是个假象,事实上是(1)另觅更大空间;(2)将原数据复制过去;(3)释放原空间。如果不是vector每次配置新空间的时候都留有一些余裕,vector的成长代价很大。所以,在需要大量使用插入删除的操作场景下,优先考虑其他容器。
2.3 array 容器
比起vector更简单,在数组的基础上包装成容器,是为了提供iterator等STL体系中的功能,以便于算法对其操作;若是没有包装,则array不能够使用algorithm、functor等功能了。
//实现是TR1版本。TR1(Technical Report 1):c++过渡版本,c++1.0(1998),c++2.0(2001);
template<typename _Tp, std::size_t _Nm>
struct array {
typedef _Tp value_type;
typedef *_Tp pointer;
typedef value_type* iterator; //和GNU 2.9的vector一样,array的iterator也是naive pointer
//Support for zero-sized arrays mandatory.支持0空间的array,但是其成员变量数组大小最小为1
value_type _M_instance[_Nm ? _Nm : 1];
...
iterator begin() { return iterator(&_M_instance[0]); }
iterator end() { return iterator(&_M_instance[_Nm]); }
...
//...没有dtor,只有ctor
};
array也是线性空间容器,其空间大小是指定的,不能够增长。
2.4 deque 容器
deque是一种分段连续的容器,实现是将元素分段(buffer)之后再串接(map辅助)起来。
一旦有必要在deque的前端或尾端增加新空间,便配置一段定量连续空间,串接在整个deque的头端或尾端。其本质是在分段的连续定量空间上,维护其整体连续的假象,并提供随机存取的接口。以迭代器的复杂为代价,避开了vector三部曲式成长的高昂代价。
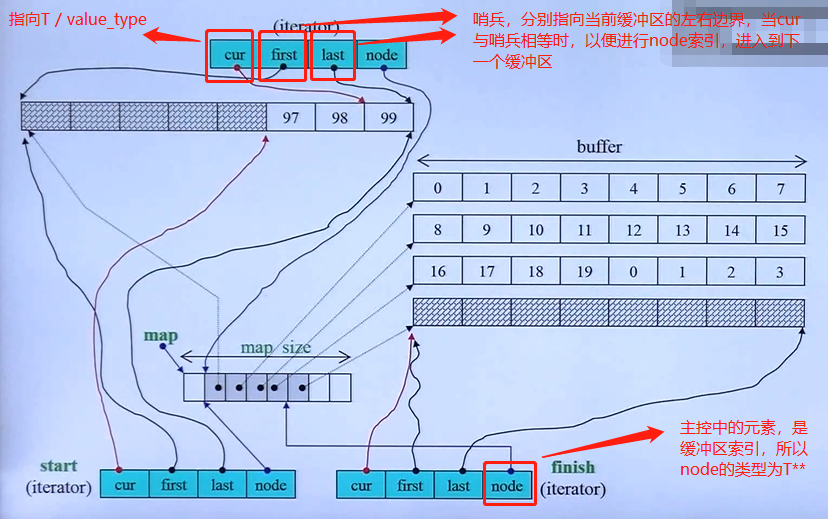
deque采用一块 主控map(实际为vector容器) ,其中每个 map元素(指针,称为node) 是指向另一段 较大连续线性空间(称为buffer,缓冲区) 的指针。其中,缓冲区才是存储空间主体。SGI STL允许指定缓冲区大小,默认值0表示使用512bytes大小的缓存区,另外新版GNU已不支持。
template<class T, class Alloc = alloc, size_t BufSiz=0>
class deque {
public:
typedef T value_type;
typedef value_type* pointer;
typedef __deque_iterator<T, T&, T*, BufSize> iterator;
...
protected:
typedef pointer* map_pointer; //T**,指定类的二重指针
protected:
iterator start; //第一个node
iterator finish; //最后一个node,其是备用缓冲区
//在实际实现中,finish作为备用缓冲区,若有新元素插入尾端,且实际存储数据的最后一个缓冲区满,可直接使用finish,并再开一缓冲区作为备用缓冲区
map_pointer map; //主控器是二重指针,因为从主控器node->buffer[pos]->T
size_type map_size;
//map内可容纳多少指针,即能容纳多少node
//一旦map所能提供的节点不足,就必须重新配置更大的一块map
public:
iterator begin() { return start; }
iterator end() { return finish; }
size_type size() const { return finish - start; }
...
}
//------------------------------------------------------------------------------------------------------------
//deque's iterator,双端队列的迭代器实现
//deque模拟连续空间,由deque iterator来实现
template<class T, class Ref, class Ptr, size_t BufSiz>
struct __deque_iterator { //未继承std::iterator,所以必须自行写出五个必要的迭代器相应类别
typedef __deque_iterator<T, T&, T*, BufSiz> iterator;
typedef __deque_iterator<T, const T&, const T*, BufSiz> const_iterator;
//用来决定缓冲区大小,调用内联函数__deque_buf_size()
static size_t buffer_size() { return __deque_buf_size(BufSiz, sizeof(T)); }
//所谓BufSiz指的是每个缓冲区容纳的元素个数
inline size_t __deque_buf_size(size_t n, size_t sz) {
return n != 0 ? n : (sz < 512 ? size_t(512/sz) : size_t(1));
}
//n!=0,返回n,表示buffer_size由用户自定义
//n=0,表示buffer_size使用默认值,那么:
// sz<512,传回512/sz;
// sz>=512,传回1
typedef random_access_iterator_tag iterator_category; //(1)
typedef T value_type; //(2)
typedef Ptr pointer; //(3)
typedef Ref reference; //(4)
typedef size_t size_type;
typedef ptrdiff_t difference_type; //(5)
typedef T** map_pointer
typedef __deque_iterator self;
//保持与容器的联结
T* cur; //此迭代器所指之缓冲区中的现行(current)元素
T* first; //此迭代器所指之缓冲区的头
T* last; //此迭代器所指之缓冲区的尾(含备用空间)
map_pointer node; //指向主控
...
}
相比于vector,deque维持这样的 “连续” 空间需要付出更大的代价,和vector一样,在需要大量使用插入删除的操作场景下,优先考虑其他容器。接下来再把std::deque<T>::insert()单独拎出来,理解其实现,这里可以查看deque容器的insert函数。
iterator insert(iterator position, const value_type& x) {
if(position.cur == start.cur) {//如果安插的位置是deque的最前端,交给push_front()来做
//可以查看源码做进一步了解,push_front,未满情况下是--start.cur;
push_front(x); //push_front()在第一个缓冲区满的情况下,会调用push_front_aux(const value_type& t)
return start; //返回start,说明做了*运算符重载
} else if(position.cur == finish.cur) {
push_back(x); //同push_front(),调用push_back_aux(const value_type& t)
//iterator tmp = finish--;未满情况下,++tmp.cur;
iterator tmp = finish;
--tmp; //这里__deque_iterator做了--运算符重载
return tmp;
} else {
return insert_aux(position, x);
//insert_aux的思想:
//1.先计算安插点之前的元素的个数,
//2.如果安插点之前的元素个数较少,则在前端加入第一个元素同值的元素,然后将所有元素向前搬移,
// 如果按差点之后的元素个数较少,则在末端加入最后一个元素同值的元素,若后将所有元素后向搬移
//3.在腾出来的安插点位置设定插入值
}
}
通过insert()函数,我们意识到了iterator对其运算符进行了重载,实际上deque维持其"整体连续"的假象任务,完全落在了迭代器的运算符身上。
对于operator:
- 必须能够指出分段连续空间(即缓冲区)在哪里,当前
cur(一级指针,可以做++、–运算)所在的缓冲区是哪个; - 必须能够判断自己是否已经处于其所在缓冲区的边缘,在跳跃时,必须掌握控制中心
map的位置(通过map_pointer node来解决);
用于迭代器内对各种指针运算都进行重载操作,所以各种运算算法都比较麻烦,特别是对于在缓冲区边缘的元素操作都需要调用set_node操作,来跳到前一个或后一个缓冲区。代码如下:
void set_node(map_pointer new_node){
node=new_node;
first=*new_node;
last=first+difference_type(buffer_size());
}
以后置++为例,通常后置++实现前,先实现前置++,并在后置++中调用前置++。更多运算符重载实现,见deque源码2(deque迭代器、deque的数据结构)。
self& operator++(){ //前置++
++cur; //切换下一个元素
if(cur==last){ //如果已达到所在缓冲区的尾端
set_node(node+1); //利用set_node方法切换到下一个缓冲区
cur=first;
}
return *this;
}
self operator++(int){ //后置++
self temp=*this;
++*this; //调用operator++
return temp;
}
2.4.1 queue 容器
queue是deque的适配器(adaptor),其内含一个deque,并只封装满足FIFO特性的函数,不再提供非FIFO特性的函数。deque容器成员及函数如下:
template<class T, class Sequence=deque<T>>
class queue {
...
public:
typedef typename Sequence::value_type value_type;
typedef typename Sequence::size_type size_type;
typedef typename Sequence::reference reference;
typedef typename Sequence::const_reference const_reference;
protected:
Sequence c; //底层容器
public:
bool empty() const { return c.empty(); }
size_type size() const { return c.size(); }
reference front() { return c.front(); }
const_reference front() const { return c.front(); }
reference back() { return c.back(); }
const_reference back() const { return c.back(); }
void push(const value_type& x) { c.push_back(x); }
void pop() { c.pop_front(); }
...
//运算符重载,size(),swap()...
};
2.4.2 stack 容器
同queue一样,但只提供满足FILO特性的函数。
template<class T, class Sequence=deque<T>>
class stack {
...
public:
typedef typename Sequence::value_type value_type;
typedef typename Sequence::size_type size_type;
typedef typename Sequence::reference reference;
typedef typename Sequence::const_reference const_reference;
protected:
Sequence c; //底层容器
public:
bool empty() const { return c.empty(); }
size_type size() const { return c.size(); }
reference top() { return c.back(); }
const_reference top() const { return c.back(); }
void push(const value_type& x) { c.push_back(x); }
void pop() { c.pop_front(); }
...
stack和queue都不允许遍历,所以不提供iterator(如果提供的话会破坏FILO、FIFO特性)。但是它们的底层Sequence除了默认的deque外,还可以选择list进行,且可以编译通过。
3. 关联容器(Associative Container)
3.1 set / multiset 容器
set / multiset 以 rb_tree 为底层结构(rb_tree概念见 红黑树性质、插入节点和rb_tree容器),由于该类容器所开放的各种操作接口,RB-tree都提供了,所以几乎所有的set操作行为,都只是转调用RB-tree的操作行为,也因此其有元素自动排序的特性。
其中排序的依据是key,而该类容器的key和value值是相同的,在 GNU 2.9 中,KeyOfValue 模板对应的是 identity<value_type>,在 VC6 中是 _Kfn,其功能都类同,传入一个 x 再传回 x 。
set / multiset 提供遍历操作及 iterators 。按正常规则(++iter)遍历,便可得到红黑树的先序遍历,及排序序列。需要注意的是,所提供的 iterators 并不能改变元素值(考虑到 key 和 value 相同,且更改 key 值之后会造成容器底层有序性的破坏),因为 set / multiset 的iterator是其底部的 RB tree 的 const_iterator,常量迭代器禁止对对象进行赋值操作。
- set 元素的 key 必须是 unique 的,因此其 insert() 用的是 rb_tree 的 insert_unique() ;
- multiset 元素的 key 可以重复,因此其 insert() 用的是 rb_tree 的 insert_equal() ;
 | 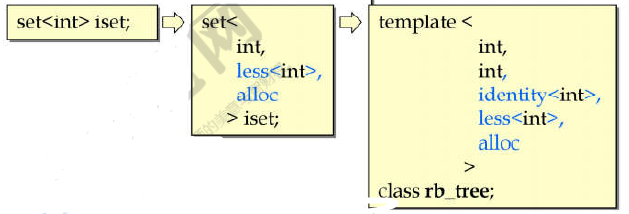 |
节选源码如下:
//以GNU 2.9中的set为例
template <class Key,
class Compare = less<Key>,
class Alloc = alloc>
class set {
public:
typedef Key key_type;
typedef Key value_type; //key_type和value_type相同,及key,value相同
typedef Compare key_compare;
typedef Compare value_compare;
private:
typedef rb_tree<key_type, value_type,
identity<value_type>, key_compare, Alloc> rep_type;
/*template<class Key, class Value, class KeyOfValue, class Compare, class Alloc = alloc>
//Key:键的类型,Value:值的类型,其中key和data合成value
//KeyOfValue:如何取出key,如 gnu C中的identity<int>,是一种仿函数
//Compare:key的大小比较准则,是一个函数对象function object
//class rb_tree {*/
rep_type t;
public:
typedef typename rep_type::const_iterator iterator; //其迭代器是个常量迭代器,限制对元素的修改
/*set拥有与list相同的某些性质,当客户端对它进行元素新增操作或删除操作时,操作之前的迭代器在操作完成后
依然有效,被删除的节点的迭代器除外*/
...
//set的所有操作,都转调用底层红黑树t的操作,
//从这层意义上来看,set是一个容器适配器(container adaptor)
//set自身提供了set<T>::find()函数,相较于algorithm中的全局::find()效率要快的多
};
3.2 map / multimap 容器
map 和 set 实现大同小异,主要区别在于无法使用 map / multimap 的 iterators 改变元素的 key,但可以用其来改变元素的 data。因此在 map / multimap 的内部将用户指定的 key_type 设定为 const 的,如此便能禁止用户对元素 key 的赋值。
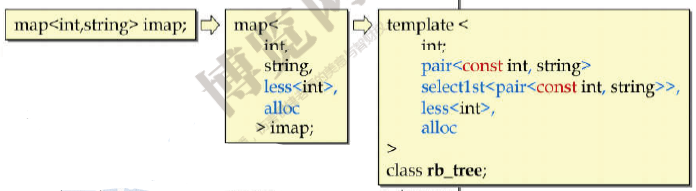
节选源码如下:
template <class Key,
class T,
class Compare = less<int>,
class Alloc = alloc>
class map {
public:
typedef Key key_type; //键值类别
typedef T data_type; //数据(实值)类别
typedef T mapped_type;
typedef pair<const Key, T> value_type; //元素类别,二元组(键值/实值)
typedef Compare key_compare; //键值比较函数
...
private:
typedef rb_tree<key_type, value_type,
select1st<value_type>, key_compare, Alloc> rep_type; //仍然遵循rb_tree的模板
rep_type t;
public:
typedef typename rep_type::iterator iterator; //注意,在这里和set的区别是不再是const修饰的iterator
...
public:
//operator[]重载的实现
T& operator[] (const key_type& k) {
return (*((insert(value_type(k, T()))).first())).second;
}
/*首先根据键值和实值创建出一个元素,由于实值未知,所以产生一个与实值类型相同的暂时对象替代
再将该元素插入map当中去,插入操作返回一个pair,其第一元素是个迭代器,指向插入妥当的新元素,或指向插入失败的已有的旧元素
然后提领该迭代器,将迭代器的实值以reference引用的方式传递给调用的过程:
如果operator[]是lhs(左值),则可以对 data/实值 进行 更改/赋值 操作
如果operator[]是rhs(右值),则返回的是 iterator 所指元素的 data/实值
*/
};
//key值比较类,select1st
template <class Pair>
struct select1st : public unary_function<Pair, typename Pair::first_type> {
const typename Pair::first_type operator() (const Pair& x) const {
return x.first;
}
};
对于 map 容器,在算法题中经常会使用到operator[]/下标运算符,对于其实现,STL标准文件当中给出了详细要求和说明;
...
Allows for easy lookup with the subscript (@c [])
operator. Returns data associated with the key specified in
subscript. If the key does exist, a pair with that key
is created usig default values, which is then returned.
Lookup requires logarithmic time.
...
在GNU 4.9 版本当中,对下标运算符的重载,其间调用了lower_bound()函数,是二分搜寻的一种版本。其试图在sorted[first, last)中寻找拥有与传入的key相等的key/value对。若有,则指向其中第一个元素,若没有,则返回假设该元素存在时应该出现的不小于传入的key的位置。也就是说它会返回iterator指向第一个不小于传入key的元素的data。如果传入的key大于[first, last)中的所有元素,将返回last。换句话说low_bound返回的是不破坏排序得以安插传入的key值的第一个合适位置。
3.3 unordered 容器
对于unordered容器,具体用法查看以下cppreference文档:
理解unordered容器,就要介绍hashtable容器,原本unordered容器叫做hash容器,在C++ 11之后改名为现在的样子。
对于一个大小为T TT个32 3232位元素的类型而言,穷尽所有的可能有T × 2 32 T \times 2 ^{32}T×232种,如果存储的话会有4 × T ( G B ) 4 \times T (GB)4×T(GB)大小,这显然是不切实际的,所以要想办法使用某种映射函数,将大数映射为小数,这样的映射函数称为hash function(散列函数),如下图,其中M < < N M<<NM<<N。
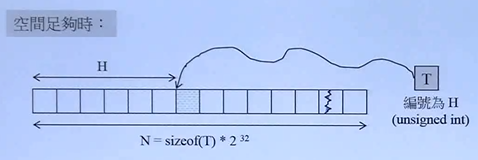 | 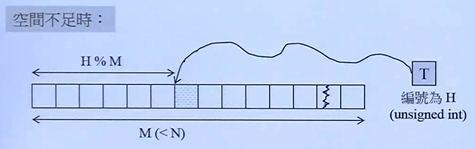 |
但是,散列函数使用起来难免可能会有不同的元素值被映射到相同的位置,也就是发生hash碰撞(collision)。解决该问题有线性探测(linear probing)、二次探测(quadratic probing)、开链(separate chaining)…等做法。
对于哈希表,其中有一专有名词称为负载系数(loading factor),指的是元素个数除以表格大小。只有在使用开链策略时,其值会不在0~1之间,其余策略都在区间内。对于SGI STL的hash table所采用的hash策略就是开链策略。
对于开链策略,做法是在每一个表格元素(抽象为bucket,桶)中维护一个list;hash function为我们分配某一个list,然后在list身上执行元素的插入、搜寻和删除等。虽然对链表list的搜寻只能是线性的,但如果list长度够短,速度还是挺快的。SGI STL实际实现的hashtable数据结构示意图如下:
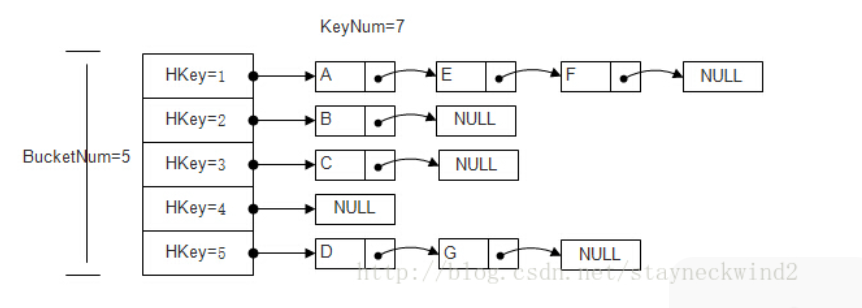 |  |
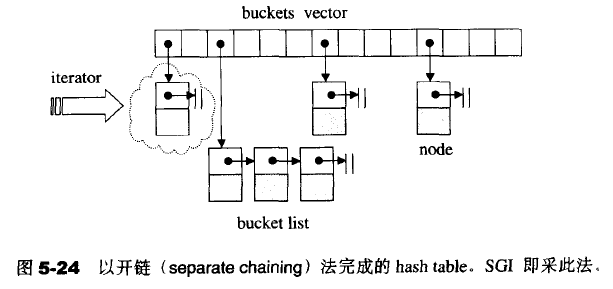
以下是hash table节点的定义
//bucket所维护的linked list,并不采用STL的list或slist,而是自行维护
//buckets聚合,以vector实现,以便对桶的数量进行拓展
template <class Value>
struct __hashtable_node {
__hashtable_node* next; //ptr 4bytes
Value val; //4bytes
}; //sizeof() = 8;
以下是hashtable的实现源码:
/*Value:节点的实值类别
Key:节点的键值型类别
HashFcn:hash function的函数类别
ExtractKey:从节点中提取出key的方法(函数或仿函数)
EqualKey:判断键值是否相同的方法
Alloc:空间配置器,缺省使用std::alloc*/
template <class Value, class Key, class HashFcn,
class ExtractKey, class EqualKey,
class Alloc = alloc>
class hashtable {
public:
typedef HashFcn hasher; //hash函数
typedef EqualKey key_equal; //判等函数
typedef size_t size_type;
private:
hasher hash; //大小为0,但是实际值为1,仿函数
key_equal equals;//大小为0,但是实际值为1
ExtractKey get_key;//大小为0,但是实际值为1
typedef __hashtable_node<Value>node;
vector<node*, Alloc>buckets; // vector里有三个指针,大小为12
size_type num_elements;//4个字节 12+1+1+1+4 = 19 ->字节对齐 20
public:
size_type bucket_count() const { return bucket.size(); }
};
以下是hashtable迭代器的实现源码:
template <class Value, class Key, class HashFcn,
class ExtractKey, class EqualKey,
class Alloc = alloc>
struct __hashtable_iterator {
...
typedef hashtable<Value, Key, HashFcn, ExtractKey, EqualKey, Alloc> hashtable;
...//iterator const_iterator
typedef __hashtable_node<Value> node;
typedef forward_iterator_tag iterator_category; //前向迭代器,不提供逆向迭代器,非unordered提供
typedef Value value_type;
typedef ptrdiff_t difference_type;
typedef size_t size_type;
typedef Value& reference;
typedef Value* pointer;
...
node* cur; //迭代器目前所指的节点
hashtable* ht;
//保持和容器的连接关系(因为可能要从bucket跳到bucket),
//有点deque的list中控的味道,但是这里是vector
};
SGI STL在判知元素的位置时,将调用bkt_num()函数,再由此函数调用hash function,取得一个可执行modulus运算的数值。因为有些元素类型无法直接拿来对hashtable的大小进行模运算,比如char*字符串,需要进行转换后再进行求模。
可以看到,上面进行模运算的过程中调用了hashtable中的hash()函数,SGI实现中bkt_num()调用了<stl_hash_fun.h>中现成的hash functions,它们全是仿函数。针对char,int,long等整形类别只是返回,对于字符串进行了转换,用到了偏特化(partial specification),偏特化概念见STL迭代器详解。
